
Heim >Technologie-Peripheriegeräte >KI >Google brauchte zwei Jahre, um mithilfe von Reinforcement Learning 23 Roboter zu bauen, die beim Sortieren von Müll helfen sollen
Google brauchte zwei Jahre, um mithilfe von Reinforcement Learning 23 Roboter zu bauen, die beim Sortieren von Müll helfen sollen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-09 15:01:091073Durchsuche
Reinforcement Learning (RL) ermöglicht es Robotern, durch Versuch und Irrtum zu interagieren, komplexe Verhaltensweisen zu erlernen und mit der Zeit immer besser zu werden. Einige frühere Arbeiten bei Google haben untersucht, wie RL es Robotern ermöglichen kann, komplexe Fähigkeiten wie Greifen, Multitasking-Lernen und sogar Tischtennis zu beherrschen. Obwohl das Reinforcement-Learning bei Robotern große Fortschritte gemacht hat, sehen wir immer noch keine Roboter mit Reinforcement-Learning in alltäglichen Umgebungen. Da die reale Welt komplex und vielfältig ist und sich im Laufe der Zeit ständig verändert, stellt dies große Herausforderungen an Robotersysteme. Allerdings sollte Reinforcement Learning ein hervorragendes Werkzeug zur Bewältigung dieser Herausforderungen sein: Durch Üben, Verbessern und Lernen am Arbeitsplatz sollten Roboter in der Lage sein, sich an eine sich ständig verändernde Welt anzupassen.
In dem Google-Artikel „Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators“ untersuchen Forscher, wie dieses Problem durch die neuesten groß angelegten Experimente gelöst werden kann, die sie über zwei Jahre hinweg durchgeführt haben Eine Gruppe von 23 RL-fähigen Robotern wird für die Müllsortierung und das Recycling in Google-Bürogebäuden eingesetzt. Das verwendete Robotersystem kombiniert skalierbares Deep Reinforcement Learning aus realen Daten mit geführten und zusätzlichen objektbewussten Eingaben aus dem Simulationstraining, um die Generalisierung zu verbessern und gleichzeitig die Vorteile von End-to-End-Trainings zu überprüfen.

Papieradresse: https://rl-at-scale.github.io/assets/rl_at_scale.pdf
Problemstellung
Wenn Menschen Müll nicht richtig klassifizieren, in Chargen von Wertstoffen können kontaminiert werden und Kompost kann unsachgemäß auf Mülldeponien entsorgt werden. In Googles Experiment streiften Roboter durch Bürogebäude und suchten nach „Müllcontainern“ (Recyclingbehälter, Kompostbehälter und andere Abfallbehälter). Die Aufgabe des Roboters besteht darin, an jeder Müllstation anzukommen, um Abfälle zu sortieren, Gegenstände zwischen verschiedenen Behältern zu transportieren, um alle wiederverwertbaren Gegenstände (Dosen, Flaschen) in die wiederverwertbaren Behälter und alle kompostierbaren Gegenstände (Kartonbehälter, Pappbecher) in den Kompostbehälter zu legen alles andere in den anderen Behältern.
Eigentlich ist diese Aufgabe nicht so einfach, wie es scheint. Allein die Teilaufgabe, die verschiedenen Gegenstände aufzusammeln, die Menschen in den Müll werfen, ist bereits eine große Herausforderung. Der Roboter muss außerdem für jedes Objekt den passenden Behälter identifizieren und es so schnell und effizient wie möglich sortieren. In der realen Welt begegnen Roboter einer Vielzahl einzigartiger Situationen, wie zum Beispiel den folgenden realen Beispielen für Bürogebäude:
Lernen Sie aus unterschiedlichen Erfahrungen
Kontinuierliches Lernen am Arbeitsplatz ist hilfreich, aber bevor Sie an diesen Punkt gelangen. Zuvor a Um einen Roboter zu führen, waren grundlegende Fähigkeiten erforderlich. Zu diesem Zweck nutzt Google vier Erfahrungsquellen: (1) einfache, von Hand entworfene Strategien, die eine geringe Erfolgsquote haben, aber dazu beitragen, erste Erfahrungen zu sammeln; (2) ein Simulationstrainings-Framework, das die Übertragung von Simulationen in die Realität nutzt; einige vorläufige Erfahrungen. (3) „Roboterklassenzimmer“, in denen Roboter repräsentative Müllstationen nutzen, um kontinuierlich zu üben; (4) reale Einsatzumgebungen, in denen Roboter in Bürogebäuden mit echtem Müll üben;
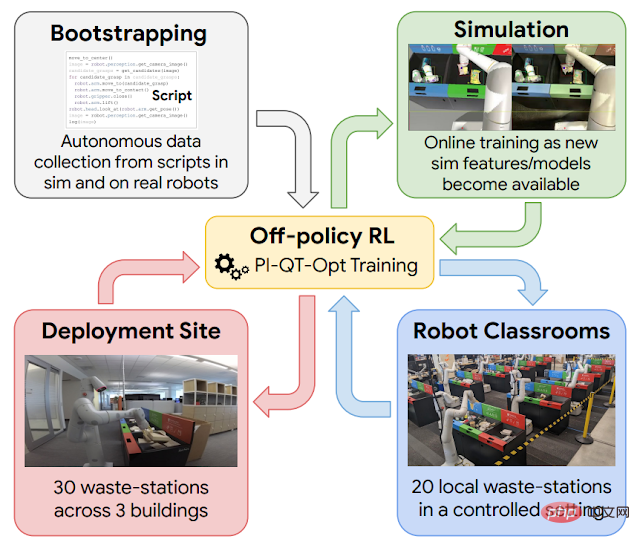
Schematische Darstellung des verstärkenden Lernens in dieser groß angelegten Anwendung. Verwenden Sie skriptgenerierte Daten, um die Einführung der Richtlinie zu steuern (oben links). Anschließend wird ein Simulation-zu-Realität-Modell trainiert, das zusätzliche Daten in der Simulationsumgebung generiert (oben rechts). Fügen Sie während jedes Bereitstellungszyklus Daten hinzu, die in „Roboterklassen“ (unten rechts) gesammelt wurden. Bereitstellung und Erfassung von Daten in einem Bürogebäude (unten links).
Das hier verwendete Reinforcement-Learning-Framework basiert auf QT-Opt, das auch zum Erfassen verschiedener Abfälle in der Laborumgebung und einer Reihe anderer Fähigkeiten verwendet wird. Beginnen Sie mit einer einfachen Skriptstrategie, die Sie durch eine Simulationsumgebung führt, wenden Sie Reinforcement Learning an und verwenden Sie CycleGAN-basierte Übertragungsmethoden, um Simulationsbilder mit RetinaGAN realistischer aussehen zu lassen.
Hier fangen wir an, „Roboter-Klassenzimmer“ zu betreten. Während tatsächliche Bürogebäude das realistischste Erlebnis bieten, ist der Datenerfassungsdurchsatz begrenzt – an manchen Tagen muss viel Müll sortiert werden, an anderen nicht so viel. Roboter haben den größten Teil ihrer Erfahrung in „Roboterklassenzimmern“ gesammelt. In den unten gezeigten „Roboter-Klassenzimmern“ üben 20 Roboter die Müllsortieraufgabe:

Während diese Roboter in den „Roboter-Klassenzimmern“ trainiert werden, lernen andere Roboter in 3 Bürogebäuden das Sortieren von 30 Müll im Stehen.
Klassifizierungsleistung
Am Ende sammelten die Forscher 540.000 experimentelle Daten aus „Roboterklassenzimmern“ und 325.000 experimentelle Daten in der tatsächlichen Einsatzumgebung. Da die Datenmenge weiter zunimmt, verbessert sich die Leistung des gesamten Systems. Die Forscher bewerteten das endgültige System in „Roboterklassenzimmern“, um kontrollierte Vergleiche zu ermöglichen und Szenarien basierend auf dem zu erstellen, was die Roboter bei tatsächlichen Einsätzen sehen würden. Das endgültige System erreichte eine durchschnittliche Genauigkeit von etwa 84 %, wobei sich die Leistung mit dem Hinzufügen von Daten stetig verbesserte. In der realen Welt dokumentierten Forscher Statistiken von tatsächlichen Einsätzen in den Jahren 2021 bis 2022 und stellten fest, dass das System die Schadstoffe in Behältern um 40 bis 50 Gewichtsprozent reduzieren konnte. In ihrem Artikel liefern Google-Forscher tiefere Einblicke in das Design der Technologie, eine Studie zur Dämpfung verschiedener Designentscheidungen und detailliertere Statistiken aus ihren Experimenten.
Fazit und Ausblick auf die zukünftige Arbeit
Die experimentellen Ergebnisse zeigen, dass das auf Verstärkungslernen basierende System es Robotern ermöglichen kann, reale Aufgaben in realen Büroumgebungen zu bewältigen. Die Kombination von Offline- und Online-Daten ermöglicht es Robotern, sich an unterschiedlichste Situationen in der realen Welt anzupassen. Gleichzeitig kann das Lernen in einer kontrollierteren „Klassenzimmer“-Umgebung, einschließlich Simulationsumgebungen und realen Umgebungen, einen leistungsstarken Startmechanismus bereitstellen, der es dem „Schwungrad“ des verstärkenden Lernens ermöglicht, sich zu drehen und so Anpassungsfähigkeit zu erreichen.
Obwohl wichtige Ergebnisse erzielt wurden, gibt es noch viel zu tun: Die endgültige Strategie des verstärkenden Lernens ist nicht immer erfolgreich, und es sind leistungsfähigere Modelle erforderlich, um ihre Leistung zu verbessern und sie auf einen breiteren Aufgabenbereich zu skalieren . Darüber hinaus können andere Erfahrungsquellen, unter anderem aus anderen Aufgaben, anderen Robotern und sogar Internetvideos, die Startup-Erfahrung aus Simulation und „Klassenzimmer“ weiter ergänzen. Dies sind Probleme, die in Zukunft angegangen werden müssen.
Das obige ist der detaillierte Inhalt vonGoogle brauchte zwei Jahre, um mithilfe von Reinforcement Learning 23 Roboter zu bauen, die beim Sortieren von Müll helfen sollen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr