
Heim >Technologie-Peripheriegeräte >KI >HuggingGPT: Ein magisches Werkzeug für KI-Aufgaben
HuggingGPT: Ein magisches Werkzeug für KI-Aufgaben

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-08 18:40:191532Durchsuche
Einführung
Künstliche Allgemeine Intelligenz (AGI) kann als ein künstliches Intelligenzsystem betrachtet werden, das in der Lage ist, intellektuelle Aufgaben wie Menschen zu verstehen, zu verarbeiten und darauf zu reagieren. Dies ist eine herausfordernde Aufgabe, die ein tiefes Verständnis der Funktionsweise des menschlichen Gehirns erfordert, damit wir es nachbilden können. Das Aufkommen von ChatGPT hat jedoch in der Forschungsgemeinschaft großes Interesse an der Entwicklung solcher Systeme geweckt. Microsoft hat ein so wichtiges KI-gestütztes System namens HuggingGPT (Microsoft Jarvis) veröffentlicht.
Bevor wir uns mit den Neuerungen in HuggingGPT und den relevanten Details seiner Funktionsweise befassen, wollen wir zunächst die Probleme mit ChatGPT verstehen und erklären, warum es Schwierigkeiten bei der Lösung komplexer KI-Aufgaben hat. Große Sprachmodelle wie ChatGPT eignen sich gut für die Interpretation von Textdaten und die Bewältigung allgemeiner Aufgaben. Allerdings tun sie sich bei bestimmten Aufgaben oft schwer und können absurd reagieren. Möglicherweise sind Sie beim Lösen komplexer mathematischer Probleme auf gefälschte Antworten von ChatGPT gestoßen. Auf der anderen Seite haben wir KI-Modelle auf Expertenebene wie Stable Diffusion und DALL-E, die über ein tieferes Verständnis ihrer jeweiligen Fachgebiete verfügen, aber mit einem breiteren Aufgabenspektrum zu kämpfen haben. Wenn wir keine Verbindung zwischen LLM und professionellen KI-Modellen herstellen, können wir das Potenzial von LLM zur Lösung anspruchsvoller KI-Aufgaben nicht voll ausschöpfen. Genau das macht HuggingGPT: Es kombiniert die Vorteile beider, um ein effektiveres, genaueres und vielseitigeres KI-System zu schaffen.
Was ist HuggingGPT?
Laut einem kürzlich von Microsoft veröffentlichten Artikel nutzt HuggingGPT die Leistungsfähigkeit von LLM als Controller, indem es es mit verschiedenen KI-Modellen in der Community für maschinelles Lernen (HuggingFace) verbindet und so die Verwendung externer Tools zur Verbesserung der Arbeitseffizienz ermöglicht. HuggingFace ist eine Website, die Entwicklern und Forschern unzählige Tools und Ressourcen zur Verfügung stellt. Darüber hinaus gibt es eine große Auswahl an professionellen und hochpräzisen Modellen. HuggingGPT wendet diese Modelle auf komplexe KI-Aufgaben in verschiedenen Bereichen und Modi an und erzielt beeindruckende Ergebnisse. Es verfügt über ähnliche multimodale Fähigkeiten wie OPenAI GPT-4, wenn es um Text und Bilder geht. Es stellt jedoch auch eine Verbindung zum Internet her und Sie können einen externen Weblink bereitstellen, um Fragen dazu zu stellen.
Angenommen, Sie möchten, dass das Modell den auf einem Bild geschriebenen Text per Audio vorliest. HuggingGPT führt diese Aufgabe seriell mit dem am besten passenden Modell aus. Zunächst wird Text aus dem Bild exportiert und das Ergebnis für die Audiogenerierung verwendet. Die Antwortdetails können im Bild unten angezeigt werden. Einfach großartig!

Qualitative Analyse der multimodalen Zusammenarbeit von Video- und Audiomodi
Wie funktioniert HuggingGPT?
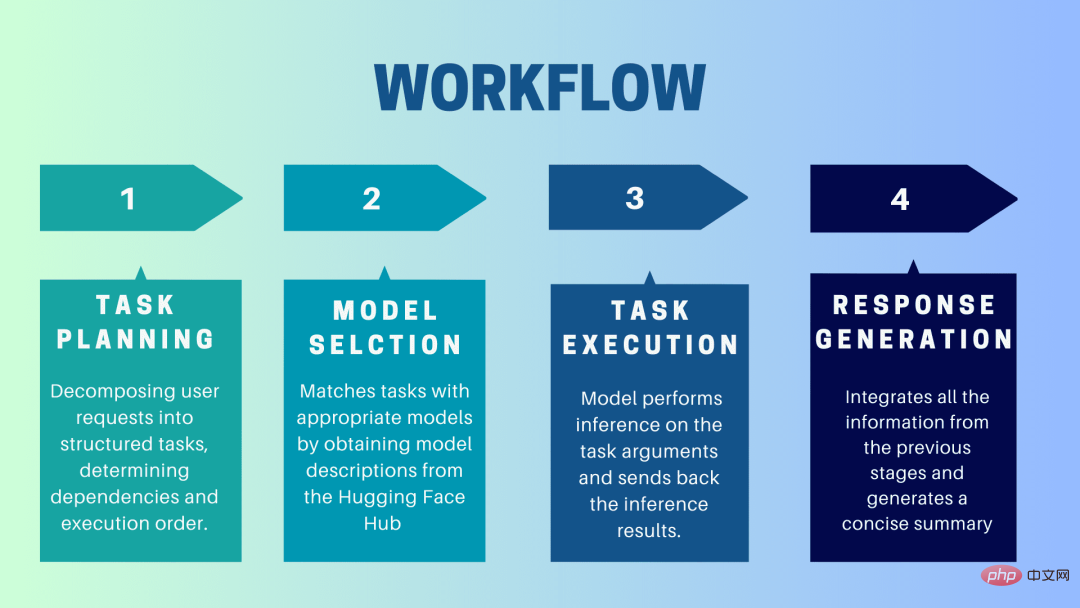
HuggingGPT ist ein Kollaborationssystem, das LLM als Schnittstelle verwendet, um Benutzeranfragen an Expertenmodelle zu senden. Der gesamte Prozess von der Benutzeraufforderung über das Modell bis zum Eingang der Antwort kann in die folgenden einzelnen Schritte unterteilt werden:
1. Aufgabenplanung
In dieser Phase verwendet HuggingGPT ChatGPT, um die Benutzeraufforderung zu verstehen und die Abfrage dann in kleine und überschaubare Teile zu zerlegen Operative Aufgaben. Außerdem identifiziert es die Abhängigkeiten dieser Aufgaben und definiert die Reihenfolge, in der sie ausgeführt werden. HuggingGPT verfügt über vier Slots zum Parsen von Aufgaben: Aufgabentyp, Aufgaben-ID, Aufgabenabhängigkeit und Aufgabenparameter. Chats zwischen HuggingGPT und dem Benutzer werden aufgezeichnet und auf dem Bildschirm mit dem Ressourcenverlauf angezeigt.
2. Modellauswahl
Basierend auf der Benutzerumgebung und den verfügbaren Modellen verwendet HuggingGPT einen kontextbezogenen Aufgabenmodellzuordnungsmechanismus, um das am besten geeignete Modell für eine bestimmte Aufgabe auszuwählen. Nach diesem Mechanismus wird die Modellauswahl als Multiple-Choice-Frage betrachtet, die zunächst Modelle basierend auf der Art der Aufgabe herausfiltert. Anschließend wurden die Modelle anhand der Anzahl der Downloads gerankt, da diese als zuverlässiges Maß für die Modellqualität gilt. Basierend auf diesem Ranking werden die Top-K-Modelle ausgewählt. K ist hier lediglich eine Konstante, die die Anzahl der Modelle widerspiegelt. Wenn sie beispielsweise auf 3 eingestellt ist, werden die 3 Modelle mit den meisten Downloads ausgewählt.
3. Aufgabenausführung
Hier wird die Aufgabe einem bestimmten Modell zugewiesen, das darauf Rückschlüsse zieht und die Ergebnisse zurückgibt. Um diesen Prozess effizienter zu gestalten, kann HuggingGPT verschiedene Modelle gleichzeitig ausführen, sofern diese nicht dieselben Ressourcen benötigen. Wenn Sie beispielsweise aufgefordert werden, Bilder von Katzen und Hunden zu erstellen, können verschiedene Modelle parallel ausgeführt werden, um diese Aufgabe auszuführen. Manchmal benötigt ein Modell jedoch möglicherweise dieselbe Ressource, weshalb HuggingGPT ein
4. Antwort generieren
Der letzte Schritt besteht darin, eine Antwort an den Benutzer zu generieren. Zunächst werden alle Informationen und Argumentationsergebnisse aus den vorherigen Phasen integriert. Die Informationen werden in einem strukturierten Format dargestellt. Wenn die Eingabeaufforderung beispielsweise darin besteht, die Anzahl der Löwen in einem Bild zu erkennen, werden entsprechende Begrenzungsrahmen mit Erkennungswahrscheinlichkeiten gezeichnet. LLM (ChatGPT) nimmt dann dieses Format und gibt es in einer benutzerfreundlichen Sprache wieder.
HuggingGPT einrichten
HuggingGPT basiert auf der hochmodernen GPT-3.5-Architektur von Hugging Face, einem tiefen neuronalen Netzwerkmodell, das Text in natürlicher Sprache generieren kann. Hier sind die Schritte zum Einrichten auf Ihrem lokalen Computer:
Systemanforderungen
Die Standardkonfiguration erfordert Ubuntu 16.04 LTS, mindestens 24 GB VRAM, mindestens 12 GB (Minimum), 16 GB (Standard) oder 80 GB (voll). ) RAM und mindestens 284 GB Festplattenspeicher. Darüber hinaus sind 42 GB Speicherplatz für damo-vilab/text-to-video-ms-1.7b, 126 GB für ControlNet, 66 GB für Stable-Diffusion-v1-5 und 50 GB für andere Ressourcen erforderlich. Für die „Lite“-Konfiguration ist nur Ubuntu 16.04 LTS erforderlich.
Schritte für den Einstieg
Ersetzen Sie zunächst den OpenAI-Schlüssel und das Hugging Face Token in der Datei server/configs/config.default.yaml durch Ihre Schlüssel. Alternativ können Sie sie in die Umgebungsvariablen OPENAI_API_KEY bzw. HUGGINGFACE_ACCESS_TOKEN einfügen.
Führen Sie den folgenden Befehl aus:
Für Server:
- Richten Sie die Python-Umgebung ein und installieren Sie die erforderlichen Abhängigkeiten.
<code># 设置环境cd serverconda create -n jarvis pythnotallow=3.8conda activate jarvisconda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidiapip install -r requirements.txt</code>
- Laden Sie das gewünschte Modell herunter.
<code># 下载模型。确保`git-lfs`已经安装。cd modelsbash download.sh # required when `inference_mode` is `local` or `hybrid`.</code>
- Führen Sie den Server aus
<code># 运行服务器cd ..python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid`python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003</code>
Jetzt können Sie auf die Dienste von Jarvis zugreifen, indem Sie HTTP-Anfragen an den Web-API-Endpunkt senden. Senden Sie eine Anfrage an:
- /hugginggpt Endpoint und verwenden Sie die POST-Methode, um auf den gesamten Dienst zuzugreifen.
- /tasks-Endpunkt, verwenden Sie die POST-Methode, um auf die Zwischenergebnisse von Stufe 1 zuzugreifen.
- /results-Endpunkt: Verwenden Sie die POST-Methode, um auf die Zwischenergebnisse der Stufen 1–3 zuzugreifen.
Diese Anfragen sollten im JSON-Format vorliegen und eine Liste der im Namen des Benutzers eingegebenen Informationen enthalten.
Für das Web:
- Nachdem Sie die Anwendung awesome_chat.py im Servermodus gestartet haben, installieren Sie Node js und npm auf Ihrem Computer.
- Navigieren Sie zum Webverzeichnis und installieren Sie die folgenden Abhängigkeiten:
<code>cd webnpm installnpm run dev</code>
- Setzen Sie http://{LAN_IP_of_the_server}:{port}/ auf die HUGGINGGPT_BASE_URL von web/src/config/index.ts, falls Sie sich auf einem anderen befinden Maschine Führen Sie den Webclient aus.
- Wenn Sie die Videogenerierungsfunktion nutzen möchten, kompilieren Sie ffmpeg bitte manuell mit H.264.
<code># 可选:安装 ffmpeg# 这个命令需要在没有错误的情况下执行。LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4</code>
- Doppelklicken Sie auf das Einstellungssymbol, um zurück zu ChatGPT zu wechseln.
Für CLI:
Das Einrichten von Jarvis mithilfe der CLI ist sehr einfach. Führen Sie einfach den unten genannten Befehl aus:
<code>cd serverpython awesome_chat.py --config configs/config.default.yaml --mode cli</code>
Für Gradio:
Die Gradio-Demo wird auch auf Hugging Face Space gehostet. Sie können experimentieren, nachdem Sie OPENAI_API_KEY und HUGGINGFACE_ACCESS_TOKEN eingegeben haben.
So führen Sie es lokal aus:
- Installieren Sie die erforderlichen Abhängigkeiten, klonen Sie das Projekt-Repository von Hugging Face Space und navigieren Sie zum Projektverzeichnis.
- Starten Sie den Modellserver mit dem folgenden Befehl und starten Sie dann die Gradio-Demo:
<code>python models_server.py --config configs/config.gradio.yamlpython run_gradio_demo.py --config configs/config.gradio.yaml</code>
- Greifen Sie in Ihrem Browser unter http://localhost:7860 auf die Demo zu und testen Sie sie durch Eingabe verschiedener Eingaben.
- Optional können Sie die Demo auch als Docker-Image ausführen, indem Sie den folgenden Befehl ausführen:
<code>docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.py</code>
HINWEIS: Wenn Sie Fragen haben, lesen Sie bitte das offizielle Github Repo (https://github.com/microsoft/JARVIS).
Abschließende Gedanken
HuggingGPT weist auch bestimmte Einschränkungen auf, die hier hervorgehoben werden müssen. Beispielsweise stellt die Effizienz des Systems einen großen Engpass dar, und HuggingGPT erfordert in allen zuvor genannten Phasen mehrere Interaktionen mit LLM. Diese Interaktionen können zu einer beeinträchtigten Benutzererfahrung und einer erhöhten Latenz führen. Ebenso ist die maximale Kontextlänge durch die Anzahl der zulässigen Token begrenzt. Ein weiteres Problem ist die Zuverlässigkeit des Systems, da LLM Eingabeaufforderungen möglicherweise falsch interpretiert und eine falsche Reihenfolge von Aufgaben erzeugt, was sich wiederum auf den gesamten Prozess auswirkt. Dennoch hat es großes Potenzial zur Lösung komplexer KI-Aufgaben und ist eine gute Weiterentwicklung für AGI. Freuen wir uns auf die Richtung, in die diese Forschung die Zukunft der KI lenken wird!
Das obige ist der detaillierte Inhalt vonHuggingGPT: Ein magisches Werkzeug für KI-Aufgaben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr