
Heim >Technologie-Peripheriegeräte >KI >Das vom Institut für Automatisierung entwickelte nicht-invasive multimodale Lernmodell realisiert die Dekodierung von Gehirnsignalen und die semantische Analyse
Das vom Institut für Automatisierung entwickelte nicht-invasive multimodale Lernmodell realisiert die Dekodierung von Gehirnsignalen und die semantische Analyse

- PHPznach vorne
- 2023-05-08 10:40:091382Durchsuche

- Papieradresse: https://ieeexplore.ieee.org/document /10089190
- Code-Adresse: https://github.com/ChangdeDu/BraVL#🎜 🎜#
- Datenadresse: https://figshare.com/articles/dataset/BraVL/17024591 #🎜 🎜#太长不看版
ist die erste, die Gehirn-, visuelles und sprachliches Wissen durch multimodales Lernen kombiniert mit null Proben aus Aufzeichnungen der menschlichen Gehirnaktivität. Dieser Artikel trägt auch drei dreimodale „Gehirn-Bild-Text“-Matching-Datensätze bei .
Die experimentellen Ergebnisse weisen auf einige interessante Schlussfolgerungen und kognitive Erkenntnisse hin: 1) Die Entschlüsselung neuer visueller Kategorien aus der menschlichen Gehirnaktivität ist mit hoher Genauigkeit möglich; 2) Die Entschlüsselung von Modellen mithilfe einer Kombination von visuellen und sprachlichen Merkmalen funktionieren besser als Modelle, die nur eines davon verwenden. 3) Die visuelle Wahrnehmung kann von sprachlichen Einflüssen begleitet sein, um die Semantik visueller Reize darzustellen. Diese Erkenntnisse geben nicht nur Aufschluss über das Verständnis des menschlichen visuellen Systems, sondern liefern auch neue Ideen für die zukünftige Gehirn-Computer-Schnittstellentechnologie. Der Code und die Datensätze für diese Studie sind Open Source.Forschungshintergrund
Die Entschlüsselung menschlicher visueller neuronaler Darstellungen ist eine wissenschaftlich wichtige Herausforderung, die visuelle Verarbeitungsmechanismen aufdecken und die Hirnforschung und die Entwicklung von fördern kann künstliche Intelligenz.aktuelle neuronale Dekodierungsmethoden lassen sich jedoch aus zwei Hauptgründen nur schwer auf neue Kategorien über Trainingsdaten hinaus verallgemeinern: Erstens nutzen bestehende Methoden die neuronale Multimodalität nicht vollständig aus semantisches Wissen hinter den Daten, und zweitens sind nur sehr wenige gepaarte Trainingsdaten (Reiz-Hirn-Reaktion) verfügbar.
Untersuchungen zeigen, dass die menschliche Wahrnehmung und Erkennung visueller Reize durch visuelle Merkmale und frühere Erfahrungen der Menschen beeinflusst wird. Wenn wir beispielsweise einen vertrauten Gegenstand sehen, ruft unser Gehirn auf natürliche Weise Wissen ab, das sich auf diesen Gegenstand bezieht. Wie in Abbildung 1 unten dargestellt, geht die kognitive neurowissenschaftliche Forschung zur dualen Kodierungstheorie [9] davon aus, dass bestimmte Konzepte sowohl visuell als auch sprachlich im Gehirn kodiert werden, wobei Sprache als wirksame vorherige Erfahrung dabei hilft, durch das Sehen erzeugte Darstellungen zu formen.Daher ist der Autor der Ansicht, dass zur besseren Dekodierung der aufgezeichneten Gehirnsignale nicht nur die tatsächlich dargestellten visuellen semantischen Merkmale verwendet werden sollten, sondern auch das visuelle Zielobjekt sollte enthalten sein. Die Dekodierung erfolgt durch eine Kombination relevanter, reichhaltigerer linguistischer semantischer Merkmale. Abbildung 1. Im menschlichen Gehirn Duale Kodierung von Wissen. Wenn wir Bilder von Elefanten sehen, rufen wir ganz automatisch Wissen über Elefanten in unserem Kopf ab (z. B. lange Rüssel, lange Zähne, große Ohren usw.). An diesem Punkt ist das Konzept des Elefanten sowohl in visueller als auch in verbaler Form im Gehirn kodiert, wobei die Sprache als gültige Vorerfahrung dient, die dabei hilft, die durch das Sehen erzeugte Darstellung zu formen.
Wie in Abbildung 2 unten gezeigt, haben Forscher normalerweise sehr viel Zeit, um Aktivitäten des menschlichen Gehirns in verschiedenen visuellen Kategorien zu erfassen, da es sehr teuer ist eingeschränkte Gehirnaktivität für visuelle Kategorien. Bild- und Textdaten sind jedoch reichlich vorhanden und können zusätzliche nützliche Informationen liefern. 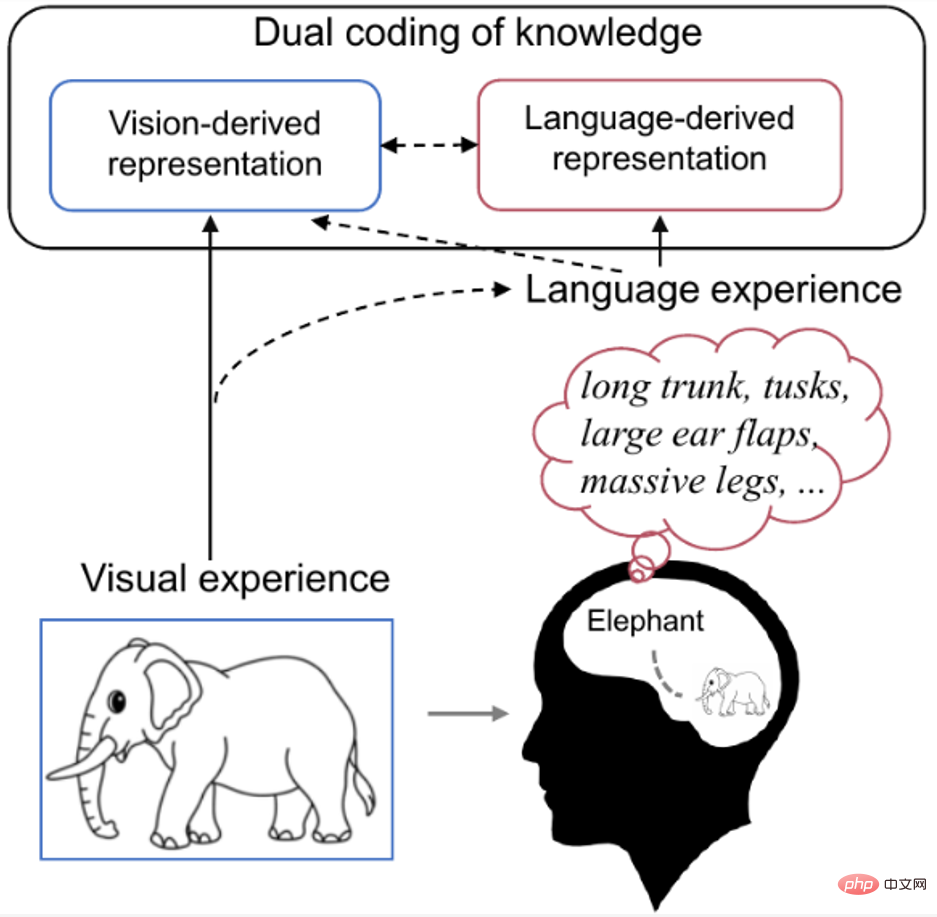
#🎜🎜 ## 🎜🎜#.
Abbildung 2. Bildreize, induzierte Gehirnaktivitäten und die entsprechenden Textdaten. Wir können nur für einige Kategorien Daten zur Gehirnaktivität sammeln, aber Bild- und/oder Textdaten können für fast alle Kategorien problemlos erfasst werden. Daher gehen wir für bekannte Kategorien davon aus, dass Gehirnaktivität, visuelle Bilder und entsprechende Textbeschreibungen alle für das Training verfügbar sind, während für neue Kategorien nur visuelle Bilder und Textbeschreibungen für das Training verfügbar sind. Bei den Testdaten handelt es sich um Gehirnaktivitätsdaten aus neuen Kategorien.
Multimodales Lernen „Gehirn-Bild-Text“
Wie in Abbildung 3A unten dargestellt, besteht der Schlüssel zu dieser Methode darin, die von jeder Modalität gelernte Verteilung in einem gemeinsamen latenten Raum auszurichten, der grundlegende multimodale Informationen enthält im Zusammenhang mit neuen Kategorien.
Konkret schlägt der Autor ein multimodales autoenkodierendes Variations-Bayesian-Lern-Framework vor, das das Mixture-of-Products-of-Experts (MoPoE) verwendet, eine latente Kodierung wird abgeleitet, um die gemeinsame Generierung aller zu ermöglichen drei Modalitäten. Um relevantere gemeinsame Darstellungen zu lernen und die Dateneffizienz zu verbessern, wenn die Daten zur Gehirnaktivität begrenzt sind, führen die Autoren außerdem Begriffe zur Regulierung intramodaler und intermodaler gegenseitiger Informationen ein. Darüber hinaus können BraVL-Modelle in verschiedenen halbüberwachten Lernszenarien trainiert werden, um zusätzliche visuelle und textliche Merkmale großer Bildkategorien zu integrieren.
In Abbildung 3B trainieren die Autoren einen SVM-Klassifikator aus latenten Darstellungen visueller und Textmerkmale neuer Kategorien. Es ist zu beachten, dass die Encoder E_v und E_t in diesem Schritt eingefroren werden und nur der SVM-Klassifikator (Graumodul) optimiert wird.
In der Anwendung, wie in Abbildung 3C dargestellt, ist die Eingabe dieser Methode nur eine neue Kategorie von Gehirnsignalen und erfordert keine anderen Daten, sodass sie problemlos auf die meisten neuronalen Dekodierungsszenarien angewendet werden kann. Der SVM-Klassifikator kann von (B) auf (C) verallgemeinern, da die zugrunde liegenden Darstellungen dieser drei Modalitäten bereits in A ausgerichtet sind.

Abbildung 3 Der in diesem Artikel vorgeschlagene dreimodale gemeinsame Lernrahmen „Gehirn-Bild-Text“, der als BraVL bezeichnet wird.
Darüber hinaus ändern sich die Gehirnsignale von Versuch zu Versuch, selbst bei demselben visuellen Reiz. Um die Stabilität der neuronalen Dekodierung zu verbessern, verwendeten die Autoren eine Stabilitätsauswahlmethode zur Verarbeitung von fMRT-Daten. Die Stabilitätswerte aller Voxel sind in Abbildung 4 unten dargestellt. Der Autor hat die besten 15 % der Voxel mit der besten Stabilität ausgewählt, um am neuronalen Dekodierungsprozess teilzunehmen. Dieser Vorgang kann die Dimensionalität von fMRT-Daten effektiv reduzieren und durch verrauschte Voxel verursachte Störungen unterdrücken, ohne die Unterscheidungsfähigkeit von Gehirnmerkmalen ernsthaft zu beeinträchtigen.

Abbildung 4. Voxelaktivitätsstabilitäts-Score-Karte des visuellen Kortex des Gehirns.
Vorhandene Datensätze zur neuronalen Kodierung und Dekodierung verfügen oft nur über Bildreize und Gehirnreaktionen. Um die sprachliche Beschreibung zu erhalten, die dem visuellen Konzept entspricht, hat der Autor eine halbautomatische Methode zur Extraktion von Wikipedia-Artikeln übernommen. Konkret erstellen die Autoren zunächst einen automatischen Abgleich von ImageNet-Klassen mit ihren entsprechenden Wikipedia-Seiten. Der Abgleich basiert auf der Ähnlichkeit zwischen den Synset-Wörtern der ImageNet-Klasse und dem Wikipedia-Titel sowie ihren übergeordneten Kategorien. Wie in Abbildung 5 unten dargestellt, kann diese Art des Abgleichs leider gelegentlich zu falsch positiven Ergebnissen führen, da ähnlich benannte Klassen möglicherweise sehr unterschiedliche Konzepte darstellen. Bei der Erstellung des trimodalen Datensatzes haben die Autoren nicht übereinstimmende Artikel manuell gelöscht, um eine qualitativ hochwertige Übereinstimmung zwischen visuellen und sprachlichen Merkmalen sicherzustellen.
Abbildung 5: Halbautomatische Erfassung visueller Konzeptbeschreibungen Die experimentellen Ergebnisse sind in der folgenden Tabelle aufgeführt. Wie man sehen kann, schneiden
Modelle, die eine Kombination aus visuellen und textuellen Merkmalen (V&T) verwenden, viel besser ab als Modelle, die nur eines dieser Merkmale verwenden. Bemerkenswert ist, dass BraVL, das auf V&T-Funktionen basiert, die durchschnittliche Top-5-Genauigkeit bei beiden Datensätzen deutlich verbessert. Diese Ergebnisse legen nahe, dass, obwohl die Reize, die den Probanden präsentiert werden, nur visuelle Informationen enthalten, es denkbar ist, dass Probanden unbewusst entsprechende sprachliche Darstellungen aufrufen und dadurch die visuelle Verarbeitung beeinflussen.
Für jede visuelle Konzeptkategorie zeigen die Autoren auch den Genauigkeitsgewinn bei der neuronalen Dekodierung nach dem Hinzufügen von Textfunktionen, wie in Abbildung 6 unten dargestellt. Es ist ersichtlich, dass sich das Hinzufügen von Textfunktionen für die meisten Testklassen positiv auswirkt und die durchschnittliche Top-1-Dekodierungsgenauigkeit um etwa 6 % steigt. Abbildung 6. Genauigkeitsgewinn bei der neuronalen Dekodierung nach dem Hinzufügen von Textmerkmalen Codierungsbeitrag (Vorhersage der entsprechenden Gehirnvoxelaktivität basierend auf visuellen oder Textmerkmalen), die Ergebnisse sind in Abbildung 7 dargestellt. Es ist ersichtlich, dass für die meisten visuellen Kortexe auf hoher Ebene (HVC, wie FFA, LOC und IT) die Fusion von Textmerkmalen auf der Grundlage visueller Merkmale die Vorhersagegenauigkeit der Gehirnaktivität verbessern kann, während dies für die meisten visuellen Kortexe auf niedriger Ebene der Fall ist (LVC, wie V1, V2 und V3) ist die Zusammenführung von Textfunktionen weder vorteilhaft noch sogar schädlich.Aus Sicht der kognitiven Neurowissenschaften sind unsere Ergebnisse vernünftig, da allgemein angenommen wird, dass HVC für die Verarbeitung semantischer Informationen höherer Ebene wie Kategorieinformationen und Bewegungsinformationen von Objekten verantwortlich ist, während LVC für die Verarbeitung der Richtung verantwortlich ist. Kontur usw. zugrunde liegende Informationen. Darüber hinaus ergab eine aktuelle neurowissenschaftliche Studie, dass visuelle und sprachliche semantische Darstellungen an der Grenze des menschlichen visuellen Kortex ausgerichtet sind (d. h. die „Hypothese der semantischen Ausrichtung“)[10], und die experimentellen Ergebnisse des Autors stützen diese Hypothese ebenfalls
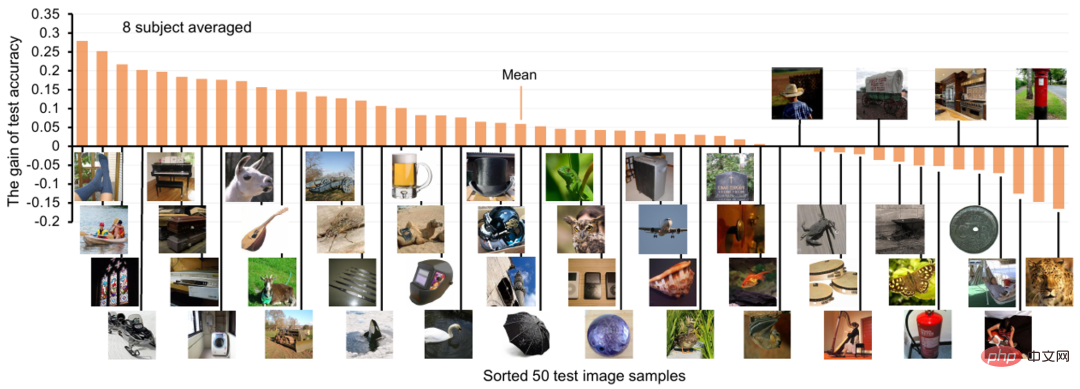 Abbildung 7. Projektion des Beitrags von Textmerkmalen zum visuellen Kortex
Abbildung 7. Projektion des Beitrags von Textmerkmalen zum visuellen Kortex
Weitere experimentelle Ergebnisse finden Sie im Originaltext.
Insgesamt zieht dieser Artikel einige interessante Schlussfolgerungen und kognitive Erkenntnisse: 1) Die Dekodierung neuer visueller Kategorien aus der menschlichen Gehirnaktivität ist mit hoher Genauigkeit möglich. 2) Die Verwendung einer Kombination aus visuellen und sprachlichen Merkmalen verfügt über eine höhere neuronale Dekodierung Leistung; 5) Zusätzliche Daten sowohl in der Einzelmodalität als auch in der Dualmodalität können die Decodierungsgenauigkeit erheblich verbessern.Diskussion und AusblickDu Changde, Erstautor des Artikels und Sonderforschungsassistent am Institut für Automatisierung der Chinesischen Akademie der Wissenschaften, sagte: „Diese Arbeit bestätigt, dass Merkmale aus Gehirnaktivität, visuellen Bildern und Textbeschreibungen extrahiert werden.“ sind für die Dekodierung neuronaler Signale wirksam. Die extrahierten visuellen Merkmale spiegeln jedoch möglicherweise nicht alle Phasen der menschlichen visuellen Verarbeitung wider, und ein besserer Funktionsumfang wäre für diese Aufgaben hilfreich -3) kann verwendet werden, um Textmerkmale mit besseren Zero-Shot-Generalisierungsfähigkeiten zu extrahieren. Darüber hinaus enthalten Wikipedia-Artikel umfangreiche visuelle Informationen, diese Informationen werden jedoch durch visuelle Satzextraktion oder -verwendung leicht verdeckt ChatGPT und GPT-4 können dieses Problem lösen, obwohl in dieser Studie im Vergleich zu verwandten Studien relativ große Mengen trimodaler Daten verwendet wurden. Wir überlassen diese Aspekte der zukünftigen Forschung.“
Der Forscher He Huiguang vom Institut für Automatisierung der Chinesischen Akademie der Wissenschaften, korrespondierender Autor des Artikels, wies darauf hin: „Die in diesem Artikel vorgeschlagene Methode hat drei mögliche Anwendungen: 1) Als neurosemantisches Dekodierungswerkzeug wird diese Methode verwendet.“ in neuen neuroprothetischen Geräten, die semantische Informationen aus dem menschlichen Gehirn lesen. Obwohl diese Anwendung noch nicht ausgereift ist, bietet die Methode in diesem Artikel eine technische Grundlage dafür. Die Methode in diesem Artikel kann auch als neuronales Kodierungswerkzeug zur Untersuchung des Sehens und der Art und Weise, wie Sprachmerkmale in der menschlichen Großhirnrinde ausgedrückt werden, verwendet werden, um aufzudecken, welche Gehirnregionen multimodale Eigenschaften haben (d. h. empfindlich auf visuelle und sprachliche Merkmale reagieren). 3) Die Die neuronale Dekodierbarkeit der internen Darstellung des KI-Modells kann als gehirnähnliches Modell angesehen werden. Daher kann die Methode in diesem Artikel auch als gehirnähnliches Eigenschaftsbewertungstool zum Testen verwendet werden Die (visuelle oder sprachliche) Darstellung ist näher an der menschlichen Gehirnaktivität und motiviert Forscher daher dazu, gehirnähnlichere Rechenmodelle zu entwerfen Auch eine effektive Möglichkeit, die Prinzipien hinter den komplexen Funktionen des menschlichen Gehirns zu erforschen und die Entwicklung gehirnähnlicher Intelligenz zu fördern. Das Forschungsteam für neuronale Informatik und Gehirn-Computer-Interaktion des Instituts für Automatisierung arbeitet seit vielen Jahren auf diesem Gebiet und hat eine Reihe von Forschungsarbeiten erstellt, die in TPAMI 2023, TMI2023, TNNLS 2022/2019, TMM 2021 veröffentlicht wurden. Infos. Fusion 2021, AAAI 2020 usw. Über die Vorarbeit wurde in den Schlagzeilen der MIT Technology Review berichtet und sie wurde mit dem ICME 2019 Best Paper Runner-up Award ausgezeichnet.
Diese Forschung wurde vom Großprojekt Science and Technology Innovation 2030 – „New Generation Artificial Intelligence“, dem National Foundation Project, dem Institute of Automation 2035 Project und dem China Artificial Intelligence Society-Huawei MindSpore Academic Award Fund unterstützt Intelligent Base-Projekte.
Über den Autor
Erster Autor: Du Changde, Sonderforschungsassistent am Institut für Automatisierung der Chinesischen Akademie der Wissenschaften, beschäftigt sich mit der Forschung zu Gehirnkognition und künstlicher Intelligenz und hat Artikel zur visuellen neuronalen Informationskodierung und veröffentlicht Dekodierung, multimodales neuronales Rechnen usw. Mehr als 40 Artikel, einschließlich TPAMI/TNNNLS/AAAI/KDD/ACMMM usw. Er hat den IEEE ICME Best Paper Runner-up Award 2019 und die Top 100 Chinese AI Rising Stars 2021 gewonnen. Er hat nacheinander eine Reihe wissenschaftlicher Forschungsaufgaben für das Ministerium für Wissenschaft und Technologie, die Nationale Stiftung für Wissenschaft und Technologie und die Chinesische Akademie der Wissenschaften übernommen, und über seine Forschungsergebnisse wurde in den Schlagzeilen der MIT Technology Review berichtet.
 Persönliche Homepage: https://changdedu.github.io/
Persönliche Homepage: https://changdedu.github.io/
Korrespondierender Autor: He Huiguang, Forscher am Institut für Automatisierung der Chinesischen Akademie der Wissenschaften, Doktorvater, Postprofessor am der Universität der Chinesischen Akademie der Wissenschaften, angesehener Professor an der Shanghai University of Science and Technology, herausragendes Mitglied der Jugendförderungsvereinigung der Chinesischen Akademie der Wissenschaften und Gewinner der Gedenkmedaille zum 70. Jahrestag der Gründung der Volksrepublik China . Er hat nacheinander 7 Projekte des Nationalen Naturschutzfonds (einschließlich wichtiger Fonds- und internationaler Kooperationsprojekte), 2.863 Projekte und nationale Schlüsselforschungsplanprojekte durchgeführt. Er hat zwei zweitklassige National Science and Technology Progress Awards (Rang zwei und drei), zwei Beijing Science and Technology Progress Awards, den erstklassigen Science and Technology Progress Award des Bildungsministeriums und den ersten Outstanding Doctoral Thesis Award gewonnen der Chinesischen Akademie der Wissenschaften, Beijing Science and Technology Rising Star, und „Lu Jiaxi Young Talent Award“ der Chinesischen Akademie der Wissenschaften, „Minjiang Scholar“-Lehrstuhlprofessor der Provinz Fujian. Zu seinen Forschungsgebieten gehören künstliche Intelligenz, Gehirn-Computer-Schnittstelle, medizinische Bildanalyse usw. In den letzten fünf Jahren hat er mehr als 80 Artikel in Fachzeitschriften und Konferenzen wie IEEE TPAMI/TNNLS und ICML veröffentlicht. Er ist Redaktionsmitglied von IEEEE TCDS, Journal of Automation und anderen Fachzeitschriften, ein angesehenes Mitglied von CCF und ein angesehenes Mitglied von CSIG.

Das obige ist der detaillierte Inhalt vonDas vom Institut für Automatisierung entwickelte nicht-invasive multimodale Lernmodell realisiert die Dekodierung von Gehirnsignalen und die semantische Analyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr