
Heim >Technologie-Peripheriegeräte >KI >Mit TensorFlow und Keras ist es ganz einfach, Ihr erstes neuronales Netzwerk aufzubauen und zu trainieren
Mit TensorFlow und Keras ist es ganz einfach, Ihr erstes neuronales Netzwerk aufzubauen und zu trainieren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-09 19:04:06926Durchsuche
Die KI-Technologie entwickelt sich rasant weiter. Mithilfe verschiedener fortschrittlicher KI-Modelle können Chat-Roboter, humanoide Roboter, selbstfahrende Autos usw. gebaut werden. KI hat sich zur am schnellsten wachsenden Technologie entwickelt und Objekterkennung und Objektklassifizierung sind aktuelle Trends.
In diesem Artikel werden die vollständigen Schritte zum Erstellen und Trainieren eines Bildklassifizierungsmodells von Grund auf mithilfe eines Faltungs-Neuronalen Netzwerks vorgestellt. In diesem Artikel wird der öffentliche Cifar-10-Datensatz zum Trainieren dieses Modells verwendet. Dieser Datensatz ist einzigartig, da er Bilder von Alltagsgegenständen wie Autos, Flugzeugen, Hunden, Katzen usw. enthält. Durch das Trainieren eines neuronalen Netzwerks auf diese Objekte wird in diesem Artikel ein intelligentes System zur Klassifizierung dieser Dinge in der realen Welt entwickelt. Es enthält mehr als 60.000 32x32-Bilder von 10 verschiedenen Objekttypen. Am Ende dieses Tutorials verfügen Sie über ein Modell, das Objekte anhand ihrer visuellen Eigenschaften identifizieren kann.

Abbildung 1 Beispielbild eines Datensatzes | Bild von datasets.activeloop
Dieser Artikel deckt alles von Anfang an ab. Wenn Sie also noch nicht die tatsächliche Implementierung neuronaler Netze kennengelernt haben, ist das völlig in Ordnung.
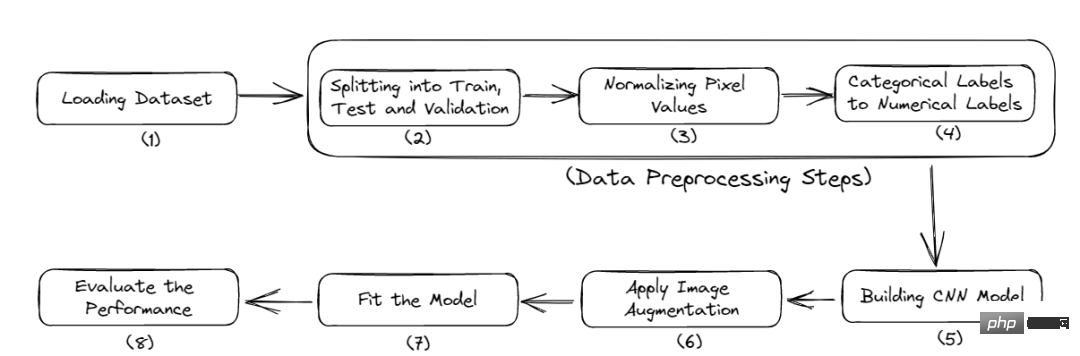
Das Folgende ist der vollständige Arbeitsablauf dieses Tutorials:
- Importieren Sie die erforderlichen Bibliotheken.
- Laden Sie die Daten.
- Vorverarbeitung der Daten.
- Erstellen Sie das Modell.
- Bewerten Sie die Leistung des Modells 2 Vorgang abschließen
 Zuerst müssen Sie einige Module installieren, um dieses Projekt zu starten. In diesem Artikel wird Google Colab verwendet, da es kostenloses GPU-Training bietet.
Zuerst müssen Sie einige Module installieren, um dieses Projekt zu starten. In diesem Artikel wird Google Colab verwendet, da es kostenloses GPU-Training bietet.
Hier sind die Befehle zum Installieren der erforderlichen Bibliotheken:
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
Importieren Sie die Bibliotheken in die Python-Datei.
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>Numpy: Es wird für effiziente Array-Berechnungen für große Datensätze mit Bildern verwendet. Tensorflow: Es handelt sich um eine von Google entwickelte Open-Source-Bibliothek für maschinelles Lernen. Es bietet viele Funktionen zum Erstellen großer und skalierbarer Modelle. Keras: Eine weitere High-Level-API für neuronale Netzwerke, die auf TensorFlow läuft.
- Matplotlib: Diese Python-Bibliothek kann Diagramme erstellen und eine bessere Datenvisualisierung ermöglichen.
- Sklearn: Es bietet Funktionen zur Durchführung von Datenvorverarbeitungs- und Merkmalsextraktionsaufgaben für Datensätze. Es enthält integrierte Funktionen zum Finden von Modellbewertungsmetriken wie Genauigkeit, Präzision, falsch-positiven, falsch-negativen Ergebnissen usw.
- Geben Sie nun den Datenladeschritt ein.
- Daten laden
- In diesem Abschnitt wird der Datensatz geladen und die Trainings-Test-Datenaufteilung durchgeführt.
Laden und Aufteilen von Daten:
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>
cifar10-Datensatz wird direkt aus der Keras-Datensatzbibliothek geladen. Und diese Daten werden auch in Trainingsdaten und Testdaten unterteilt. Mithilfe von Trainingsdaten wird das Modell trainiert, damit es darin Muster erkennen kann. Während Testdaten für das Modell unsichtbar sind, werden sie verwendet, um seine Leistung zu überprüfen, d. h. wie viele Datenpunkte im Verhältnis zur Gesamtzahl der Datenpunkte korrekt vorhergesagt werden.
training_label enthält die Beschriftungen, die den Bildern in training_data entsprechen.
Verwenden Sie dann die integrierte train_test_split-Funktion von sklearn, um die Trainingsdaten erneut in Validierungsdaten aufzuteilen. Validierungsdaten wurden verwendet, um das endgültige Modell auszuwählen und abzustimmen. Abschließend werden alle Trainings-, Test- und Validierungsdaten in 32-Bit-Gleitkommazahlen umgewandelt.
Jetzt ist das Laden des Datensatzes abgeschlossen. Im nächsten Abschnitt werden in diesem Artikel einige Vorverarbeitungsschritte durchgeführt.
Datenvorverarbeitung
Die Datenvorverarbeitung ist der erste und wichtigste Schritt bei der Entwicklung eines Modells für maschinelles Lernen. Folgen Sie diesem Artikel, um herauszufinden, wie das geht.
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>
Ausgabe:
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
Dieser Datensatz enthält Bilder aus 10 Kategorien, jedes Bild ist 32 x 32 Pixel groß. Jedes Pixel hat einen Wert zwischen 0 und 255 und wir müssen ihn zwischen 0 und 1 normalisieren, um den Berechnungsprozess zu vereinfachen. Danach werden wir die kategorialen Labels in One-Hot-codierte Labels umwandeln. Dies geschieht, um kategoriale Daten in numerische Daten umzuwandeln, sodass wir maschinelle Lernalgorithmen problemlos anwenden können.
Jetzt beginnen wir mit der Konstruktion des CNN-Modells.
Erstellen Sie ein CNN-Modell
Das CNN-Modell funktioniert in drei Phasen. Die erste Stufe besteht aus Faltungsschichten, um relevante Merkmale aus dem Bild zu extrahieren. Der zweite Schritt besteht darin, Ebenen zusammenzufassen, um die Bildgröße zu reduzieren. Es trägt auch dazu bei, eine Überanpassung des Modells zu reduzieren. Die dritte Stufe besteht aus dichten Schichten, die das 2D-Bild in ein 1D-Array umwandeln. Schließlich wird dieses Array in die vollständig verbundene Schicht eingespeist, um die endgültige Vorhersage zu treffen.
Das Folgende ist der Code:
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
In diesem Artikel werden drei Schichtensätze angewendet. Jeder Satz enthält zwei Faltungsschichten, eine Max-Pooling-Schicht und eine Dropout-Schicht. Die Conv2D-Ebene empfängt input_shape als (32, 32, 3), die dieselbe Größe wie das Bild haben muss.
Jede Conv2D-Ebene benötigt außerdem eine Aktivierungsfunktion, nämlich relu. Aktivierungsfunktionen werden verwendet, um die Nichtlinearität im System zu erhöhen. Einfacher ausgedrückt bestimmt es, ob ein Neuron basierend auf einem bestimmten Schwellenwert aktiviert werden muss. Es gibt viele Arten von Aktivierungsfunktionen wie ReLu, Tanh, Sigmoid, Softmax usw., die unterschiedliche Algorithmen verwenden, um das Feuern von Neuronen zu bestimmen.
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
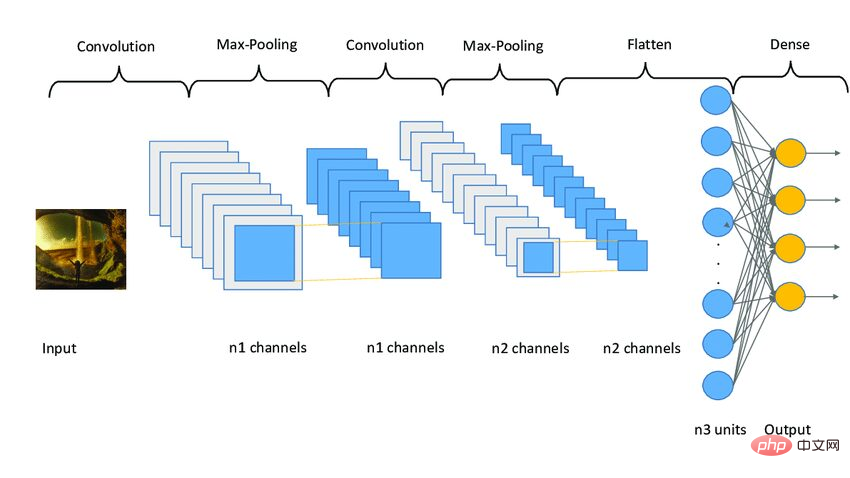
图3 Sampe CNN架构|图片来源:Researchgate
编译模型
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
拟合模型
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:

图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
评估模型性能
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>
输出:
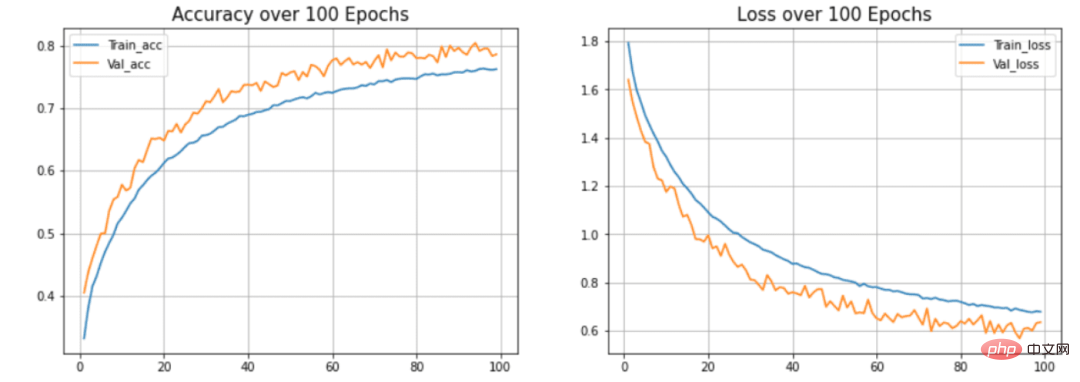
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
总结
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
Das obige ist der detaillierte Inhalt vonMit TensorFlow und Keras ist es ganz einfach, Ihr erstes neuronales Netzwerk aufzubauen und zu trainieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr