
Heim >Technologie-Peripheriegeräte >KI >Anwendung des erklärbaren Empfehlungsalgorithmus von Alibaba
Anwendung des erklärbaren Empfehlungsalgorithmus von Alibaba

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-10 16:52:061078Durchsuche
1. Einführung in das empfohlene Geschäft
Lassen Sie uns zunächst den geschäftlichen Hintergrund von Alibaba Health und die Analyse der aktuellen Situation vorstellen.
1. Anzeige von Empfehlungsszenarien
Interpretierbare Empfehlungen, zum Beispiel die „Empfehlungen basierend auf den von Ihnen durchsuchten Produkten“ von Dangdang.com (die den Benutzern die Gründe für Empfehlungen mitteilen) und „1000+“ von Taobao „Home Control Collection“ und „2000+ Digital Experts Additional Purchases“ sind allesamt interpretierbare Empfehlungen, die die Gründe für empfohlene Produkte durch die Bereitstellung von Benutzerinformationen erläutern.

Die interpretierbare Empfehlung im Bild links hat eine relativ einfache Implementierungsidee: Die Empfehlung umfasst hauptsächlich zwei Hauptmodule: Rückruf und Sortierung, und Rückruf umfasst häufig Mehrkanalrückruf sowie Benutzerrückruf Verhaltensrückruf Eine gängige Rückrufmethode. Die Produkte, die das Sortiermodul durchlaufen haben, können beurteilt werden. Wenn die Produkte aus dem Benutzerverhaltensrückrufpool stammen, können nach den empfohlenen Produkten entsprechende Empfehlungskommentare hinzugefügt werden. Allerdings weist diese Methode oft eine geringe Genauigkeit auf und liefert den Benutzern nicht viele effektive Informationen.
Im Vergleich dazu kann der entsprechende erklärende Text dem Benutzer mehr Informationen wie Produktkategorieinformationen usw. liefern. Diese Methode erfordert jedoch häufig mehr manuelle Eingriffe von den Funktionen bis zur Textausgabe.
Was Ali Health betrifft, kann es aufgrund der Besonderheiten der Branche zu mehr Einschränkungen kommen als in anderen Szenarien. Relevante Vorschriften sehen vor, dass Textinformationen wie „Hot Sales, Ranking und Empfehlung“ nicht in der Werbung für „drei Produkte und ein Gerät“ (Arzneimittel, Reformkost, Fertignahrung für besondere medizinische Zwecke und medizinische Geräte) erscheinen dürfen. Daher muss Alibaba Health Produkte empfehlen, die auf dem Geschäft von Alibaba Health basieren, unter der Voraussetzung, dass die oben genannten Vorschriften eingehalten werden.
2. Geschäftslage von Ali Health
Ali Health verfügt derzeit über zwei Arten von Geschäften: selbstbetriebene Ali Health-Geschäfte und Ali Health-Industriegeschäfte. Zu den selbst betriebenen Geschäften zählen vor allem große Apotheken, Überseegeschäfte und Pharma-Flagship-Stores, während Alibabas Geschäfte in der Gesundheitsbranche hauptsächlich Flagship-Stores verschiedener Kategorien und private Geschäfte umfassen.
Was die Produkte betrifft, deckt Ali Health hauptsächlich drei Hauptproduktkategorien ab: konventionelle Waren, OTC-Waren und verschreibungspflichtige Medikamente. Als reguläre Produkte gelten Produkte, bei denen es sich nicht um Medikamente handelt. Empfehlungen für reguläre Produkte können mehr Informationen anzeigen, z. B. die Kategorie mit den höchsten Verkäufen, mehr als n+ Menschen haben sie gesammelt/gekauft usw. Empfehlungen für pharmazeutische Produkte wie OTC- und verschreibungspflichtige Medikamente unterliegen entsprechenden Vorschriften, und Empfehlungen müssen stärker mit den Anliegen der Benutzer verknüpft werden, wie z. B. Informationen zu funktionellen Indikationen, Medikationszyklen, Kontraindikationen und anderen Informationen.
Die oben genannten Informationen, die für Arzneimittelempfehlungstexte verwendet werden können, stammen hauptsächlich aus den folgenden Hauptquellen:
- Produktbewertungen (ausgenommen verschreibungspflichtige Medikamente).
- Produktdetailseite.
- Anleitungen und weitere Informationen.
2. Grundlegende Datenvorbereitung
Der zweite Teil stellt hauptsächlich vor, wie die Funktionen des Produkts extrahiert und codiert werden.
1.
Um die Erinnerung an Produkte zu erhöhen, fügen Händler häufig weitere Schlüsselwörter zum Titel hinzu. Daher können Schlüsselwörter über die eigene Titelbeschreibung des Händlers extrahiert werden.
- Bild mit Produktdetails
Mit der OCR-Technologie können Sie basierend auf dem Bild mit Produktdetails umfassendere Produktinformationen wie Produktfunktionen, Hauptverkaufsargumente und Kernverkaufsargumente extrahieren.
- Benutzerbewertungsdaten
Anhand der Benutzerbewertung basierend auf der Emotion einer bestimmten Funktion können die entsprechenden Schlüsselwörter des Produkts gewichtet und entgewichtet werden. Beispielsweise kann für das Huoxiang Zhengqi-Wasser, das „Hitzschlag verhindert“, das entsprechende Gewicht basierend auf der emotionalen Bewertung „Hitzschlag verhindern“ in Benutzerkommentaren verarbeitet werden.
- Arzneimittelanweisungen
Durch die oben genannten mehreren Datenquellen können Schlüsselwörter in den Informationen extrahiert und eine Schlüsselwortdatenbank erstellt werden. Da die extrahierten Schlüsselwörter viele Duplikate und Synonyme enthalten, müssen Synonyme zusammengeführt und mit manueller Überprüfung kombiniert werden, um eine Standardvokabularbibliothek zu erstellen. Schließlich kann eine einzelne Produkt-Tag-Listenbeziehung gebildet werden, die für die anschließende Codierung und Verwendung im Modell verwendet werden kann.
2. Feature-Kodierung
Im Folgenden wird beschrieben, wie Features kodiert werden. Die Feature-Codierung basiert hauptsächlich auf der Word2vec-Methode zur Worteinbettung.
Echte historische Kaufproduktpaardaten können in die folgenden drei Kategorien unterteilt werden:
(1) Gemeinsam durchsuchte Produktpaare: Benutzer klickten innerhalb eines Zeitraums (30 Minuten) Benutzerdefinierte Co-Browsing-Daten.
(2) Gemeinsam gekaufte Produktpaare: Gemeinsam gekaufte Produkte können im Großen und Ganzen als ein Paar gemeinsam gekaufter Produkte zwischen Unterbestellungen unter derselben Hauptbestellung definiert werden die tatsächlichen Bestellgewohnheiten des Benutzers, Definieren Sie die Bestellproduktdaten desselben Benutzers innerhalb eines bestimmten Zeitraums (10 Minuten).
(3) Browse-to-Purchase-Produktpaar: Derselbe Benutzer kaufte Produkt B, nachdem er auf A geklickt hatte. A und B sind gegenseitige Browse-to-Purchase-Daten.
Durch die Analyse historischer Daten wurde festgestellt, dass die Post-Browse-Kaufdaten ein hohes Maß an Ähnlichkeit zwischen den Produkten aufweisen: Oft sind die Kernfunktionen von Arzneimitteln ähnlich und unterscheiden sich nur geringfügig. Sie können als ähnliche Produkte definiert werden Paare, die positive Proben sind.
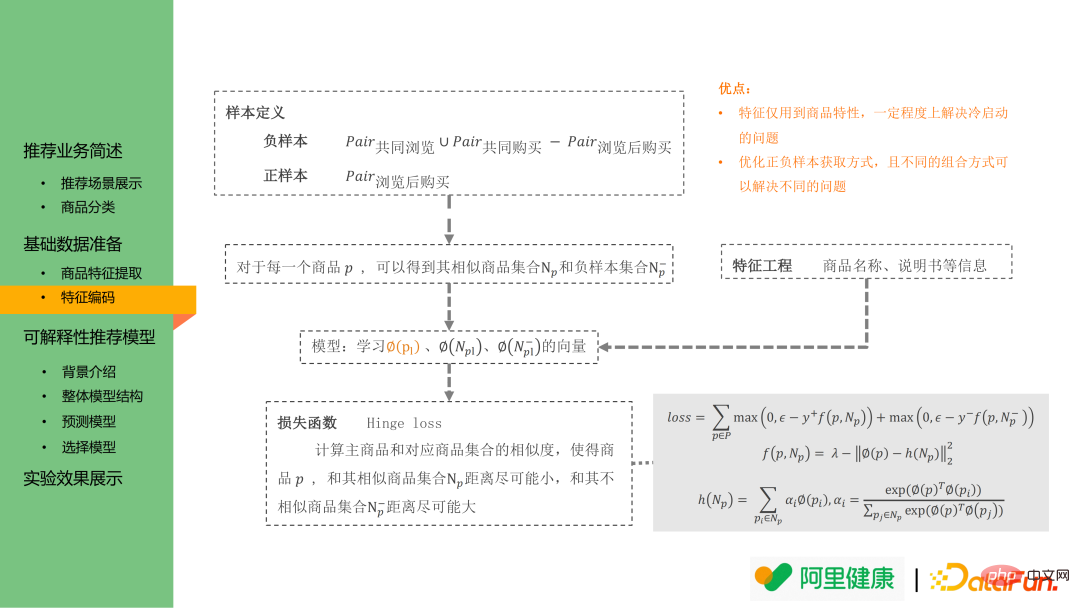
Das Feature-Codierungsmodell basiert immer noch auf der Idee von word2vec: Hauptsächlich in der Hoffnung, dass die Einbettung zwischen ähnlichen Produkten/Labels enger wird. Daher ist die positive Stichprobe bei der Worteinbettung als die oben genannten Produktpaare definiert, die nach dem Durchsuchen gekauft wurden. Die negative Stichprobe ist die Vereinigung der gemeinsam durchsuchten Produktpaare und der gemeinsam gekauften Produktpaare abzüglich der Daten der nach dem Durchsuchen gekauften Produktpaare.
Basierend auf der obigen Definition positiver und negativer Beispielpaare kann mithilfe des Scharnierverlusts die Einbettung jedes Produkts für die i2i-Rückrufphase erlernt werden. In diesem Szenario kann auch die Einbettung von Tags/Schlüsselwörtern erlernt und als Eingabe verwendet werden für Folgemodelle.
Die obige Methode hat zwei Vorteile:
(1) Features verwenden nur Produkteigenschaften, wodurch das Kaltstartproblem bis zu einem gewissen Grad gelöst werden kann: Für neu eingeführte Produkte können Sie deren Titel weiterhin verwenden Produkte Detaillierte Bilder und andere Informationen erhalten entsprechende Tags.
(2) Die Definition von Positiv- und Negativproben kann in verschiedenen Empfehlungsszenarien verwendet werden: Wenn die Positivproben als Paar gemeinsam gekaufter Produkte definiert sind, kann die trainierte Produkteinbettung im Szenario „Kollokationskaufempfehlung“ verwendet werden. 3. Interpretierbares Empfehlungsmodell Interpretierbarkeit Es gibt zwei Hauptkategorien: modellunabhängig.
Es verfügt über integrierte Interpretierbarkeitsmodelle wie das gängige XGBoost usw. Obwohl XGBoost ein End-to-End-Modell ist, basiert seine Funktionsbedeutung auf dem Gesamtdatensatz, der die Anforderungen an personalisierte Empfehlungen nicht erfüllt „Tausende Menschen und Tausende Gesichter“.
Die modellunabhängige Interpretierbarkeit bezieht sich hauptsächlich auf die Rekonstruktion des logischen Simulationsmodells und die Erklärung des Modells, wie z. B. SHAP, das einen einzelnen Fall analysieren und den Grund ermitteln kann, warum der vorhergesagte Wert vom tatsächlichen Wert abweicht. Allerdings ist SHAP komplex und zeitaufwändig und kann die Online-Leistungsanforderungen nach einer Leistungsänderung nicht erfüllen.
Daher ist es notwendig, ein End-to-End-Modell zu erstellen, das die Funktionsbedeutung jeder Stichprobe ausgeben kann.
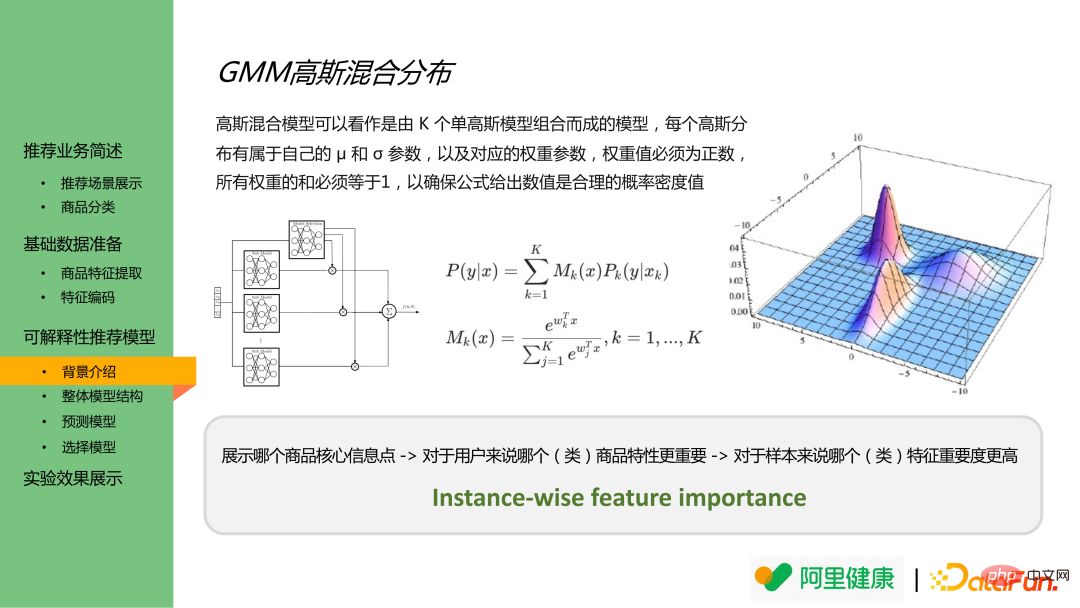
Die Gaußsche Mischungsverteilung ist eine Kombination mehrerer Gaußscher Verteilungen, die den Ergebniswert einer bestimmten Verteilung und die Wahrscheinlichkeit, dass jedes Stichprobenergebnis zu einer bestimmten Verteilung gehört, ausgeben kann. Daher kann eine Analogie gezogen werden, um die klassifizierten Merkmale als Daten mit unterschiedlichen Verteilungen zu verstehen und die Vorhersageergebnisse der entsprechenden Merkmale und die Bedeutung der Vorhersage in den tatsächlichen Ergebnissen zu modellieren.
2. Modellstrukturdiagramm
Das Bild unten ist das Auswahlmodell, das zur Anzeige der Merkmalsbedeutung verwendet werden kann .
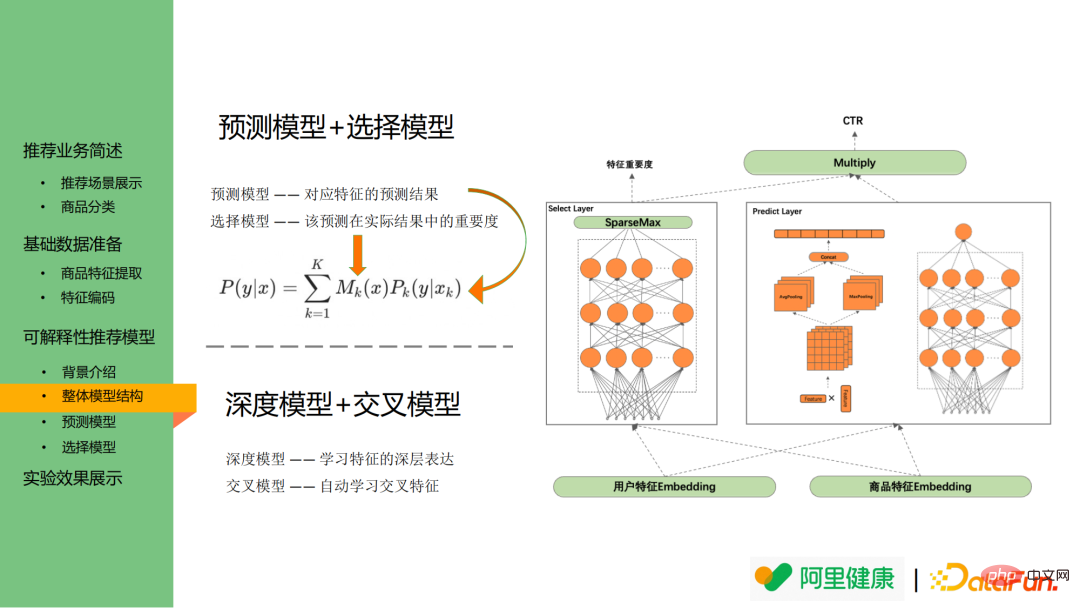
Konkret wird das Vorhersagemodell verwendet, um die Wahrscheinlichkeit einer entsprechenden Feature-Vorhersage/Klicks vorherzusagen, während das Auswahlmodell verwendet wird, um zu erklären, welche Feature-Verteilungen wichtiger sind und als Anzeige von erklärendem Text verwendet werden kann.
3. Vorhersagemodell
Das Bild unten zeigt die Ergebnisse des Vorhersagemodells. Das Vorhersagemodell basiert hauptsächlich auf der Idee von DeepFM und umfasst ein Tiefenmodell und ein Kreuzmodell. Tiefe Modelle werden hauptsächlich zum Erlernen tiefer Darstellungen von Merkmalen verwendet, während Kreuzmodelle zum Erlernen übergreifender Merkmale verwendet werden.
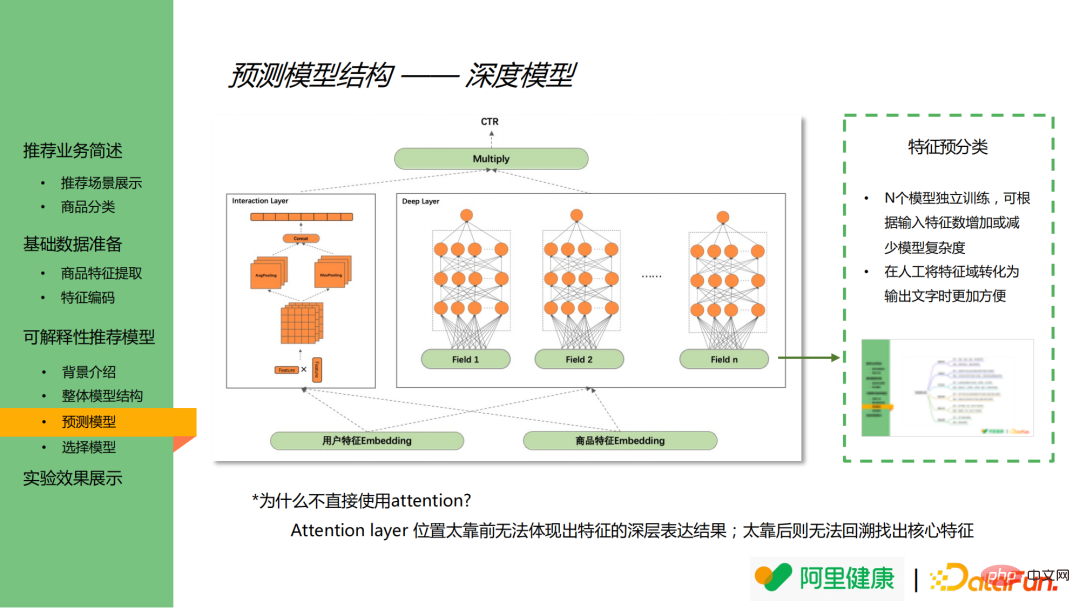
Im Tiefenmodell werden die Funktionen zunächst im Voraus gruppiert (unter der Annahme, dass insgesamt N Gruppen vorhanden sind), z. B. Preis, Kategorie und andere verwandte Funktionen werden in Preis- und Kategoriekategorien (Feldfelder im Bild) zusammengeführt. , und jedes einzelne Modell wird auf den Merkmalssatz trainiert und die Modellergebnisse werden basierend auf dem Merkmalssatz erhalten.
Das Zusammenführen und Gruppieren von Modellen im Voraus hat die folgenden zwei Vorteile:
(1) Durch unabhängiges Training von N Modellen kann die Komplexität des Modells durch Erhöhen oder Verringern der Eingabefunktionen geändert werden, was sich auf die Online-Leistung auswirkt.
(2) Durch das Zusammenführen und Gruppieren von Features kann die Feature-Größe erheblich reduziert werden, wodurch es bequemer wird, die Feature-Domäne manuell in Text umzuwandeln.
Es ist erwähnenswert, dass die Aufmerksamkeitsschicht theoretisch zur Analyse der Merkmalsbedeutung verwendet werden kann. Die Hauptgründe dafür, dass in diesem Modell keine Aufmerksamkeit eingeführt wird, sind jedoch folgende:
(1) Wenn die Aufmerksamkeitsschicht zu weit vorne platziert ist, wird dies der Fall sein kann die Ergebnisse des tiefen Ausdrucks von Merkmalen nicht widerspiegeln;
(2) Wenn die Aufmerksamkeitsebene an einer späteren Position platziert wird, ist es unmöglich, zurückzugehen und die Kernmerkmale zu finden.
Was das Vorhersagemodell betrifft:
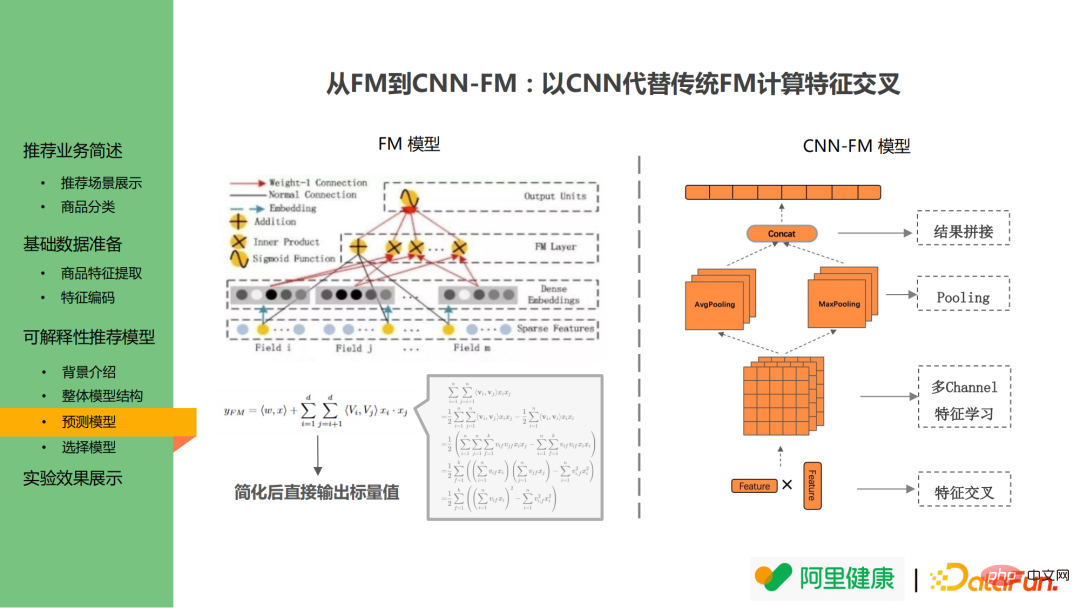
Die Cross-Layer folgt nicht dem FM-Modell, sondern verwendet CNN, um die FM-Struktur in DeepFM zu ersetzen. Das FM-Modell lernt die paarweisen Kreuzergebnisse von Merkmalen und berechnet die paarweisen Kreuzergebnisse direkt durch mathematische Formeln, um eine Dimensionsexplosion während der Berechnung zu vermeiden. Daher wird CNN in das Kreuzmodell eingeführt Ersetzen Sie die ursprüngliche Struktur: N wird verwendet. Die Features werden multipliziert, um eine Feature-Schnittmenge zu erreichen, und dann werden die entsprechenden Operationen von CNN ausgeführt. Dadurch können die Merkmalswerte nach Pooling, Concat und anderen Vorgängen nach der Eingabe zurückverfolgt werden.
Zusätzlich zu den oben genannten Vorteilen hat diese Methode noch einen weiteren Vorteil: Obwohl die aktuelle Version nur ein einzelnes Feature in einen einzigen Beschreibungstext umwandelt, hofft man dennoch, in Zukunft die Konvertierung der Multi-Feature-Interaktion zu erreichen. Wenn ein Benutzer beispielsweise daran gewöhnt ist, preisgünstige Produkte für 100 Yuan zu kaufen, ein Produkt mit einem ursprünglichen Preis von 50.000 Yuan jedoch auf 500 Yuan reduziert wird und der Benutzer das Produkt kauft, kann das Modell ihn daher als definieren Benutzer mit hohen Ausgaben. In der Praxis können Benutzer jedoch aufgrund der doppelten Faktoren von High-End-Marken und hohen Rabatten Bestellungen aufgeben, sodass die Kombinationslogik berücksichtigt werden muss. Für das CNN-FM-Modell kann die Feature-Map später direkt zur Ausgabe der Feature-Kombination verwendet werden.
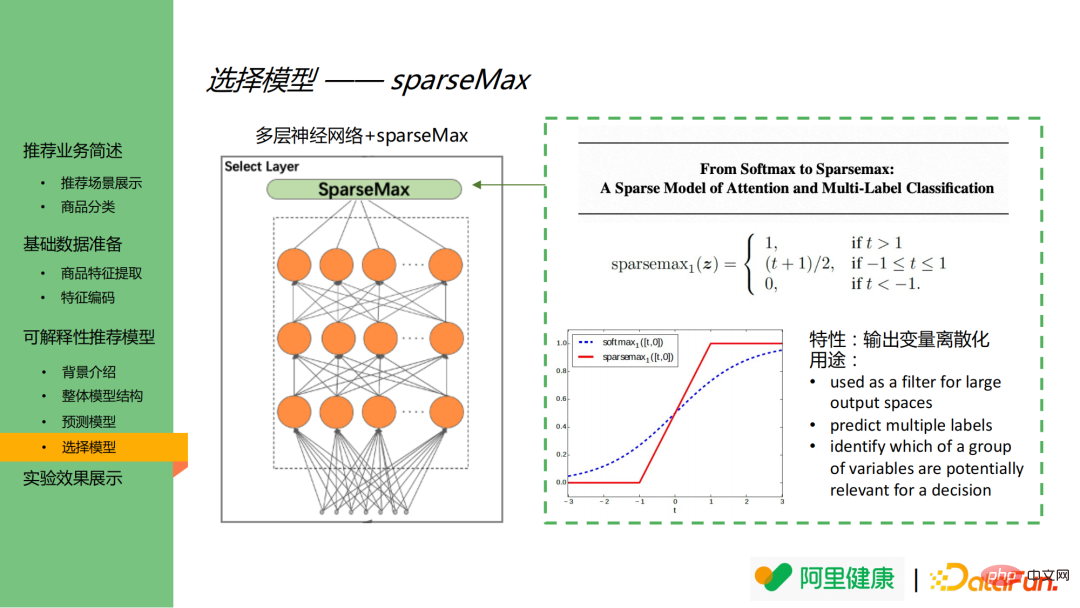
4. Wählen Sie das Modell aus, aus dem sparseMax besteht. Es ist erwähnenswert, dass die Aktivierungsfunktion im Auswahlmodell Sparsemax anstelle des häufigeren Softmax ist. Auf der rechten Seite des Bildes befinden sich die Funktionsdefinition von Sparsemax und die Funktionsvergleichstabelle von Softmax und Sparsemax.Wie aus dem Bild unten rechts ersichtlich ist, weist Softmax Ausgabeknoten mit geringerer Bedeutung immer noch kleinere Werte zu. In diesem Szenario explodiert die Feature-Dimension Es ist leicht, dass sich wichtige Merkmale voneinander unterscheiden. Die Ausgabe zwischen unwichtigen Merkmalen ist nicht unterscheidbar. SparseMax kann die Ausgabe diskretisieren und letztendlich nur die wichtigeren Funktionen ausgeben.
4. Experimentelle Effektanzeige
3. Online-Indikatoren
Da es in der Online-Szene bereits ein CTR-Modell gibt, sollten Sie die neue Version in Betracht ziehen des Algorithmus außer Zusätzlich zur Änderung des Modells wird auch der entsprechende erklärende Text angezeigt und die Variablen werden nicht kontrolliert. Daher wurde der AB-Test in diesem Experiment nicht direkt verwendet. Stattdessen wird der Text der Empfehlungsgründe nur dann angezeigt, wenn die vorhergesagten Werte des Online-CTR-Modells und der neuen Version des Algorithmus höher als ein bestimmter Schwellenwert sind. Nach der Online-Schaltung stieg die PCTR der neuen Version des Algorithmus um 9,13 % und die UCTR um 3,4 %.5. Frage- und Antwortsitzung
F1: Welches Modell wird verwendet, um Standardlexikon zu generieren und Synonyme zusammenzuführen? Wie effektiv ist es? Wie viel mehr manuelle Kalibrierungsarbeit ist erforderlich?
A1: Beim Zusammenführen von Synonymen wird das Modell zum Erlernen von Textstandards und zur Bereitstellung einer Grundvokabularbibliothek verwendet. Tatsächlich nimmt jedoch die manuelle Überprüfung einen größeren Anteil ein. Da im Geschäftsszenario Gesundheit/Pharma höhere Anforderungen an die Genauigkeit des Algorithmus gestellt werden, können Abweichungen bei einzelnen Wörtern zu großen Abweichungen in der tatsächlichen Bedeutung führen. Insgesamt wird der Anteil der manuellen Verifizierung größer sein als der der Algorithmen.
F2: Kann das LIME-Modell als Erklärung für das Empfehlungsmodell verwendet werden?
A2: Ja. Es gibt viele andere Modelle, die erklärbare Empfehlungen geben können. Da der Sharer im Allgemeinen mit GMM vertraut ist, wurde das obige Modell ausgewählt.F3: Wie hängen das Auswahlmodell und das Vorhersagemodell zusammen?
A3: Unter der Annahme, dass es N Gruppen von Merkmalsgruppen gibt, generieren sowohl das Vorhersagemodell als auch das Auswahlmodell 1 * N-dimensionale Vektoren und schließlich Das Vorhersagemodell und die Ergebnisse der ausgewählten Modelle werden multipliziert (multipliziert), um eine Verknüpfung zu erreichen.
F4: Wie erstelle ich interpretierbaren Text?
A4: Derzeit gibt es kein geeignetes maschinelles Lernmodell für die Textgenerierung und es basiert hauptsächlich auf manuellen Methoden . Wenn der Preis das Hauptmerkmal ist, das den Benutzern am Herzen liegt, werden sie sich dafür entscheiden, historische Daten zu analysieren und Produkte mit einem hohen Preis-Leistungs-Verhältnis zu empfehlen. Aber im Moment ist es hauptsächlich Handarbeit. Es besteht die Hoffnung, dass es in Zukunft ein geeignetes Modell für die Textgenerierung geben wird. Angesichts der Besonderheiten des Geschäftsszenarios muss der vom Modell generierte Text jedoch noch manuell überprüft werden.
F5: Was ist die Filterlogik des Modells?
A5: Für die Auswahl der GMM-Neutronenverteilung wird die Verteilung hauptsächlich durch Mk in GMM gelernt und basierend auf den hohen und niedrigen Werten gefiltert von Mk.
F6: Gibt es Attributtypen für die Annotation des Vokabulars?
A6: Erfüllen Sie die Standards für Attributwörter wie Krankheiten, Funktionen, Tabus usw. in Produktbeschreibungen.
F7: Kann interpretierbarer Text die Idee des Slot-Fillings nutzen? Das heißt, verschiedene Vorlagen vorbereiten und je nach Wortgewicht unterschiedliche Vorlagen auswählen?
A7: Ja, die eigentliche Nutzung ist jetzt das Füllen von Slots.
Das war's für das heutige Teilen, vielen Dank an alle.
Das obige ist der detaillierte Inhalt vonAnwendung des erklärbaren Empfehlungsalgorithmus von Alibaba. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr