
Heim >Technologie-Peripheriegeräte >KI >Komprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen
Komprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen

- PHPznach vorne
- 2023-05-09 14:10:371501Durchsuche
Bevor Sie den Text eingeben, berücksichtigen Sie die Eingabeaufforderung eines Transformer-Sprachmodells (LM) wie ChatGPT:

Mit Millionen von Benutzern und Abfragen, die jeden Tag generiert werden, verwendet ChatGPT einen Selbstaufmerksamkeitsmechanismus, um Eingabeaufforderungen zu implementieren Bei wiederholter Codierung nehmen Zeit und Speicherkomplexität quadratisch mit der Eingabelänge zu. Das Zwischenspeichern der Transformer-Aktivierung der Eingabeaufforderung verhindert eine teilweise Neuberechnung, diese Strategie verursacht jedoch immer noch erhebliche Speicher- und Speicherkosten, da die Anzahl der zwischengespeicherten Eingabeaufforderungen zunimmt. Im Maßstab kann bereits eine geringfügige Reduzierung der Eingabeaufforderungslänge zu Rechen-, Speicher- und Speichereinsparungen führen und es dem Benutzer gleichzeitig ermöglichen, mehr Inhalte in das begrenzte Kontextfenster des LM einzufügen.
Dann. Wie lassen sich die Kosten für die prompte Abwicklung senken? Ein typischer Ansatz besteht darin, das Modell so zu verfeinern oder zu destillieren, dass es sich ohne Eingabeaufforderungen ähnlich wie das Originalmodell verhält, möglicherweise unter Verwendung parametereffizienter adaptiver Methoden. Ein grundlegender Nachteil dieses Ansatzes besteht jedoch darin, dass das Modell jedes Mal für eine neue Eingabeaufforderung neu trainiert werden muss (dargestellt in der Mitte von Abbildung 1 unten).
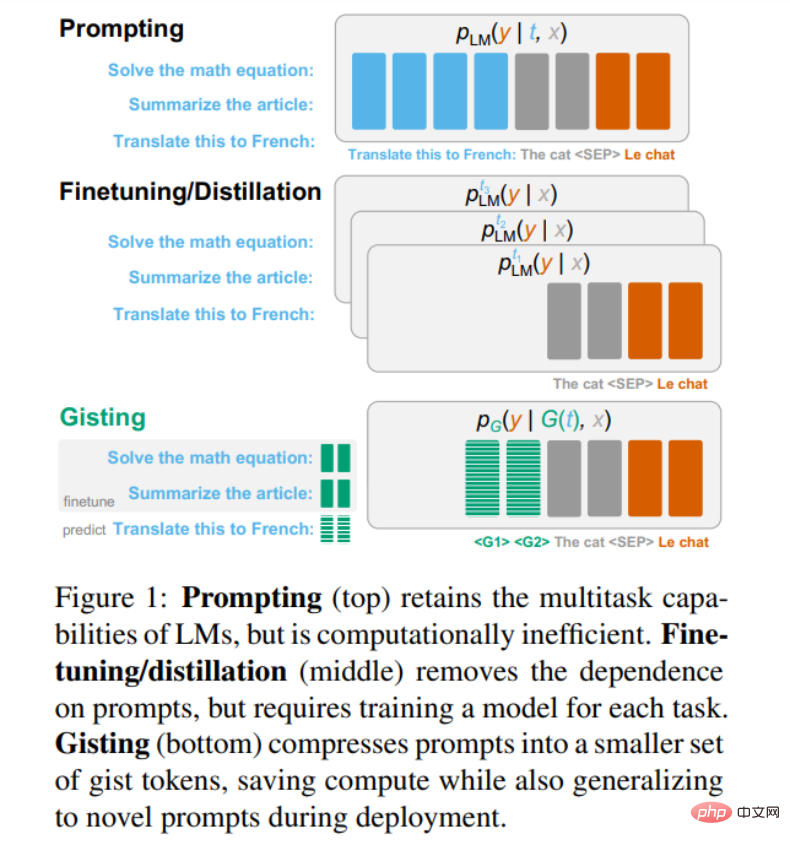
In diesem Artikel schlugen Forscher der Stanford University das Gisting-Modell vor (unten in Abbildung 1 oben), das beliebige Eingabeaufforderungen in einen Satz kleinerer virtueller „Gist“-Tokens komprimiert, ähnlich dem Präfix Fine -Tuning. Die Präfix-Feinabstimmung erfordert jedoch das Lernen des Präfixes für jede Aufgabe durch Gradientenabstieg, während Gisting eine Meta-Lernmethode verwendet, um das Gist-Präfix nur durch Eingabeaufforderungen vorherzusagen, ohne das Präfix für jede Aufgabe zu lernen. Dies amortisiert die Kosten für das Lernen von Präfixen pro Aufgabe und ermöglicht die Verallgemeinerung auf unbekannte Anweisungen ohne zusätzliche Schulung.
Da außerdem das „Gist“-Token viel kürzer ist als die vollständige Eingabeaufforderung, ermöglicht Gisting die Komprimierung, Zwischenspeicherung und Wiederverwendung der Eingabeaufforderung, um die Recheneffizienz zu verbessern.

Papieradresse: https://arxiv.org/pdf/2304.08467v1.pdf
Forscher haben eine sehr einfache Methode vorgeschlagen, um grundlegende Anweisungen zu befolgen, Modell: Simply Optimieren Sie den Befehl, fügen Sie das Gish-Token nach der Eingabeaufforderung ein, und die geänderte Aufmerksamkeitsmaske verhindert, dass das Token nach dem Gist-Token auf das Token vor dem Gist-Token verweist. Dadurch kann das Modell ohne zusätzliche Schulungskosten gleichzeitig die sofortige Komprimierung und das Befolgen von Anweisungen erlernen.
Auf dem Nur-Decoder- (LLaMA-7B) und Encoder-Decoder-LM (FLAN-T5-XXL) erreicht Gisting eine bis zu 26-fache Sofortkomprimierung und behält dabei eine ähnliche Ausgabequalität wie das Originalmodell bei. Dies führt zu einer 40-prozentigen Reduzierung der FLOPs während der Inferenz, einer Latenzbeschleunigung um 4,2 % und deutlich reduzierten Speicherkosten im Vergleich zu herkömmlichen Prompt-Caching-Methoden.
Gisting
Die Forscher beschreiben Gisting zunächst im Zusammenhang mit der Feinabstimmung von Anweisungen. Für die Anweisung nach dem Datensatz 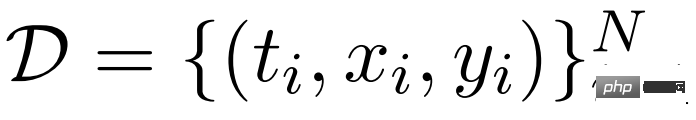
Dieses Muster der Verbindung von t und x hat jedoch Nachteile: Transformer-basiertes LM hat ein begrenztes Kontextfenster, das durch Architektur oder Rechenleistung begrenzt ist. Letzteres ist besonders schwer zu lösen, da die Selbstaufmerksamkeit quadratisch mit der Eingabelänge skaliert. Daher sind sehr lange Eingabeaufforderungen, insbesondere solche, die wiederholt wiederverwendet werden, rechenineffizient. Welche Optionen stehen zur Verfügung, um die Kosten für die Einleitung zu senken?
Ein einfacher Ansatz besteht darin, LM für eine bestimmte Aufgabe t zu optimieren, d. h. wenn ein Datensatz 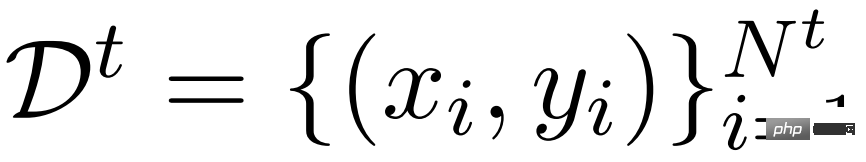
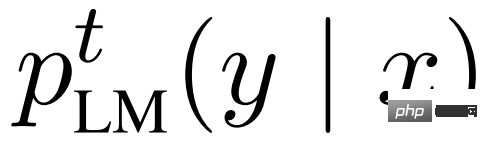
Selbst bessere, parametereffiziente Feinabstimmungsmethoden wie Präfix-/Prompt-Feinabstimmung oder Adapter können das gleiche Ziel zu deutlich geringeren Kosten erreichen als eine vollständige Feinabstimmung. Allerdings bleibt ein Problem bestehen: Mindestens ein Teil der Modellgewichte für jede Aufgabe muss gespeichert werden, und was noch wichtiger ist, für jede Aufgabe t muss der entsprechende Eingabe-/Ausgabepaar-Datensatz D^t erfasst und das Modell neu trainiert werden.
Gisting ist ein anderer Ansatz, der zwei Kosten amortisiert: (1) den Inferenzzeitaufwand für die Konditionierung von p_LM auf t, (2) den Trainingszeitaufwand für das Lernen eines neuen p^t_LM für jedes t. Die Idee besteht darin, während der Feinabstimmung eine komprimierte Version von t G (t) zu lernen, sodass die Schlussfolgerung aus p_G (y | G (t),x) schneller ist als aus p_LM (y|t,x).
In LM-Begriffen wird G (t) ein Satz „virtueller“ Gist-Token sein, deren Anzahl geringer ist als die Token in t, die aber dennoch ein ähnliches Verhalten in LM hervorrufen. Transformatoraktivierungen (z. B. Schlüssel- und Wertmatrizen) auf G (t) können dann zwischengespeichert und wiederverwendet werden, um die Recheneffizienz zu verbessern. Wichtig ist, dass die Forscher hoffen, dass G auf unbekannte Aufgaben verallgemeinert werden kann: Bei einer neuen Aufgabe t kann die entsprechende Gist-Aktivierung G(t) ohne zusätzliches Training vorhergesagt und verwendet werden.
Lernen von Gisting über Masken
Der allgemeine Rahmen von Gisting wurde oben beschrieben, und als nächstes werden wir eine sehr einfache Möglichkeit untersuchen, ein solches Modell zu lernen: die Verwendung des LM selbst als Gist-Prädiktor G. Dies nutzt nicht nur bereits vorhandenes Wissen im LM, sondern ermöglicht auch das Erlernen von Gisting, indem einfach eine Standardanweisungsfeinabstimmung durchgeführt und die Transformer-Aufmerksamkeitsmaske geändert wird, um die Prompt-Komprimierung zu verbessern. Das bedeutet, dass für Gisting kein zusätzlicher Schulungsaufwand anfällt und nur eine Feinabstimmung anhand von Standardanweisungen erforderlich ist!
Fügen Sie insbesondere ein spezielles Gist-Token zum Modellvokabular und zur Einbettungsmatrix hinzu, ähnlich den in solchen Modellen üblichen Satzanfangs-/Endtokens. Verketten Sie dann für ein gegebenes (Aufgaben-, Eingabe-)Tupel (t, x) t und x unter Verwendung einer Menge von k aufeinanderfolgenden Kerntokens in (t, g_1, . . , g_k, x), z. B. 
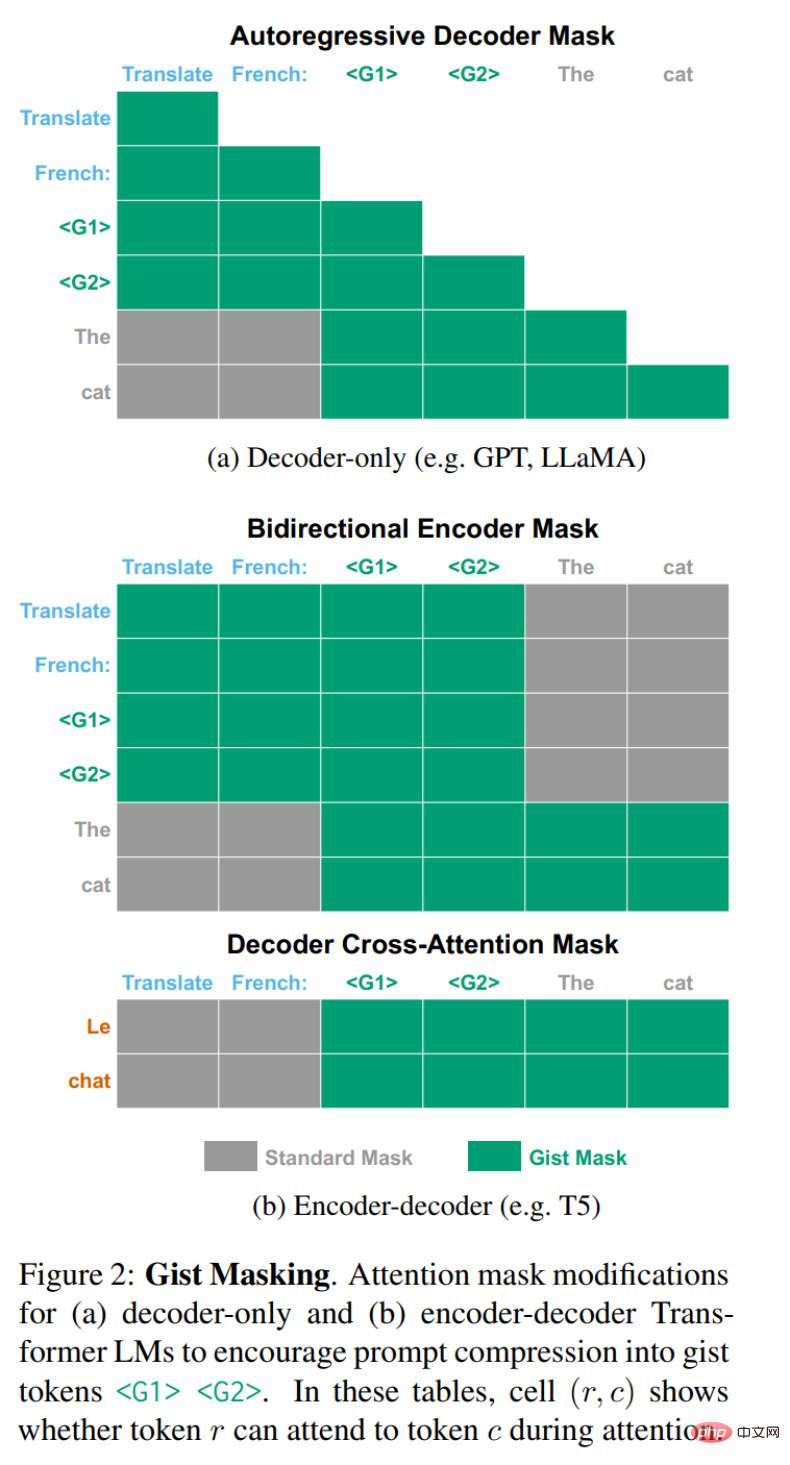
Abbildung 2 unten zeigt die erforderlichen Änderungen. Für reine Decoder-LMs wie GPT-3 oder LLaMA, die typischerweise autoregressive kausale Aufmerksamkeitsmasken verwenden, muss man nur die untere linke Ecke des in Abbildung 2a gezeigten Dreiecks ausblenden. Für einen Encoder-Decoder LM mit einem bidirektionalen Encoder und einem autoregressiven Decoder sind zwei Modifikationen erforderlich (dargestellt in Abbildung 2b).
Zuerst blockieren Sie bei Encodern, die normalerweise keine Masken haben, den Eingabetoken x mit Bezug auf den Eingabeaufforderungstoken t. Es muss aber auch verhindert werden, dass Prompt t und Gist-Token g_i auf das Eingabetoken x verweisen, da der Encoder sonst je nach Eingabe unterschiedliche Gist-Darstellungen lernt. Schließlich arbeitet der Decoder normal, außer während der Queraufmerksamkeitsperioden, in denen verhindert werden muss, dass der Decoder auf den Prompt-Token t verweist.
Experimentelle Ergebnisse
Für unterschiedliche Anzahlen von Gist-Tokens sind die ROUGE-L- und ChatGPT-Bewertungsergebnisse von LLaMA-7B und FLAN-T5-XXL in Abbildung 3 unten dargestellt.
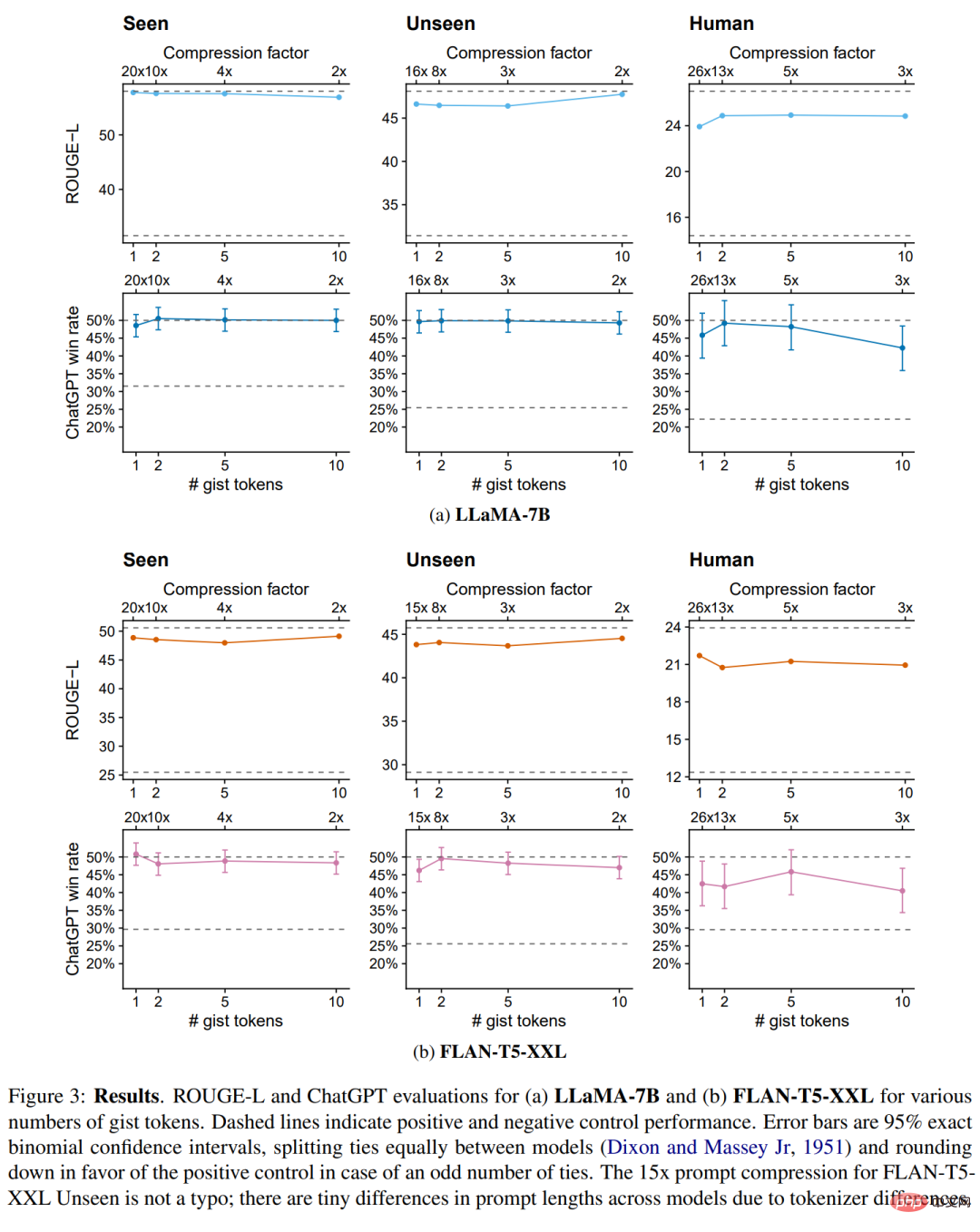
Modelle sind im Allgemeinen unempfindlich gegenüber der Anzahl k der Gist-Tokens: Das Komprimieren von Eingabeaufforderungen in einem einzigen Token führt nicht zu erheblichen Leistungseinbußen. Tatsächlich beeinträchtigen in einigen Fällen zu viele Gist-Tokens die Leistung (z. B. LLaMA-7B, 10 Gist-Tokens), möglicherweise weil die erhöhte Kapazität zu stark zur Trainingsverteilung passt. Daher geben die Forscher die spezifischen Werte des Einzel-Token-Modells in der folgenden Tabelle 1 an und verwenden in den verbleibenden Experimenten ein einzelnes Kernmodell.
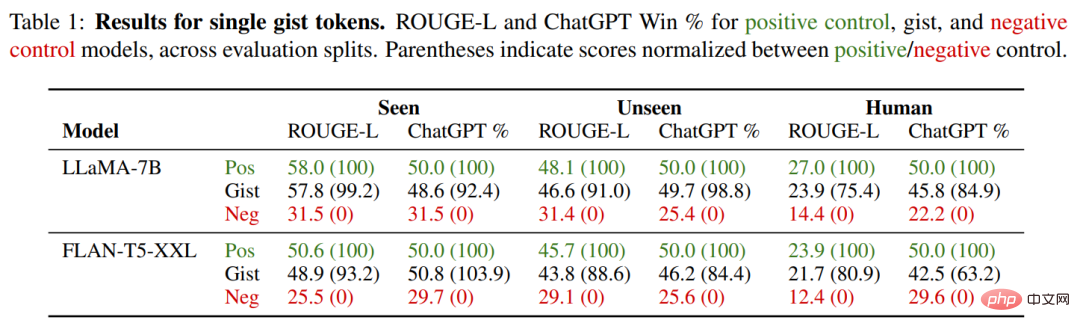
Den gesehenen Anweisungen erreichte das Gist-Modell fast die gleiche ROUGE- und ChatGPT-Leistung wie sein entsprechendes Positivkontrollmodell, mit Gewinnraten von 48,6 % bzw. 48,6 % auf LLaMA-7B FLANT5- XXL. 50,8 %. Was die Forscher hier am meisten interessiert, ist ihre Generalisierungsfähigkeit bei unbekannten Aufgaben, die anhand von zwei anderen Datensätzen gemessen werden muss.
In den unsichtbaren Eingabeaufforderungen im Alpaca+-Trainingsdatensatz können wir sehen, dass das Gist-Modell über eine starke Generalisierungsfähigkeit bei unsichtbaren Eingabeaufforderungen verfügt: 49,7 % (LLaMA) bzw. 46,2 % im Vergleich zur Kontrollgruppe (FLAN-T5), die gewinnt Rate. Beim anspruchsvollsten OOD Human Split sinkt die Gewinnquote des Kernmodells leicht auf 45,8 % (LLaMA) und 42,5 % (FLANT5).
Der Zweck dieses Artikels besteht darin, ein Kernmodell zu schaffen, das die Funktionalität des Originalmodells genau nachahmt. Daher könnte man sich fragen, wann genau ein Kernmodell nicht von einer Kontrollgruppe zu unterscheiden ist. Abbildung 4 unten zeigt, wie oft dies geschieht: Bei gesehenen Aufgaben (aber unsichtbaren Eingaben) liegt das Gist-Modell fast die Hälfte der Zeit auf Augenhöhe mit der Kontrollgruppe. Bei ungesehenen Aufgaben sinkt diese Zahl auf 20–25 %. Für die OOD Human-Aufgabe sinkt diese Zahl wieder auf 10 %. Unabhängig davon ist die Qualität der Kernmodellausgabe sehr hoch.
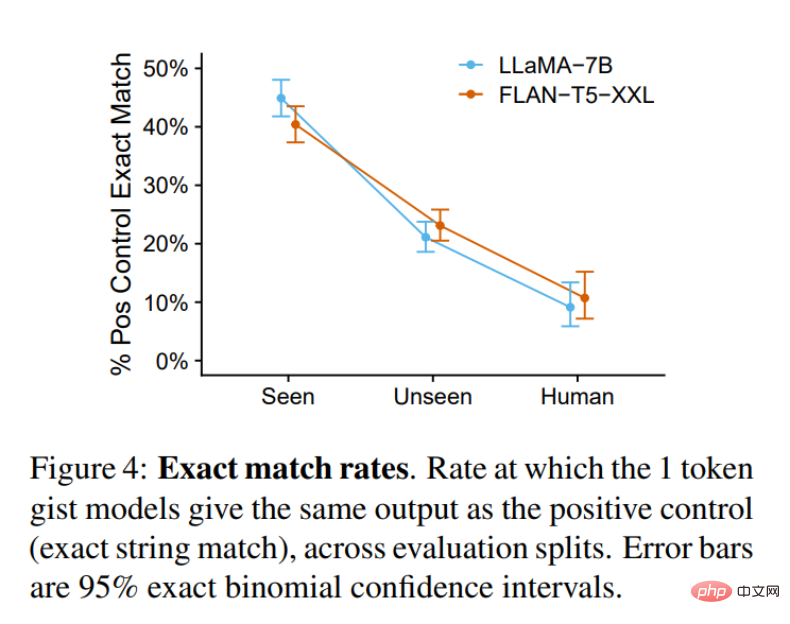
Insgesamt zeigen diese Ergebnisse, dass das Gist-Modell Eingabeaufforderungen zuverlässig komprimieren kann, selbst bei einigen Eingabeaufforderungen außerhalb der Trainingsverteilung, insbesondere bei LLaMA, einem solchen kausalen LM, der nur durch Decoder erfolgt. Encoder-Decoder-Modelle wie FLAN-T5 schneiden etwas schlechter ab. Ein möglicher Grund dafür ist, dass die Kernmaske den bidirektionalen Aufmerksamkeitsfluss im Encoder unterdrückt, was eine größere Herausforderung darstellt, als nur einen Teil des Verlaufs im autoregressiven Decoder zu maskieren. Weitere Arbeiten sind erforderlich, um diese Hypothese in Zukunft zu untersuchen.
Rechen-, Speicher- und Speichereffizienz
Abschließend noch einmal zurück zu einer der Kernmotivationen dieser Arbeit: Welche Effizienzsteigerungen kann Gisting mit sich bringen?
Tabelle 2 unten zeigt die Ergebnisse eines einzelnen Vorwärtsdurchlaufs des Modells (d. h. eines Schritts der autoregressiven Dekodierung mit einem einzelnen Eingabetoken) unter Verwendung des PyTorch 2.0-Profilers, gemittelt über die 252 Anweisungen im Human-Eval-Split-Wert. Das Gist-Caching verbessert die Effizienz im Vergleich zu nicht optimierten Modellen erheblich. Bei beiden Modellen wurden FLOP-Einsparungen von 40 % und eine Taktzeitverkürzung von 4–7 % erzielt.
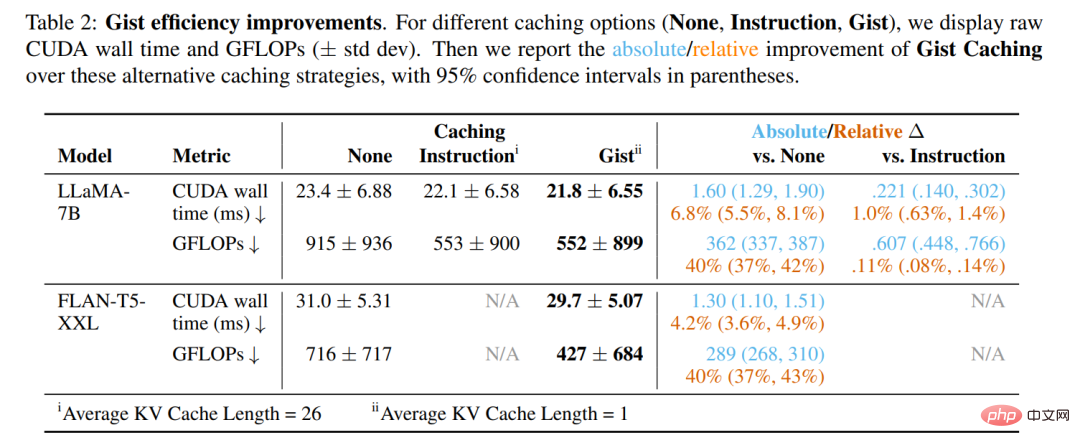
Noch wichtiger ist jedoch, dass der Gist-Cache im Vergleich zum Befehlscache neben der Latenz einen entscheidenden Vorteil hat: Durch die Komprimierung von 26 Token in 1 wird im Eingabekontextfenster mehr Platz frei, der durch begrenzt ist absolute Positionseinbettung oder GPU-VRAM. Speziell für LLaMA-7B benötigt jeder Token im KV-Cache 1,05 MB Speicherplatz. Obwohl der KV-Cache im Verhältnis zum Gesamtspeicher, der für die LLaMA-7B-Inferenz bei den getesteten Eingabeaufforderungslängen erforderlich ist, nur wenig beiträgt, kommt es immer häufiger vor, dass Entwickler viele Eingabeaufforderungen für eine große Anzahl von Benutzern zwischenspeichern, und die Speicherkosten können schnell steigen. Bei gleichem Speicherplatz kann der Gist-Cache 26-mal mehr Eingabeaufforderungen verarbeiten als der vollständige Befehlscache.
Das obige ist der detaillierte Inhalt vonKomprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr