
Heim >Technologie-Peripheriegeräte >KI >Durch die Verwendung von Bildern zur Ausrichtung aller Modalitäten wird ein multisensorisches Open-Source-KI-Basismodell für Meta verwendet, um eine große Vereinheitlichung zu erreichen
Durch die Verwendung von Bildern zur Ausrichtung aller Modalitäten wird ein multisensorisches Open-Source-KI-Basismodell für Meta verwendet, um eine große Vereinheitlichung zu erreichen

- 王林nach vorne
- 2023-05-11 19:25:111433Durchsuche
In den menschlichen Sinnen kann ein Bild viele Erlebnisse miteinander verbinden. Beispielsweise kann uns ein Strandbild an das Rauschen der Wellen, die Textur des Sandes, die Brise, die uns ins Gesicht weht, erinnern Kann ein Gedicht inspirieren. Diese „bindende“ Eigenschaft von Bildern stellt eine große Quelle der Aufsicht für das Erlernen visueller Merkmale dar, indem sie sie mit allen damit verbundenen Sinneserfahrungen in Einklang bringt.
Idealerweise sollten visuelle Merkmale erlernt werden, indem alle Sinne auf einen einzigen gemeinsamen Einbettungsraum ausgerichtet werden. Dies erfordert jedoch die Gewinnung gepaarter Daten für alle Sinnestypen und -kombinationen aus demselben Bildsatz, was offensichtlich nicht möglich ist.
In letzter Zeit lernen viele Methoden Bildfunktionen, die an Text, Audio usw. ausgerichtet sind. Diese Methoden verwenden ein einzelnes Modalitätenpaar oder höchstens mehrere visuelle Modalitäten. Die endgültige Einbettung ist auf die für das Training verwendeten Modalpaare beschränkt. Daher kann die Video-Audio-Einbettung nicht direkt für Bild-Text-Aufgaben verwendet werden und umgekehrt. Ein großes Hindernis beim Erlernen echter Gelenkeinbettungen ist das Fehlen großer Mengen multimodaler Daten, in denen alle Modalitäten miteinander verschmolzen sind.
Heute hat Meta AI ImageBind vorgeschlagen, indem es mehrere Arten von Bildpaarungsdaten nutzt, um ein einzelnes zu lernen gemeinsamer Repräsentationsraum. Für diese Studie ist kein Datensatz erforderlich, in dem alle Modalitäten gleichzeitig auftreten. Stattdessen nutzt die Bindungseigenschaften des Bildes, wodurch alle Modalitäten erreicht werden, solange jede Modalität eingebettet ist ist mit der Bildeinbettung ausgerichtet. Die schnelle Ausrichtung von . Auch Meta AI gab den entsprechenden Code bekannt.

- # 🎜 🎜#Papieradresse: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
- GitHub-Adresse: https:/ /github.com/facebookresearch/ImageBind
Spezifisch und Spezifisch Mit anderen Worten: ImageBind nutzt Matching-Daten im Netzwerkmaßstab (Bild, Text) und kombiniert sie mit natürlich vorkommenden gepaarten Daten (Video, Audio, Bild, Tiefe), um einen einzelnen gemeinsamen Einbettungsraum zu lernen. Dadurch kann ImageBind Texteinbettungen implizit mit anderen Modalitäten (z. B. Audio, Tiefe usw.) ausrichten und so eine Zero-Shot-Erkennung dieser Modalitäten ohne explizite Semantik oder Textpaarung ermöglichen.
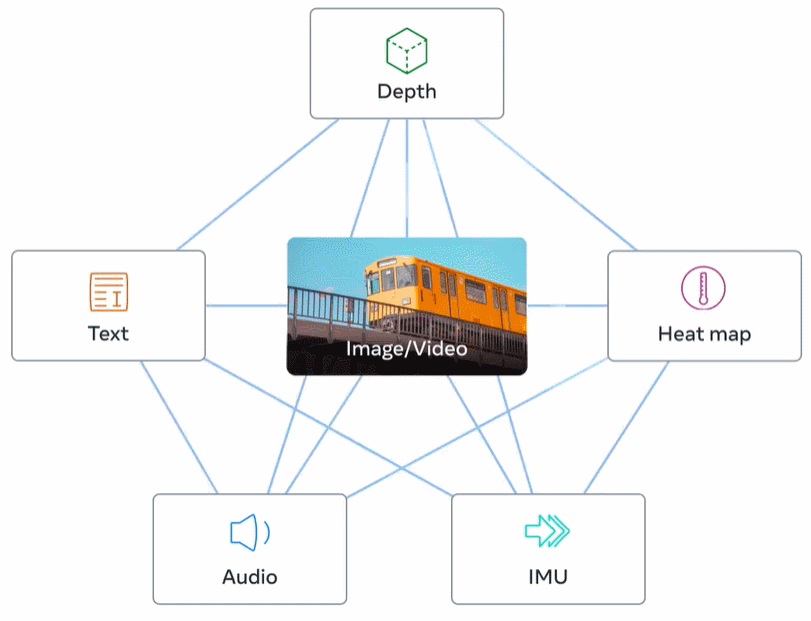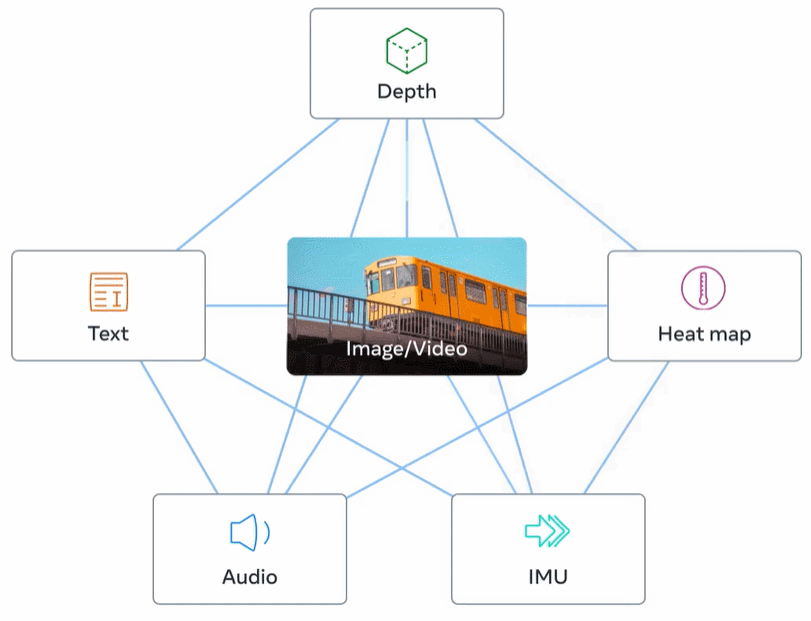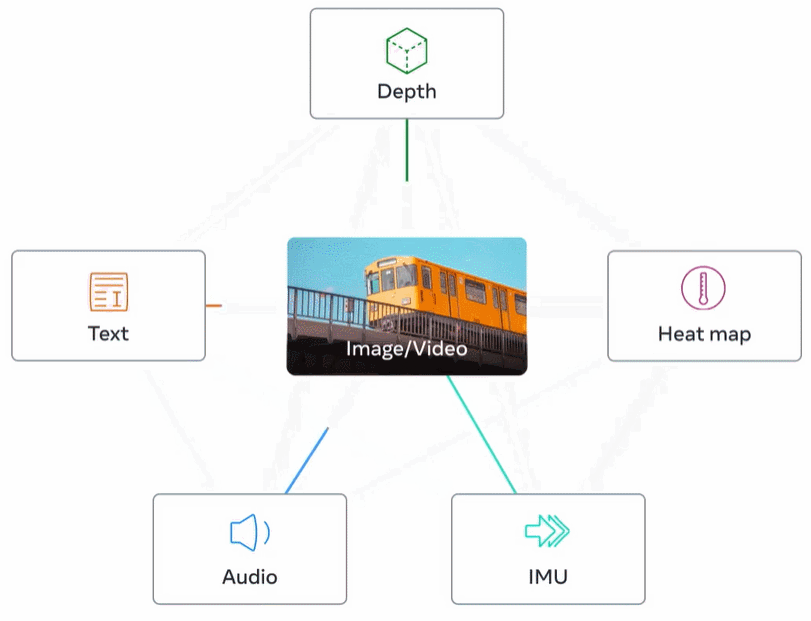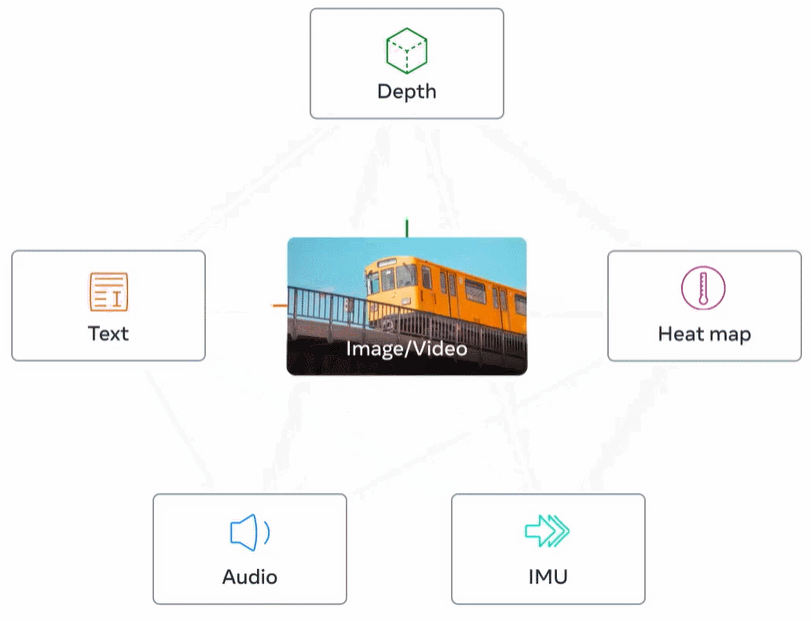
Abbildung 2 unten ist eine Gesamtübersicht über ImageBind.

Gleichzeitig sagten Forscher, dass ImageBind mithilfe groß angelegter visueller Sprachmodelle (z. B CLIP), wodurch die reichhaltigen Bild- und Textdarstellungen dieser Modelle genutzt werden. Daher erfordert ImageBind nur sehr wenig Schulung und kann auf eine Vielzahl unterschiedlicher Modalitäten und Aufgaben angewendet werden.
ImageBind ist Teil von Metas Engagement für die Entwicklung multimodaler KI-Systeme, die aus allen relevanten Datentypen lernen. Da die Anzahl der Modalitäten zunimmt, öffnet ImageBind den Forschern die Schleusen, um zu versuchen, neue ganzheitliche Systeme zu entwickeln, beispielsweise die Kombination von 3D- und IMU-Sensoren, um immersive virtuelle Welten zu entwerfen oder zu erleben. Es bietet auch eine umfassende Möglichkeit, Ihr Gedächtnis zu erkunden, indem Sie eine Kombination aus Text, Video und Bildern verwenden, um nach Bildern, Videos, Audiodateien oder Textinformationen zu suchen.
Inhalte und Bilder verknüpfen, einen einzigen Einbettungsraum lernenMenschen haben die Fähigkeit, neue Konzepte mit sehr wenigen Beispielen zu erlernen, wie zum Beispiel Lesen Paare: Anhand der Beschreibung eines Tieres können Sie es im wirklichen Leben erkennen; anhand eines Fotos eines unbekannten Automodells können Sie vorhersagen, welches Geräusch sein Motor wahrscheinlich machen wird. Dies liegt zum Teil daran, dass ein einzelnes Bild ein gesamtes Sinneserlebnis „bündeln“ kann. Obwohl im Bereich der künstlichen Intelligenz die Anzahl der Modalitäten zunimmt, wird der Mangel an multisensorischen Daten das standardmäßige multimodale Lernen, das gepaarte Daten erfordert, einschränken.
Idealerweise ermöglicht ein gemeinsamer Einbettungsraum mit verschiedenen Datentypen dem Modell, andere Modalitäten zu erlernen und gleichzeitig visuelle Merkmale zu lernen. Bisher war es oft notwendig, alle möglichen paarweisen Datenkombinationen zu sammeln, damit alle Modalitäten einen gemeinsamen Einbettungsraum lernen konnten.
ImageBind umgeht dieses Rätsel, indem es aktuelle groß angelegte visuelle Sprachmodelle nutzt. Es erweitert die Zero-Shot-Fähigkeiten neuerer groß angelegter visueller Sprachmodelle auf neue Modalitäten mit ihren natürlichen Bildpaarungen, wie z. B. Video-Audio und Bild -Tiefendaten zum Erlernen eines gemeinsamen Einbettungsraums. Für die anderen vier Modalitäten (Audio, Tiefe, Wärmebildgebung und IMU-Messwerte) verwendeten die Forscher natürlich gepaarte selbstüberwachte Daten.
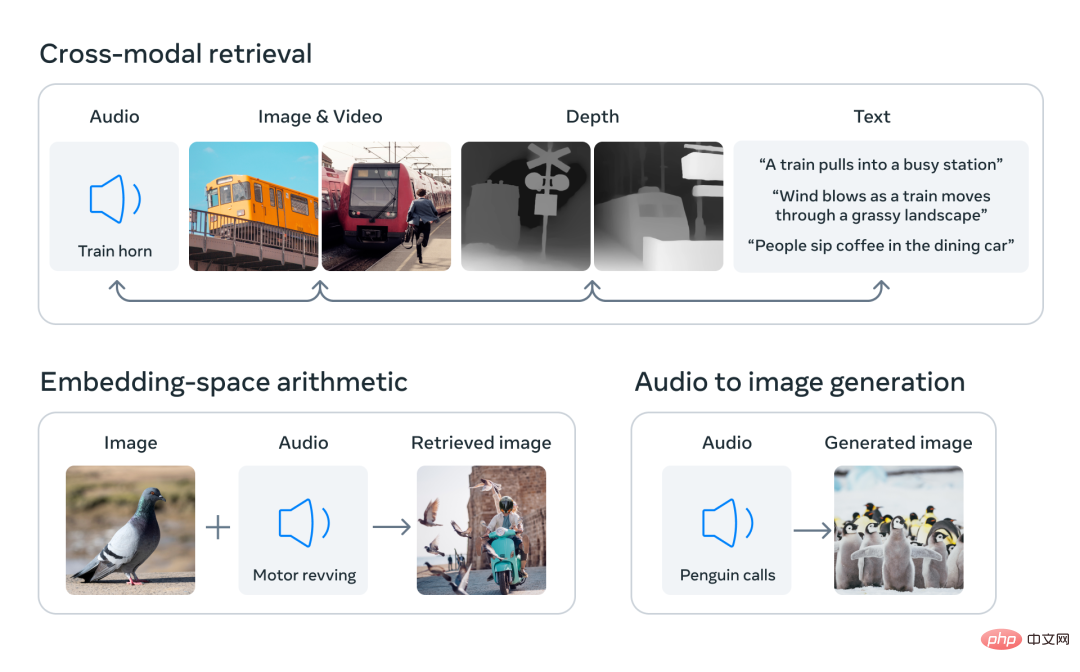
Durch die Ausrichtung der Einbettungen von sechs Modalitäten in einem gemeinsamen Raum kann ImageBind verschiedene Arten von Inhalten abrufen, die nicht gleichzeitig über Modalitäten hinweg beobachtet werden, und Einbettungen verschiedener Modalitäten hinzufügen, um deren Semantik und natürlich zu kombinieren Verwenden Sie die Audioeinbettungen von Meta AI mit einem vortrainierten DALLE-2-Decoder (für die Verwendung mit CLIP-Texteinbettung konzipiert), um eine Audio-zu-Bild-Generierung zu erreichen.
Es gibt eine große Anzahl von Bildern, die zusammen mit Text im Internet erscheinen, daher wurde das Training von Bild-Text-Modellen umfassend untersucht. ImageBind nutzt die Bindungseigenschaften von Bildern, die mit verschiedenen Modalitäten verbunden werden können, z. B. die Verknüpfung von Text mit Bildern mithilfe von Netzwerkdaten oder die Verknüpfung von Bewegung mit Video mithilfe von Videodaten, die in einer tragbaren Kamera mit einem IMU-Sensor erfasst wurden.
Visuelle Darstellungen, die aus umfangreichen Netzwerkdaten gelernt wurden, können als Ziele für das Erlernen verschiedener modaler Merkmale verwendet werden. Dadurch kann ImageBind das Bild an allen gleichzeitig vorhandenen Modalitäten ausrichten und diese Modalitäten auf natürliche Weise aneinander ausrichten. Modalitäten wie Wärmekarten und Tiefenkarten, die eine starke Korrelation mit Bildern aufweisen, lassen sich leichter anpassen. Nicht-visuelle Modalitäten wie Audio und IMU (Inertial Measurement Unit) weisen schwächere Korrelationen auf. Beispielsweise können bestimmte Geräusche wie das Weinen eines Babys mit verschiedenen visuellen Hintergründen übereinstimmen.
ImageBind zeigt, dass Bildpaarungsdaten ausreichen, um diese sechs Modalitäten miteinander zu verbinden. Das Modell kann Inhalte umfassender erklären und ermöglicht es verschiedenen Modalitäten, miteinander zu „sprechen“ und Verbindungen zwischen ihnen zu finden, ohne sie gleichzeitig zu beobachten. ImageBind kann beispielsweise Audio und Text verknüpfen, ohne sie zusammen zu betrachten. Dadurch können andere Modelle neue Modalitäten „verstehen“, ohne dass eine ressourcenintensive Schulung erforderlich ist.
Die leistungsstarke Skalierungsleistung von ImageBind ermöglicht es diesem Modell, viele Modelle der künstlichen Intelligenz zu ersetzen oder zu verbessern und ihnen die Verwendung anderer Modalitäten zu ermöglichen. Während Make-A-Scene beispielsweise ein Bild mithilfe einer Textaufforderung generieren kann, kann ImageBind es so erweitern, dass ein Bild mithilfe von Audiodaten wie Lachen oder Regengeräuschen generiert wird.
Die überlegene Leistung von ImageBind
Die Analyse von Meta zeigt, dass sich das Skalierungsverhalten von ImageBind mit der Stärke des Bildencoders verbessert. Mit anderen Worten: Die Fähigkeit von ImageBind, Modalitäten auszurichten, skaliert mit der Leistung und Größe des visuellen Modells. Dies deutet darauf hin, dass größere visuelle Modelle für nicht-visuelle Aufgaben wie die Audioklassifizierung von Vorteil sind und dass die Vorteile des Trainings solcher Modelle über Computer-Vision-Aufgaben hinausgehen.
In Experimenten verwendete Meta die Audio- und Tiefenencoder von ImageBind und verglich sie mit früheren Arbeiten zu Zero-Shot-Retrieval- und Audio- und Tiefenklassifizierungsaufgaben.
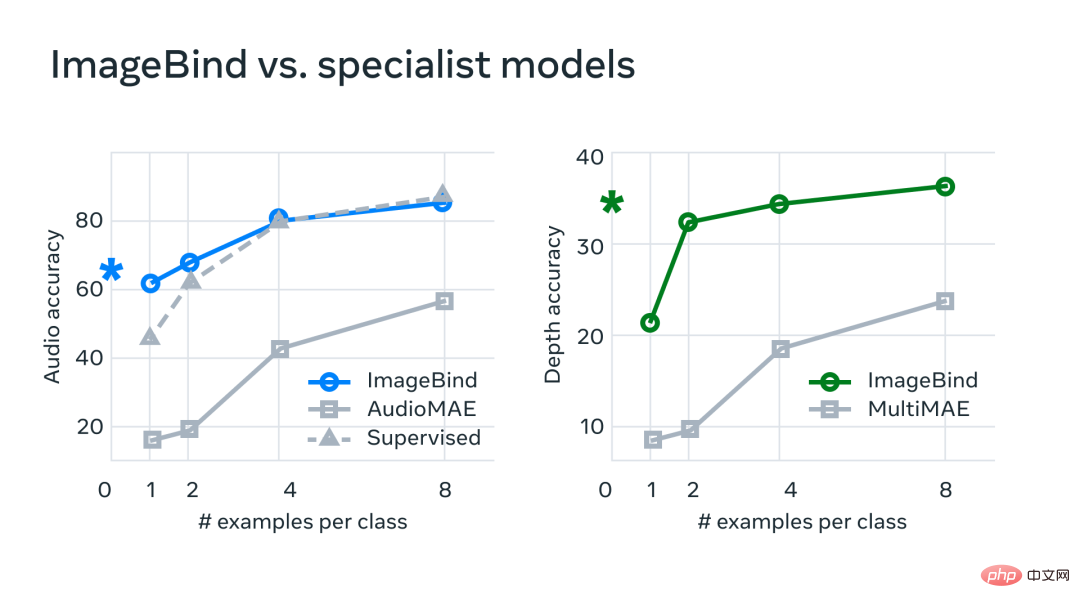
Bei Benchmarks übertrifft ImageBind Expertenmodelle in Audio und Tiefe.
Meta hat herausgefunden, dass ImageBind für Audioaufnahmen mit wenigen Aufnahmen und Tiefenklassifizierungsaufgaben verwendet werden kann und frühere benutzerdefinierte Methoden übertrifft. ImageBind übertrifft beispielsweise das selbstüberwachte AudioMAE-Modell von Meta, das auf Audioset trainiert wurde, sowie das überwachte AudioMAE-Modell, das auf die Audioklassifizierung abgestimmt ist, deutlich.
Darüber hinaus erreicht ImageBind eine neue SOTA-Leistung bei der modalübergreifenden Zero-Shot-Erkennungsaufgabe und übertrifft damit sogar hochmoderne Modelle, die darauf trainiert sind, Konzepte in dieser Modalität zu erkennen.
Das obige ist der detaillierte Inhalt vonDurch die Verwendung von Bildern zur Ausrichtung aller Modalitäten wird ein multisensorisches Open-Source-KI-Basismodell für Meta verwendet, um eine große Vereinheitlichung zu erreichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr