
Heim >Technologie-Peripheriegeräte >KI >Wie man ChatGPT vernünftig behandelt: eine ausführliche Diskussion eines zehnjährigen Symbolismusforschers.
Wie man ChatGPT vernünftig behandelt: eine ausführliche Diskussion eines zehnjährigen Symbolismusforschers.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-08 19:28:071665Durchsuche
In den letzten zehn Jahren haben Konnektionisten mit Unterstützung verschiedener Deep-Learning-Modelle die Führung in der Symbolik auf dem Weg der künstlichen Intelligenz übernommen, indem sie die Macht von Big Data und hoher Rechenleistung genutzt haben.
Aber jedes Mal, wenn ein neues großes Deep-Learning-Modell veröffentlicht wird, wie beispielsweise das kürzlich beliebte ChatGPT, wird nach dem Lob seiner leistungsstarken Leistung eine heftige Diskussion über die Forschungsmethode selbst geführt, und auch die Lücken und Mängel des Modells selbst werden zutage treten .
Kürzlich veröffentlichte Dr. Qian Xiaoyi vom Beiming Laboratory als Wissenschaftler und Unternehmer, der seit zehn Jahren der symbolischen Schule angehört, eine relativ ruhige und objektive Bewertung des ChatGPT-Modells.
Insgesamt halten wir ChatGPT für eine bahnbrechende Veranstaltung.
Das Pre-Training-Modell zeigte vor einem Jahr starke Auswirkungen. Dieses Mal hat es ein neues Niveau erreicht und mehr Aufmerksamkeit erregt. Nach diesem Meilenstein werden sich viele Arbeitsmodelle im Zusammenhang mit der menschlichen natürlichen Sprache ändern Ein großer Teil davon wurde durch Maschinen ersetzt.
Keine Technologie wird über Nacht erreicht, anstatt ihre Mängel zu erkennen, sollte ein wissenschaftlicher Mitarbeiter sensibler für ihr Potenzial sein.
Die Grenze von Symbolismus und Konnektionismus
Unser Team widmet ChatGPT dieses Mal besondere Aufmerksamkeit, nicht wegen der erstaunlichen Effekte, die die Öffentlichkeit sieht, denn wir können viele scheinbar erstaunliche Effekte immer noch auf technischer Ebene verstehen.
Was unsere Sinne wirklich beeinflusst, ist, dass einige seiner Aufgaben die Grenzen zwischen dem symbolischen Genre und dem neuronalen Genre durchbrechen – die logische Fähigkeit scheint diese Fähigkeit in mehreren Aufgaben wie der Selbstkodierung und der Auswertung von Code zu verkörpern.
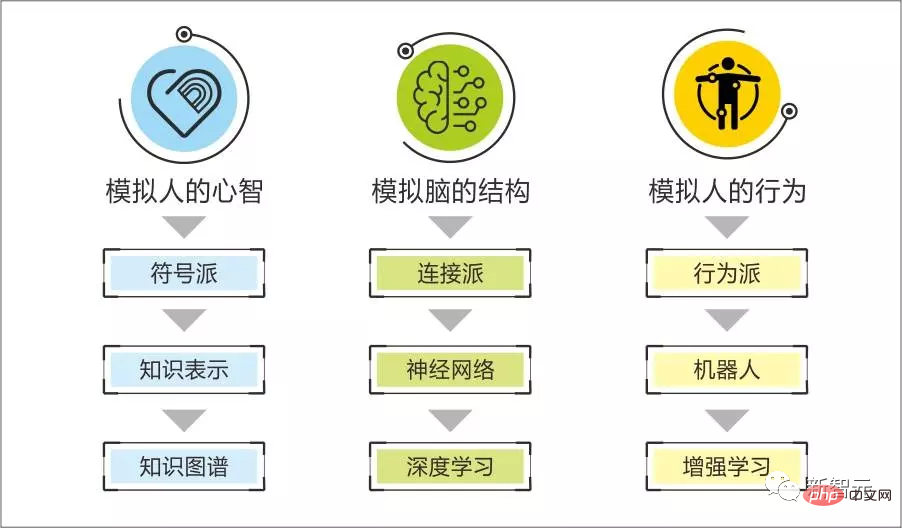
Wir haben immer geglaubt, dass die symbolische Schule gut darin ist, die starke logische Intelligenz des Menschen zu reproduzieren, z. B. wie man ein Problem löst, die Ursache eines Problems analysiert, ein Werkzeug erstellt usw.
Und Konnektionismus ist im Wesentlichen ein statistischer Typ. Algorithmen werden verwendet, um glatte Muster aus Stichproben zu entdecken, z. B. das Finden des Musters dessen, was im nächsten Satz gesagt werden soll, durch Finden des Musters der entsprechenden Bilderkennung und -generierung durch beschreibenden Text ...
Wir können Sie durch das Verständnis dieser Fähigkeiten durch größere Modelle, qualitativ hochwertigere Daten und Verbesserungen der Reinforcement-Learning-Schleife hervorheben.
Wir glauben, dass Menschen über die Eigenschaften sowohl symbolischer als auch neuronaler technischer Pfade verfügen, wie z. B. alle reflexiven kognitiven Prozesse, Wissenserwerbs- und -anwendungsprozesse, eine große Anzahl reflexiver Denkweisen, Verhaltensweisen, Ausdrucksmuster, reflexiver Motivationen und Emotionen. Sie alle sind vorhanden leicht zu interpretieren und systematisch auf der Grundlage symbolischer Darstellung zu reproduzieren.
Wenn Sie genügend fremde Gesichter sehen, können Sie fremde Gesichter erkennen, und Sie können nicht erklären, warum.
Sie werden natürlich die Fähigkeit haben, die Sprache des männlichen Protagonisten nachzuahmen, nachdem Sie die erste Fernsehserie gesehen haben Die Fähigkeit, ohne nachzudenken zu chatten, nachdem man genügend Gespräche geführt hat, sind allesamt neurologische Merkmale.
Wir können den starken logischen Teil mit wachsenden Knochen vergleichen und die „unlogische Fähigkeit, Gesetze zu begreifen“ mit wachsendem Fleisch.
Es ist schwierig, mit der Fähigkeit des Symbols „das Skelett wachsen lassen“ „Fleisch wachsen zu lassen“, und es ist auch schwierig für die Nerven, mit der Fähigkeit „das Fleisch wachsen zu lassen“ „das Skelett wachsen zu lassen“.
So wie wir den KI-Aufbauprozess begleiten, ist das Symbolsystem gut darin, die spezifischen Dimensionen der Informationen des Gesprächspartners zu erfassen, die dahinter stehenden Absichten zu analysieren, verwandte Ereignisse abzuleiten und präzise Vorschläge zu machen, aber es ist nicht gut im Schaffen reibungslose und natürliche Gespräche.
Wir haben auch gesehen, dass das durch GPT dargestellte Dialoggenerierungsmodell zwar einen reibungslosen Dialog erzeugen kann, aber das Langzeitgedächtnis nutzt, um kohärente Kameradschaft zu schaffen, vernünftige emotionale Motivationen zu erzeugen und logisches Denken mit einer gewissen Tiefe zu liefern, um Analysevorschläge zu geben. Es ist schwierig, diese Aspekte zu realisieren.
Die „Größe“ eines großen Modells ist kein Vorteil, sondern der Preis, den statistische Algorithmen für den Versuch zahlen, einen Teil der starken logischen Gesetze zu erfassen, die Oberflächendaten innewohnen. Es verkörpert die Grenze zwischen Symbolen und Nerven.
Nachdem wir ein tieferes Verständnis der Prinzipien von ChatGPT erlangt hatten, stellten wir fest, dass es nur relativ einfache logische Operationen als reguläre Trainingsgeneration betrachtet und den Umfang des ursprünglichen statistischen Algorithmus – also den Verbrauch des Systems – nicht durchbricht . Es wird immer noch geometrisch wachsen, wenn die Tiefe der logischen Aufgaben zunimmt.
Aber warum kann ChatGPT die Grenzen des ursprünglichen großen Modells durchbrechen?
Wie ChatGPT die technischen Grenzen gewöhnlicher großer Modelle durchbricht
Lassen Sie uns in nicht-technischer Sprache die Prinzipien erklären, die dahinterstecken, wie ChatGPT die Grenzen anderer großer Modelle durchbricht.
GPT3 zeigte bei seinem Erscheinen ein Erlebnis, das andere große Modelle übertraf. Dies hängt mit der Selbstüberwachung, also der Selbstkennzeichnung von Daten, zusammen.
Nehmen wir immer noch das Beispiel der Dialoggenerierung: Ein großes Modell wurde mit umfangreichen Daten trainiert, um die Regeln von 60 Dialogrunden und dem nächsten Satz zu beherrschen.
Warum benötigen Sie so viele Daten? Warum können Menschen die Sprache des männlichen Protagonisten nachahmen, nachdem sie eine Fernsehserie gesehen haben?
Weil Menschen die vorherigen Dialogrunden nicht als Input nutzen, um die Regeln dafür zu erfassen, was im nächsten Satz gesagt werden soll, sondern sich während des subjektiven Dialogprozesses ein Verständnis für den Kontext bilden: die Persönlichkeit des Sprechers und welche Art Welche aktuellen Emotionen er hat, welche Motivation er hat, welche Art von Wissen damit verbunden ist, plus die vorherigen Dialogrunden, um die Regeln zu verstehen, was im nächsten Satz gesagt werden soll.
Wir können uns vorstellen, dass, wenn das große Modell zunächst die Kontextelemente des Dialogs identifiziert und diese dann verwendet, um die Regeln des nächsten Satzes zu generieren, im Vergleich zur Verwendung des ursprünglichen Dialogs die Datenanforderungen erfüllt werden Der gleiche Effekt kann stark reduziert werden. Daher ist die Qualität der Selbstüberwachung ein wichtiger Faktor, der die „Modelleffizienz“ großer Modelle beeinflusst.
Um zu untersuchen, ob ein großer Modelldienst während des Trainings bestimmte Arten von Kontextinformationen selbst gekennzeichnet hat, können Sie untersuchen, ob die Dialoggenerierung auf solche Kontextinformationen reagiert (ob der generierte Dialog diese Kontextinformationen widerspiegelt). Informationen) zu beurteilen.
Das menschliche Schreiben des gewünschten Outputs ist der zweite Punkt, der ins Spiel kommt.
ChatGPT verwendet manuell geschriebene Ausgaben in verschiedenen Aufgabentypen, um das große Modell von GPT3.5 zu verfeinern, das die allgemeinen Regeln der Dialoggenerierung gelernt hat.
Das ist der Geist des Pre-Training-Modells – die Dialogregeln einer geschlossenen Szene spiegeln möglicherweise tatsächlich mehr als 99 % der allgemeinen Regeln der menschlichen Dialoggenerierung wider, während die szenenspezifischen Regeln weniger ausmachen als 1 % . Daher können ein großes Modell, das darauf trainiert wurde, die allgemeinen Regeln des menschlichen Dialogs zu erfassen, und ein zusätzliches kleines Modell für geschlossene Szenen verwendet werden, um den Effekt zu erzielen, und die zum Trainieren der spezifischen Regeln der Szene verwendeten Beispiele können sehr klein sein.

Der nächste Mechanismus, der ins Spiel kommt, ist, dass ChatGPT Verstärkungslernen integriert. Der gesamte Prozess ist ungefähr so:
Beginnt mit der Vorbereitung: ein vorab trainiertes Modell (GPT-3.5), eine Gruppe gut geschulter Labore, eine Reihe von Eingabeaufforderungen (Anweisungen oder Fragen, gesammelt aus dem Nutzungsprozess einer großen Anzahl von Benutzern und dem Design des Labors). .
Schritt 1: Nehmen Sie eine zufällige Stichprobe und erhalten Sie eine große Anzahl von Eingabeaufforderungen, und das Datenpersonal (Labor) stellt auf der Grundlage der Eingabeaufforderungen standardisierte Antworten bereit. Datenwissenschaftler können Eingabeaufforderungen in GPT-3.5 eingeben und auf die Ausgabe des Modells verweisen, um bei der Bereitstellung kanonischer Antworten zu helfen.
Auf diese Weise können Daten
Basierend auf diesem Datensatz wird das GPT-3.5-Modell durch überwachtes Lernen verfeinert. Das nach der Verfeinerung erhaltene Modell wird vorübergehend GPT-3.X genannt.
Schritt2: Probieren Sie nach dem Zufallsprinzip einige Eingaben aus (die meisten davon wurden in Schritt 1 ausgewählt) und generieren Sie K Antworten (K>=2) über GPT-3.X für jede Eingabe.
Laber sortiert die K-Antworten. Eine große Menge sortierter Vergleichsdaten kann einen Datensatz bilden, und auf der Grundlage dieses Datensatzes kann ein Bewertungsmodell trainiert werden.
Schritt 3: Verwenden Sie die Verstärkungslernstrategie PPO, um GPT-3.X und das Bewertungsmodell iterativ zu aktualisieren und schließlich das Richtlinienmodell zu erhalten. GPT-3.X initialisiert die Parameter des Richtlinienmodells, prüft einige Eingabeaufforderungen, die in Schritt 1 und Schritt 2 nicht erfasst wurden, generiert eine Ausgabe über das Richtlinienmodell und bewertet die Ausgabe mithilfe des Bewertungsmodells.
Aktualisieren Sie die Parameter des Richtlinienmodells basierend auf dem durch die Bewertung generierten Richtliniengradienten, um ein leistungsfähigeres Richtlinienmodell zu erhalten.
Lassen Sie ein starkes Strategiemodell an Schritt 2 teilnehmen, erhalten Sie durch Laber-Sortierung und Annotation einen neuen Datensatz und aktualisieren Sie ihn, um ein vernünftigeres Bewertungsmodell zu erhalten.
Wenn das aktualisierte Bewertungsmodell an Schritt 3 teilnimmt, wird ein aktualisiertes Strategiemodell erhalten. Führen Sie Schritt 2 und Schritt 3 iterativ aus, und das endgültige Richtlinienmodell ist ChatGPT.
Wenn Sie mit der oben genannten Sprache nicht vertraut sind, finden Sie hier eine leicht verständliche Metapher: Dies ist, als würde man ChatGPT bitten, Kampfkunst zu lernen. Die menschliche Antwort ist die Routine des Meisters Für einen Kampfsportbegeisterten ist das bewertende neuronale Netzwerk ein Bewerter, der ChatGPT mitteilt, wer in jedem Spiel besser abgeschnitten hat.
So kann ChatGPT zum ersten Mal den Vergleich zwischen menschlichen Meistern und GPT3.5 beobachten, ihn auf der Basis von GPT3.5 ein wenig in Richtung menschlicher Meister verbessern und dann die Weiterentwicklung durchführen lassen ChatGPT Als Kampfsportbegeisterter, der am Vergleich mit menschlichen Meistern teilnimmt, sagt ihm das bewertende neuronale Netzwerk noch einmal, wo die Lücke ist, damit er wieder besser werden kann.
Was ist der Unterschied zwischen diesem und einem herkömmlichen neuronalen Netzwerk?
Das traditionelle neuronale Netzwerk ermöglicht es einem neuronalen Netzwerk direkt, einen menschlichen Meister zu imitieren, und dieses neue Modell ermöglicht es dem neuronalen Netzwerk, den Unterschied zwischen einem bereits guten Kampfsportbegeisterten und einem Meister zu erfassen, sodass es dies kann Bauen Sie auf dem Vorhandenen auf. Nehmen Sie subtile Anpassungen in Richtung menschlicher Meister vor und verbessern Sie sich weiter.
Aus dem obigen Prinzip ist ersichtlich, dass das auf diese Weise generierte große Modell vom Menschen markierte Proben als Leistungsgrenze verwendet.
Mit anderen Worten: Es beherrscht die Antwortmuster von menschlich markierten Proben nur bis zum Äußersten, verfügt jedoch nicht über die Fähigkeit, neue Antwortmuster zu erstellen wirkt sich auf die Modellausgabe aus. Die Genauigkeit von ChatGPT ist ein schwerwiegender Fehler in den Such- und Beratungsszenarien.
Die Anforderungen an ähnliche Gesundheitsberatungen sind streng, was für die eigenständige Durchführung dieser Art von Modell nicht geeignet ist.
Die von ChatGPT verkörperten Codierungsfunktionen und Codeauswertungsfunktionen stammen aus einer großen Anzahl von Codes, Codebeschreibungsanmerkungen und Änderungsdatensätzen auf Github. Dies liegt immer noch im Bereich statistischer Algorithmen.
ChatGPT sendet ein gutes Signal, dass wir tatsächlich mehr Ideen wie „Human Focus“ und „Reinforcement Learning“ nutzen können, um die „Modelleffizienz“ zu verbessern.
„Groß“ ist nicht mehr der einzige Indikator, der mit den Modellfähigkeiten verknüpft ist. Beispielsweise ist InstructGPT mit 1,3 Milliarden Parametern besser als GPT-3 mit 17,5 Milliarden Parametern.
Da der Verbrauch von Rechenressourcen durch Training jedoch nur einer der Schwellenwerte für große Modelle ist, gefolgt von hochwertigen und umfangreichen Daten, glauben wir, dass die frühe Geschäftslandschaft immer noch ist: Große Hersteller bieten große Modelle für den Infrastrukturbau an, auf deren Grundlage kleine Fabriken Superanwendungen herstellen. Die kleinen Fabriken, die zu Riesen geworden sind, werden dann ihre eigenen großen Modelle ausbilden.
Die Kombination von Symbolen und Nerven
Wir glauben, dass sich das Potenzial der Kombination von Symbolen und Nerven in zwei Punkten widerspiegelt: dem Training von „Fleisch“ auf „Knochen“ und der Verwendung „Knochen“ „Fleisch“.
Wenn die Oberflächenprobe einen starken logischen Kontext (Knochen) enthält, wie im vorherigen Beispiel des Dialogtrainings, ist das Kontextelement der Knochen, dann ist es sehr hilfreich, einfach die Regeln zu trainieren, die die Knochen aus der Oberflächenprobe enthalten kostspielig, was sich in der Nachfrage nach Mustern und den Kosten für ein höheres Modelltraining widerspiegelt, also in der „Größe“ großer Modelle.
Wenn wir ein symbolisches System verwenden, um Kontext zu generieren und ihn als Beispieleingabe für das neuronale Netzwerk zu verwenden, ist dies gleichbedeutend damit, Muster in den Hintergrundbedingungen einer starken logischen Erkennung zu finden und „Fleisch“ darauf zu trainieren „Knochen“.
Wenn ein großes Modell auf diese Weise trainiert wird, reagiert seine Ausgabe empfindlich auf starke logische Bedingungen.
Zum Beispiel geben wir in der Dialoggenerierungsaufgabe die aktuellen Emotionen, Motivationen, zugehörigen Kenntnisse und zugehörigen Ereignisse beider am Dialog beteiligten Parteien ein. Der vom großen Modell generierte Dialog kann diese kontextuell widerspiegeln Informationen mit einer bestimmten Wahrscheinlichkeit. Dies ist die Verwendung von „Fleisch“ auf den „Knochen“ einer starken Logik.
Bisher sind wir auf das Problem gestoßen, dass Symbole bei der Entwicklung der KI auf Begleiterebene keine reibungslosen Gespräche ermöglichen können. Wenn der Benutzer nicht bereit ist, mit der KI zu sprechen, sind alle logischen und emotionalen Fähigkeiten hinter der KI vorhanden kann nicht angezeigt werden und es besteht keine Möglichkeit zur kontinuierlichen Um die Iterationsbedingungen zu optimieren, haben wir die Glätte des Dialogs durch eine ähnliche Kombination wie oben und das vorab trainierte Modell gelöst.
Aus der Sicht großer Modelle mangelt es der einfachen Erstellung von KI mit großen Modellen an Integrität und Dreidimensionalität.
„Ganzheitlichkeit“ spiegelt sich vor allem darin wider, ob das kontextbezogene Langzeitgedächtnis bei der Dialoggenerierung berücksichtigt wird.
Zum Beispiel wurde im Chat zwischen der KI und dem Benutzer am Vortag darüber gesprochen, dass der Benutzer eine Erkältung hatte, ins Krankenhaus ging, verschiedene Symptome hatte und wie lange diese anhielt. ..; am nächsten Tag äußerte der Benutzer plötzlich „Ich habe Halsschmerzen“ Es tut so weh.“
In einem einfachen großen Modell antwortet die KI mit dem Inhalt im Kontext und drückt aus: „Warum tut dir der Hals weh?“ „Warst du im Krankenhaus?“ … Diese Ausdrücke sind Das unmittelbare und das langfristige Gedächtnis sind widersprüchlich und spiegeln Inkonsistenzen im Langzeitgedächtnis wider.
Durch die Kombination von KI und Symbolsystemen kann die KI von „Der Benutzer hat am nächsten Tag immer noch Halsschmerzen“ über „Der Benutzer hatte gestern eine Erkältung“ bis hin zu „Der Benutzer war im …“ zuordnen Krankenhaus“ und „die anderen Symptome des Benutzers“ … Bringen Sie diese Informationen in einen Kontext, sodass die Kontextkonsistenzfähigkeit des großen Modells genutzt werden kann, um die Konsistenz des Langzeitgedächtnisses widerzuspiegeln.
Der „dreidimensionale Sinn“ spiegelt sich darin wider, ob die KI besessen ist.
Werden Sie wie Menschen von Ihren eigenen Emotionen, Motivationen und Ideen besessen sein? Die von einem einfachen großen Modell erstellte KI erinnert eine Person nach dem Zufallsprinzip daran, beim geselligen Beisammensein weniger zu trinken. In Kombination mit dem Symbolsystem erkennt sie jedoch, dass die Leber des Benutzers im Langzeitgedächtnis nicht gut ist, und kombiniert sie mit dem Gemeinsamen Wenn Sie das Gefühl haben, dass die Leber des Benutzers nicht in Ordnung ist und er nicht trinken kann, wird eine starke und kontinuierliche Meldung generiert, um den Benutzer vom Trinken abzuhalten. Es wird empfohlen, nachzuverfolgen, ob der Benutzer nach dem geselligen Beisammensein Alkohol trinkt und ob es ihm an Selbstdisziplin mangelt beeinflussen die Stimmung und damit das anschließende Gespräch. Dies ist eine Widerspiegelung des dreidimensionalen Sinnes.
Ist das große Vorbild eine allgemeine künstliche Intelligenz?
Dem Implementierungsmechanismus des Pre-Training-Modells nach zu urteilen, wird die Fähigkeit statistischer Algorithmen, „Mustermuster zu erfassen“, lediglich ausgenutzt auf einem sehr hohen Niveau und spiegelt sogar die Illusion wider, dass es über bestimmte logische Fähigkeiten und Lösungsfähigkeiten verfügt.
Ein einfaches vorab trainiertes Modell verfügt nicht über menschliche Kreativität, tiefe logische Denkfähigkeiten und die Fähigkeit, komplexe Aufgaben zu lösen.
Daher verfügt das vorab trainierte Modell aufgrund der kostengünstigen Migration auf bestimmte Szenarien über eine gewisse Vielseitigkeit, verfügt jedoch nicht über die Vielseitigkeit des Menschen, „die sich ständig ändernden intelligenten Darstellungen der oberen Schicht zu verallgemeinern“. durch begrenzte zugrunde liegende Intelligenzmechanismen“ intelligent.
Zweitens möchten wir über „Emergenz“ sprechen. Bei der Untersuchung großer Modelle werden Forscher feststellen, dass einige Fähigkeitsindikatoren schnell ansteigen, wenn die Modellparameterskala und die Datenskala bestimmte kritische Werte überschreiten Emergenzeffekt.
Tatsächlich zeigt jedes System mit abstrakten Lernfähigkeiten „Emergenz“.
Dies hängt mit der Natur abstrakter Operationen zusammen – „nicht besessen von der Richtigkeit einzelner Stichproben oder Vermutungen, sondern basierend auf der statistischen Richtigkeit der gesamten Stichprobe oder Vermutung.“
Wenn also die Stichprobengröße ausreichend ist und das Modell die Entdeckung detaillierter Muster in den Stichproben unterstützen kann, wird plötzlich eine bestimmte Fähigkeit gebildet.
In semi-symbolischen Denkprojekten sehen wir, dass der Prozess des Sprachlernens der symbolischen KI bis zu einem gewissen Grad auch wie der Spracherwerb menschlicher Kinder „entstehen“ wird Das Verständnis und die Sprechfähigkeit werden sich sprunghaft verbessern.
Kurz gesagt, es ist für uns in Ordnung, Emergenz als Phänomen zu betrachten, aber wir sollten alle Systemfunktionsmutationen mit unklaren Mechanismen als Emergenz interpretieren und erwarten, dass ein einfacher Algorithmus mit der Gesamtintelligenz des Menschen entstehen kann Gewissermaßen ist dies keine streng wissenschaftliche Haltung.
Allgemeine künstliche Intelligenz
Das Konzept der künstlichen Intelligenz entstand fast mit dem Aufkommen von Computern. Es war eine einfache Idee, menschliche Intelligenz in Computer zu übertragen ist der Ausgangspunkt der künstlichen Intelligenz. Das früheste Konzept der künstlichen Intelligenz bezieht sich auf „allgemeine künstliche Intelligenz“.
Das Intelligenzmodell des Menschen ist allgemeine Intelligenz, und die Übertragung dieses Intelligenzmodells auf Computer ist allgemeine künstliche Intelligenz.
Seitdem sind viele Schulen entstanden, die versuchen, den Mechanismus der menschlichen Intelligenz zu reproduzieren, aber keine dieser Schulen hat herausragende Ergebnisse erzielt, so dass Rich Sutton, der herausragende Wissenschaftler von Deepmind und Begründer der Verstärkung Lernen, stark ausgedrückt einen Standpunkt :
Die größte Lektion, die aus den letzten 70 Jahren der Forschung im Bereich der künstlichen Intelligenz gelernt werden kann, ist, dass Forscher mehr tun, um kurzfristig Ergebnisse zu erzielen neigen dazu, menschliche Erfahrung und Wissen über den Mechanismus zu nutzen (Nachahmung von Menschen), und auf lange Sicht ist die Verwendung skalierbarer allgemeiner Rechenmethoden letztendlich effektiv.
Die herausragenden Leistungen des heutigen großen Modells beweisen die Richtigkeit seines Vorschlags des „Algorithmus“, aber das bedeutet nicht, dass der Weg der Schaffung intelligenter Agenten durch „Nachahmung der Schöpfung und Schaffung von Menschen“ notwendigerweise falsch ist.
Warum mussten die bisherigen Schulen der Menschennachahmung einen nach dem anderen Rückschläge hinnehmen? Dies hängt mit der Integrität des Kerns der menschlichen Intelligenz zusammen.
Einfach ausgedrückt unterstützen sich die aus menschlicher Sprache, Kognition, emotionaler Entscheidungsfindung und Lernfähigkeit gebildeten Subsysteme gegenseitig bei der Umsetzung der meisten Aufgaben, und kein Subsystem kann unabhängig voneinander laufen.
Da es sich um ein hochintegriertes System handelt, entsteht ein Erscheinungsbild auf der oberen Ebene durch das Zusammenwirken vieler zugrunde liegender Mechanismen. Solange einer von ihnen fehlerhaft ist, wird dies das Erscheinungsbild dieses Oberflächeneffekts beeinflussen.
Genau wie der menschliche Körper ist es auch ein sehr komplexes System. Es mag subtile Unterschiede zwischen einem gesunden und einem kranken Menschen geben, aber dieser subtile pathologische Unterschied hemmt die Funktionen eines Menschen in allen Dimensionen.
Auch bei der allgemeinen künstlichen Intelligenz kann die Wirkung der ersten 99 Schritte sehr begrenzt sein. Wenn wir das letzte Puzzleteil fertigstellen, werden die Funktionen der ersten 99 Schritte offensichtlich.
Frühere Schulen haben einen Teil der menschlichen Gesamtintelligenz aus ihrer eigenen Perspektive gesehen und auch gewisse Ergebnisse bei der Nachahmung von Menschen erzielt, aber das ist nur ein Bruchteil im Vergleich zu der Energie, die das Gesamtsystem freisetzen kann. .
Prozessintelligenz und menschliche Zivilisation
Jede lokale Intelligenz des Menschen wurde oder wird von Computern weit übertroffen, aber selbst wenn die gesamte lokale Intelligenz von Computern übertroffen wird, sind wir es Man kann immer noch behaupten, dass nur der Mensch eine Zivilisation schaffen kann und Computer nur Werkzeuge sind.
Warum?
Denn hinter der Entstehung der Zivilisation steht der Prozess verschiedener menschlicher intelligenter Aktivitäten, was bedeutet, dass die menschliche Zivilisation aus „Prozessintelligenz“ hervorgeht. Dies ist eine Richtung, die derzeit stark vernachlässigt wird.
„Kognitiver Prozess“ ist keine Aufgabe, sondern die Organisation vieler Aufgaben in einem Prozess.
Wenn KI beispielsweise die Symptome von Patienten heilen möchte, handelt es sich um eine „Ziellösung“-Aufgabe.
Zunächst müssen wir zur Attributionslösung übergehen, die als kognitive Aufgabe angesehen wird. Nachdem wir die möglichen Ursachen gefunden haben, wird es zur Aufgabe, „das Auftreten bestimmter Ereignisse zu lösen“, um festzustellen, ob die Möglicherweise ist auch diese Aufgabe aufgetreten. Es wird weiterhin zerlegt und auf andere Aufgaben übertragen. Wenn es dabei an Wissen mangelt, wird es zu einer Aufgabe der „Wissenslösung“.
Sie können vorhandenes Wissen durch Fragen, Suchen und Lesen erhalten, oder Sie können „statistische Erkenntnis“ nutzen, nachdem die statistische Erkenntnis Korrelationen entdeckt hat, um weitere Einblicke in die dahinter stehende Kausalkette zu gewinnen, um bessere Ergebnisse zu erzielen In dieser Phase wird der Mangel an Wissen oft auf die Lösung des Wissens umgestellt. Um die Vermutung zu überprüfen, ist es notwendig, Experimente zu entwerfen, um das Auftreten spezifischer Ereignisse zu lösen...
Nachher Wenn Sie die Kausalkette haben, können Sie versuchen, das Ziel erneut zu erreichen, in die Kausalkette einzugreifen und das ursprüngliche Ziel in die Schaffung, Beendigung, Verhinderung und Aufrechterhaltung von Ereignissen in der Kausalkette umzuwandeln. Dies ist wieder ein Prozess der „Ziellösung“. „...
#🎜🎜 #
Wir können uns vorstellen, dass, wenn wir die Gesamtintelligenz des Menschen auf Computern reproduzieren können, sodass Maschinen den Prozess der unabhängigen Erforschung von Erkenntnissen, der Erstellung von Werkzeugen, der Lösung von Problemen und dem Erreichen von Zielen unterstützen können, mit dem Trägervorteil von Computern, die Gesamtintelligenz und Prozessintelligenz des Menschen Nur dann können wir die Kraft der künstlichen Intelligenz wirklich entfesseln und die menschliche Zivilisation auf ein neues Niveau heben, wenn wir sie nach wie vor verstärken.
Über den Autor

Der Autor Dr. Qian Xiaoyi ist ein symbolischer Wissenschaftler für künstliche Intelligenz, leitender Ingenieur, hochqualifiziertes Talent in Hangzhou, ein früher Entdecker des logischen bionischen Frameworks und der Schöpfer der ersten Version des M-Sprachsymbolsystems. Gründer, CEO und Vorsitzender von Bei Mingxing Mou.
Ph.D. in Angewandter Wirtschaftswissenschaften von der Shanghai Jiao Tong University, Master of Financial Engineering von der CGU Drucker School of Business, USA, und Doppel-Bachelor-Abschluss in Mathematik und Finanzen von der Yau Shing-tung Mathematics Elite Class der Zhejiang University, Zhu Kezhen College. Er forscht seit 11 Jahren im allgemeinen KI-Bereich und leitet das Team seit 7 Jahren in der Ingenieurpraxis.
Das obige ist der detaillierte Inhalt vonWie man ChatGPT vernünftig behandelt: eine ausführliche Diskussion eines zehnjährigen Symbolismusforschers.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr