
Heim >Technologie-Peripheriegeräte >KI >Meta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen
Meta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-07 15:49:181264Durchsuche
Nach dem Open-Source-SAM-Modell, das „alles teilt“, geht Meta immer weiter auf dem Weg zum „visuellen Basismodell“.
Dieses Mal haben sie eine Reihe von Modellen namens DINOv2 als Open Source bereitgestellt. Diese Modelle können leistungsstarke visuelle Darstellungen erzeugen, die ohne Feinabstimmung für nachgelagerte Aufgaben wie Klassifizierung, Segmentierung, Bildabruf und Tiefenschätzung verwendet werden können.
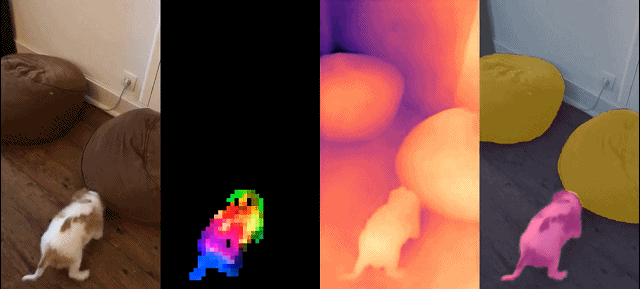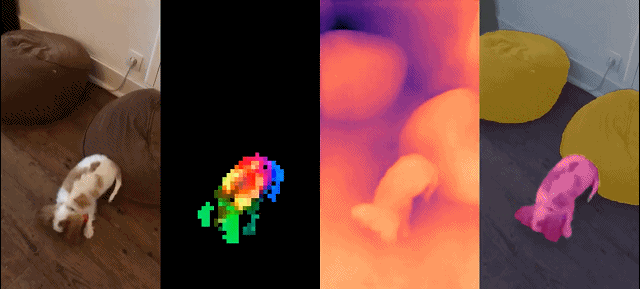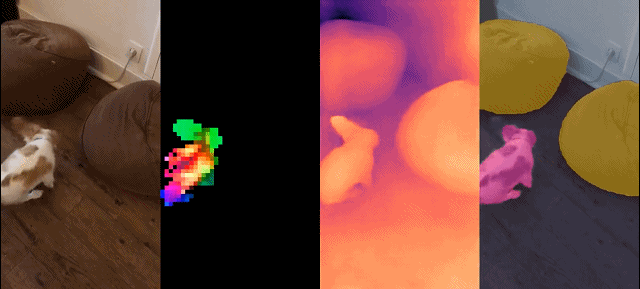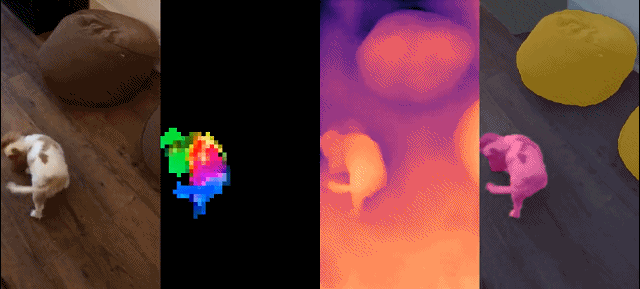
Dieser Satz von Modellen hat die folgenden Eigenschaften: #
- Nutzen Sie selbstüberwachtes Training, ohne dass eine große Menge an gekennzeichneten Daten erforderlich ist;
- # 🎜🎜##🎜 🎜# kann ohne Feinabstimmung als Rückgrat für fast alle Lebenslaufaufgaben verwendet werden, z. B. Bildklassifizierung, Segmentierung, Bildabruf und Tiefenschätzung; aus Bildern, ohne auf Textbeschreibungen angewiesen zu sein, kann das Modell lokale Informationen besser verstehen; # #🎜 🎜# Eine vorab trainierte Version von DINOv2 ist bereits verfügbar und ist bei einer Reihe von Aufgaben mit CLIP und OpenCLIP vergleichbar.
- Papierlink: https://arxiv.org /pdf/2304.07193.pdf
- Projektlink: https://dinov2.metademolab.com/

- Das Erlernen nicht aufgabenspezifischer vorab trainierter Darstellungen ist zu einem Standard in der Verarbeitung natürlicher Sprache geworden. Sie können diese Funktionen „wie sie sind“ verwenden (keine Feinabstimmung erforderlich) und sie erzielen bei nachgelagerten Aufgaben eine deutlich bessere Leistung als aufgabenspezifische Modelle. Dieser Erfolg ist auf das Vortraining großer Rohtextmengen unter Verwendung von Hilfszielen wie Sprachmodellierung oder Wortvektoren zurückzuführen, die keiner Aufsicht bedürfen. Da dieser Paradigmenwechsel im Bereich NLP stattfindet, wird erwartet, dass ähnliche „grundlegende“ Modelle in der Computer Vision entstehen werden. Diese Modelle sollten visuelle Funktionen generieren, die bei jeder Aufgabe „out of the box“ funktionieren, sei es auf Bildebene (z. B. Bildklassifizierung) oder Pixelebene (z. B. Segmentierung).
- Diese Grundmodelle konzentrieren sich stark auf das textgesteuerte Vortraining, das heißt, sie verwenden eine Form der Textüberwachung, um das Trainieren von Funktionen zu leiten. Diese Form des textgesteuerten Vortrainings schränkt die Informationen über das Bild ein, die gespeichert werden können, da die Bildunterschrift die umfangreichen Informationen im Bild nur annähernd wiedergibt und feinere, komplexe Informationen auf Pixelebene bei dieser Überwachung möglicherweise nicht entdeckt werden. Darüber hinaus erfordern diese Bildencoder bereits ausgerichtete Text-Bild-Korpora und bieten nicht die Flexibilität ihrer Text-Gegenstücke, d. h. sie können nicht allein aus Rohdaten lernen.
Eine Alternative zum textgesteuerten Vortraining ist selbstüberwachtes Lernen, bei dem Funktionen ausschließlich aus Bildern gelernt werden. Diese Methoden sind konzeptionell näher an Front-End-Aufgaben wie der Sprachmodellierung und können Informationen auf Bild- und Pixelebene erfassen. Trotz ihres Potenzials zum Erlernen allgemeiner Funktionen wurden die meisten Verbesserungen beim selbstüberwachten Lernen jedoch im Kontext des Vortrainings mit dem kleinen, verfeinerten Datensatz ImageNet1k erzielt. Einige Forscher haben einige Anstrengungen unternommen, diese Methoden über ImageNet-1k hinaus zu erweitern, sie konzentrierten sich jedoch auf ungefilterte Datensätze, was häufig zu einer erheblichen Verschlechterung der Leistungsqualität führte. Dies liegt an der mangelnden Kontrolle über die Datenqualität und -vielfalt, die für die Erzielung guter Ergebnisse von entscheidender Bedeutung sind.
In dieser Arbeit untersuchen Forscher, ob selbstüberwachtes Lernen möglich ist, um allgemeine visuelle Merkmale zu erlernen, wenn es vorab auf einer großen Menge verfeinerter Daten trainiert wird. Sie überdenken bestehende diskriminierende selbstüberwachte Methoden, die Funktionen auf Bild- und Patchebene lernen, wie z. B. iBOT, und überdenken einige ihrer Designentscheidungen anhand größerer Datensätze. Die meisten unserer technischen Beiträge sind darauf zugeschnitten, diskriminierendes selbstüberwachtes Lernen bei der Skalierung von Modell- und Datengrößen zu stabilisieren und zu beschleunigen. Diese Verbesserungen machten ihre Methode ungefähr doppelt so schnell und benötigten 1/3 weniger Speicher als ähnliche diskriminierende selbstüberwachte Methoden, sodass sie von längerem Training und größeren Batchgrößen profitieren konnten.
In Bezug auf die Daten vor dem Training haben sie eine automatisierte Pipeline erstellt, um den Datensatz aus einer großen Sammlung ungefilterter Bilder zu filtern und neu auszugleichen. Dies ist von Pipelines inspiriert, die in NLP verwendet werden, wo Datenähnlichkeit anstelle externer Metadaten verwendet wird und keine manuelle Annotation erforderlich ist. Eine große Schwierigkeit bei der Verarbeitung von Bildern besteht darin, Konzepte neu auszubalancieren und eine Überanpassung in einigen vorherrschenden Modi zu vermeiden. In dieser Arbeit kann die naive Clustering-Methode dieses Problem gut lösen, und die Forscher sammelten einen kleinen, aber vielfältigen Korpus bestehend aus 142 Millionen Bildern, um ihre Methode zu validieren.
Schließlich stellen die Forscher verschiedene vorab trainierte Vision-Modelle namens DINOv2 bereit, die auf ihren Daten mithilfe verschiedener Visual Transformer (ViT)-Architekturen trainiert werden. Sie haben alle Modelle und Codes veröffentlicht, um DINOv2 auf beliebigen Daten neu zu trainieren. Bei der Erweiterung validierten sie die Qualität von DINOv2 anhand verschiedener Computer-Vision-Benchmarks auf Bild- und Pixelebene, wie in Abbildung 2 dargestellt. Wir kommen zu dem Schluss, dass selbstüberwachtes Vortraining allein ein guter Kandidat für das Erlernen übertragbarer eingefrorener Funktionen ist, vergleichbar mit den besten öffentlich verfügbaren, schwach überwachten Modellen.
Datenverarbeitung
Die Forscher stellten ihren verfeinerten LVD-142M-Datensatz zusammen, indem sie Bilder aus einer großen Menge ungefilterter Daten abgerufen haben, die den Bildern in mehreren verfeinerten Datensätzen nahe kamen. In ihrem Artikel beschreiben sie die Hauptkomponenten der Datenpipeline, einschließlich kuratierter/ungefilterter Datenquellen, Schritte zur Bilddeduplizierung und Abrufsysteme. Die gesamte Pipeline benötigt keine Metadaten oder Text und verarbeitet Bilder direkt, wie in Abbildung 3 dargestellt. Für weitere Einzelheiten zur Modellmethodik wird der Leser auf Anhang A verwiesen.
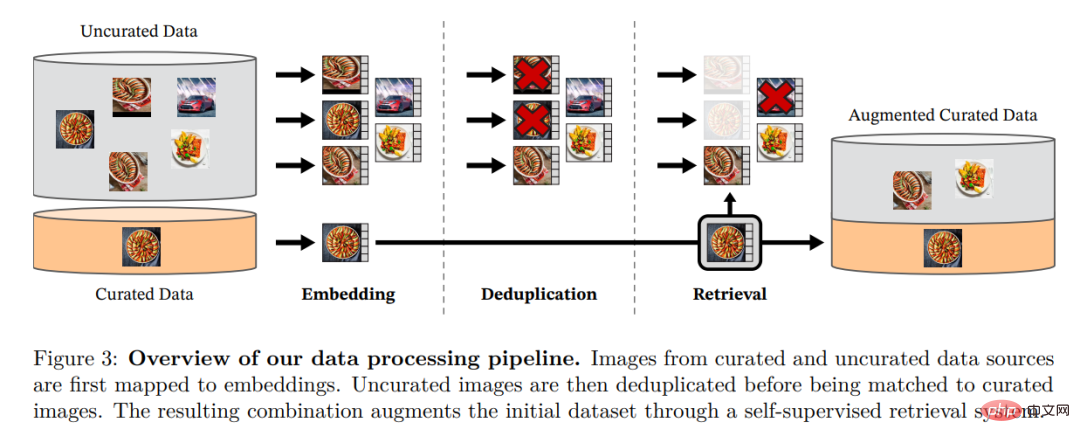
Abbildung 3: Übersicht über die Datenverarbeitungspipeline. Bilder aus verfeinerten und nicht verfeinerten Datenquellen werden zunächst Einbettungen zugeordnet. Das nicht verfeinerte Bild wird dann dedupliziert, bevor es mit dem Standardbild abgeglichen wird. Die resultierende Kombination bereichert den ursprünglichen Datensatz durch ein selbstüberwachtes Abrufsystem weiter.
Diskriminatives selbstüberwachtes Vortraining
Die Forscher lernten ihre Merkmale durch einen diskriminierenden selbstüberwachten Ansatz, der als eine Kombination aus DINO- und iBOT-Verlusten betrachtet werden kann, die sich auf SwAV konzentrieren. Sie fügten außerdem einen Regularisierer zur Verbreitung von Funktionen und eine kurze hochauflösende Trainingsphase hinzu.
Effiziente Implementierung
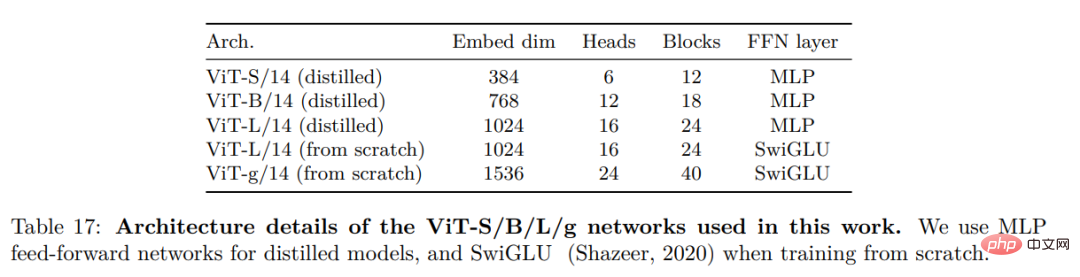
Sie erwogen mehrere Verbesserungen, um das Modell in größerem Maßstab zu trainieren. Das Modell wird auf einer A100-GPU mit PyTorch 2.0 trainiert, und der Code kann auch mit einem vorab trainierten Modell zur Merkmalsextraktion verwendet werden. Einzelheiten zum Modell finden Sie in Anhang Tabelle 17. Auf derselben Hardware nutzt der DINOv2-Code nur 1/3 des Speichers und läuft 2-mal schneller als die iBOT-Implementierung.
Experimentelle Ergebnisse
In diesem Abschnitt stellen die Forscher die empirische Bewertung des neuen Modells für eine Reihe von Bildverständnisaufgaben vor. Sie bewerteten globale und lokale Bilddarstellungen, einschließlich Erkennung auf Kategorie- und Instanzebene, semantische Segmentierung, monokulare Tiefenvorhersage und Aktionserkennung.
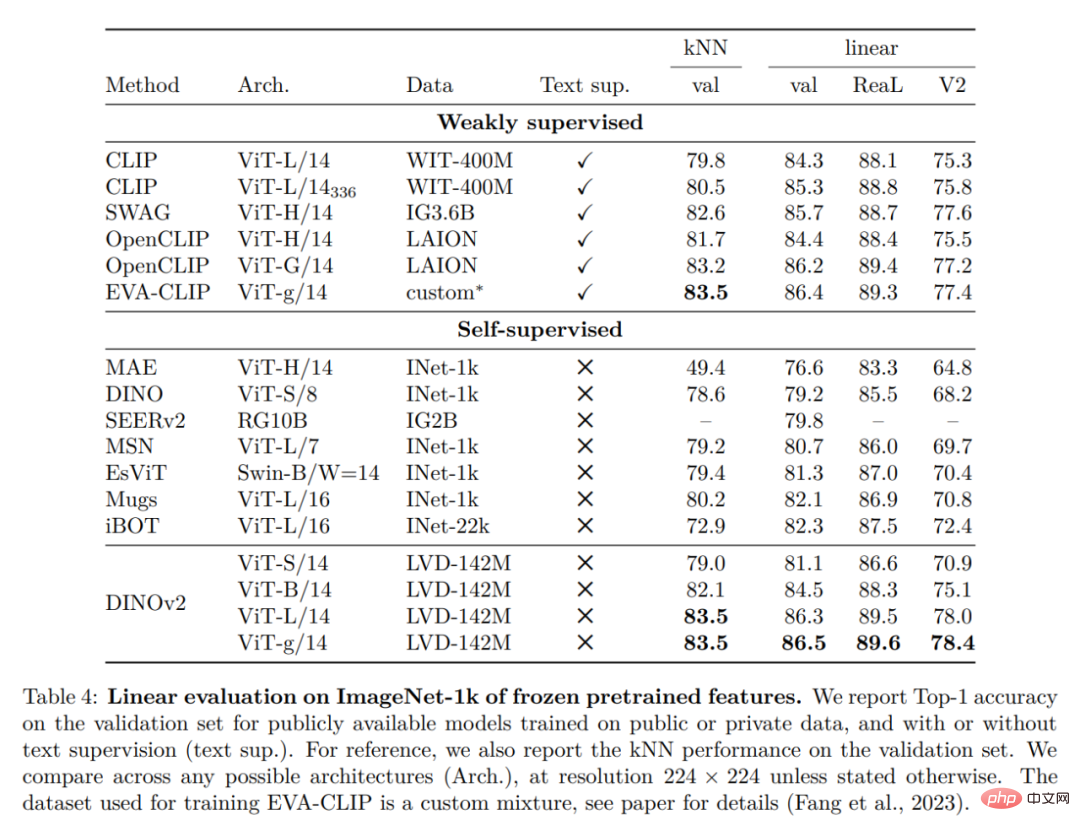
ImageNet-Klassifizierung
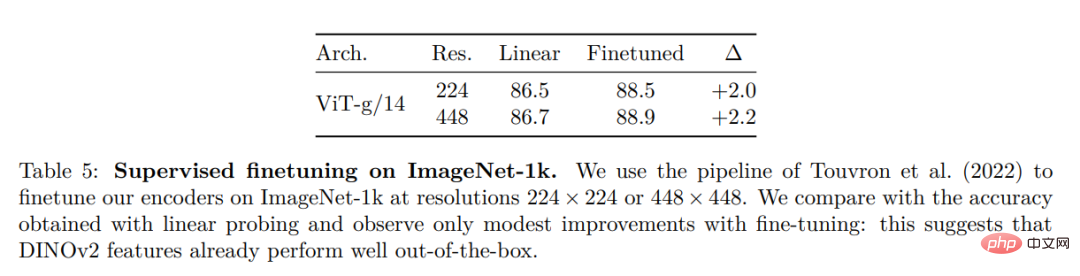
Instanzerkennung
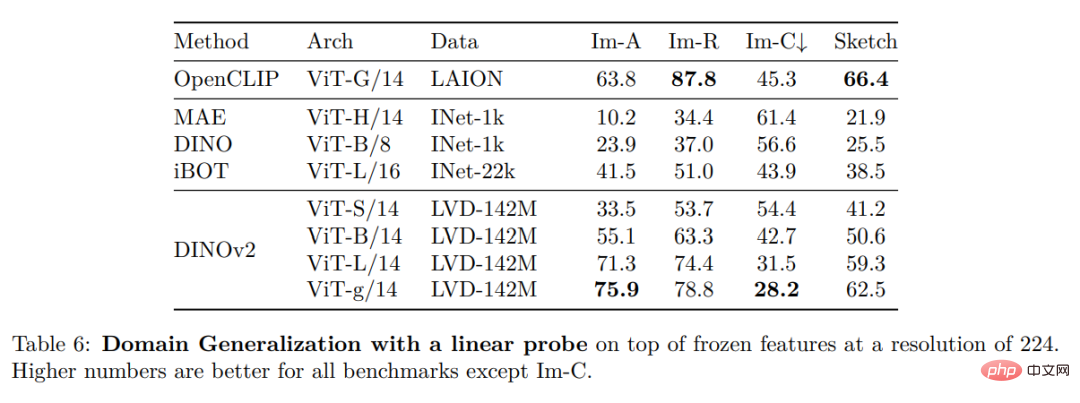
Dichte Erkennung Aufgabe: qualitative Ergebnisse:
Das obige ist der detaillierte Inhalt vonMeta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr