
Heim >Technologie-Peripheriegeräte >KI >Ein durchgesickertes internes Google-Dokument zeigt, dass es sowohl Google als auch OpenAI an wirksamen Schutzmechanismen mangelt, sodass die Schwelle für große Modelle von der Open-Source-Community kontinuierlich gesenkt wird.
Ein durchgesickertes internes Google-Dokument zeigt, dass es sowohl Google als auch OpenAI an wirksamen Schutzmechanismen mangelt, sodass die Schwelle für große Modelle von der Open-Source-Community kontinuierlich gesenkt wird.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-08 23:19:201596Durchsuche
„Wir haben keinen Wassergraben und OpenAI auch nicht.“ In einem kürzlich durchgesickerten Dokument äußerte ein Forscher bei Google diese Ansicht.
Dieser Forscher glaubt, dass, obwohl es oberflächlich betrachtet so aussieht, als ob OpenAI und Google bei großen KI-Modellen einander jagen, der wahre Gewinner möglicherweise nicht von diesen beiden kommt, weil eine dritte Partei stillschweigend aufsteigt.
Diese Macht nennt sich „Open Source“. Die gesamte Community konzentriert sich auf Open-Source-Modelle wie Metas LLaMA und erstellt schnell Modelle mit Funktionen, die denen von OpenAI und den großen Modellen von Google ähneln. Darüber hinaus sind Open-Source-Modelle iterativ schneller, anpassbarer und privater ... „Wenn es ist kostenlos, die Menschen zahlen nicht für ein eingeschränktes Modell, wenn die uneingeschränkten Alternativen von gleicher Qualität sind“, schreiben die Autoren.
Dieses Dokument wurde ursprünglich von einer anonymen Person auf einem öffentlichen Discord-Server geteilt. SemiAnalysis, ein zum Nachdruck berechtigtes Branchenmedium, gab an, die Echtheit dieses Dokuments überprüft zu haben.
Dieser Artikel wurde auf sozialen Plattformen wie Twitter stark weitergeleitet. Unter ihnen äußerte Alex Dimakis, Professor an der University of Texas in Austin, die folgende Ansicht:
- Open-Source-KI ist auf dem Vormarsch. Ich stimme zu, dass dies eine gute Sache für die Welt und für den Aufbau eines wettbewerbsfähigen Ökosystems ist. Es ist auch eine gute Sache. Obwohl wir in der LLM-Welt noch nicht so weit sind, haben wir OpenClip gerade openAI Clip geschlagen und Stable Diffusion war besser als das geschlossene Modell.
- Sie benötigen kein riesiges Modell, qualitativ hochwertige Daten sind effektiver und wichtiger und das Alpaka-Modell hinter der API schwächt den Burggraben weiter.
- Sie können mit einem guten Basismodell und einem Parameter Efficient Fine-Tuning (PEFT)-Algorithmus wie Lora beginnen, der an einem Tag sehr gut läuft. Die algorithmische Innovation hat endlich begonnen!
- Universitäten und Open-Source-Communities sollten mehr Anstrengungen unternehmen, um Datensätze zu verwalten, Basismodelle zu trainieren und Feinabstimmungs-Communities wie Stable Diffusion aufzubauen.
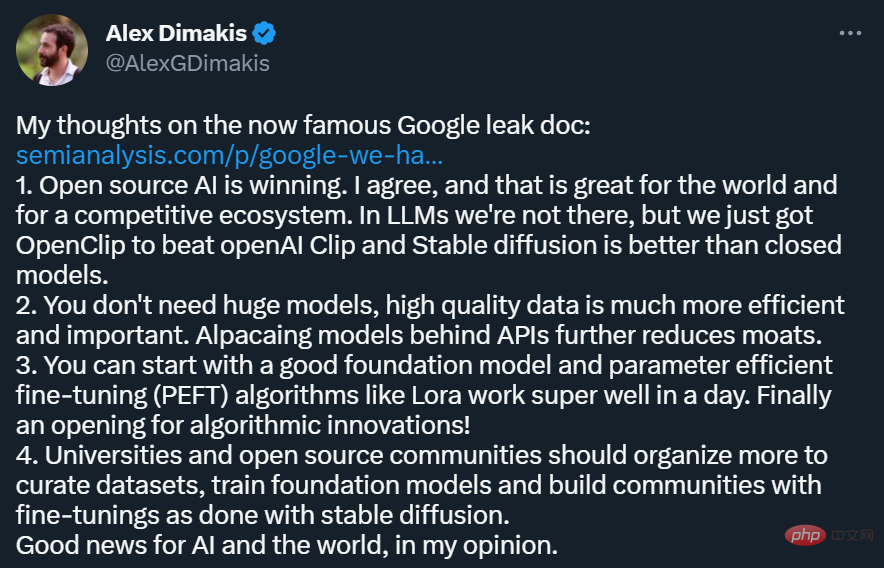
Natürlich stimmen nicht alle Forscher mit den Ansichten im Artikel überein. Einige Leute sind skeptisch, ob Open-Source-Modelle wirklich die Leistungsfähigkeit und Vielseitigkeit großer Modelle haben können, die mit OpenAI vergleichbar sind.
Für die Wissenschaft ist der Aufstieg der Open-Source-Leistung jedoch immer eine gute Sache, was bedeutet, dass Forscher auch dann noch etwas zu tun haben, wenn es nicht 1000 GPUs gibt.
Das Folgende ist der Originaltext des Dokuments:
Weder Google noch OpenAI haben einen Burggraben
Wir haben keinen Burggraben und OpenAI auch nicht.
Wir haben auf die Dynamik und Entwicklung von OpenAI geachtet. Wer schafft den nächsten Meilenstein? Was kommt als nächstes?
Aber die unbequeme Wahrheit ist, dass wir nicht in der Lage sind, dieses Wettrüsten zu gewinnen, und OpenAI auch nicht. Während wir uns stritten, profitierte eine dritte Fraktion davon.
Diese Fraktion ist die „Open-Source-Fraktion“. Ehrlich gesagt sind sie uns voraus. Was wir als „wichtige zu lösende Probleme“ betrachteten, wurde nun gelöst und liegt nun in den Händen der Menschen.
Lass mich dir ein paar Beispiele nennen:
- Großes Sprachmodell, das auf Mobiltelefonen ausgeführt werden kann: Das Basismodell kann auf Pixel 6 mit 5 Token/Sekunde ausgeführt werden.
- Skalierbare persönliche KI: Sie können einen Abend damit verbringen, eine personalisierte KI auf Ihrem Laptop zu optimieren.
- Verantwortungsvolles Publizieren: Dieses Problem ist nicht so sehr „gelöst“, sondern vielmehr „ignoriert“. Einige Websites sind rein künstlerische Modelle ohne jegliche Einschränkungen, und Text bildet da keine Ausnahme.
- Multimodalität: Die aktuelle multimodale wissenschaftliche Qualitätssicherung SOTA wird in weniger als einer Stunde trainiert.
Während unsere Modelle immer noch einen leichten Qualitätsvorsprung haben, schließt sich der Abstand besorgniserregend schnell. Das Open-Source-Modell ist unter den gleichen Bedingungen schneller, anpassbarer, privater und leistungsfähiger. Sie machen etwas mit Parametern von 100 und 13 Milliarden US-Dollar, was uns mit Parametern von 10 Millionen und 54 Milliarden US-Dollar schwerfällt. Und sie können es in Wochen schaffen, nicht in Monaten. Das hat tiefgreifende Auswirkungen auf uns:
- Wir haben kein Geheimrezept. Unsere größte Hoffnung besteht darin, von anderen außerhalb von Google zu lernen und mit ihnen zusammenzuarbeiten. Wir sollten der Erreichung der 3P-Integration Priorität einräumen.
- Menschen zahlen nicht für ein eingeschränktes Modell, wenn die kostenlose, uneingeschränkte Alternative von vergleichbarer Qualität ist. Wir sollten uns überlegen, wo unser Mehrwert liegt.
- Das riesige Modell hat uns ausgebremst. Auf lange Sicht sind die besten Modelle diejenigen, die schnell iteriert werden können. Da wir nun wissen, was Modelle mit weniger als 20 Milliarden Parametern leisten können, sollten wir sie von Anfang an erstellen.
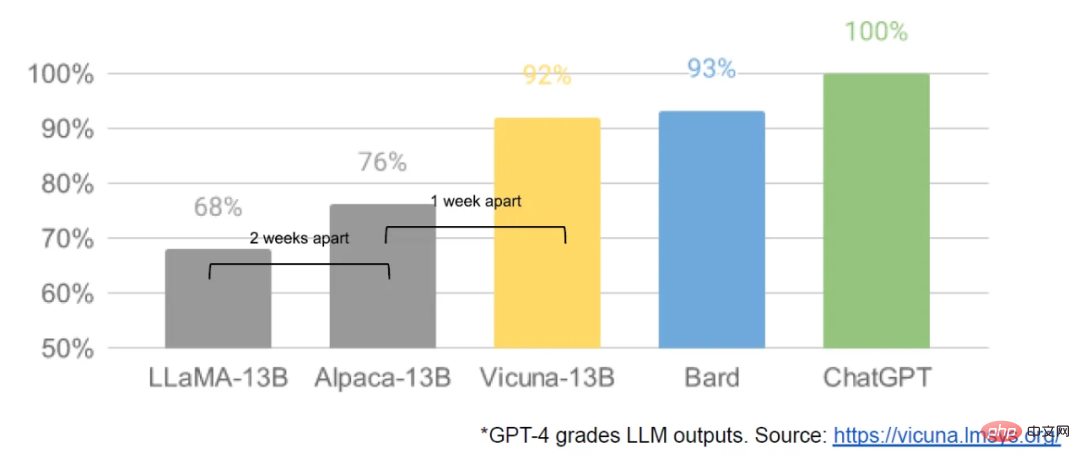
Von LLaMA initiierte Open-Source-Änderungen
Anfang März, als das LLaMA-Modell von Meta an die Öffentlichkeit gelangte, erhielt die Open-Source-Community ihr erstes wirklich nützliches Basismodell. Dieses Modell verfügt über keine Anweisungen oder Dialoganpassungen und kein RLHF. Dennoch erkannte die Open-Source-Community sofort die Bedeutung von LLaMA.
Was folgte, war ein stetiger Innovationsstrom, bei dem große Entwicklungen nur wenige Tage auseinander lagen (z. B. die Ausführung des LLaMA-Modells auf dem Raspberry Pi 4B, die Feinabstimmung der LLaMA-Anweisungen auf einem Laptop, die Ausführung von LLaMA auf einem MacBook, usw.) . Nur einen Monat später erschienen Varianten wie Befehlsfeinabstimmung, Quantisierung, Qualitätsverbesserung, Multimodalität, RLHF usw., von denen viele aufeinander aufbauten.
Das Beste daran ist, dass sie das Skalierungsproblem gelöst haben, was bedeutet, dass jeder dieses Modell frei modifizieren und optimieren kann. Viele neue Ideen kommen von einfachen Menschen. Die Schwelle für Training und Experimente hat sich von großen Forschungseinrichtungen auf eine Person, einen Abend und einen leistungsstarken Laptop verlagert.
LLMs stabiler Diffusionsmoment
In vielerlei Hinsicht sollte dies niemanden überraschen. Die aktuelle Renaissance des Open-Source-LLM folgt auf eine Renaissance der Bilderzeugung, und viele bezeichnen dies als den Moment der stabilen Verbreitung für LLM.
In beiden Fällen wird eine kostengünstige öffentliche Beteiligung durch einen viel günstigeren Feinabstimmungsmechanismus für die Low-Rank-Adaption (LoRA) in Kombination mit einem großen Durchbruch in der Größenordnung erreicht. Die einfache Verfügbarkeit qualitativ hochwertiger Modelle half Einzelpersonen und Institutionen auf der ganzen Welt dabei, eine Pipeline von Ideen aufzubauen, diese zu iterieren und große Unternehmen schnell zu überholen.
Diese Beiträge sind im Bereich der Bilderzeugung von entscheidender Bedeutung und bringen Stable Diffusion auf einen anderen Weg als Dall-E. Ein offenes Modell ermöglichte Produktintegration, Marktplätze, Benutzeroberflächen und Innovationen, die es bei Dall-E nicht gab.
Der Effekt ist offensichtlich: Der kulturelle Einfluss von Stable Diffusion überwiegt schnell im Vergleich zu OpenAI-Lösungen. Ob LLM ähnliche Entwicklungen erleben wird, bleibt abzuwarten, aber die allgemeinen Strukturelemente sind dieselben.
Was hat Google übersehen?
Open-Source-Projekte nutzen innovative Methoden oder Technologien, die Probleme, mit denen wir uns immer noch auseinandersetzen, direkt lösen. Wenn wir auf Open-Source-Bemühungen achten, können wir die gleichen Fehler vermeiden. Unter ihnen ist LoRA eine äußerst leistungsstarke Technologie, der wir mehr Aufmerksamkeit schenken sollten.
LoRA stellt Modellaktualisierungen als Low-Rank-Faktorisierung dar, wodurch die Größe der Aktualisierungsmatrix um das Tausendfache reduziert werden kann. Auf diese Weise erfordert die Feinabstimmung des Modells nur einen geringen Kosten- und Zeitaufwand. Es ist wichtig, die Zeit für die personalisierte Abstimmung von Sprachmodellen auf Hardware für Endverbraucher auf wenige Stunden zu verkürzen, insbesondere für diejenigen mit der Vision, neues und vielfältiges Wissen nahezu in Echtzeit zu integrieren. Während die Technologie einen großen Einfluss auf einige der Projekte hat, die wir durchführen möchten, wird sie bei Google nur unzureichend genutzt.
Die erstaunliche Kraft von LoRA
Ein Grund, warum LoRA so effektiv ist: Genau wie andere Formen der Optimierung ist es stapelbar. Wir können Verbesserungen wie die Feinabstimmung von Befehlen anwenden, um Aufgaben wie Dialog und Argumentation zu erleichtern. Während einzelne Feinabstimmungen einen niedrigen Rang haben, ihre Summe jedoch nicht, ermöglicht LoRA, dass sich Aktualisierungen des Modells mit vollem Rang im Laufe der Zeit ansammeln.
Das bedeutet, dass das Modell kostengünstig aktualisiert werden kann, wenn neuere und bessere Datensätze und Tests verfügbar werden, ohne dass die vollen laufenden Kosten bezahlt werden müssen.
Im Gegensatz dazu macht das Training eines großen Modells von Grund auf nicht nur das Vortraining überflüssig, sondern auch alle vorherigen Iterationen und Verbesserungen. In der Open-Source-Welt setzen sich diese Verbesserungen schnell durch, sodass eine vollständige Umschulung unerschwinglich teuer wird.
Wir sollten ernsthaft darüber nachdenken, ob jede neue Anwendung oder Idee wirklich ein völlig neues Modell erfordert. Wenn wir erhebliche Architekturverbesserungen haben, die eine direkte Wiederverwendung von Modellgewichten ausschließen, sollten wir uns zu einem aggressiveren Destillationsansatz verpflichten, der die Funktionalität der vorherigen Generation so weit wie möglich beibehält.
Große Modelle vs. kleine Modelle, wer ist wettbewerbsfähiger?
Die Kosten für LoRA-Updates sind für die gängigsten Modellgrößen sehr niedrig (ca. 100 US-Dollar). Das bedeutet, dass fast jeder, der eine Idee hat, diese generieren und verbreiten kann. Bei normalen Geschwindigkeiten, bei denen das Training weniger als einen Tag dauert, überwindet der kumulative Effekt der Feinabstimmung schnell den anfänglichen Größennachteil. Tatsächlich verbessern sich diese Modelle viel schneller, als es unsere größten Varianten in Bezug auf die Ingenieurszeit erreichen können. Und die besten Modelle sind von ChatGPT bereits weitgehend nicht zu unterscheiden. Wenn wir uns also auf die Wartung einiger der größten Modelle konzentrieren, sind wir tatsächlich im Nachteil.
Datenqualität geht über Datengröße
Viele dieser Projekte sparen Zeit, indem sie auf kleinen, stark kuratierten Datensätzen trainieren. Dies weist auf Flexibilität bei den Datenskalierungsregeln hin. Dieser Datensatz basiert auf Ideen von „Data Doesn't Do What You Think“ und entwickelt sich schnell zur Standardmethode für das Training ohne Google. Diese Datensätze werden mithilfe synthetischer Methoden erstellt (z. B. durch Herausfiltern der besten Reflexionen aus vorhandenen Modellen) und aus anderen Projekten extrahiert. Beides wird bei Google nicht häufig verwendet. Glücklicherweise sind diese hochwertigen Datensätze Open Source und daher frei verfügbar.
Der Wettbewerb mit Open Source ist zum Scheitern verurteilt
Diese jüngste Entwicklung hat sehr direkte Auswirkungen auf die Geschäftsstrategie. Wer würde für ein Google-Produkt mit Nutzungsbeschränkungen bezahlen, wenn es eine kostenlose, qualitativ hochwertige Alternative ohne Nutzungsbeschränkungen gibt? Außerdem sollten wir nicht damit rechnen, aufzuholen. Das moderne Internet basiert auf Open Source, weil Open Source einige bedeutende Vorteile bietet, die wir nicht reproduzieren können.
„Wir brauchen sie“ mehr als „sie brauchen uns“
Die Wahrung unserer Technologiegeheimnisse ist immer eine fragile Angelegenheit. Google-Forscher reisen regelmäßig zu anderen Unternehmen, um zu studieren, daher kann man davon ausgehen, dass sie alles wissen, was wir wissen. Und das werden sie auch weiterhin tun, solange diese Pipeline offen ist.
Aber da Spitzenforschung im Bereich LLMs erschwinglich wird, wird es immer schwieriger, einen technologischen Wettbewerbsvorteil zu wahren. Forschungseinrichtungen auf der ganzen Welt lernen voneinander, Lösungsräume in einem Breitenansatz zu erkunden, der weit über unsere eigenen Möglichkeiten hinausgeht. Wir können hart daran arbeiten, unsere eigenen Geheimnisse zu bewahren, aber externe Innovationen verwässern ihren Wert, also versuchen Sie, voneinander zu lernen.
Einzelpersonen sind nicht an Lizenzen gebunden wie Unternehmen
Die meisten Innovationen basieren auf von Meta durchgesickerten Modellgewichten. Dies wird sich unweigerlich ändern, da wirklich offene Modelle immer besser werden, aber der Punkt ist, dass sie nicht warten müssen. Der rechtliche Schutz, den die „persönliche Nutzung“ bietet, und die Undurchführbarkeit einer individuellen Strafverfolgung bedeuten, dass Einzelpersonen diese Technologien nutzen können, solange sie noch heiß sind.
Besitzen Sie das Ökosystem: Sorgen Sie dafür, dass Open Source für Sie funktioniert
Paradoxerweise gibt es bei all dem nur einen Gewinner, und das ist Meta, schließlich gehört das durchgesickerte Modell ihnen. Da die meisten Open-Source-Innovationen auf ihrer Architektur basieren, steht einer direkten Integration in die eigenen Produkte nichts im Wege.
Wie Sie sehen, kann der Wert eines Ökosystems nicht hoch genug eingeschätzt werden. Google selbst nutzt dieses Paradigma bereits in Open-Source-Produkten wie Chrome und Android. Durch die Schaffung einer Plattform zur Inkubation innovativer Arbeit hat Google seine Position als Vordenker und Richtungsgeber gefestigt und die Fähigkeit erlangt, Ideen zu entwickeln, die größer sind als das eigene Unternehmen.
Je strenger wir unsere Modelle kontrollieren, desto attraktiver ist es, offene Alternativen zu entwickeln. Sowohl Google als auch OpenAI neigen dazu, ein defensives Release-Modell zu verwenden, das es ihnen ermöglicht, die Verwendung der Modelle streng zu kontrollieren. Diese Kontrolle ist jedoch unrealistisch. Wer LLMs für nicht genehmigte Zwecke nutzen möchte, kann aus frei verfügbaren Modellen wählen.
Deshalb sollte sich Google als führend in der Open-Source-Community positionieren und die Führung übernehmen, indem es an einem breiteren Dialog mitarbeitet, anstatt ihn zu ignorieren. Dies kann einige unbequeme Schritte bedeuten, wie etwa die Freigabe von Modellgewichten für kleine ULM-Varianten. Das bedeutet zwangsläufig auch, dass man einen Teil der Kontrolle über das eigene Modell aufgibt, aber dieser Kompromiss ist unvermeidlich. Wir können nicht darauf hoffen, Innovationen sowohl voranzutreiben als auch zu kontrollieren.
Wo liegt die Zukunft von OpenAI?
Angesichts der aktuellen geschlossenen Richtlinie von OpenAI fühlt sich diese ganze Open-Source-Diskussion unfair an. Wenn sie nicht bereit sind, die Technologie zu teilen, warum sollten wir sie dann teilen? Tatsache ist jedoch, dass wir alles mit ihnen geteilt haben, indem wir kontinuierlich leitende Forscher bei OpenAI abgeworben haben. Solange wir die Flut nicht eindämmen, wird die Geheimhaltung ein umstrittenes Thema bleiben.
Schließlich spielt OpenAI keine Rolle. Sie machen die gleichen Fehler wie wir mit ihrer Open-Source-Haltung, und ihre Fähigkeit, ihren Vorsprung aufrechtzuerhalten, wird zwangsläufig in Frage gestellt. Sofern OpenAI seine Haltung nicht ändert, können und werden Open-Source-Alternativen sie irgendwann in den Schatten stellen. Zumindest in dieser Hinsicht können wir diesen Schritt gehen.
Das obige ist der detaillierte Inhalt vonEin durchgesickertes internes Google-Dokument zeigt, dass es sowohl Google als auch OpenAI an wirksamen Schutzmechanismen mangelt, sodass die Schwelle für große Modelle von der Open-Source-Community kontinuierlich gesenkt wird.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr