
Heim >Technologie-Peripheriegeräte >KI >Mikroservice-Governance des WeChat NLP-Algorithmus
Mikroservice-Governance des WeChat NLP-Algorithmus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-10 11:52:051295Durchsuche

1. Überblick
Musk erwarb Twitter, war aber mit seiner Technologie unzufrieden. Ich denke, die Homepage ist zu langsam, da es über 1000 RPCs gibt. Ohne darauf einzugehen, ob die von Musk genannten Gründe richtig sind, lässt sich erkennen, dass ein vollständiger Dienst, der Benutzern im Internet bereitgestellt wird, eine große Anzahl von Microservice-Aufrufen hinter sich haben wird.
Am Beispiel der WeChat-Leseempfehlung ist sie in zwei Phasen unterteilt: Abrufen und Sortieren.
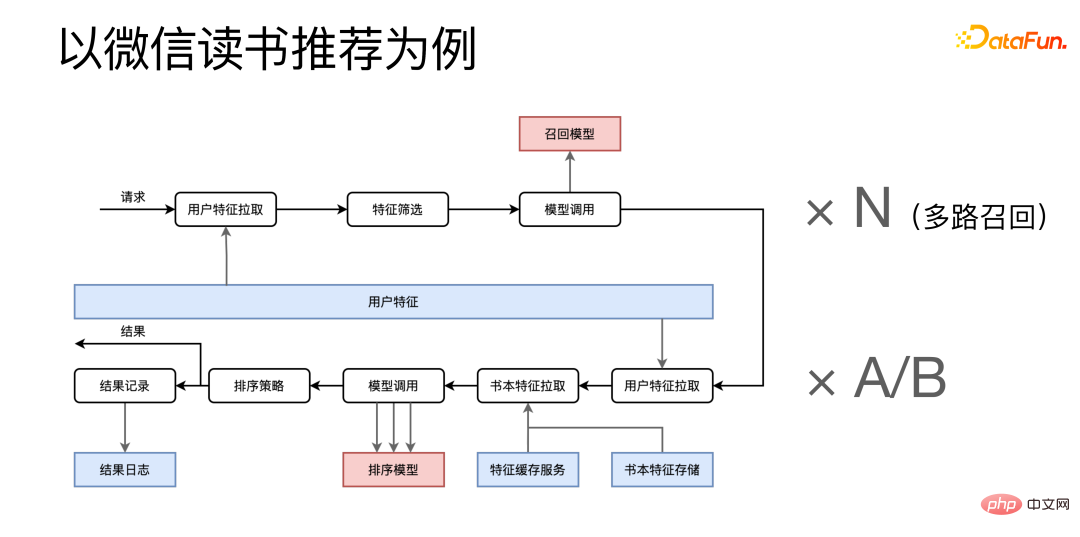
Nachdem die Anfrage eingegangen ist, werden zunächst Funktionen aus dem Benutzer-Feature-Microservice abgerufen, die Features zur Funktionsüberprüfung zusammengefasst und dann verwandte Microservices aufgerufen und abgerufen von An N, da wir einen Mehrkanal-Rückruf haben, werden viele ähnliche Rückrufprozesse gleichzeitig ausgeführt. Das Folgende ist die Sortierphase, in der relevante Features aus mehreren Feature-Microservices abgerufen werden und der Sortiermodelldienst nach der Kombination mehrmals aufgerufen wird. Nach Erhalt des Endergebnisses wird einerseits das Endergebnis an den Aufrufer zurückgegeben und andererseits werden einige Protokolle des Prozesses zur Archivierung an das Protokollsystem gesendet.
Leseempfehlungen machen nur einen sehr kleinen Teil der gesamten WeChat-Lese-APP aus. Es ist ersichtlich, dass selbst ein relativ kleiner Dienst eine große Anzahl von Microservice-Aufrufen hat. Wenn man genauer hinschaut, kann man davon ausgehen, dass das gesamte WeChat Reading-System eine große Anzahl von Microservice-Aufrufen haben wird.
Welche Probleme bringt eine Vielzahl von Microservices mit sich?
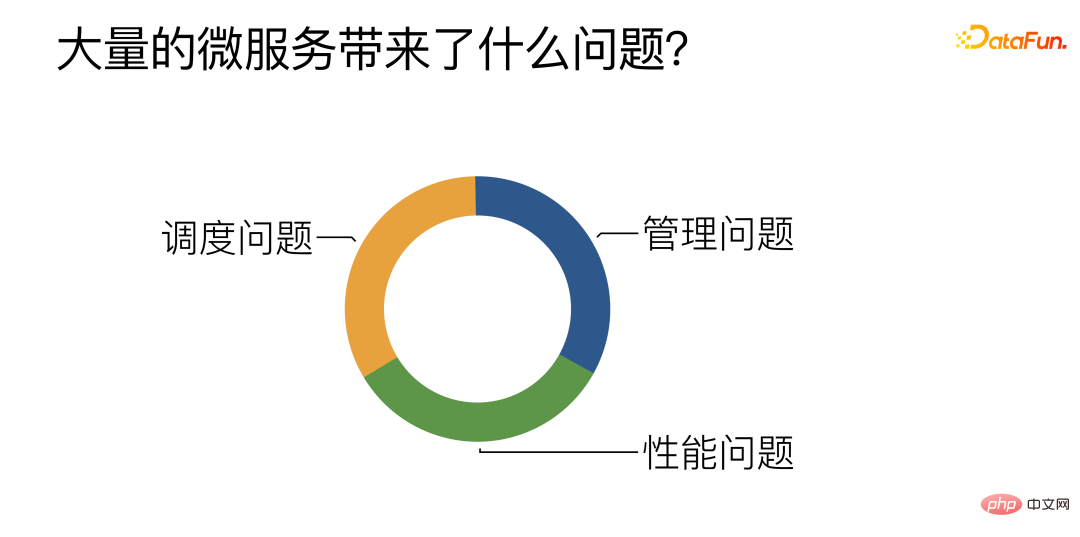
Laut Zusammenfassung der täglichen Arbeit gibt es hauptsächlich drei Herausforderungen:
① Management: Hauptsächlich darum, wie man effizient verwaltet, entwickelt und bereitstellt ein großes Anzahl der Algorithmus-Microservices.
② Leistung: Versuchen Sie, die Leistung von Microservices, insbesondere Algorithmus-Microservices, zu verbessern.
③ Planung: So erreichen Sie einen effizienten und angemessenen Lastausgleich zwischen mehreren ähnlichen Algorithmus-Microservices.
2. Verwaltungsprobleme bei Microservices
1. Entwicklung und Bereitstellung: Das CI/CD-System bietet automatische Verpackung und Bereitstellung Pipeline reduziert den Druck von Algorithmenstudenten, Algorithmus-Microservices zu entwickeln. Jetzt müssen Algorithmenstudenten nur noch eine Python-Funktion schreiben, und die Pipeline ruft automatisch eine Reihe vorab geschriebener Microservice-Vorlagen ab und füllt die von Algorithmenstudenten entwickelten Funktionen schnell aus Mikrodienste. ?? Wir erkennen aktiv den Grad des Rückstands oder der Inaktivität einer bestimmten Art von Aufgaben. Wenn der Rückstand einen bestimmten Schwellenwert überschreitet, wird der Erweiterungsvorgang automatisch ausgelöst ebenfalls ausgelöst werden.
Der dritte Punkt ist wie man eine große Anzahl von Microservices zusammen organisiert, um einen vollständigen Oberschichtdienst aufzubauen. Unsere Dienste der oberen Schicht werden durch DAG repräsentiert. Jeder Knoten von DAG stellt einen Aufruf an den Mikrodienst dar, und jede Kante repräsentiert die Datenübertragung zwischen Diensten. Für DAG wurde außerdem speziell eine DSL (Domain Specific Language) entwickelt, um DAG besser zu beschreiben und zu strukturieren. Und wir haben eine Reihe webbasierter Tools rund um DSL entwickelt, mit denen sich übergeordnete Dienste direkt im Browser visuell erstellen, einem Stresstest unterziehen und bereitstellen lassen. Der vierte Punkt Leistungsüberwachung besteht darin, das Problem zu lokalisieren, wenn ein Problem mit dem Dienst der oberen Schicht vorliegt. Für jede externe Anfrage gibt es einen vollständigen Tracking-Satz, mit dem der Zeitverbrauch der Anfrage in jedem Mikrodienst überprüft und so Leistungsengpässe im System ermittelt werden können. Im Allgemeinen wird die Leistungszeit des Algorithmus für das Deep-Learning-Modell aufgewendet. Ein großer Teil des Fokus der Optimierung der Leistung der Algorithmus-Microservices liegt auf Optimieren Sie die Tiefe des Lernmodells und schließen Sie die Leistung ab. Sie können ein dediziertes Infer-Framework wählen oder Deep-Learning-Compiler, Kernel-Optimierung usw. ausprobieren. Für diese Lösungen sind wir der Meinung, dass sie nicht unbedingt notwendig sind. In vielen Fällen verwenden wir direkt Python-Skripte, um online zu gehen, und können dennoch eine mit C++ vergleichbare Leistung erzielen. Der Grund dafür, dass dies nicht unbedingt erforderlich ist, liegt darin, dass diese Lösungen zwar eine bessere Leistung bringen können, eine gute Leistung jedoch nicht die einzige Anforderung an den Dienst ist. Es gibt eine bekannte 80/20-Regel, die in Bezug auf Menschen und Ressourcen beschrieben wird, das heißt, 20 % der Menschen werden 80 % der Ressourcen erwirtschaften. Mit anderen Worten, 20 % der Menschen werden 80 % der Beiträge bereitstellen . Dies gilt auch für Microservices. Wir können Mikrodienste in zwei Kategorien einteilen. Erstens sind ausgereifte und stabile Dienste nicht zahlreich und nehmen möglicherweise nur 20 % ein, tragen aber 80 % des Datenverkehrs. Der andere Typ sind einige experimentelle Dienste oder Dienste, die sich noch in der Entwicklung und Iteration befinden. Es gibt viele davon, die 80 % ausmachen, aber nur 20 % des Datenverkehrs ausmachen. Der wichtige Punkt ist, dass es häufig Änderungen gibt Iterationen, daher wird es auch eine starke Nachfrage nach schneller Entwicklung und Markteinführung geben. Die zuvor genannten Methoden wie das Infer-Framework, die Kernel-Optimierung usw. erfordern zwangsläufig zusätzliche Entwicklungskosten. Ausgereifte und stabile Dienste eignen sich für diese Art von Verfahren nach wie vor sehr gut, da es relativ wenige Änderungen gibt und sie nach einer Optimierung lange Zeit genutzt werden können. Andererseits verursachen diese Dienste eine große Menge an Datenverkehr und eine kleine Leistungsverbesserung kann große Auswirkungen haben, sodass es sich lohnt, in die Kosten zu investieren. Aber diese Methoden eignen sich nicht so gut für experimentelle Dienste, da experimentelle Dienste häufig aktualisiert werden und wir nicht für jedes neue Modell neue Optimierungen vornehmen können. Für experimentelle Dienste haben wir einen selbst entwickelten Python-Interpreter entwickelt – PyInter für GPU-Hybrid-Bereitstellungsszenarien. Es ist möglich, mit Python-Skripten direkt online zu gehen, ohne Code zu ändern, und gleichzeitig kann die Leistung der von C++ nahe kommen oder diese sogar übertreffen. 3. Microservice-Organisation: Turing kompletter DAG / DSL / automatischer Stresstest / automatische Bereitstellung
4. Leistungsüberwachung: Trace-System
3. Leistungsprobleme, mit denen Microservices konfrontiert sind
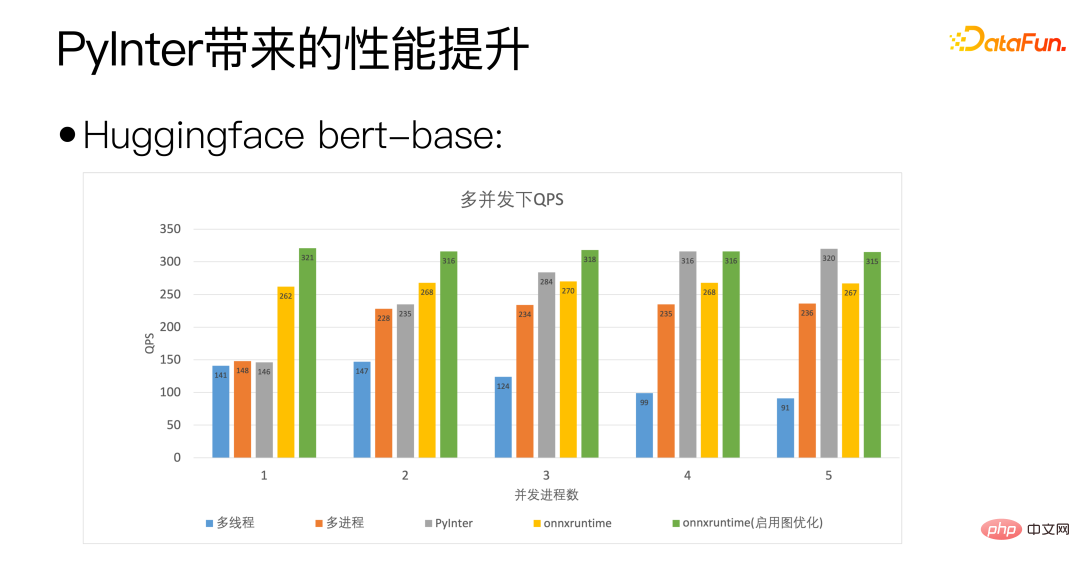
Wir verwenden die Bert-Basis von Huggingface als Standard. Die horizontale Achse der obigen Abbildung ist die Anzahl der gleichzeitigen Prozesse und gibt die Anzahl der von uns bereitgestellten Modellkopien an PyInter hat eine höhere Anzahl an Modellkopien. In vielen Fällen übertrifft QPS sogar onnxruntime.
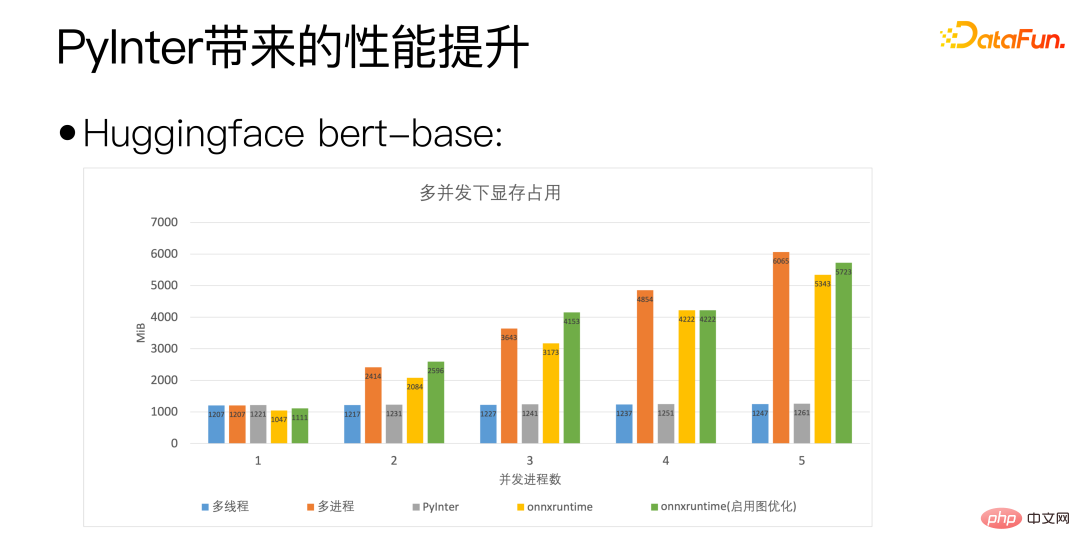
Anhand der obigen Abbildung können Sie sehen, dass PyInter die Videospeichernutzung im Vergleich zu Multiprozess und ONNXRuntime um fast 80 % reduziert, wenn die Anzahl der Modellkopien groß ist. Bitte beachten Sie dies Unabhängig vom Modell Unabhängig von der Anzahl der Kopien bleibt die Speichernutzung von PyInter unverändert.
Kehren wir zur grundlegenderen Frage zurück: Ist Python wirklich langsam?
Ja, Python ist wirklich langsam, aber Python ist nicht langsam, wenn es um wissenschaftliche Berechnungen geht, denn der eigentliche Ort für Berechnungen ist nicht Python, sondern spezielle Berechnungen wie MKL oder cuBLAS Library.
Wo liegt also der größte Leistungsengpass von Python? Hauptsächlich aufgrund der GIL (Global Interpreter Lock) unter Multithreading, die dazu führt, dass unter Multithreading nur ein Thread gleichzeitig arbeitet. Diese Form des Multithreading kann für IO-intensive Aufgaben hilfreich sein, macht jedoch für die Modellbereitstellung, die ebenso rechenintensiv ist, keinen Sinn.
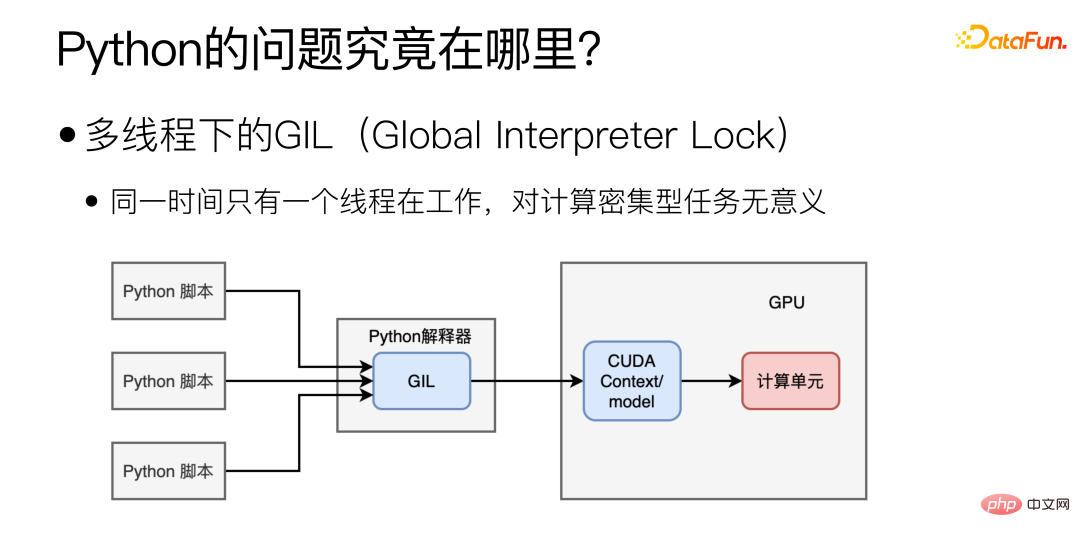
Sollte ich es in mehr ändern? Prozess kann das Problem lösen?
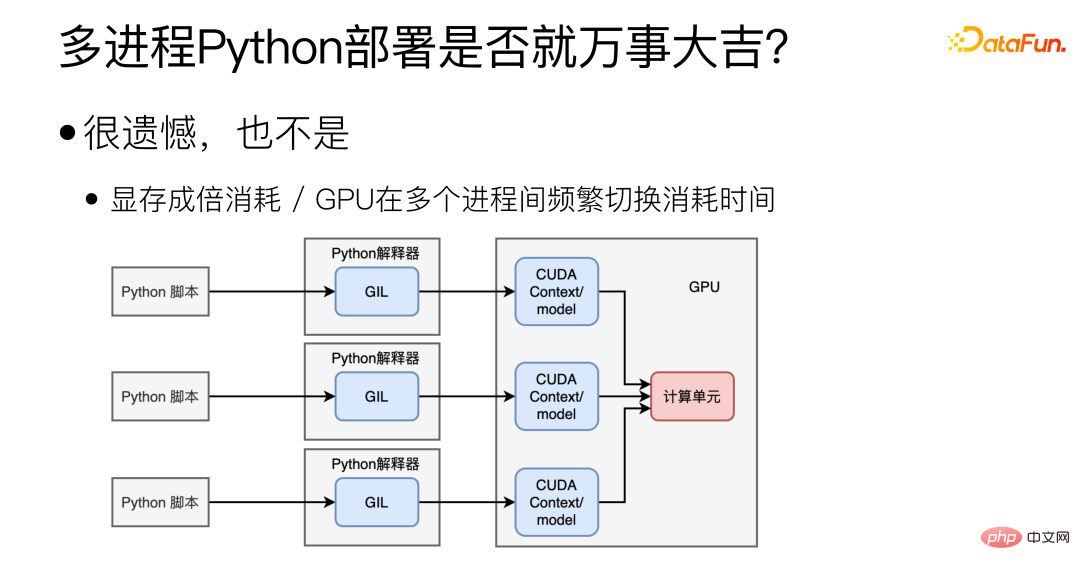
Eigentlich nicht, Multiprozess ist zwar Es kann das Problem von GIL lösen, wird aber auch andere neue Probleme mit sich bringen. Erstens ist es schwierig, den CUDA-Kontext/das CUDA-Modell zwischen mehreren Prozessen zu teilen, was zu einer großen Verschwendung von Videospeicher führt. In diesem Fall können nicht mehrere Modelle auf einer Grafikkarte bereitgestellt werden. Das zweite ist das Problem der GPU. Die GPU kann nur die Aufgaben eines Prozesses gleichzeitig ausführen, und das häufige Umschalten der GPU zwischen mehreren Prozessen kostet ebenfalls Zeit.
Für Python-Szenarien ist der ideale Modus wie unten dargestellt:
#🎜 🎜#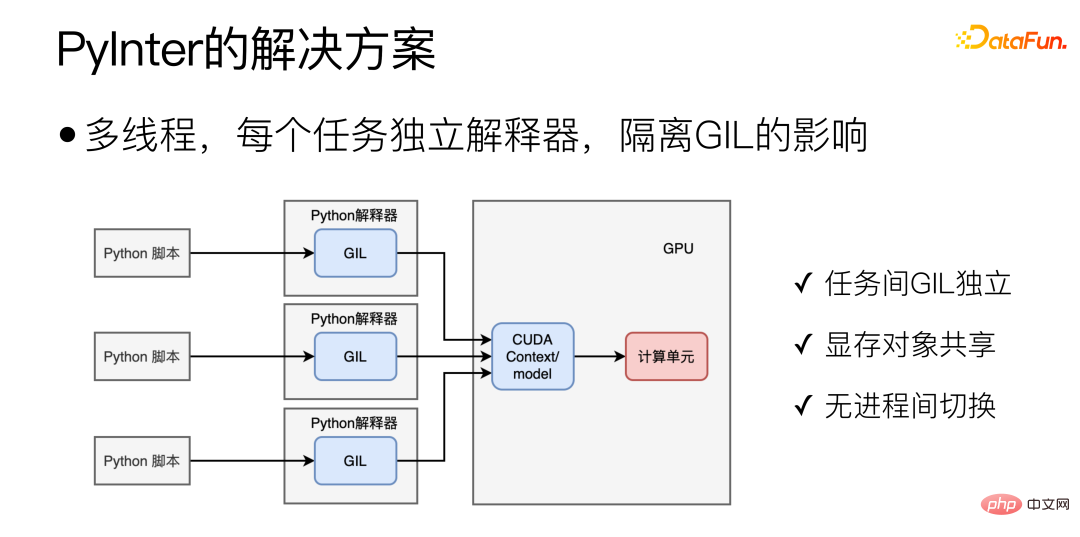
Der Schlüssel zur Implementierung von PyInter ist die Isolierung dynamischer Bibliotheken innerhalb des Prozesses, die Isolierung des Interpreters, was im Wesentlichen die Isolierung dynamischer Bibliotheken ist haben einen selbst entwickelten dynamischen Bibliothekslader entwickelt, der dlopen ähnelt, jedoch „isolierte“ und „gemeinsam genutzte“ dynamische Bibliothekslademethoden unterstützt. Laden im „Isolations“-Modus Dynamische Bibliotheken werden in verschiedene virtuelle Räume geladen, und verschiedene virtuelle Räume können sich gegenseitig nicht sehen. Wenn die dynamische Bibliothek im „Shared“-Modus geladen wird, kann die dynamische Bibliothek überall im Prozess gesehen und verwendet werden, auch innerhalb jedes virtuellen Raums.
Laden Sie die Python-Interpreter-bezogenen Bibliotheken im „isolierten“ Modus und laden Sie dann die Cuda-bezogenen Bibliotheken im „gemeinsam genutzten“ Modus , so Dies erreicht die gemeinsame Nutzung von Videospeicherressourcen und isoliert gleichzeitig den Interpreter. 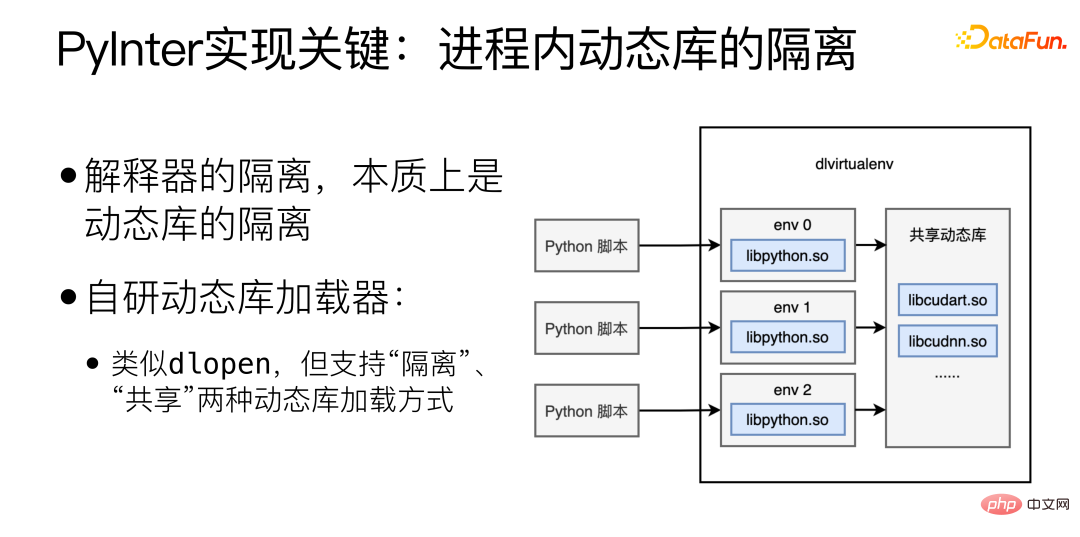
4. Planungsprobleme, mit denen Microservices konfrontiert sind Jeder Microservice spielt die gleiche Bedeutung und Rolle, also wie kann ein dynamischer Lastausgleich zwischen mehreren Microservices erreicht werden? Der dynamische Lastausgleich ist wichtig, aber es ist fast unmöglich, ihn perfekt durchzuführen.
Warum ist dynamischer Lastausgleich wichtig? Die Gründe sind wie folgt:
(1) Unterschiede in der Maschinenhardware (CPU / GPU);
(2) Längenunterschied anfordern (2 Wörter übersetzen / 200 Wörter übersetzen);
#🎜 🎜# (3) Unter Random Load Balancing ist der Long-Tail-Effekt offensichtlich:
① P99/P50 Der Unterschied kann bis zum 10-fachen betragen. Der Unterschied kann bis zum 20-fachen betragen.
(4) Bei Microservices ist der Long Tail der Schlüssel zur Bestimmung der Gesamtgeschwindigkeit.
Die für die Bearbeitung einer Anfrage benötigte Zeit variiert stark und Unterschiede in der Rechenleistung, der Anfragelänge usw. wirken sich auf die benötigte Zeit aus . Da die Anzahl der Microservices zunimmt, wird es immer einige Microservices geben, die den Long Tail erreichen, was sich auf die Reaktionszeit des gesamten Systems auswirkt.
Warum ist der dynamische Lastausgleich so schwer zu perfektionieren?
Option 1: Benchmark auf allen Maschinen ausführen.
Diese Lösung ist nicht „dynamisch“ und kann den Unterschied in der Anfragelänge nicht bewältigen. Und es gibt keinen perfekten Maßstab, der die Leistung widerspiegeln kann. Verschiedene Maschinen reagieren unterschiedlich auf verschiedene Modelle.
Option 2: Erhalten Sie den Status jeder Maschine in Echtzeit und senden Sie die Aufgabe an die Maschine mit der geringsten Auslastung.
Diese Lösung ist intuitiver, aber das Problem besteht darin, dass es in einem verteilten System keine echten „Echtzeit“-Informationen gibt wird von einer Maschine auf eine andere übertragen. Der Übergang zu einer anderen Maschine wird definitiv einige Zeit dauern, und während dieser Zeit kann sich der Zustand der Maschine ändern. Beispielsweise ist zu einem bestimmten Zeitpunkt eine bestimmte Worker-Maschine am untätigsten, und mehrere Master-Maschinen, die für die Aufgabenverteilung verantwortlich sind, erkennen dies alle, sodass sie alle diesem am meisten untätigen Worker Aufgaben zuweisen, und dieser am meisten untätige Worker wird sofort zu This is the berühmter Gezeiteneffekt beim Lastausgleich.
Option 3: Pflegen Sie eine global eindeutige Aufgabenwarteschlange. Alle für die Aufgabenverteilung zuständigen Master senden Aufgaben an die Warteschlange aus der Warteschlange.
Bei dieser Lösung kann die Aufgabenwarteschlange selbst zu einem Einzelpunkt-Engpass werden, was eine horizontale Erweiterung erschwert.
Der grundlegende Grund, warum der dynamische Lastausgleich schwer zu perfektionieren ist, liegt darin, dass die Übertragung von Informationen Zeit braucht #🎜🎜 #, wenn ein Zustand beobachtet wird, muss dieser Zustand „bestanden“ sein. Auf Youtube gibt es ein Video, das ich jedem empfehlen kann: „Load Balancing is Impossible“ https://www.youtube.com/watch?v=kpvbOzHUakA.
In Bezug auf den dynamischen Lastausgleichsalgorithmus wählt der Power of 2 Choices-Algorithmus zufällig zwei Arbeiter aus und weist dem untätigeren Arbeiter Aufgaben zu. Dieser Algorithmus ist die Grundlage für den dynamischen Entzerrungsalgorithmus, den wir derzeit verwenden. Beim Power of 2 Choices-Algorithmus gibt es jedoch zwei große Probleme: Erstens muss vor der Zuweisung jeder Aufgabe der Leerlaufstatus des Workers abgefragt werden, wodurch ein weiterer RTT hinzugefügt wird. Außerdem ist es möglich, dass die beiden zufällig zugewiesen werden Ausgewählte Arbeiter sind zufällig sehr beschäftigt. Um diese Probleme zu lösen, haben wir Verbesserungen vorgenommen.
Nach Verbesserung
Der Algorithmus von 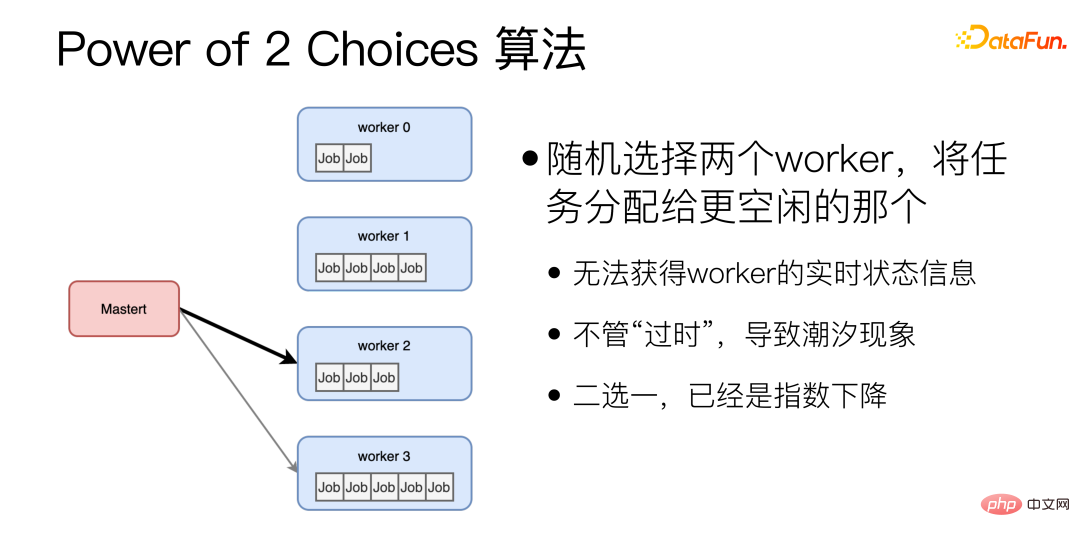 ist Joint-Idle-Queue.
ist Joint-Idle-Queue.
Wir haben der Master-Maschine zwei Komponenten hinzugefügt: Idle-Queue und Amnesia . Idle-Queue wird verwendet, um aufzuzeichnen, welche Worker derzeit inaktiv sind. Amnesia zeichnet auf, welche Worker in der letzten Zeit Heartbeat-Pakete an sich selbst gesendet haben. Wenn ein Worker längere Zeit kein Heartbeat-Paket gesendet hat, vergisst Amnesia dies nach und nach. Jeder Worker meldet regelmäßig, ob er inaktiv ist. Der inaktive Worker wählt einen Master aus, der seine Inaktivität meldet, und meldet die Nummer, die er verarbeiten kann. Der Worker verwendet bei der Auswahl des Masters auch den Power-of-2-Choices-Algorithmus. Für andere Master meldet der Worker Heartbeat-Pakete.
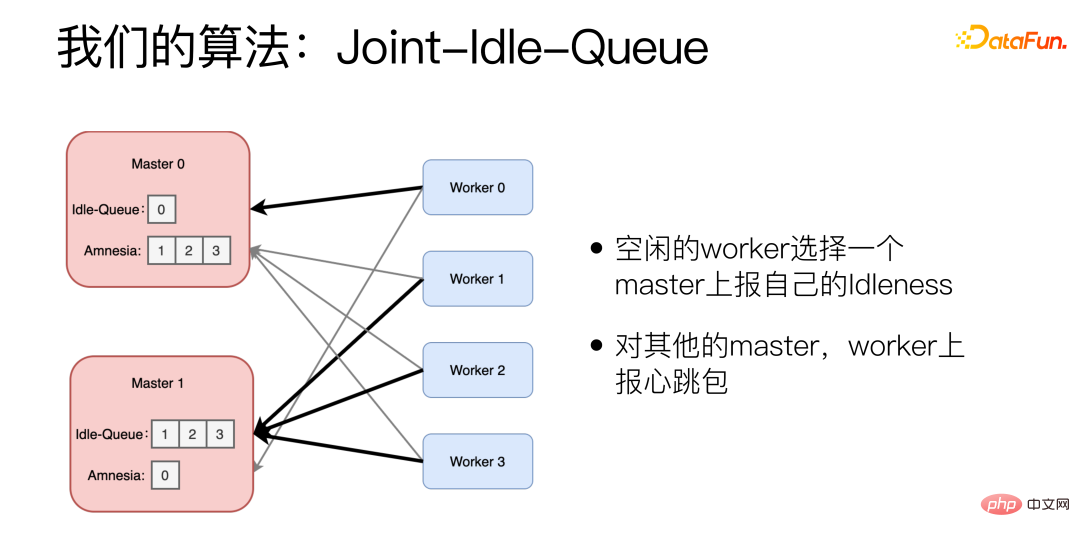
Wenn eine neue Aufgabe eintrifft, wählt der Master zufällig zwei aus der Idle-Queue aus und wählt diejenige mit der geringeren historischen Latenz aus. Wenn die Idle-Queue leer ist, wird Amnesia angezeigt. Wählen Sie zufällig zwei aus Amnesia aus und wählen Sie die mit der geringeren historischen Latenz.
In Bezug auf die tatsächliche Wirkung kann P99/P50 mit diesem Algorithmus auf das 1,5-fache komprimiert werden, was 10-mal besser ist als der Zufallsalgorithmus.
5. Zusammenfassung
In der Praxis der Modellservitisierung sind wir auf drei Herausforderungen gestoßen:
Die erste besteht darin, wie man eine große Anzahl von Microservices verwaltet und wie man die Entwicklung optimiert. Unsere Lösung ist den Online- und Bereitstellungsprozess so weit wie möglich zu automatisieren, sich wiederholende Prozesse zu extrahieren und sie in automatisierte Pipelines und Programme umzuwandeln.
Der zweite Aspekt ist die Optimierung der Modellleistung. Unsere Lösung besteht darin, von den tatsächlichen Anforderungen des Modells auszugehen und eine maßgeschneiderte Optimierung für Dienste durchzuführen, die relativ stabil sind Experimentelle Dienste verwenden PyInter und verwenden Python-Skripte direkt zum Starten von Diensten, wodurch auch die Leistung von C++ erreicht werden kann.
Das dritte Problem ist die Aufgabenplanung. Wie erreicht man einen dynamischen Lastausgleich? Unsere Lösung basiert auf Power of 2 Choices und hat den JIQ-Algorithmus entwickelt, der das Long-Tail-Problem zeitaufwändiger Dienste erheblich lindert.
Das obige ist der detaillierte Inhalt vonMikroservice-Governance des WeChat NLP-Algorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr