
Heim >Technologie-Peripheriegeräte >KI >A100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms
A100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms

- PHPznach vorne
- 2023-05-07 10:43:081760Durchsuche
Die Rekonstruktion von 3D-Innenszenen aus Posenbildern gliedert sich normalerweise in zwei Phasen: Schätzung der Bildtiefe, gefolgt von Tiefenzusammenführung und Oberflächenrekonstruktion. Kürzlich haben mehrere Studien eine Reihe von Methoden vorgeschlagen, die die Rekonstruktion direkt im endgültigen volumetrischen 3D-Merkmalsraum durchführen. Obwohl diese Methoden beeindruckende Rekonstruktionsergebnisse erzielt haben, basieren sie auf teuren 3D-Faltungsschichten, was ihre Anwendung in ressourcenbeschränkten Umgebungen einschränkt.
Jetzt versuchen Forscher von Institutionen wie Niantic und UCL, traditionelle Methoden wiederzuverwenden und sich auf eine qualitativ hochwertige Multi-View-Tiefenvorhersage zu konzentrieren, um schließlich mithilfe einfacher und handelsüblicher Tiefenfusionsmethoden eine hochpräzise 3D-Rekonstruktion zu erreichen .

- Papieradresse: https://nianticlabs.github.io/simplerecon/resources/SimpleRecon.pdf
- GitHub-Adresse: https://github.com /nianticlabs/simplerecon Sorgfältig entworfenes 2D-CNN. Die vorgeschlagene Methode SimpleRecon erzielt deutlich führende Ergebnisse bei der Tiefenschätzung und ermöglicht eine Online-Echtzeit-Rekonstruktion mit geringem Speicherbedarf.
- Wie in der Abbildung unten gezeigt, ist die Rekonstruktionsgeschwindigkeit von SimpleRecon sehr hoch und dauert nur etwa 70 ms pro Frame. Die Vergleichsergebnisse zwischen
SimpleRecon und anderen Methoden lauten wie folgt:
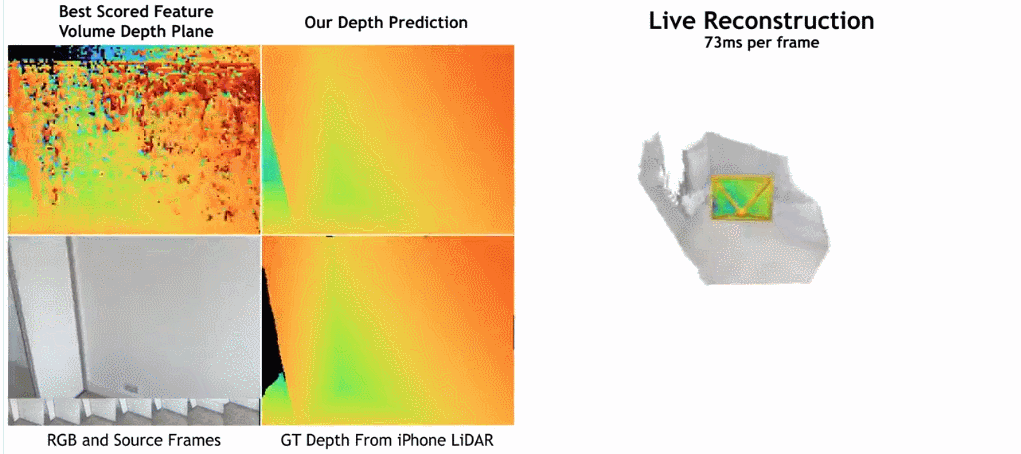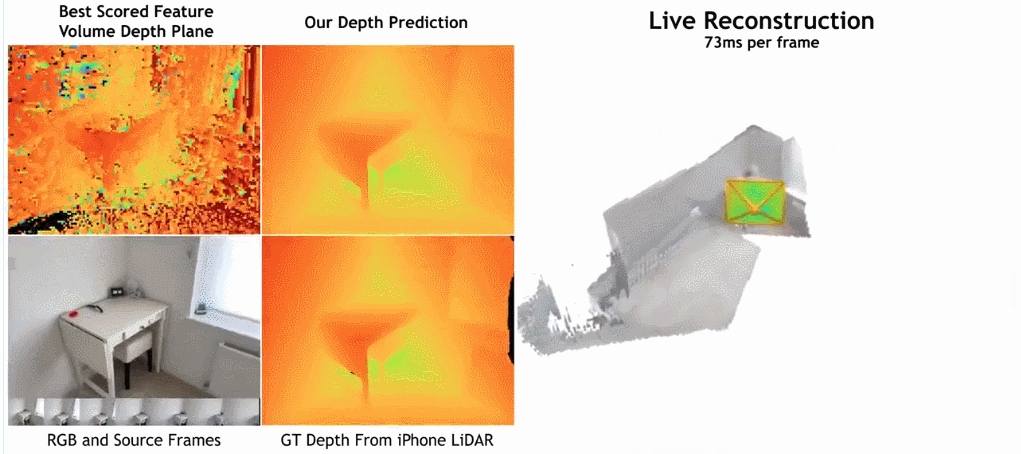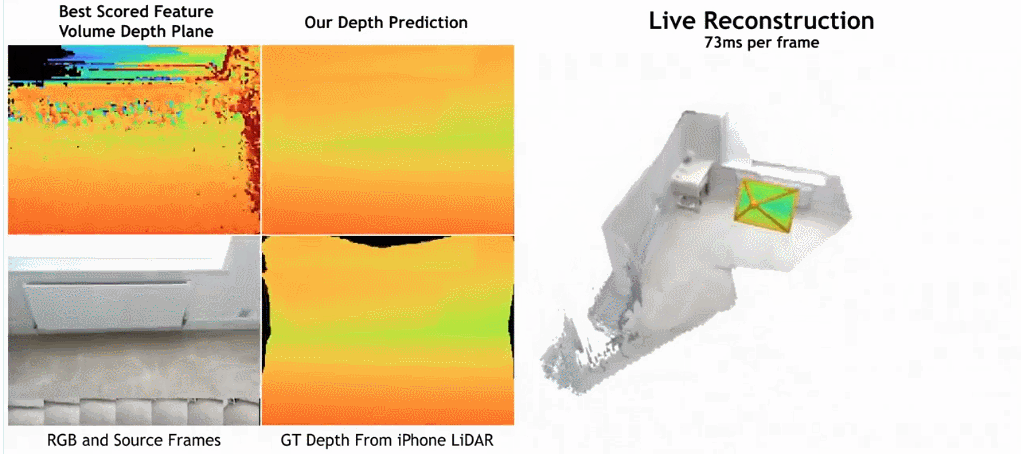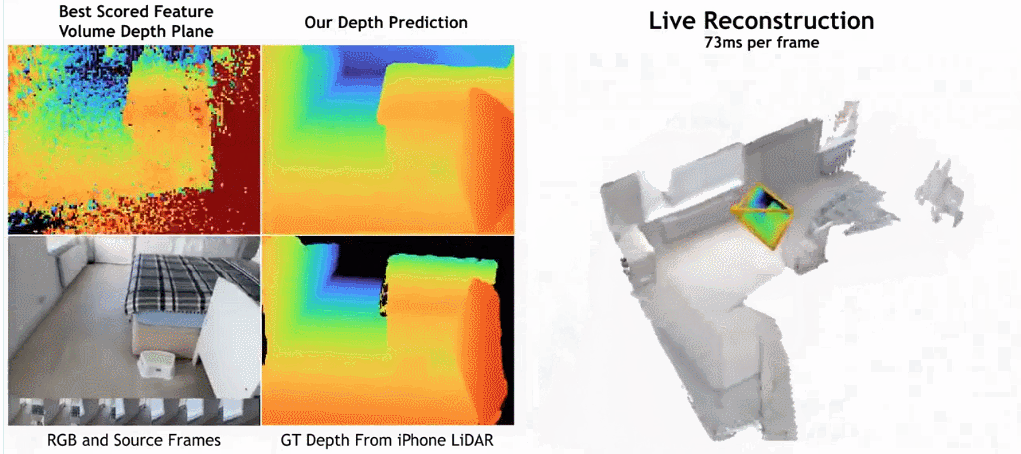 Methode
Methode
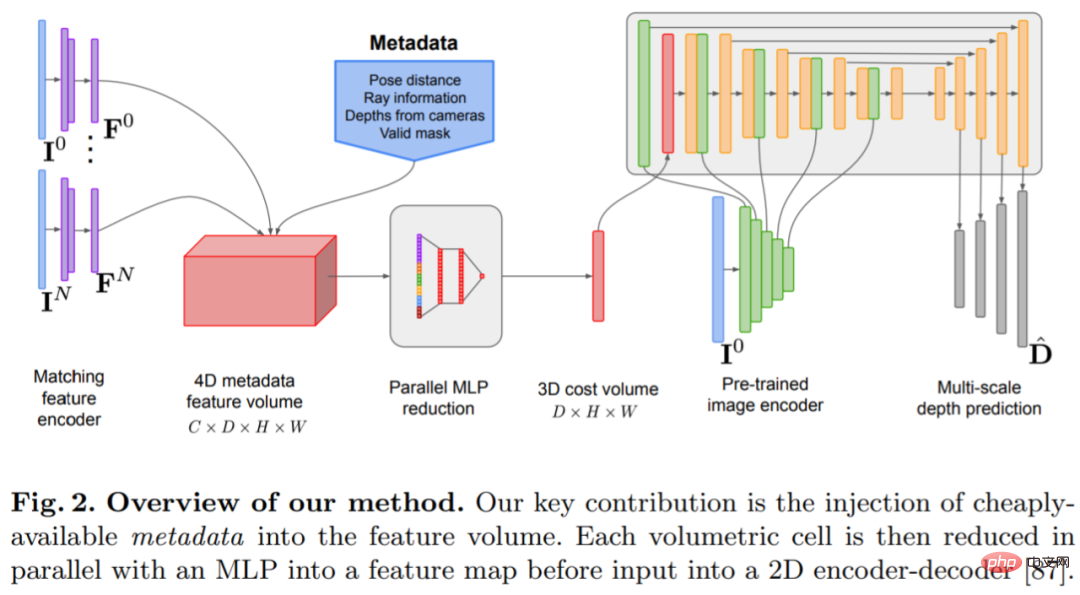
Das Tiefenschätzungsmodell befindet sich am Schnittpunkt von monokularer Tiefenschätzung und planarem Scanning MVS. Der Forscher nutzt das Kostenvolumen (Kostenvolumen), um die Encoder-Decoder-Architektur für die Tiefenvorhersage zu erhöhen, wie in Abbildung 2 dargestellt. Der Bildencoder extrahiert passende Merkmale aus den Referenz- und Quellbildern als Eingabe für das Kostenvolumen. Zur Verarbeitung der Ausgabe des Kostenvolumens wird ein 2D-Faltungs-Encoder-Decoder-Netzwerk verwendet, das durch Merkmale auf Bildebene ergänzt wird, die von einem separaten vorab trainierten Bildencoder extrahiert werden.

 Der Schlüssel zu dieser Forschung besteht darin, vorhandene Metadaten zusammen mit typischen Tiefenbildfunktionen in das Kostenvolumen einzufügen, um dem Netzwerk den Zugriff auf nützliche Informationen wie Geometrie und relative Kamerapositionsinformationen zu ermöglichen. Abbildung 3 zeigt den Aufbau des Feature-Volumes im Detail. Durch die Integration dieser bisher unerschlossenen Informationen ist unser Modell in der Lage, frühere Methoden in der Tiefenvorhersage deutlich zu übertreffen, ohne teure 4D-Kostenvolumina, komplexe zeitliche Fusion und Gaußsche Prozesse.
Der Schlüssel zu dieser Forschung besteht darin, vorhandene Metadaten zusammen mit typischen Tiefenbildfunktionen in das Kostenvolumen einzufügen, um dem Netzwerk den Zugriff auf nützliche Informationen wie Geometrie und relative Kamerapositionsinformationen zu ermöglichen. Abbildung 3 zeigt den Aufbau des Feature-Volumes im Detail. Durch die Integration dieser bisher unerschlossenen Informationen ist unser Modell in der Lage, frühere Methoden in der Tiefenvorhersage deutlich zu übertreffen, ohne teure 4D-Kostenvolumina, komplexe zeitliche Fusion und Gaußsche Prozesse.
Die Studie wurde mit PyTorch implementiert und verwendete EfficientNetV2 S als Rückgrat, das über einen UNet++-ähnlichen Decoder verfügt. Darüber hinaus wurden auch die ersten beiden Blöcke von ResNet18 für die Matching-Feature-Extraktion verwendet, und der Optimierer war AdamW, dessen Fertigstellung auf zwei 40-GB-A100-GPUs 36 Stunden dauerte.
Das Netzwerk wird basierend auf der 2D-Faltungs-Encoder-Decoder-Architektur implementiert. Untersuchungen haben ergeben, dass es beim Aufbau eines solchen Netzwerks einige wichtige Entwurfsentscheidungen gibt, die die Genauigkeit der Tiefenvorhersage erheblich verbessern können, darunter vor allem:
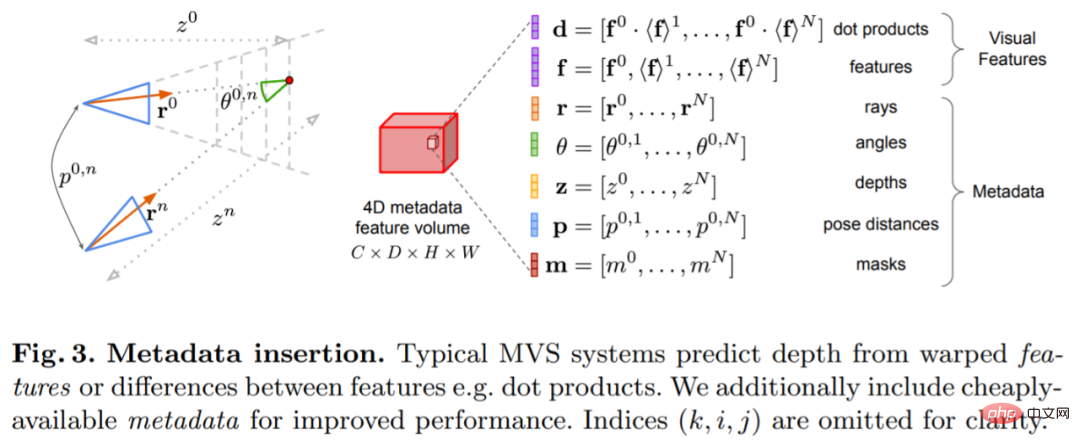
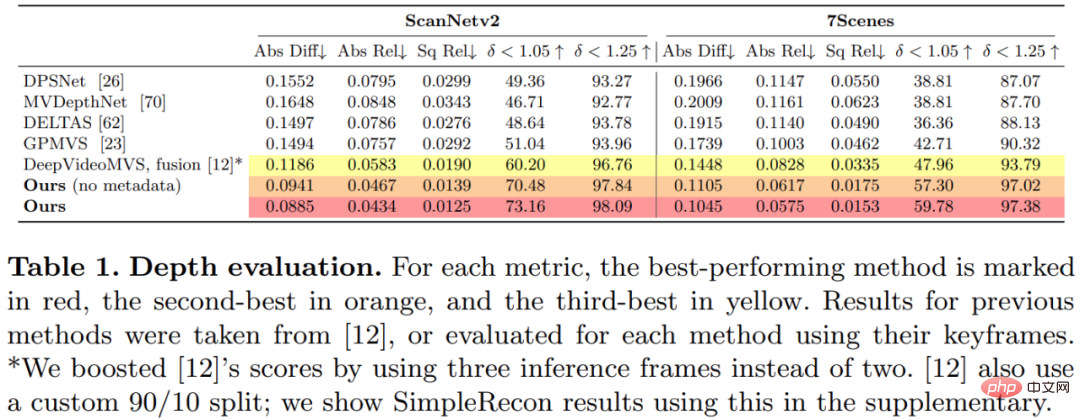
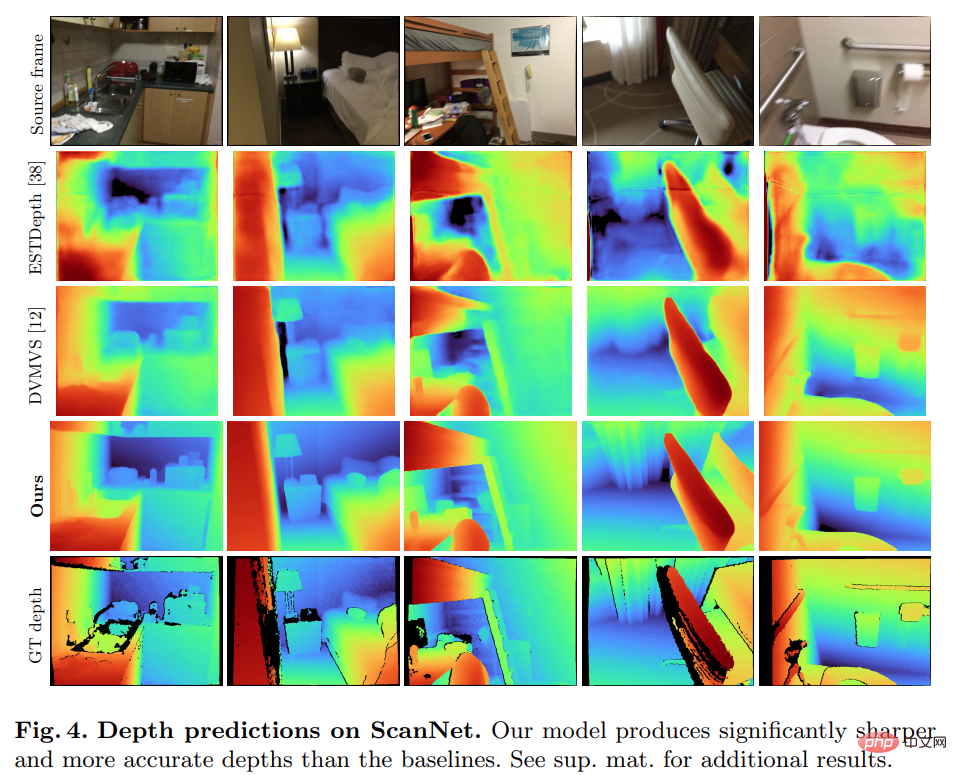
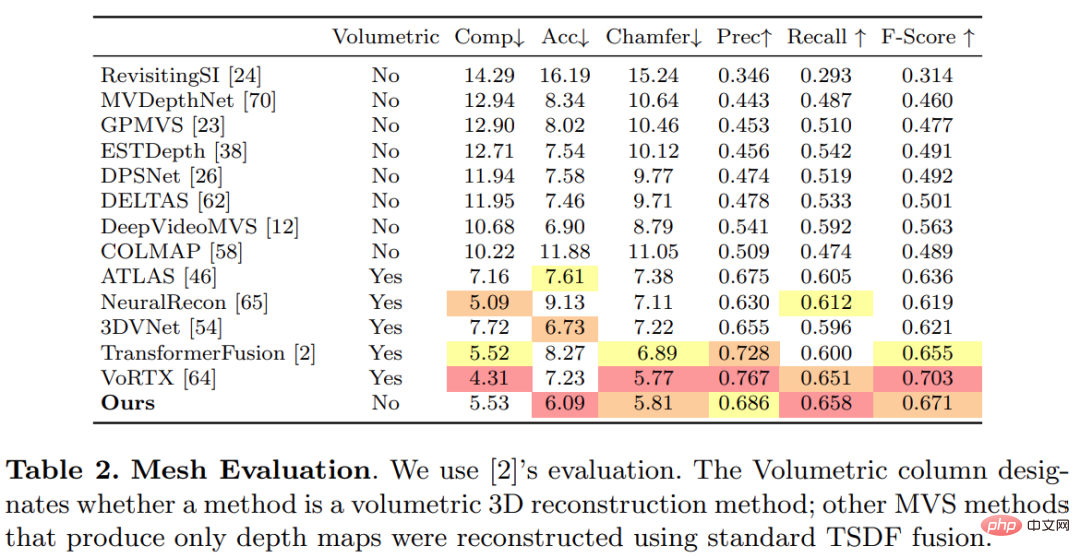
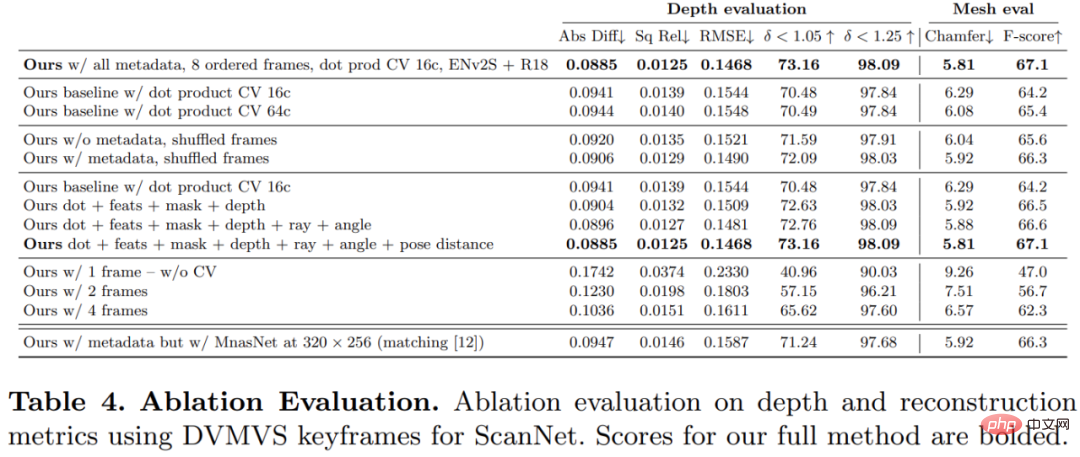
Bild-Encoder und Feature-Matching-Encoder: Frühere Untersuchungen haben gezeigt, dass der Bild-Encoder für die Tiefenschätzung sowohl bei der monokularen als auch bei der Multi-View-Schätzung sehr wichtig ist. DeepVideoMVS verwendet beispielsweise MnasNet als Bildencoder, der eine relativ geringe Latenz aufweist. Die Studie empfiehlt die Verwendung eines kleinen, aber leistungsstärkeren EfficientNetv2 S-Encoders, der die Genauigkeit der Tiefenschätzung deutlich verbessert, allerdings auf Kosten einer höheren Anzahl von Parametern und einer Reduzierung der Ausführungsgeschwindigkeit um 10 %. Verschmelzung von Bildmerkmalen mit mehreren Maßstäben in einem Kostenvolumen-Encoder: Bei 2D-CNN-basiertem Tiefenstereo und Multi-View-Stereo werden Bildmerkmale normalerweise mit der Kostenvolumenausgabe in einem einzigen Maßstab kombiniert. Kürzlich schlägt DeepVideoMVS vor, Deep-Image-Features in mehreren Maßstäben zusammenzufügen und bei allen Auflösungen Sprungverbindungen zwischen Bild-Encodern und Kostenvolumen-Encodern hinzuzufügen. Dies ist hilfreich für LSTM-basierte Fusionsnetzwerke und die Studie ergab, dass es auch für deren Architektur wichtig ist. Diese Studie trainierte und evaluierte die vorgeschlagene Methode anhand des 3D-Szenenrekonstruktionsdatensatzes ScanNetv2. In der folgenden Tabelle 1 werden die von Eigen et al. (2014) vorgeschlagenen Metriken verwendet, um die Tiefenvorhersageleistung mehrerer Netzwerkmodelle zu bewerten. Überraschenderweise verwendet das in dieser Studie vorgeschlagene Modell keine 3D-Faltung, übertrifft aber alle Basismodelle hinsichtlich der Tiefenvorhersageindikatoren. Darüber hinaus schneiden Basismodelle, die keine Metadatenkodierung verwenden, auch besser ab als frühere Methoden, was darauf hindeutet, dass ein gut entworfenes und trainiertes 2D-Netzwerk für eine qualitativ hochwertige Tiefenschätzung ausreicht. Die Abbildungen 4 und 5 unten zeigen qualitative Ergebnisse für Tiefe und Normal. Diese Studie verwendete das von TransformerFusion entwickelte Standardprotokoll für die 3D-Rekonstruktionsbewertung. Die Ergebnisse sind in Tabelle 2 unten aufgeführt. Für Online- und interaktive 3D-Rekonstruktionsanwendungen ist die Reduzierung der Sensorlatenz von entscheidender Bedeutung. Tabelle 3 unten zeigt die Ensemble-Rechenzeit pro Frame für jedes Modell bei einem neuen RGB-Frame. Um die Wirksamkeit jeder Komponente der in dieser Studie vorgeschlagenen Methode zu überprüfen, führte der Forscher ein Ablationsexperiment durch. Die Ergebnisse sind in Tabelle 4 unten aufgeführt. Interessierte Leser können den Originaltext des Artikels lesen, um weitere Forschungsdetails zu erfahren. Experimente


Das obige ist der detaillierte Inhalt vonA100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr