
Heim >Java >javaLernprogramm >So beheben Sie den 502-Fehler beim Upgrade der k8s-Service-Springboot-Projektanwendung
So beheben Sie den 502-Fehler beim Upgrade der k8s-Service-Springboot-Projektanwendung

- 王林nach vorne
- 2023-05-11 22:28:042966Durchsuche
Da das Entwicklungsmodell der kleinen Schritte und der schnellen Iteration von immer mehr Internetunternehmen erkannt und übernommen wird, wird die Häufigkeit von Anwendungsänderungen und -upgrades immer häufiger. Um den unterschiedlichen Upgrade-Anforderungen gerecht zu werden und sicherzustellen, dass der Upgrade-Prozess reibungslos verläuft, wurde eine Reihe von Bereitstellungs- und Release-Modellen entwickelt.
Veröffentlichung stoppen – Stoppen Sie die alte Version der Anwendungsinstanz vollständig und geben Sie dann die neue Version frei. Dieses Release-Modell dient hauptsächlich dazu, das Problem der Inkompatibilität und Koexistenz zwischen alten und neuen Versionen zu lösen. Der Nachteil besteht darin, dass der Dienst für einen bestimmten Zeitraum vollständig nicht verfügbar ist.
Blau-grüne Version – Stellen Sie die gleiche Anzahl neuer und alter Anwendungsinstanzen gleichzeitig online bereit. Nachdem die neue Version den Test bestanden hat, wird der Datenverkehr sofort auf die neue Dienstinstanz umgeleitet. Dieses Veröffentlichungsmodell löst das Problem der vollständigen Nichtverfügbarkeit von Diensten bei der Veröffentlichung in Ausfallzeiten, verursacht jedoch einen relativ hohen Ressourcenverbrauch.
Rolling Release – Ersetzen Sie Anwendungsinstanzen schrittweise in Stapeln. Dieser Release-Modus unterbricht die Dienste nicht und verbraucht nicht zu viele zusätzliche Ressourcen. Da jedoch die Instanzen der alten und neuen Version gleichzeitig online sind, kann es dazu führen, dass Anfragen desselben Clients zwischen der alten und der neuen Version wechseln Kompatibilitätsprobleme.
Canary Release – Wechseln Sie den Datenverkehr schrittweise von der alten Version zur neuen Version. Wenn nach längerer Beobachtung kein Problem festgestellt wird, wird der Datenverkehr der neuen Version weiter ausgeweitet, während der Datenverkehr der alten Version reduziert wird.
A/B-Tests – Starten Sie zwei oder mehr Versionen gleichzeitig, sammeln Sie Benutzerfeedback zu diesen Versionen, analysieren und bewerten Sie die beste Version für die offizielle Einführung.
K8s-Anwendungs-Upgrade
In k8s ist Pod die Grundeinheit für die Bereitstellung und Aktualisierung. Im Allgemeinen stellt ein Pod eine Anwendungsinstanz dar, und der Pod wird in Form von Deployment, StatefulSet, DaemonSet, Job usw. bereitgestellt und ausgeführt. Im Folgenden werden die Upgrade-Methoden von Pods in diesen Bereitstellungsformen beschrieben.
Bereitstellung
Bereitstellung ist die häufigste Bereitstellungsform von Pod. Hier nehmen wir als Beispiel eine Java-Anwendung, die auf Spring Boot basiert. Diese Anwendung ist eine einfache, von einer realen Anwendung abstrahierte Version und weist die folgenden Eigenschaften auf:
Nachdem die Anwendung gestartet wurde, dauert es eine gewisse Zeit, bis die Konfiguration geladen ist der Außenwelt zur Verfügung gestellt werden.
Nur weil die Anwendung gestartet werden kann, bedeutet das nicht, dass sie Dienste normal bereitstellen kann.
Die Anwendung wird möglicherweise nicht automatisch beendet, wenn sie keine Dienste bereitstellen kann.
Während des Upgrade-Prozesses muss sichergestellt werden, dass die Anwendungsinstanz, die offline gehen soll, keine neuen Anfragen erhält und genügend Zeit hat, die aktuelle Anfrage zu verarbeiten.
Parameterkonfiguration
Damit Anwendungen mit den oben genannten Eigenschaften keine Ausfallzeiten und keine Produktionsunterbrechungen bei Upgrades erreichen, müssen die relevanten Parameter in der Bereitstellung sorgfältig konfiguriert werden. Die mit dem Upgrade verbundene Konfiguration lautet hier wie folgt (die vollständige Konfiguration finden Sie unter spring-boot-probes-v1.yaml).
kind: Deployment
...
spec:
replicas: 8
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 3
maxUnavailable: 2
minReadySeconds: 120
...
template:
...
spec:
containers:
- name: spring-boot-probes
image: registry.cn-hangzhou.aliyuncs.com/log-service/spring-boot-probes:1.0.0
ports:
- containerPort: 8080
terminationGracePeriodSeconds: 60
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
failureThreshold: 1
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
failureThreshold: 3
...Strategie konfigurieren
Sie können die Pod-Ersatzstrategie über die Strategie konfigurieren. Die Hauptparameter sind wie folgt.
.spec.strategy.type– wird verwendet, um den Strategietyp anzugeben, der den Pod ersetzen soll. Dieser Parameter kann den Wert Recreate oder RollingUpdate annehmen und der Standardwert ist RollingUpdate..spec.strategy.type- 用于指定替换 pod 的策略类型。该参数可取值 Recreate 或 RollingUpdate,默认为 RollingUpdate。Recreate - K8s 会先删掉全部原有 pod 再创建新的 pod。该方式适用于新老版本互不兼容、无法共存的场景。但由于该方式会造成一段时间内服务完全不可用,在上述场景之外须慎用。
RollingUpdate - K8s 会将 pod 分批次逐步替换掉,可用来实现服务热升级。
.spec.strategy.rollingUpdate.maxSurge- 指定在滚动更新过程中最多可创建多少个额外的 pod,可以是数字或百分比。该值设置得越大、升级速度越快,但会消耗更多的系统资源。-
.spec.strategy.rollingUpdate.maxUnavailable
- RollingUpdate – K8s werden Pods nach und nach stapelweise ersetzen, was zur Implementierung von Hot-Upgrades von Diensten verwendet werden kann.
.spec.strategy.rollingUpdate.maxSurge– Gibt die maximale Anzahl zusätzlicher Pods an, die während eines fortlaufenden Updates erstellt werden können, entweder als Zahl oder als Prozentsatz. Je höher der Wert eingestellt ist, desto schneller erfolgt das Upgrade, es werden aber auch mehr Systemressourcen beansprucht.
.spec.strategy.rollingUpdate.maxUnavailable – Gibt die maximale Anzahl von Pods an, die während des fortlaufenden Aktualisierungsprozesses nicht verfügbar sein dürfen. Dies kann eine Zahl oder ein Prozentsatz sein. Je höher der Wert eingestellt ist, desto schneller erfolgt das Upgrade, allerdings wird der Dienst instabiler.
Durch Anpassen von maxSurge und maxUnavailable können Sie den Upgrade-Anforderungen in verschiedenen Szenarien gerecht werden.
🎜🎜🎜Wenn Sie ein Upgrade so schnell wie möglich durchführen und gleichzeitig die Systemverfügbarkeit und -stabilität sicherstellen möchten, können Sie maxUnavailable auf 0 setzen und maxSurge einen größeren Wert zuweisen. 🎜🎜🎜🎜Wenn die Systemressourcen knapp sind und die Pod-Auslastung gering ist, können Sie maxSurge auf 0 setzen und maxUnavailable einen größeren Wert zuweisen, um das Upgrade zu beschleunigen. Es ist zu beachten, dass, wenn maxSurge 0 ist und maxUnavailable DESIRED ist, dies dazu führen kann, dass der gesamte Dienst nicht verfügbar ist. Zu diesem Zeitpunkt wird RollingUpdate auf eine Shutdown-Version herabgestuft. 🎜🎜🎜🎜Das Beispiel wählt eine Kompromisslösung und setzt maxSurge auf 3 und maxUnavailable auf 2, wodurch Stabilität, Ressourcenverbrauch und Upgrade-Geschwindigkeit ausgeglichen werden. 🎜🎜Konfigurationssonden🎜🎜K8s bietet die folgenden zwei Arten von Sonden: 🎜ReadinessProbe – Sobald alle Container in einem Pod gestartet sind, betrachtet k8s den Pod standardmäßig als bereit und sendet Datenverkehr an den Pod. Nachdem einige Anwendungen gestartet wurden, müssen sie jedoch noch das Laden von Daten oder Konfigurationsdateien abschließen, bevor sie externe Dienste bereitstellen können. Daher ist es nicht streng, anhand des Starts zu beurteilen, ob der Container bereit ist. Durch die Konfiguration von Bereitschaftstests für Container kann k8s genauer bestimmen, ob der Container bereit ist, und so eine robustere Anwendung erstellen. K8s stellt sicher, dass der Dienst nur dann Datenverkehr an den Pod senden darf, wenn alle Container in einem Pod die Bereitschaftserkennung bestehen. Sobald die Bereitschaftserkennung fehlschlägt, sendet k8s keinen Datenverkehr mehr an den Pod.
LivenessProbe – Standardmäßig betrachtet k8s laufende Container als verfügbar. Diese Beurteilung kann jedoch problematisch sein, wenn die Anwendung nicht automatisch beendet werden kann, wenn ein Fehler auftritt oder ein Fehler auftritt (z. B. wenn ein schwerwiegender Deadlock auftritt). Durch die Konfiguration von Liveness-Tests für Container kann k8s genauer bestimmen, ob der Container normal läuft. Wenn der Container die Lebendigkeitserkennung nicht besteht, stoppt das Kubelet ihn und bestimmt die nächste Aktion basierend auf der Neustartrichtlinie.
Die Konfiguration der Sonde ist sehr flexibel. Benutzer können die Erkennungshäufigkeit, die Erkennungserfolgsschwelle, die Erkennungsfehlerschwelle usw. festlegen. Informationen zur Bedeutung und Konfigurationsmethode der einzelnen Parameter finden Sie im Dokument Liveness and Readiness Probes konfigurieren.
Das Beispiel konfiguriert einen Bereitschaftstest und einen Lebendigkeitstest für den Zielcontainer:
Die initialDelaySeconds des Bereitschaftstests sind auf 30 eingestellt, da die Anwendung durchschnittlich 30 Sekunden benötigt, um die Initialisierungsarbeit abzuschließen.
Bei der Konfiguration der Lebendigkeitssonde müssen Sie sicherstellen, dass der Container genügend Zeit hat, um den Bereitschaftszustand zu erreichen. Wenn die Parameter initialDelaySeconds, periodSeconds und failThreshold zu klein eingestellt sind, kann es dazu führen, dass der Container neu gestartet wird, bevor er bereit ist, sodass der Bereitschaftszustand nie erreicht werden kann. Die Konfiguration im Beispiel stellt sicher, dass der Container nicht neu gestartet wird, wenn er innerhalb von 80 Sekunden nach dem Start bereit ist. Dies ist ein ausreichender Puffer im Vergleich zur durchschnittlichen Initialisierungszeit von 30 Sekunden.
Die periodSeconds der Bereitschaftsprüfung sind auf 10 und der FailureThreshold auf 1 gesetzt. Wenn der Container abnormal ist, wird auf diese Weise nach etwa 10 Sekunden kein Datenverkehr mehr an ihn gesendet.
Die periodSeconds des Aktivitätstests sind auf 20 und der FailureThreshold auf 3 eingestellt. Wenn der Container auf diese Weise abnormal ist, wird er nach etwa 60 Sekunden nicht neu gestartet.
Konfigurieren Sie minReadySeconds
Sobald ein neu erstellter Pod bereit ist, betrachtet k8s standardmäßig den Pod als verfügbar und löscht den alten Pod. Manchmal tritt das Problem jedoch auf, wenn der neue Pod tatsächlich Benutzeranfragen verarbeitet. Ein robusterer Ansatz besteht daher darin, einen neuen Pod eine Zeit lang zu beobachten, bevor der alte Pod gelöscht wird.
Der Parameter minReadySeconds kann die Beobachtungszeit des Pods im Bereitschaftszustand steuern. Wenn die Container im Pod in diesem Zeitraum normal laufen können, betrachtet k8s den neuen Pod als verfügbar und löscht den alten Pod. Wenn Sie diesen Parameter konfigurieren, müssen Sie ihn sorgfältig abwägen. Wenn er zu klein eingestellt ist, kann dies zu einer unzureichenden Beobachtung führen. Wenn er zu groß eingestellt ist, wird der Upgrade-Fortschritt verlangsamt. Das Beispiel setzt minReadySeconds auf 120 Sekunden, wodurch sichergestellt wird, dass der Pod im Bereitschaftszustand einen vollständigen Lebendigkeitserkennungszyklus durchlaufen kann.
BeendigungGracePeriodSeconds konfigurieren
Wenn k8s bereit ist, einen Pod zu löschen, sendet es ein TERM-Signal an den Container im Pod und entfernt gleichzeitig den Pod aus der Endpunktliste des Dienstes. Wenn der Container nicht innerhalb der angegebenen Zeit (Standard 30 Sekunden) beendet werden kann, sendet k8s das SIGKILL-Signal an den Container, um den Prozess zwangsweise zu beenden. Den detaillierten Ablauf der Pod-Kündigung finden Sie im Dokument „Kündigung von Pods“.
Da die Anwendung bis zu 40 Sekunden benötigt, um Anfragen zu verarbeiten, legt das Beispiel eine ordnungsgemäße Abschaltzeit von 60 Sekunden fest, damit sie die beim Server eingegangenen Anfragen verarbeiten kann, bevor sie heruntergefahren wird. Für verschiedene Anwendungen können Sie den Wert von termationGracePeriodSeconds entsprechend den tatsächlichen Bedingungen anpassen.
Beobachten Sie das Upgrade-Verhalten
Die obige Konfiguration kann ein reibungsloses Upgrade der Zielanwendung gewährleisten. Wir können ein Pod-Upgrade auslösen, indem wir ein beliebiges Feld von PodTemplateSpec in der Bereitstellung ändern und das Upgrade-Verhalten beobachten, indem wir den Befehl kubectl get rs -w ausführen. Die hier beobachteten Änderungen in der Anzahl der Pod-Kopien der alten und neuen Version sind wie folgt:
Erstellen Sie maxSurge neue Pods. Zu diesem Zeitpunkt erreicht die Gesamtzahl der Pods die zulässige Obergrenze, d. h. DESIRED + maxSurge.
Starten Sie sofort den Löschvorgang für maximal nicht verfügbare alte Pods, ohne darauf zu warten, dass der neue Pod bereit oder verfügbar ist. Zu diesem Zeitpunkt ist die Anzahl der verfügbaren Pods GEWÜNSCHT – max. Nicht verfügbar.
Wenn ein alter Pod vollständig gelöscht wird, wird sofort ein neuer Pod hinzugefügt.
Wenn ein neuer Pod die Bereitschaftserkennung besteht und bereit wird, sendet k8s Datenverkehr an den Pod. Da die angegebene Beobachtungszeit jedoch nicht erreicht wurde, gilt der Pod als nicht verfügbar.
Ein fertiger Pod, der während des Beobachtungszeitraums normal läuft, gilt als verfügbar. Zu diesem Zeitpunkt kann der Löschvorgang eines alten Pods erneut gestartet werden.
Wiederholen Sie die Schritte 3, 4 und 5, bis alle alten Pods gelöscht sind und die verfügbaren neuen Pods die Zielanzahl an Replikaten erreichen.
失败回滚
应用的升级并不总会一帆风顺,在升级过程中或升级完成后都有可能遇到新版本行为不符合预期需要回滚到稳定版本的情况。K8s 会将 PodTemplateSpec 的每一次变更(如果更新模板标签或容器镜像)都记录下来。这样,如果新版本出现问题,就可以根据版本号方便地回滚到稳定版本。回滚 Deployment 的详细操作步骤可参考文档 Rolling Back a Deployment。
StatefulSet
StatefulSet 是针对有状态 pod 常用的部署形式。针对这类 pod,k8s 同样提供了许多参数用于灵活地控制它们的升级行为。好消息是这些参数大部分都和升级 Deployment 中的 pod 相同。这里重点介绍两者存在差异的地方。
策略类型
在 k8s 1.7 及之后的版本中,StatefulSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 StatefulSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.6 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - K8s 会将 StatefulSet 管理的 pod 分批次逐步替换掉。它与 Deployment 中 RollingUpdate 的区别在于 pod 的替换是有序的。例如一个 StatefulSet 中包含 N 个 pod,在部署的时候这些 pod 被分配了从 0 开始单调递增的序号,而在滚动更新时,它们会按逆序依次被替换。
Partition
可以通过参数.spec.updateStrategy.rollingUpdate.partition实现只升级部分 pod 的目的。在配置了 partition 后,只有序号大于或等于 partition 的 pod 才会进行滚动升级,其余 pod 将保持不变。
Partition 的另一个应用是可以通过不断减少 partition 的取值实现金丝雀升级。具体操作方法可参考文档 Rolling Out a Canary。
DaemonSet
DaemonSet 保证在全部(或者一些)k8s 工作节点上运行一个 pod 的副本,常用来运行监控或日志收集程序。对于 DaemonSet 中的 pod,用于控制它们升级行为的参数与 Deployment 几乎一致,只是在策略类型方面略有差异。DaemonSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 DaemonSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.5 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - 其含义和可配参数与 Deployment 的 RollingUpdate 一致。
滚动更新 DaemonSet 的具体操作步骤可参考文档 Perform a Rolling Update on a DaemonSet。
Job
Deployment、StatefulSet、DaemonSet 一般用于部署运行常驻进程,而 Job 中的 pod 在执行完特定任务后就会退出,因此不存在滚动更新的概念。当您更改了一个 Job 中的 PodTemplateSpec 后,需要手动删掉老的 Job 和 pod,并以新的配置重新运行该 job。
总结
K8s 提供的功能可以让大部分应用实现零宕机时间和无生产中断的升级,但也存在一些没有解决的问题,主要包括以下几点:
目前 k8s 原生仅支持停机发布、滚动发布两类部署升级策略。如果应用有蓝绿发布、金丝雀发布、A/B 测试等需求,需要进行二次开发或使用一些第三方工具。
K8s 虽然提供了回滚功能,但回滚操作必须手动完成,无法根据条件自动回滚。
有些应用在扩容或缩容时同样需要分批逐步执行,k8s 还未提供类似的功能。
实例配置:
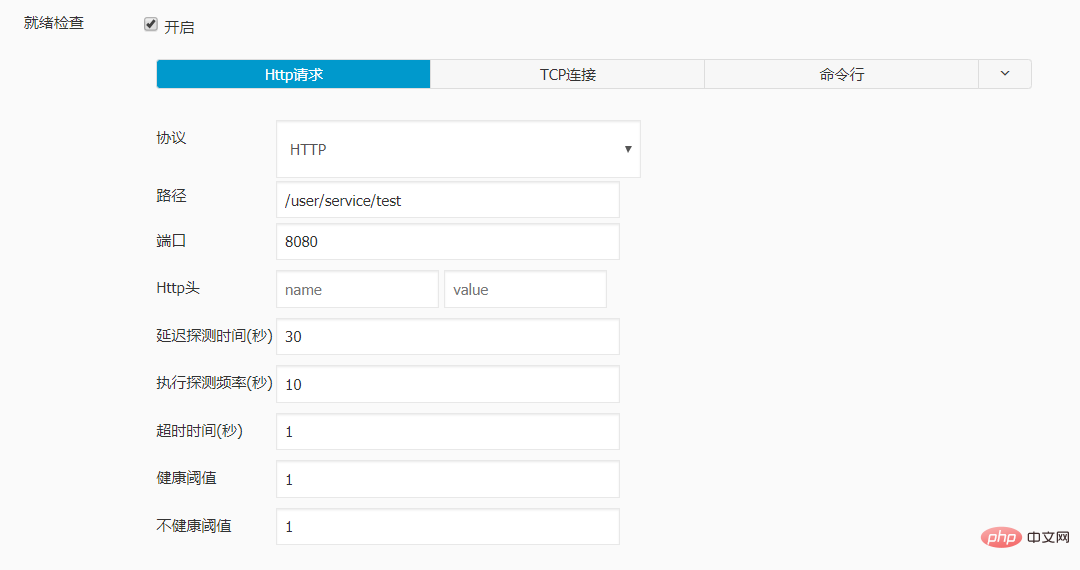
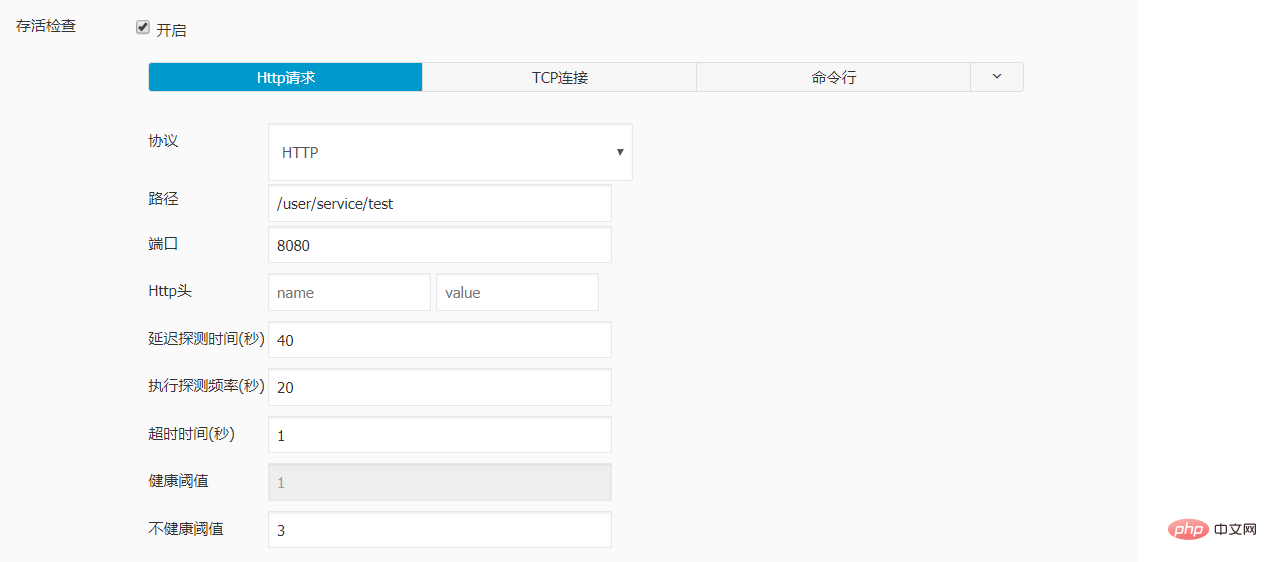
livenessProbe:
failureThreshold: 3
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 1
name: dataline-dev
ports:
- containerPort: 8080
protocol: TCP
readinessProbe:
failureThreshold: 1
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1经测试 , 再对sprintboot 应用进行更新时, 访问不再出现502的报错。
Das obige ist der detaillierte Inhalt vonSo beheben Sie den 502-Fehler beim Upgrade der k8s-Service-Springboot-Projektanwendung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Warum und wie sollten Sie String-Objekte in Java synchronisieren?
- So stellen Sie sicher, dass die Aufgabe beim Herunterfahren des Java ExecutorService beendet wird
- Warum weist SimpleDateFormat beim Analysieren von Active Directory-Daten alle Daten dem Januar zu?
- Warum gibt Java SimpleDateFormat jeden Monat immer den Januar zurück?
- Wie zeige ich bestimmte Objekteigenschaften in einer ListView mit benutzerdefinierten Objekten in JavaFX an?