
Heim >Backend-Entwicklung >Python-Tutorial >Analyse gängiger Operationsbeispiele von ndarray in Python Numpy
Analyse gängiger Operationsbeispiele von ndarray in Python Numpy

- PHPznach vorne
- 2023-05-10 16:25:141414Durchsuche
Vorwort
NumPy (Numerical Python) ist eine Open-Source-Erweiterung für numerisches Rechnen für Python. Dieses Tool kann zum Speichern und Verarbeiten großer Matrizen verwendet werden. Es ist viel effizienter als die verschachtelte Listenstruktur von Python (die auch zur Darstellung von Matrizen verwendet werden kann) und unterstützt darüber hinaus eine große Anzahl dimensionaler Array- und Matrixoperationen bietet außerdem eine große Anzahl mathematischer Funktionsbibliotheken für Array-Operationen.
Numpy verwendet hauptsächlich ndarray, um N-dimensionale Arrays zu verarbeiten. Die meisten Eigenschaften und Methoden in Numpy dienen ndarray, daher ist es sehr wichtig, die allgemeinen Operationen von ndarray in Numpy zu beherrschen!
0 Numpy-Grundlagen
Das Hauptobjekt von NumPy sind isomorphe mehrdimensionale Arrays. Es handelt sich um eine Liste von Elementen (normalerweise Zahlen), die alle vom gleichen Typ sind und durch ein Tupel nicht negativer Ganzzahlen indiziert sind. In NumPy-Dimensionen als Achse bezeichnet.
Im unten gezeigten Beispiel hat das Array 2 Achsen. Die Länge der ersten Achse beträgt 2 und die Länge der zweiten Achse beträgt 3.
[[ 1., 0., 0.], [ 0., 1., 2.]]
1 Eigenschaften von ndarray
1.1 Allgemeine Eigenschaften von ndarray ausgeben
ndarray.ndim: Die Anzahl der Achsen (Dimensionen) des Arrays. In der Python-Welt wird die Anzahl der Dimensionen als Rang bezeichnet.
ndarray.shape: Die Abmessungen des Arrays. Dies ist ein Tupel aus ganzen Zahlen, die die Größe des Arrays in jeder Dimension darstellen. Für eine Matrix mit n Zeilen und m Spalten ist die Form (n,m). Daher ist die Länge des Formtupels der Rang oder die Anzahl der Dimensionen ndim.
ndarray.size: Die Gesamtzahl der Array-Elemente. Dies ist gleich dem Produkt der Formelemente.
ndarray.dtype: Ein Objekt, das den Typ der Elemente im Array beschreibt. Ein dtype kann mit Standard-Python-Typen erstellt oder angegeben werden. Darüber hinaus stellt NumPy eigene Typen zur Verfügung. Zum Beispiel numpy.int32, numpy.int16 und numpy.float64.
ndarray.itemsize: Die Bytegröße jedes Elements im Array. Beispielsweise hat ein Array mit Elementen vom Typ float64 eine Elementgröße von 8 (=64/8), während ein Array vom Typ complex32 eine Elementgröße von 4 (=32/8) hat. Es ist gleich ndarray.dtype.itemsize.
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int64'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
<type 'numpy.ndarray'>2 Der Datentyp von ndarray
Im selben ndarray werden die gleichen Datentypen gespeichert:
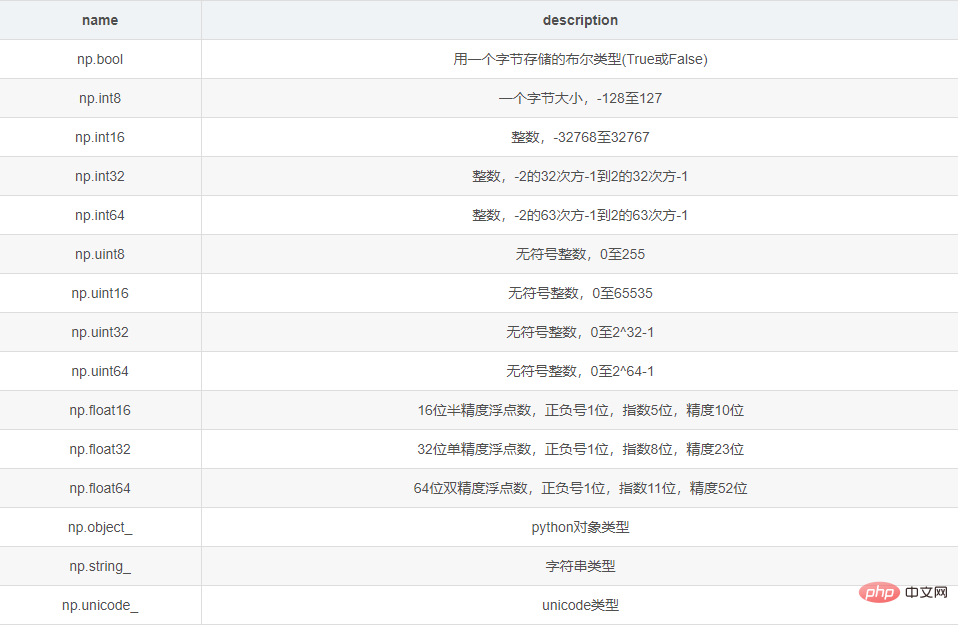
3 Ändern Sie die Form und den Datentyp von ndarray
3.1 Anzeigen und Ändern der Form von ndarray
## ndarray reshape操作 array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.shape) array_a_1 = array_a.reshape((3, 2)) print(array_a_1, array_a_1.shape) # note: reshape不能改变ndarray中元素的个数,例如reshape之前为(2,3),reshape之后为(3,2)/(1,6)... ## ndarray转置 array_a_2 = array_a.T print(array_a_2, array_a_2.shape) ## ndarray ravel操作:将ndarray展平 a.ravel() # returns the array, flattened array([ 1, 2, 3, 4, 5, 6 ]) 输出: [[1 2 3] [4 5 6]] (2, 3) [[1 2] [3 4] [5 6]] (3, 2) [[1 4] [2 5] [3 6]] (3, 2)
3.2 Anzeigen und Ändern des Datentyps von ndarray
astype(dtype[, order, casting, subok, copy]): Ändern Sie den Datentyp in ndarray. Übergeben Sie den Datentyp, der geändert werden muss, und andere Schlüsselwortparameter können ignoriert werden.
array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.dtype) array_a_1 = array_a.astype(np.int64) print(array_a_1, array_a_1.dtype) 输出: [[1 2 3] [4 5 6]] int32 [[1 2 3] [4 5 6]] int64
4 Ndarray-Array-Erstellung
NumPy erstellt Ndarray-Arrays hauptsächlich über die Funktion np.array(). np.array()函数来创建ndarray数组。
>>> import numpy as np >>> a = np.array([2,3,4]) >>> a array([2, 3, 4]) >>> a.dtype dtype('int64') >>> b = np.array([1.2, 3.5, 5.1]) >>> b.dtype dtype('float64')
也可以在创建时显式指定数组的类型:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])也可以通过使用np.random.random函数来创建随机的ndarray数组。
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组。这就减少了数组增长的必要,因为数组增长的操作花费很大。
函数zeros创建一个由0组成的数组,函数 ones创建一个完整的数组,函数empty 创建一个数组,其初始内容是随机的,取决于内存的状态。默认情况下,创建的数组的dtype是 float64 类型的。
>>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # uninitialized, output may vary
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表。
>>> np.arange( 10, 30, 5 ) array([10, 15, 20, 25]) >>> np.arange( 0, 2, 0.3 ) # it accepts float arguments array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
5 ndarray数组的常见运算
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行:
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]])某些操作(例如+=和 *=)会更直接更改被操作的矩阵数组而不会创建新矩阵数组。
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'当使用不同类型的数组进行操作时,结果数组的类型对应于更一般或更精确的数组(称为向上转换的行为)。
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum()
2.5718191614547998
>>> a.min()
0.1862602113776709
>>> a.max()
0.6852195003967595
Sie können beim Erstellen auch explizit den Typ des Arrays angeben:
>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 计算每一列的和
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 计算每一行的和
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
解释:以第一行为例,0=0,1=1+0,3=2+1+0,6=3+2+1+0Sie können auch ein zufälliges ndarray-Array erstellen, indem Sie die Funktion np.random.random verwenden. >>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # 等价于 a[0:6:2] = -1000; 从0到6的位置, 每隔一个设置为-1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, fan 216, 343, 512, 729])
>>> a[ : :-1] # 将a反转
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
Normalerweise sind die Elemente eines Arrays zunächst unbekannt, seine Größe ist jedoch bekannt. Daher bietet NumPy mehrere Funktionen zum „Erstellen von Arrays“ mit anfänglichen Platzhalterinhalten. Dies reduziert die Notwendigkeit einer Array-Vergrößerung, die einen kostspieligen Vorgang darstellt. Die Funktion zeros erstellt ein Array bestehend aus Nullen, die Funktion ones erstellt ein vollständiges Array und die Funktion empty erstellt ein Array, dessen anfänglicher Inhalt besteht ist abhängig vom Zustand des Speichers zufällig. Standardmäßig ist der dtype des erstellten Arrays float64.
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])Um Arrays aus Zahlen zu erstellen, bietet NumPy eine Funktion ähnlich range, die ein Array anstelle einer Liste zurückgibt. >>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])5 Häufige Operationen auf ndarray-Arrays
* elementweise in NumPy-Arrays. Matrixprodukte können mit dem Operator @ (in Python> = 3.5) oder der Funktion oder Methode dot ausgeführt werden: 🎜>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])🎜 Bestimmte Operationen (z. B. += und *=) ändern das Matrix-Array, an dem gearbeitet wird, direkter, ohne ein neues Matrix-Array zu erstellen. 🎜################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]🎜 Beim Arbeiten mit Arrays unterschiedlichen Typs entspricht der Typ des resultierenden Arrays dem allgemeineren oder präziseren Array (ein Verhalten, das als Upcasting bezeichnet wird). 🎜rrreee🎜Viele unäre Operationen, wie zum Beispiel die Berechnung der Summe aller Elemente in einem Array, werden als Methoden der Klasse ndarray implementiert. 🎜rrreee🎜🎜Standardmäßig funktionieren diese Operationen auf einem Array, als wäre es eine Liste von Zahlen, unabhängig von seiner Form. Durch Angabe des Achsenparameters können Sie jedoch Operationen entlang der angegebenen Achse des Arrays anwenden: 🎜🎜rrreee🎜6 Indizierung, Slicing und Iteration von ndarray-Arrays 🎜🎜🎜Eindimensionale 🎜Arrays können indiziert, geschnitten und iteriert werden Like-Listen sind wie andere Python-Sequenztypen. 🎜rrreee🎜🎜Mehrdimensionale🎜Arrays können einen Index pro Achse haben. Diese Indizes werden als durch Kommas getrenntes Tupel angegeben: 🎜>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])7 ndarray数组的堆叠、拆分
几个数组可以沿不同的轴堆叠在一起,例如:np.vstack()函数和np.hstack()函数
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])column_stack()函数将1D数组作为列堆叠到2D数组中。
>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])使用hsplit(),可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
同理,使用vsplit(),可以沿数组的垂直轴拆分数组,方法同上。
################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]Das obige ist der detaillierte Inhalt vonAnalyse gängiger Operationsbeispiele von ndarray in Python Numpy. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!