
Heim >Technologie-Peripheriegeräte >KI >Gemäß den offiziellen Regeln von arXiv ist die Nutzung von Tools wie ChatGPT als Autor nicht erlaubt
Gemäß den offiziellen Regeln von arXiv ist die Nutzung von Tools wie ChatGPT als Autor nicht erlaubt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-09 22:34:16843Durchsuche
ChatGPT, dieses kürzlich veröffentlichte Tool zur Textgenerierung, hat in der Forschungsgemeinschaft für hitzige Diskussionen gesorgt. Es kann studentische Aufsätze schreiben, Forschungsarbeiten zusammenfassen, Fragen beantworten, verwendbaren Computercode generieren und ist sogar gut genug, um medizinische Prüfungen, MBA-Prüfungen, juristische Prüfungen zu bestehen ...
#🎜 🎜# Eine zentrale Frage ist: Kann ChatGPT als Autor in einer Forschungsarbeit genannt werden?
Die offizielle klare Antwort von arXiv, der weltweit größten Preprint-Publishing-Plattform, lautet nun: „Nein.“
KI hat kein Recht auf UrheberschaftVor ChatGPT hatten Forscher lange Zeit Chatbots als Forschungsassistenten eingesetzt, um ihr Denken zu organisieren und Feedback zu generieren Arbeiten Sie an Ihrer eigenen Arbeit, helfen Sie bei der Codierung und fassen Sie Forschungsliteratur zusammen.
Es scheint, dass diese Hilfsarbeiten erkennbar sind, aber wenn es um „Signatur“ geht, ist das eine ganz andere Sache. „Natürlich kann ein Computerprogramm nicht für den Inhalt einer Arbeit verantwortlich sein. Es kann auch nicht den Bedingungen von arXiv zustimmen.“ Um dieses Problem anzugehen, hat arXiv eine neue Richtlinie für Autoren bezüglich der Verwendung generativer KI-Sprachtools verabschiedet.
Die offizielle Stellungnahme lautet wie folgt:
arXiv erkennt an, dass Wissenschaftler eine Vielzahl von Werkzeugen zur Durchführung nutzen Ihre wissenschaftliche Arbeit sowie die Erstellung des Berichts selbst reichen von einfachen bis hin zu sehr komplexen Werkzeugen.
Die Ansichten der Community über die Eignung dieser Tools können unterschiedlich sein und ändern sich ständig. Wir stellen fest, dass Tools nützliche und hilfreiche Ergebnisse liefern können, aber auch fehlerhafte oder irreführende Ergebnisse liefern können. Daher ist es für die Bewertung und Interpretation wissenschaftlicher Arbeiten wichtig zu verstehen, welche Tools verwendet werden.
Auf dieser Grundlage entschied arXiv: 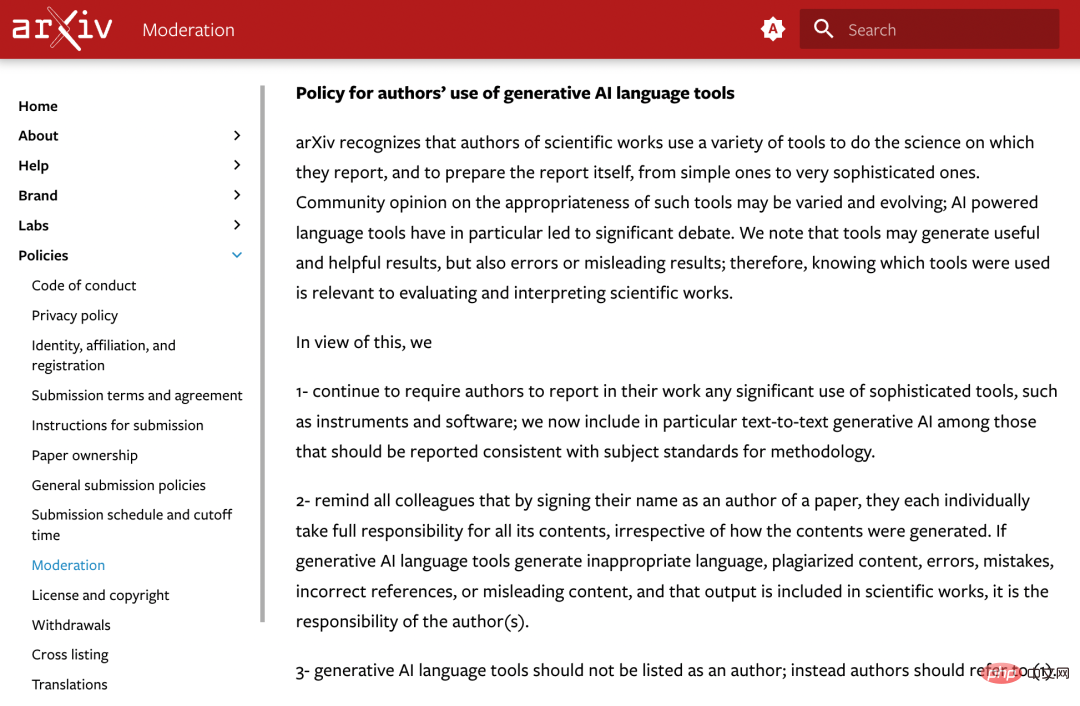 #🎜🎜 #
#🎜🎜 #
2. Erinnern Sie alle Kollegen daran, dass sie mit ihrer Unterschrift auf dem Papier die volle Verantwortung für den gesamten Inhalt des Papiers übernehmen, unabhängig davon, welchen Inhalt sie erstellt haben. Wenn ein generatives KI-Sprachtool unangemessene Sprache, plagiierte Inhalte, fehlerhafte Inhalte, falsche Verweise oder irreführende Inhalte produziert und dieser Output in eine wissenschaftliche Arbeit einfließt, liegt dies in der Verantwortung des Autors.
3. Generative künstliche Intelligenz-Sprachtools sollten nicht als Autoren aufgeführt werden, siehe 1.
Die Bedeutung von „Regeln“
Vor einigen Tagen erklärte das Magazin „Nature“ öffentlich, es habe gemeinsam mit allen Springer Regeln formuliert Naturzeitschriften Zwei Prinzipien, und diese Prinzipien wurden zu den bestehenden Autorenrichtlinien hinzugefügt:
Erstens wird kein großes Sprachmodellierungstool als Forschungsarbeit akzeptiert. Signierter Autor . Denn jede Urheberschaft bringt Verantwortung für das Werk mit sich und KI-Tools können diese Verantwortung nicht übernehmen.Zweitens sollten Forscher, die große Sprachmodellierungswerkzeuge verwenden, diese Verwendung im Abschnitt „Methoden“ oder „Danksagungen“ dokumentieren. Wenn die Arbeit diese Abschnitte nicht enthält, verwenden Sie eine Einleitung oder einen anderen geeigneten Abschnitt, um die Verwendung großer Sprachmodelle zu dokumentieren.
Diese Vorschriften sind den neuesten von arXiv veröffentlichten Grundsätzen sehr ähnlich. Es scheint, dass Organisationen im akademischen Verlagswesen einen gewissen Konsens erzielt haben.
ChatGPT Obwohl seine Fähigkeiten leistungsstark sind, hat sein Missbrauch in Bereichen wie Schulaufgaben und Papierveröffentlichungen große Besorgnis ausgelöst.
Die ICML-Konferenz für maschinelles Lernen erklärte: „ChatGPT basiert auf öffentlichen Daten, die häufig ohne Zustimmung gesammelt werden, was eine Reihe von Problemen bei der Zuweisung von Verantwortung mit sich bringt.“ 🎜🎜#
Daher begann die akademische Gemeinschaft, Methoden und Werkzeuge zur Erkennung von Text zu erforschen, der von großen Sprachmodellen (LLM) wie ChatGPT generiert wurde. In Zukunft könnte die Erkennung, ob Inhalte durch KI generiert werden, „ein wichtiger Teil des Überprüfungsprozesses“ werden.
Das obige ist der detaillierte Inhalt vonGemäß den offiziellen Regeln von arXiv ist die Nutzung von Tools wie ChatGPT als Autor nicht erlaubt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr