
Heim >Technologie-Peripheriegeräte >KI >Die Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen
Die Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-10 14:22:071237Durchsuche
In ChatGPT gibt es eine solche Kerntrainingsmethode namens „Reinforcement Learning with Human Feedback (RLHF)“.
Es kann das Modell sicherer machen und die Ausgabeergebnisse besser mit den menschlichen Absichten übereinstimmen.
Jetzt haben Forscher von Google Research und der UC Berkeley herausgefunden, dass die Anwendung dieser Methode auf KI-Malerei die Situation „behandeln“ kann, in der das Bild nicht genau mit der Eingabe übereinstimmt, und der Effekt ist überraschend gut –
kann bis zu 47 erreichen % verbessern.

△ Links ist die stabile Diffusion, rechts ist der verbesserte Effekt
Zu diesem Zeitpunkt scheinen die beiden beliebten Modelle im AIGC-Bereich eine Art „Resonanz“ gefunden zu haben.
Wie verwende ich RLHF für KI-Malerei?
RLHF, der vollständige Name lautet „Reinforcement Learning from Human Feedback“, ist eine Reinforcement-Learning-Technologie, die 2017 von OpenAI und DeepMind gemeinsam entwickelt wurde.
Wie der Name schon sagt, nutzt RLHF die menschliche Bewertung der Modellausgabeergebnisse (d. h. Feedback), um das Modell in LLM direkt zu optimieren und so die „Modellwerte“ besser mit den menschlichen Werten in Einklang zu bringen.
Im AI-Bildgenerierungsmodell kann das generierte Bild vollständig an der Textaufforderung ausgerichtet werden.
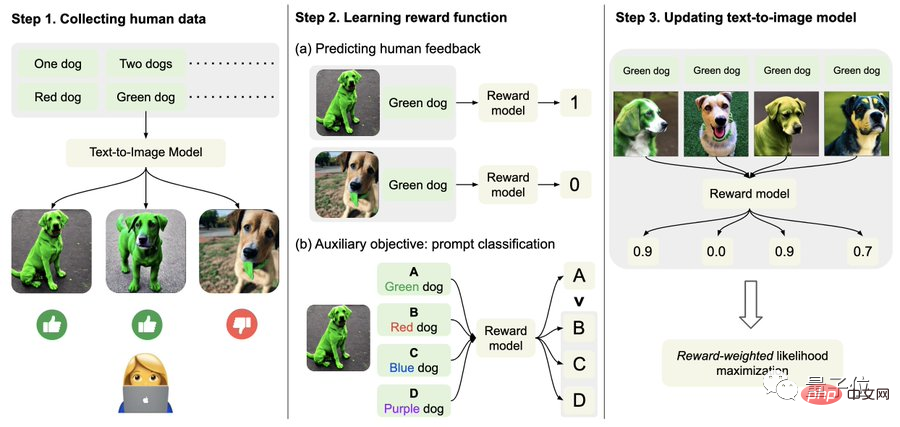
Erfassen Sie insbesondere zunächst menschliche Feedbackdaten.
Hier haben die Forscher insgesamt mehr als 27.000 „Text-Bild-Paare“ generiert und dann einige Menschen gebeten, diese zu bewerten.
Der Einfachheit halber umfassen Textaufforderungen nur die folgenden vier Kategorien, bezogen auf Menge, Farbe, Hintergrund und Mischoptionen, die nur in „gut“, „schlecht“ und „weiß nicht (überspringen)“ unterteilt sind. ".

Zweitens lernen Sie die Belohnungsfunktion.
Dieser Schritt besteht darin, den gerade erhaltenen Datensatz aus menschlichen Bewertungen zu verwenden, um eine Belohnungsfunktion zu trainieren und diese Funktion dann zu verwenden, um die Zufriedenheit des Menschen mit der Modellausgabe vorherzusagen (roter Teil der Formel).
Auf diese Weise weiß das Modell, wie sehr seine Ergebnisse mit dem Text übereinstimmen.
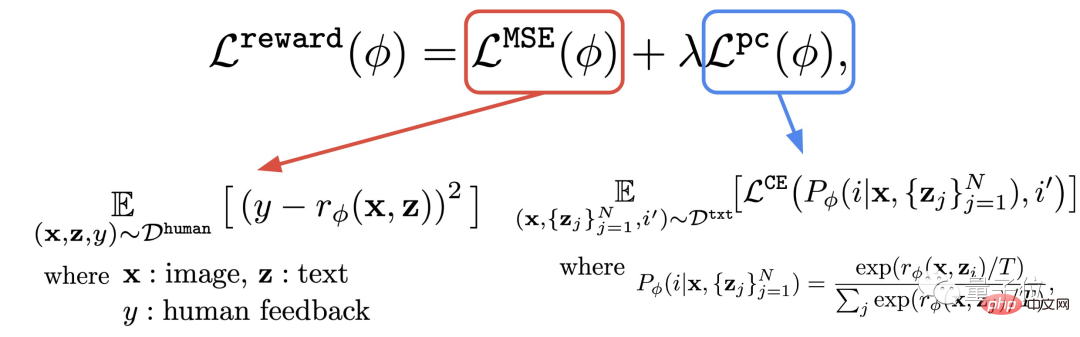
Zusätzlich zur Belohnungsfunktion schlägt der Autor auch eine Hilfsaufgabe vor (blauer Teil der Formel).
Das heißt, nach Abschluss der Bildgenerierung gibt das Modell eine Menge Text aus, von denen jedoch nur einer der Originaltext ist, und lässt das Belohnungsmodell „selbst prüfen“, ob das Bild mit dem Text übereinstimmt.
Dieser umgekehrte Vorgang kann den Effekt einer „doppelten Versicherung“ bewirken (er kann das Verständnis von Schritt 2 im Bild unten erleichtern).
Am Ende geht es um die Feinabstimmung.
Das heißt, das Text-Bild-Generierungsmodell wird durch belohnungsgewichtete Wahrscheinlichkeitsmaximierung aktualisiert (das erste Element der Formel unten).
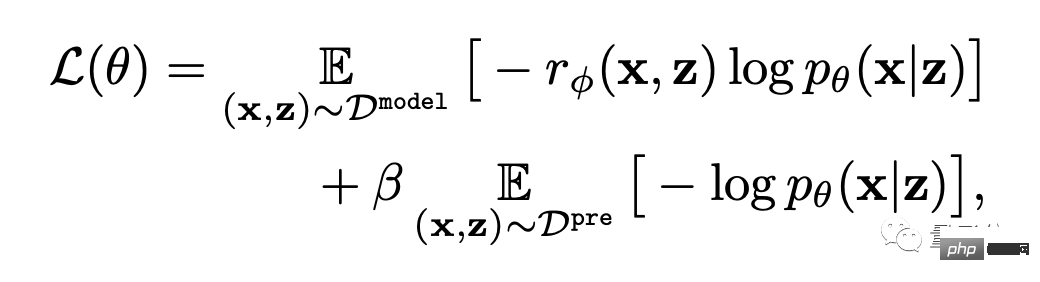
Um eine Überanpassung zu vermeiden, minimierte der Autor den NLL-Wert (den zweiten Term der Formel) im Datensatz vor dem Training. Dieser Ansatz ähnelt InstructionGPT (dem „direkten Vorgänger“ von ChatGPT).
Der Effekt nahm um 47 % zu, aber die Klarheit sank um 5 %
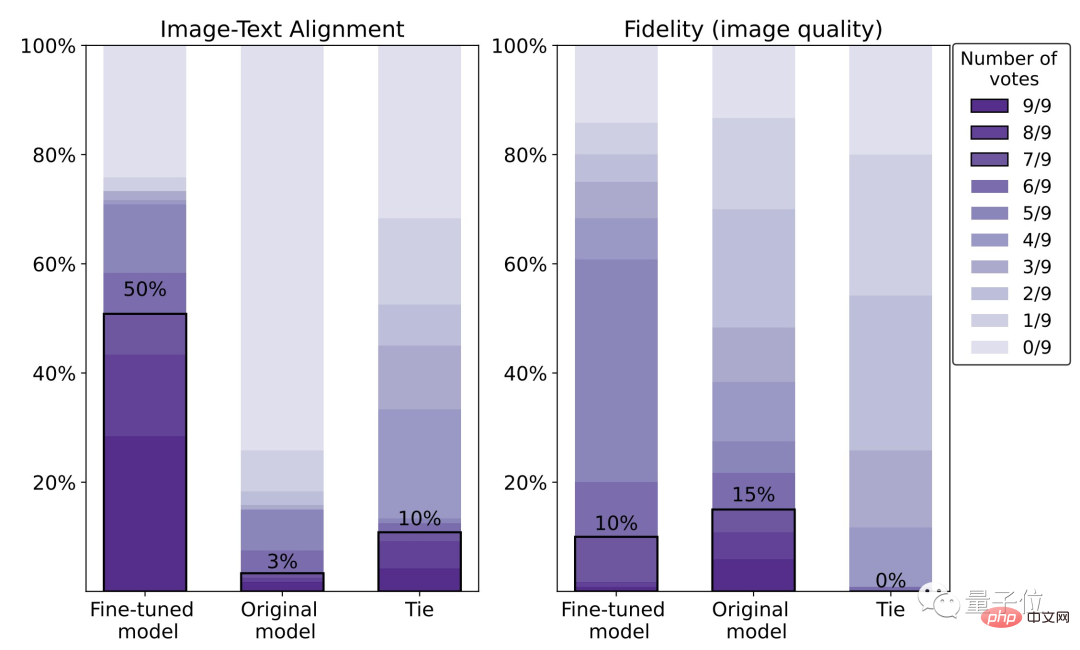
Wie in der folgenden Reihe von Effekten gezeigt, kann das mit RLHF fein abgestimmte Modell im Vergleich zur ursprünglichen Stable Diffusion:
(1) Erhalten Sie die „“ im Text korrekter „Zwei“ und „grün“; es kann zu einem „röteren“ Ergebnis führen.
Den spezifischen Daten zufolge beträgt die menschliche Zufriedenheitsrate des fein abgestimmten Modells 50 %, was einer Verbesserung von 47 % im Vergleich zum Originalmodell (3 %) entspricht.
 Der Preis ist jedoch ein Verlust von 5 % Bildschärfe.
Der Preis ist jedoch ein Verlust von 5 % Bildschärfe.
Auf dem Bild unten können wir auch deutlich erkennen, dass der Wolf auf der rechten Seite offensichtlich unschärfer ist als der auf der linken Seite:
In diesem Zusammenhang gab der Autor an, dass die Verwendung eines größeren menschlichen Bewertungsdatensatzes und Eine bessere Optimierungsmethode (RL) kann diese Situation verbessern.
Über den Autor
 Für diesen Artikel gibt es insgesamt 9 Autoren.
Für diesen Artikel gibt es insgesamt 9 Autoren.

Als Google-KI-Forscherin Kimin Lee, Ph.D. vom Korea Institute of Science and Technology, forschte sie als Postdoktorandin an der UC Berkeley.

Es gibt drei chinesische Autoren:
Liu Hao, ein Doktorand an der UC Berkeley, dessen Hauptforschungsinteresse Feedback-Neuronale Netze sind.
Du Yuqing ist Doktorand an der UC Berkeley. Seine Hauptforschungsrichtung sind unbeaufsichtigte Reinforcement-Learning-Methoden.
Shixiang Shane Gu (Gu Shixiang), der korrespondierende Autor, studierte bei Hinton, einem der drei Giganten, für seinen Bachelor-Abschluss und schloss sein Studium mit der Promotion an der Universität Cambridge ab.

△ Gu Shixiang
Erwähnenswert ist, dass er beim Schreiben dieses Artikels noch Googler war, nun aber zu OpenAI gewechselt ist, wo er direkt dem Verantwortlichen von ChatGPT unterstellt ist.
Papieradresse:
https://arxiv.org/abs/2302.12192
Referenzlink: [1]https://www.php.cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2 ] https://openai.com/blog/instruction-following/
Das obige ist der detaillierte Inhalt vonDie Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr