
Heim >Technologie-Peripheriegeräte >KI >Wie reagiert das Geschäftsfeld Digital Intelligence auf die Herausforderungen der Decision-Making-Intelligence-Technologie? Antworten von drei Experten
Wie reagiert das Geschäftsfeld Digital Intelligence auf die Herausforderungen der Decision-Making-Intelligence-Technologie? Antworten von drei Experten

- PHPznach vorne
- 2023-05-06 22:58:081407Durchsuche
In den letzten Jahren wurden mit den Veränderungen in den Bedürfnissen der Werbetreibenden und der Entwicklung verwandter Technologien die Theorie der Computerökonomie, die Spieltheorie und die Technologie der künstlichen Intelligenz zunehmend auf Werbeauktionsmechanismen und Auslieferungsstrategien angewendet.
Die Bedeutung von Entscheidungsintelligenz in Geschäftsszenarien rückt nach und nach immer mehr in den Vordergrund. Jede Produktdarstellung, die Nutzer sehen, jedes Werbegebot von Händlern und jede Traffic-Zuteilung auf der Plattform werden durch riesige und komplexe Entscheidungsintelligenz unterstützt.
Ziel dieser Maßnahmen ist es, das Einkaufserlebnis der Nutzer zu optimieren, den Entscheidungsprozess für Werbung intelligenter zu gestalten und gleichzeitig Werbetreibenden und Medien dies zu ermöglichen Erzielen Sie langfristigen Wohlstand auf der Plattform. Werbetreibende hoffen, die Marketingeffekte mit begrenzten Ressourceninvestitionen zu maximieren, und Plattformen hoffen, ein besseres Ökosystem aufzubauen. Allerdings erschweren die Komplexität des Verkehrsumfelds, das Wettbewerbsumfeld, das durch andere konkurrierende Werbeanzeigen gebildet wird, und die enorme Komplexität der Kombination von Variablen wie Geboten, Zielgruppen, Ressourcenstandorten und Lieferzeiten in der Werbestrategie die Berechnung und Ausführung Die optimale Werbestrategie voller Herausforderungen.
Wie können diese Probleme gelöst werden? Wie gliedert sich das Ziel der Nutzenmaximierung? Diese wichtigen Fragen im Zusammenhang mit Entscheidungsintelligenz sind auch für Forscher und Praktiker auf diesem Gebiet von größter Bedeutung.
Um eine ausführliche Diskussion zum Thema „Decision Intelligence in Digital Intelligence Business Scenarios“ zu führen, haben die Alimama Bojian Society und Heart of Machines kürzlich Deng Xiaotie eingeladen Professor Cai Shaowei von der Universität Peking, Forscher an der Chinesischen Akademie der Wissenschaften, und Zheng Bo, CTO von Alimama, drei hochrangige Wissenschaftler und Experten auf diesem Gebiet, tauschten eine Reihe von Themen aus.
Das Folgende ist der Themenaustauschinhalt von Professor Deng Xiaotie, Forscher Cai Shaowei und Lehrer Zheng Bo, der ihn zusammengestellt hat, ohne die ursprüngliche Bedeutung zu ändern .
Professor Deng Xiaotie: Mehrere neueste Forschungsfortschritte in der Computerökonomie
Ich werde heute eine grobe Einführung in die Computerökonomie geben Ein Forschungsgebiet, dessen Geschichte bis ins Jahr 1930 zurückreicht. Die spätere Computerökonomie begann aus einer anderen Perspektive und verwandelte die Ökonomie in Berechnungen. Die vorherige Computerökonomie bestand darin, Wirtschaftsforschung durch Berechnungen durchzuführen. Dieses Mal werde ich über die Ideen sprechen.

Wenn wir aus rechnerischer Sicht über Wirtschaftswissenschaften nachdenken, gibt es mehrere Hauptthemen: Das erste ist die Optimierung. Maschinelles Lernen ist alles Optimierung, und daraus lassen sich viele Optimierungssysteme ableiten. Nach der Optimierung gibt es noch ein weiteres Thema namens Gleichgewicht. In der Vergangenheit haben wir die rechnerische Ökonomie aus der Perspektive der Planwirtschaft betrieben. Aber damals gab es auch eine Schule, die sich mit der Entwicklung von Entwicklungsländern befasste Weltbank. Sie haben Pläne für Entwicklungsländer entwickelt. Die Berechnung des Gleichgewichts aus rechnerischer Sicht kann ein sehr schwieriges Problem sein. Daher wurde ein Konzept namens „berechenbares allgemeines Gleichgewicht“ entwickelt.
In letzter Zeit können wir immer mehr dynamische Systeme sehen, weil sich viele Dinge auf dieser Welt nicht in einem Gleichgewichtszustand befinden, und die Szene, in der wir Gleichgewicht sehen, ist besonders prominent . Bei digitalen Wirtschaftsaktivitäten umfasst dies auch Dinge auf wirtschaftlicher Ebene, wie zum Beispiel die Preisgestaltung. In der digitalen Wirtschaft sind Transaktionsdaten und Preisschwankungen jede Sekunde sichtbar. Wir können die Veränderungen in den Daten deutlich erkennen, anstatt nur die Wirtschaftsdaten nach Ablauf eines Jahres zu zählen.
Im Gesamtrahmen der Computerökonomie gibt es noch viel mehr. Jede Wirtschaftseinheit muss optimieren, und der Fixpunkt ihres gemeinsamen Spiels ist das Gleichgewicht. Plattformen spielen auch ein Gleichgewichtsspiel, insbesondere Internet-Werbeplattformen kommen auf die Plattform und verbreiten die Werbung über die Plattform und die Medien. Für die Medien ist es notwendig, Werbepositionen bereitzustellen und ihre eigene Anziehungskraft auf eine bestimmte Art von Menschen auszuüben. Was die Plattform betrifft, müssen wir darüber nachdenken, wie wir die Interessen aller besser berücksichtigen können. Als größte Werbeplattform in China steht Alimama auch vor dem Problem des Spielgleichgewichts. Es muss die Interessen aller Parteien berücksichtigen, um den sozialen Nutzen zu maximieren und die Vorteile des Mechanismusdesigns zu maximieren. Wir können aus drei Perspektiven über Optimierung sprechen.
Das erste ist die Frage der Charakterisierung der Wirtschaftsintelligenz. Viele Dinge des maschinellen Lernens werden als Optimierungsprobleme geschrieben, z. B. wie man Methoden des maschinellen Lernens verwendet, um Einschränkungen zu berechnen, einschließlich Einschränkungen in einigen Umgebungen.
Unter unvollständigen Informationen sind viele Bedingungen unbekannt. Die ursprüngliche Ökonomie kann so komplexe Dinge nicht berücksichtigen, wie zum Beispiel die Nutzenfunktion des Spielgegners, den Strategieraum des Spielgegners und wer die Spielgegner sind Auch unvollständige Informationen sind für die Beschreibung wirtschaftlicher Aktivitäten von großer Bedeutung.
Viele Annahmen können unvollständige Informationen beschreiben, z. B. dass der Wirtschaftsmensch die Nutzenfunktion des Gegners, Einschränkungen und andere verschiedene Informationen kennt. Es besteht allgemeines Wissen über die Nutzenfunktionen des jeweils anderen: Wir kennen die Verteilung. Aber woher kam diese Verbreitung? Das bringt uns in den Bereich des maschinellen Lernens: Warum erzählt der Spieler einander und uns, was er weiß? Vor diesem Hintergrund stellen sich einige sehr berechtigte Fragen zum Berechnungswinkel.
Spieldynamik, das ist der dritte Schritt der Computerökonomie. Aus der Perspektive der Ökonomie der Realwirtschaft haben sich viele Aktivitäten im Laufe von 6.000 Jahren entwickelt und entwickelt, und jeder spielt das Spiel langsam, bis ein Gleichgewicht erreicht ist. In der digitalen Wirtschaft wird es eine große Herausforderung sein, auf einmal ein Gleichgewicht zu erreichen.
Werbeplattformoptimierung ist das, was Alimama tut. Wir haben über so viele schwierige Computeraufgaben gesprochen. Wann werden wir sie gut bewältigen können? Im Fall einzelner Parameter können bestehende Theorien dies unterstützen, es gibt jedoch keine vorgefertigte theoretische Definition dafür, wie mehrere Parameter erreicht werden können.
Ein sehr wichtiger Punkt ist, dass das gesamte Wirtschaftssystem etabliert ist, aber wenn Wirtschaftswissenschaften im Internet verwendet werden, wird es einen großen Fehler geben – es ist statisch. Jeder muss wissen, dass die Dinge in der Branche nicht statisch sind. Beispielsweise wird die „Double Eleven“-Aktion viele Herausforderungen mit sich bringen. Wie man den Preis für rote Umschläge gestaltet und wie man diese Dinge auf der Grundlage bekannter Marktmodelle aufbaut Herausforderungen in der Computerökonomie: Die eine ist die Optimierung der Näherungslösung, die andere die Gleichgewichtsplanung und die andere die Dynamik des Plattformwettbewerbs.

Eine ungefähre Berechnung ist sehr schwierig. Die uns bekannte Gleichgewichtslösung kann höchstens auf ein Drittel berechnet werden, mit einer Fehlerquote von höchstens 33 %, was einer Abweichung von 33 % vom Optimum entspricht in der Tat ziemlich schwierig. Automatische Entwurfsmethoden und das Lernen versteckter Gegnermodelle sind die Rahmenbedingungen in diesem Bereich, und sie hängen alle mit der Informationskapazität zusammen.

Das andere ist das Zocken mit unbekannten Konkurrenten auf dem Markt. Wir müssen mindestens zwei Unternehmen in Betracht ziehen und ein Modell entwickeln, um das Spiel zwischen ihnen zu gestalten. Es ist alles eintönig und nicht alle Informationen sind bekannt. Basierend auf den bekannten Informationen betrachten wir Marktschwankungen und Preisdesignänderungen. Darauf aufbauend entwerfen wir ein Optimierungsmodell impliziter Funktionen und nutzen Methoden des maschinellen Lernens zur Analyse.
Die Reihenfolge der Mehrparteienkognition bringt uns die kognitive Ebene des Spiels. In den letzten Jahren wurden in mehreren Studien viele Gründe diskutiert, warum Erstpreisauktionen besser sind als Zweitpreisauktionen. Myerson hat eine Theorie optimaler Auktionen entwickelt, die davon ausgeht, dass jeder die Wertverteilung aller kennt, wir aber nicht wirklich das öffentliche Wissen kennen. Unsere eigene Forschung wird aus einer anderen Perspektive betrachtet. Der Ausgangspunkt ist, dass es kein allgemeines Vorwissen gibt und die ursprüngliche Annahme, Myersons optimale Auktionstheorie mithilfe der probabilistischen Methode zu etablieren, aufgegeben wird.
Wie kann die optimale Lösung ein Gleichgewicht erreichen, wenn diese Grundannahmen des Auktionsgleichgewichts fehlen? Es kann festgestellt werden, dass der allgemeine Ein-Preis-Auktionserlös Myerson entspricht. Hier sollten wir uns mit der vom Käufer angekündigten Wertverteilung mit dem optimalen Nutzen befassen, da das Ziel der vom Verkäufer entworfenen optimalen Rendite nach Myerson der erwarteten Auktionsrendite der allgemeinen Einpreisauktion entspricht.
Die endgültige Schlussfolgerung ist, dass Myerson und GFP gleichwertig sind, sie sind besser als VCG, aber sie sind im Fall von IID gleichwertig, Symmetric BNE und GSP sind ebenfalls gleichwertig.
Ein weiteres in der Computerökonomie verwendetes Konzept ist das Markov-Spiel, ein Spiel in einer dynamischen Umgebung, insbesondere das Problem der Lösung unendlicher Spielrunden. Wir haben das Problem aus drei Richtungen angegangen: erstens, indem wir die Berechnung rational vereinfachten und das Ziel auf Näherungslösungen beschränkten, zweitens, indem wir die Zeitdiskontrate verwendeten, um die Konvergenz unendlicher runder Renditen sicherzustellen; drittens, die mathematische Analyse der Stufensummierung begrenzt die Änderungen in der Strategie in verschiedenen Runden zu den Änderungen in einer Runde. Auf diese Weise kann die Schwierigkeit der unendlichen Summation überwunden werden.
Wir vereinfachen die Berechnungsschwierigkeiten bei der Anwendung des Markov-Spiels weiter. Für die Gestaltung des Konsensmechanismus gibt es eine klare Markov-Belohnungsanalyse, die eine gute Geschichte erzählt. Nach den Regeln des Mechanismusdesigns ist es richtig, wenn die meisten Menschen es unterstützen. Später stellte sich jedoch heraus, dass die Mehrheitsunterstützung keine wirtschaftliche Sicherheit garantierte.

Was die Probleme im Designprozess der digitalen Wirtschaft betrifft, kann unsere neueste Arbeit mit Insightful Mining Equilibrium, der Verwendung weitsichtiger Strategien zur Erreichung von Optimalität, und schließlich der Struktur des Markov-Spiels, die die Markov-Belohnung bildet, überwunden werden Der Prozess fügt eine Erkenntnisebene hinzu, vom ehrlichen Pool zum egoistischen Pool, und überquert dann eine weitere Ebene, um zum Ergebnis des visionären Pools zu gelangen.
In ähnlicher Weise müssen sich viele Internetunternehmen eher mit dynamischen als mit statischen Dingen befassen. Die heutige Weltwirtschaft ist nicht mehr die Ökonomie der Vergangenheit. Darüber hinaus sind die Methodik des maschinellen Lernens und die Spieltheorie durch die Mathematik eng miteinander verbunden. Damit haben wir die Situation, nur mit statischen Ökonomien umgehen zu können, überwunden und uns zu einer Fähigkeit entwickelt, mit dynamischen Situationen umzugehen.
Forscher Cai Shaowei: Eine effiziente Methode zur Lösung großräumiger spärlicher kombinatorischer Optimierungsprobleme
Hallo zusammen, das Thema, das ich heute teile, ist eine effiziente Methode für großräumige spärliche kombinatorische Optimierung. Der Kern vieler Entscheidungsprobleme sind kombinatorische Optimierungsprobleme, und die Menschen sind sehr besorgt darüber, wie sie eine geeignete Kombination von Lösungen auswählen können, um eine Zieloptimierung zu erreichen.
Es gibt zwei Hauptmethoden zur Lösung der kombinatorischen Optimierung: Eine davon ist die heuristische Methode, einschließlich der heuristischen Suche und der heuristischen Konstruktion. Beispielsweise kann der häufig verwendete Greedy-Algorithmus als eine Art heuristische Konstruktion angesehen werden Heuristik; die andere ist ein exakter Algorithmus, der durch Brand-and-Bound dargestellt wird.
Der Vorteil der heuristischen Methode besteht darin, dass sie nicht skalenempfindlich ist und daher großräumige Probleme mit Näherung lösen kann. Der Nachteil besteht darin, dass oft nicht bekannt ist, wie weit die optimale Dissoziationslösung entfernt ist Möglicherweise wurde eine Lösung gefunden, aber Sie wissen es nicht. Wenn Sie Branch And Bound genügend Zeit zum Berechnen und Stoppen geben, können Sie die optimale Lösung finden und beweisen, dass es die optimale Lösung ist. Allerdings ist diese Methode mit Kosten verbunden und skalenempfindlich, da diese Art von Algorithmus exponentiell explosiv ist und oft nicht für groß angelegte Probleme geeignet ist.
Ob es um Suchen oder Konstruieren geht, das heuristische Algorithmus-Framework ist meist sehr einfach. Es hängt hauptsächlich davon ab, wie die Heuristik gestaltet ist und auf welchen Kriterien sie basieren soll. Die Branch-and-Bound-Methode konzentriert sich hauptsächlich darauf, wie man „Grenzen“ festlegt. Wenn Sie die Artikel lesen, werden Sie feststellen, dass viele Branch-and-Bound-Artikel die Begrenzungstechnologie verwenden, um den Lösungsraum besser zu beschneiden.
Später dachte ich, können wir diese beiden kombinieren? Mit anderen Worten: Es kann nicht nur skalenunempfindlich bleiben, sondern auch Begrenzungstechnologie hinzufügen. Es ist leicht zu glauben, dass Sie Vorverarbeitungsmethoden verwenden oder zuerst Heuristiken und dann Branch-and-Bound durchführen und die Ergebnisse der Heuristiken als erste Lösung usw. verwenden können. Wir schlagen diesbezüglich einen neuen Ansatz vor – verschachtelte Iteration in Heuristik und Branch And Bound.

Einfach ausgedrückt führt diese Methode zunächst eine grobe heuristische Lösung durch, um ein vorläufiges Ergebnis zu finden. Im Allgemeinen sind für die Begrenzung Ober- und Untergrenzen erforderlich. Heuristiken ermitteln grob eine Untergrenze und entwerfen dann eine Funktion für die Obergrenze. Unter der Annahme, dass das Problem relativ groß ist und viele Elemente umfasst, können wir einige eliminieren, um das Problem zu verkleinern. Seien Sie dann verfeinert und fahren Sie mit der heuristischen Lösung fort, die die Untergrenze verbessern kann. Auf dieser Grundlage kann der Algorithmus weitere Begrenzungen vornehmen und weiterhin verschachtelt sein. Dieser Algorithmus wird also zu einem halbgenauen Algorithmus, und es kann bewiesen werden, dass dies die optimale Lösung ist, da in einem bestimmten Schritt festgestellt wird, dass der Problemraum klein genug ist und keine heuristische Lösung erforderlich ist, sondern gelöst werden kann direkt und präzise. Wenn die optimale Lösung nicht gefunden wird, können Sie außerdem wissen, wo das optimale Lösungsintervall liegt.

Als nächstes geben wir zwei Beispiele, um diese Methode zu erklären.
Das erste ist das „Maximalgruppenproblem“. Clique ist ein sehr klassisches Konzept in der Graphentheorie. In einem Graphen gibt es Teilgraphen, die durch Kanten zwischen Punkten verbunden sind, was als Clique bezeichnet wird. Das Problem der maximalen Clique besteht darin, die größte Clique zu finden. Wenn Sie ihm ein Gewicht geben und jedem Scheitelpunkt ein Gewicht zuweisen, besteht das Problem der maximal gewichteten Clique darin, die Clique mit dem größten Gesamtgewicht zu finden. Im folgenden Beispiel gibt es vier Gruppen bzw. drei Gruppen. Das Gewicht der drei Gruppen ist größer, was die größte gewichtete Gruppe in diesem Bild darstellt.
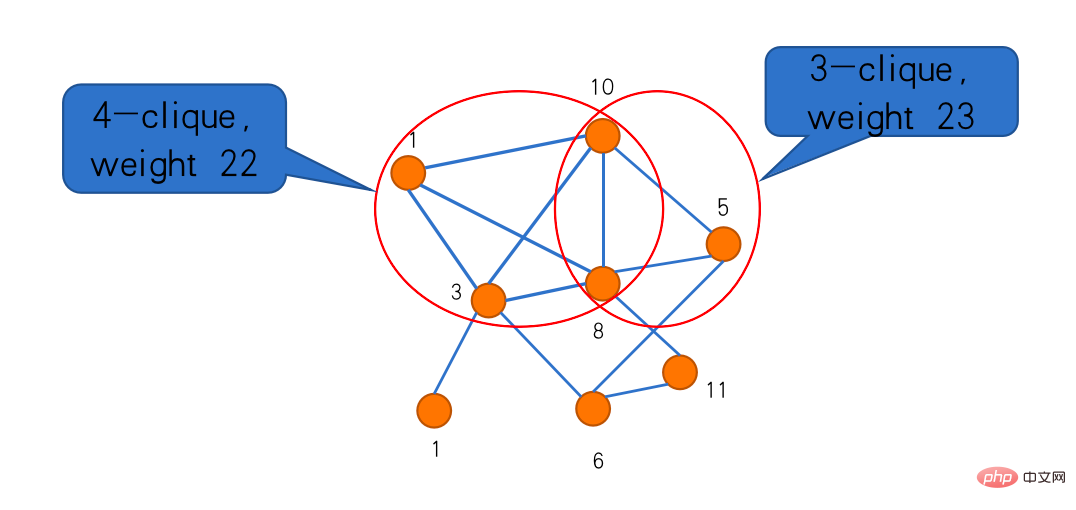
Um dies gemäß diesem Framework zu tun, benötigen wir zwei Unteralgorithmen, einer ist eine heuristische Lösung, die in der Gruppe FindClique heißt, und der andere ist ein Vereinfachungsalgorithmus namens ReduceGraph. Mit FindClique können wir eine Clique finden, die besser ist als die, die wir zuvor gefunden haben. Wenn diese bessere Gruppe den Reduziergraphen erreicht, wissen wir: Die größte Gruppe ist mindestens so groß. In diesem Schritt erfolgt auch die Vereinfachung. Wenn das Diagramm nach der Vereinfachung leer wird, ist der gefundene Cluster die optimale Lösung. Wenn er nicht leer wird, können Sie einige Punkte reduzieren und den Algorithmus zum Finden des Clusters anpassen. Der Algorithmus hier ist nicht unbedingt ein fester Algorithmus und kann sich dynamisch ändern.
Einer unserer Jobs wählte die „Construct and Cut“-Methode, die als multipler Greedy-Algorithmus verstanden werden kann.
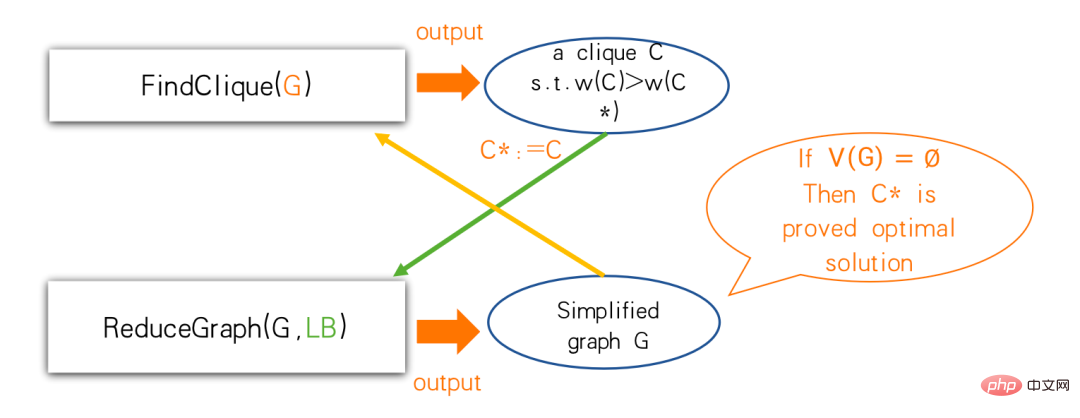
Der Effekt mehrerer Greedy-Konstruktionen besteht darin, dass jede Greedy-Konstruktion sehr schnell sein und von unterschiedlichen Startpunkten aus beginnen kann. Wenn sie während eines bestimmten Konstruktionsprozesses berechnet wird, kann die aktuelle Gruppe nicht erweitert werden, egal wie stark sie ist Es wird erweitert. Wir können die zuvor gefundene Gruppe stoppen. Das ultimative Ziel besteht darin, eine Gruppe zu finden, die größer ist als zuvor. Ob die Heuristik verfeinert werden sollte und wie die Reihenfolge angepasst werden soll, hängt vom Maßstab des Diagramms ab Verfeinern Sie es dann, um einen größeren Fokus auf die Suche nach besseren Teams zu legen. Wenn der Graph nicht mehr vereinfacht werden kann, können wir präzise Algorithmen wie Branch And Bound verwenden. Nachdem wir eine Gruppe gefunden haben, müssen wir gemäß unserer Methode eine Begrenzung durchführen und einige Punkte wegwerfen. Die Methode besteht darin, die Größe der Gruppe abzuschätzen, die die Punkte entwickeln können, und es kann verschiedene Lösungen geben, um sie zu lösen.
Diese beiden Grenzschätzungstechnologien sind nur Beispiele, und Sie können dazu verschiedene Technologien verwenden. In Bezug auf Experimente können Sie sich auf die folgende Tabelle beziehen, um Methoden wie FastWClq, LSCC+BMS und MaxWClq zu vergleichen. Die zum Erreichen der gleichen Genauigkeit erforderliche Zeit unterscheidet sich um mehr als das Zehnfache oder sogar Hundertfache.

Schauen wir uns die zweite Frage an: „Problem mit der Grafikfärbung“. Bei der sogenannten Färbung wird auf jeden Punkt des Diagramms eine Farbe angewendet. Zwei benachbarte Punkte können nicht die gleiche Farbe haben wird als Farbzahl des Diagramms bezeichnet. Das Problem der Graphfärbung hat viele Anwendungen, insbesondere bei der konfliktfreien Zuweisung von Ressourcen.
Die allgemeine Idee dieses Problems ist dieselbe – heuristische Lösung plus einige Begrenzungstechnologien. Der Unterschied besteht darin, dass für das Diagrammfärbeproblem keine Teilmenge erforderlich ist, da das gesamte Diagramm nicht gefärbt werden muss. Jeder Punkt muss am Ende zurückgegeben werden Farbe. Die Reduzierung hier besteht darin, das Diagramm in Kernel und Margin zu zerlegen:

Es gibt eine sehr einfache Regel, die sich immer noch auf die unabhängige Menge bezieht. Wenn ich zumindest weiß, wie viele Farben dieses Diagramm verwenden muss, es ist die untere Farbgrenze (aufgezeichnet als ℓ), dann kann der unabhängige Satz der ℓ-Grad-Grenze gefunden werden. Die Grade der Punkte in dieser unabhängigen Menge sind alle kleiner als ℓ, daher wird dies als ℓ-Grad-Grenze bezeichnet. Wenn Sie einen solchen unabhängigen Satz finden, können Sie ihn sicher an den Rand verschieben. Wenn wir die Lösung des Kernels finden, können wir die Marge leicht einbeziehen. Wenn der Kernel die optimale Lösung ist, muss die Kombination auch die optimale Lösung sein.

Schauen wir uns ein Beispiel an. In diesem Beispiel sind die vier grauen Punkte der Kern. Sie können sehen, dass mindestens 4 Farben benötigt werden. Die drei Punkte daneben liegen am Rand. Da die Grade der drei Punkte kleiner als 4 sind, können wir diese drei Punkte getrost zur Seite verschieben und sie vorerst ignorieren. Dann stellte ich fest, dass der verbleibende Teilgraph nicht zerlegt werden kann. Er ist bereits sehr kernintensiv und kann direkt gelöst werden. Der harte Kern dünn besetzter Graphen ist im Allgemeinen nicht groß, sodass zur Lösung exakte Algorithmen in Betracht gezogen werden können. Wenn Sie den Kern finden, ist bekannt, dass der Kern mindestens vier Farben verwendet. Für die Punkte an der Kante ist der Grad jedes Punktes kleiner als 4. Wie kann man eine Farbe dafür einfach linear durchlaufen lassen? Zeit. .

Bis zum Ende muss der Rand jeder Schale erhalten bleiben und die Schicht muss deutlich markiert sein. Dies unterscheidet sich geringfügig von der ersten Frage. Wir müssen zusätzliche Datenstrukturen verwenden, um diese Kantenkarten beizubehalten. Nachdem der letzte unbewegliche Kernel genau gelöst wurde, können wir die Methode in umgekehrter Reihenfolge verwenden, um zuerst den letzten Rand zusammenzuführen und die Optimalität gemäß den vorherigen Regeln beizubehalten , ist das Zusammenführen einer Kante immer noch optimal, wenn Sie ganz zurückgehen, muss auch die Lösung zum Originalbild optimal sein.
Wenn dieses Problem konkret wird, bleibt nur noch die Überlegung, wie man die Unter- und Obergrenze findet. Die allgemeine Idee des Algorithmus ist: Zu Beginn ist der Kernel das Originalbild, und der Maximum-Clique-Algorithmus muss verwendet werden, um eine Untergrenze zu finden. Nach dem Abziehen der Kanten kann der Greedy-Graph-Coloring-Algorithmus verwendet werden um eine Obergrenze zu finden.

Hier kommen tatsächlich drei Algorithmen zum Einsatz. In der Praxis ist die Kombinationsstanzmethode häufiger anzutreffen, insbesondere für die Kernelfärbung. Wenn das Bild relativ groß ist, verwenden wir möglicherweise eine gierige oder schnellere Methode, und schließlich wird daraus ein genauer Algorithmus. Während des gesamten Prozesses sind die Untergrenze und die Obergrenze global. Wenn diese beiden gleich sind, können Sie aufhören.

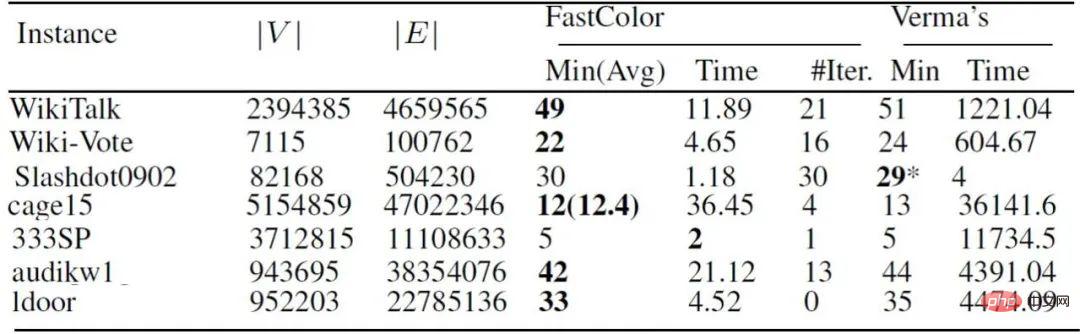
Das obige Bild ist das experimentelle Ergebnis. Es ist ersichtlich, dass der Effekt bei spärlichen großen Bildern besser ist. 97 von 144 können die optimale Lösung innerhalb einer Minute beweisen. Im Vergleich zu ähnlichen Algorithmen ist die Vergleichszeit unseres Algorithmus auch schneller. Es gibt spezielle Methoden für relativ spärliche große Diagramme, die das Problem schnell lösen können. Früher dachte man, dass die Lösung NP-schwerer Probleme mit Millionen von Eckpunkten lange dauern muss. Wenn diese Diagramme zwar groß sind, aber bestimmte Eigenschaften aufweisen, können wir sie dennoch in Sekunden und Minuten lösen.
Alimama CTO Zheng Bo: Alimamas kontinuierlich verbessertes Entscheidungsintelligenz-Technologiesystem
Hallo zusammen, als technischer Direktor von Alimama bin ich von Aus Branchenperspektive werden wir über die Fortschritte von Alimama in der Technologie zur Entscheidungsfindung in den letzten Jahren berichten.
Alimama wurde 2007 gegründet und ist die Kernkommerzialisierungsabteilung der Alibaba Group, der Abteilung für Online-Werbung. Nach mehr als zehn Jahren Entwicklungszeit hat Alimama einflussreiche Produkte wie „Search Advertising Taobao Express“ entwickelt. Im Jahr 2009 wurden Display-Werbung und Ad Exchange-Werbehandelsplattformen eingeführt, und im Jahr 2014 erschien die Datenverwaltungsplattform Damopan Marketing im Jahr 2016.

Aus technischer Sicht hat sich Alimama in den Jahren 2015 und 2016 voll und ganz dem Deep Learning verschrieben Engine OCPX bis hin zum selbst entwickelten CTR-Vorhersage-Kernalgorithmus MLR-Modell, sie alle entwickeln sich mit Deep-Learning-Methoden weiter. Im Jahr 2018 war das Deep-Learning-Framework X-Deep Learning Open Source. Im Jahr 2019 wurde das Euler-Graph-Learning-Framework als Open-Source-Lösung eingeführt und außerdem wurden Superempfehlungen für Informationsflussprodukte eingeführt, die sich zu „Waren finden Menschen“ entwickelten. Ab 2020 startete Alimama Live-Streaming-Werbung und begann auch mit der Einführung interaktiver Incentive-Anzeigen, wie zum Beispiel des interaktiven Spiels „Double Eleven“ Stacking Cat, das immer häufiger gespielt wird. Das Curvature-Space-Lernframework war dieses Jahr ebenfalls Open Source.
Im Jahr 2022 hat Alimama ein großes Upgrade an der gesamten Werbemaschine vorgenommen. Die Werbeplattform EADS und die Multimedia-Produktions- und Verständnisplattform MDL sind beide online. Im Hinblick auf den Schutz der Privatsphäre der Verbraucher wurden die Fähigkeiten von Alimama im Bereich Datenschutz-Computing-Technologie von der China Academy of Information and Communications Technology zertifiziert. Wenn wir auf die Entwicklung von Alimama in den letzten fünfzehn Jahren zurückblicken, können wir erkennen, dass wir ein Unternehmen sind, das sich mit computergestützter Werbung beschäftigt.
Was sind die Vorteile von Alimama? Im sehr professionellen E-Commerce-Bereich verfügen wir über ein sehr ausgeprägtes Verständnis für Benutzer und E-Commerce, und auch die Geschäftsszenarien sind sehr umfangreich. Neben der traditionellen Suche und Empfehlung verfügen wir auch über digitale Geschäftsszenarien wie Live-Übertragungen Werbung, Interaktion und neue Formen. Darüber hinaus gehört unser Kundenstamm zu den größten der Welt, da Millionen von Händlern als Werbetreibende auf der Plattform von Alimama fungieren. Diese Kunden haben neben den geschäftlichen Anforderungen auch verschiedene ökologische Rollen, wie z. B. Anker, Experten, Agenten und Dienstleister. Sie sind in verschiedenen Rollen auf dieser Plattform aktiv.

Wir betreiben auch viel Forschung im Bereich KI. Hier stellen wir die Merkmale der Algorithmustechnologie für Werbeszenen vor. Wie oben gezeigt, ist die umgekehrte Trichterstruktur auf der linken Seite vielen Studenten, die Suchanfragen oder Empfehlungen durchführen, sehr vertraut. Dieser Teil der Werbung ist der Suchempfehlung sehr ähnlich, einschließlich Werbeerinnerung, Grobsortierung, Feinsortierung und Bewertung von Mechanismusstrategien. Sie beinhalten eine große Menge an KI, wie z. B. Informationsabruftechnologien, insbesondere Rückrufmodelle wie Matching TDM, und nutzen alle Deep-Learning-Technologie.
Dies beinhaltet Entscheidungsintelligenz angesichts der Tatsache, dass die Plattform viele Rollen mit jeweils eigener Spielbeziehung, zwischen Mehrparteienbeziehungen und optimierter Balance enthält , Entscheidungsinformationen werden gesendet. Benutzererfahrung, Traffic-Kosten, erwartete Einnahmen, Budgetkontrolle und domänenübergreifende Integration müssen alle im Gleichgewicht sein.
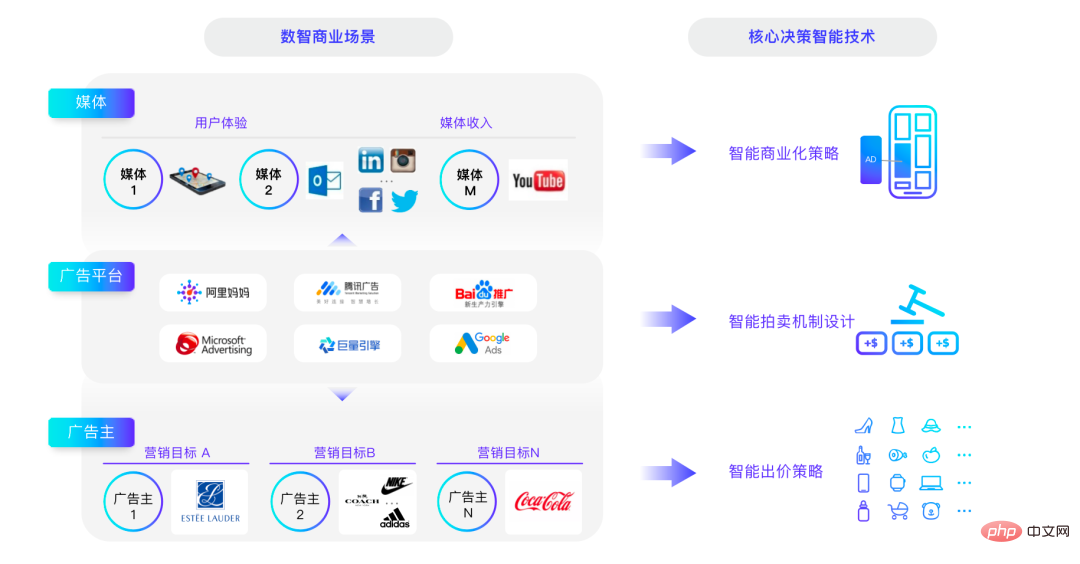
Hier werde ich über drei typische Spieler sprechen. Es gibt viele Akteure auf der Plattform und es gibt drei Hauptkategorien: Medien, Werbetreibende und Werbeplattformen.
Die Kerntechnologien dieser drei Teile lassen sich wie folgt zusammenfassen: Konzentrieren Sie sich aus Medienperspektive auf die Veröffentlichung, welche Medienressourcen aus Sicht des Werbetreibenden das beste Gleichgewicht zwischen Benutzererfahrung und kommerziellen Einnahmen herstellen können, was optimiert werden sollte und wie Marketingziele erreicht werden können zu minimalen Kosten. Was ist also das größte Ziel einer Werbeplattform? Langfristig besteht das untergeordnete Ziel der Werbeplattform darin, die gesamte Plattform erfolgreicher zu machen. Geld zu verdienen ist nur eine kurzfristige Angelegenheit, und die Plattform langfristig erfolgreich zu machen, ist daher das Die Plattform muss die Beziehung zwischen allen Parteien ausgleichen und es Spielern aller Parteien ermöglichen, auf der Plattform zu spielen.
Die Optimierungsziele der Werbeplattform erfordern viel Mechanismusdesign. Heute werde ich kurz über die drei Richtungen des intelligenten Auktionsmechanismusdesigns, der intelligenten Gebotsstrategie und der intelligenten Kommerzialisierungsstrategie sprechen. Ich werde hauptsächlich über Alimamas diesbezügliche Arbeit in den letzten Jahren auf populärwissenschaftliche Weise sprechen, damit jeder darüber diskutieren kann.

Intelligentes Auktionsmechanismusdesign.
Lassen Sie uns zunächst über das Design intelligenter Auktionsmechanismen sprechen. Dies ist ein sehr interessantes Thema. Viele Senioren und Experten haben den Nobelpreis für Wirtschaftswissenschaften gewonnen. Die klassischen Auktionsmechanismen, über die wir sprechen, erschienen alle vor den 1970er Jahren. Damals gab es noch keine Online-Werbung und alle beschäftigten sich intensiv mit der Optimierung von Einzelauktionen oder statischen Auktionen. Bei diesen Mechanismen handelt es sich in der Regel um Einzelziel- und Einzelauktionsmechanismen.
Ob es sich um eine Werbeplattform oder ein Medium handelt, es ist notwendig, Benutzererfahrung und Werbeeinnahmen in Einklang zu bringen. Ein typisches Branchenproblem ist die Optimierung mit mehreren Zielen. Wenn viele Unternehmen an der Plattform beteiligt sind, gibt es möglicherweise Plattformstrategien und Wille zwischen verschiedenen Unternehmen. Dies ist auch eine Optimierung mit mehreren Zielen.
Von Anfang an wurde die klassische Auktionstheorie wie GSP oder UGSP für die Verkehrsverteilung und Preisgestaltung verwendet. Die Branche entwickelte sich nach und nach zu Deep Learning, um dieses Problem zu lösen. Diese klassischen Algorithmen verwenden Formeln, um einige Parameter zu berechnen, die die Plattform für ein bestimmtes Ziel optimiert. Mit den Tools des Deep Learning ist das Design des Auktionsmechanismus selbst auch ein Entscheidungsproblem Der Produktionsentscheidungsalgorithmus ist ebenfalls ein Entscheidungsproblem.
Vor drei Jahren haben wir einen auf Deep Learning basierenden Deep GSP-Auktionsmechanismus entwickelt, der unter der Prämisse verbessert wurde, die gute Natur des Mechanismus zu befriedigen; Der Mechanismus bezieht sich auf die Anreizkompatibilität, und Werbetreibende müssen nicht in die gleiche Falle tappen. Es ist eine schwarz-graue Möglichkeit, Gewinne zu erzielen. Wenn Sie Ihre Wünsche wirklich äußern, können Sie den Verkehr erhalten, der dem Gebot entspricht. Deep GSP behält die Anreizkompatibilitätseigenschaft bei und ersetzt die ursprüngliche statische Formel durch ein lernbares tiefes Netzwerk. Dies ist die erste Arbeitsstufe.
In der zweiten Stufe haben wir durch Trainingsoptimierung viele Parameter im Auktionsmechanismus-Netzwerk berechnet. Tatsächlich sind sie aber im gesamten Prozess neben der Parameterberechnung, der Sortierung und den Werbeverteilungsprozessen ein integraler Bestandteil des Gesamtsystems. Einige Module sind tatsächlich nicht differenzierbar, beispielsweise das Sortiermodul. Daher ist es für ein Deep-Learning-Netzwerk schwierig, sie zu simulieren. Um den Auktionsmechanismus durchgängig zu gestalten, modellieren wir den differenzierbaren Teil des Auktionsprozesses das neuronale Netzwerk, sodass der Gradient umgekehrt werden kann, was das Modelltraining komfortabler macht.

Smart Bidding-Strategie.
Lassen Sie uns als Nächstes über die Smart Bidding-Strategie sprechen, das wichtigste Instrument, das Werbetreibende zur Anpassung von Effekten oder Spielen verwenden. Ein zentraler Vertrieb kann keine Forderungen äußern, aber es gibt eine Möglichkeit, sie in Werbeszenarien zum Ausdruck zu bringen. Ausschreibungsprodukte sind in drei Entwicklungsstufen unterteilt:
Die ursprüngliche klassische Lösung ist auch die älteste Ausschreibungsmethode. Es wird erwartet, dass das Budget reibungsloser ausgegeben wird und die Wirkung zu Beginn stärker ist ein PID-ähnlicher Regelalgorithmus. Dies ist ein sehr einfacher Algorithmus mit begrenzten Auswirkungen.
In den Jahren 2014 und 2015, nachdem AlphaGo die Menschen besiegt hatte, erkannten wir die Kraft des verstärkenden Lernens. Smart Bidding ist ein sehr typisches Problem bei der Entscheidungsfindung. Ob die vorherigen Ausgaben gut sind oder nicht, wirkt sich auf die nachfolgende Gebotsentscheidung aus. Daher haben wir in der zweiten Phase darauf geachtet Gebote, die auf verstärktem Lernen basieren, nutzen dazu durch MDP-Modellierung direkt verstärktes Lernen.
Die dritte Stufe entwickelte sich zur SORL-Plattform, die durch die Inkonsistenz zwischen der Offline-Simulationsumgebung und der Online-Umgebung beim Reinforcement Learning gekennzeichnet ist. Wir führen interaktives Lernen direkt in einer Online-Umgebung durch, was ein Beispiel für die Verbindung von technischem Design und Algorithmendesign ist. Nach der Einführung von SORL wurde das Problem der starken Abhängigkeit des Reinforcement Learning von der Simulationsplattform weitgehend gelöst.
Zu den weiteren technischen Merkmalen gehört der Teil der technischen Infrastruktur, einschließlich des Schulungsrahmens des Smart-Bidding-Modells, des integrierten Fluss- und Chargenkontrollsystems und der grafischen Online-Engine für die Mehrkanalbereitstellung. Das Engineering-System und der Algorithmus sind gleichermaßen wichtig: Je näher und Echtzeit es am Handelszentrum ist, desto besser kann es sein. Je fortschrittlicher die Engineering-Infrastruktur ist, desto besser kann sie Werbetreibenden helfen Ergebnisse.
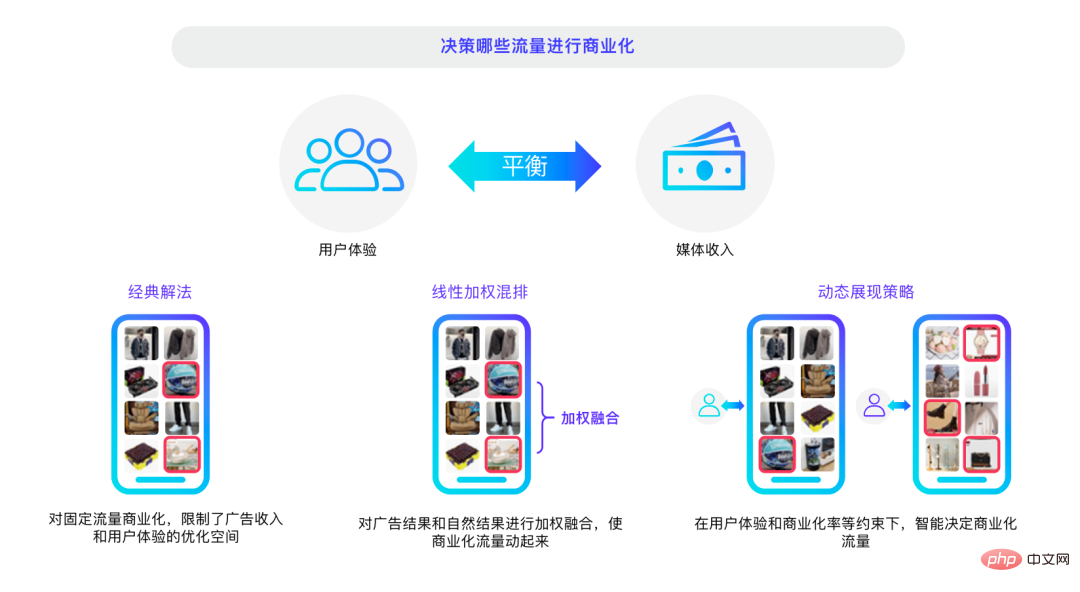
Intelligente Kommerzialisierungsstrategie.
Lassen Sie uns abschließend über die intelligente Kommerzialisierungsstrategie im Zusammenhang mit Medien sprechen. Im Hinblick auf die Optimierung der Kommerzialisierungsstrategie bestand der erste Versuch darin, Werbeergebnisse und natürliche Ergebnisse gewichtet zu integrieren, sie dann zu mischen und je nach Situation auszuwählen. Unangemessene Kommerzialisierungsmechanismen sind sehr schädlich für die Benutzererfahrung, und jeder beginnt, dieses Problem zu erkennen. In den letzten ein bis zwei Jahren sind dynamische Anzeigestrategien nach und nach populär geworden. Mit der Entwicklung von Deep Learning und anderen Technologien können wir durch die Optimierung von Entscheidungsalgorithmen ein Gleichgewicht zwischen Benutzererfahrung und kommerziellem Umsatz herstellen und das Benutzererlebnis mit dem globalen Datenverkehr in Einklang bringen.
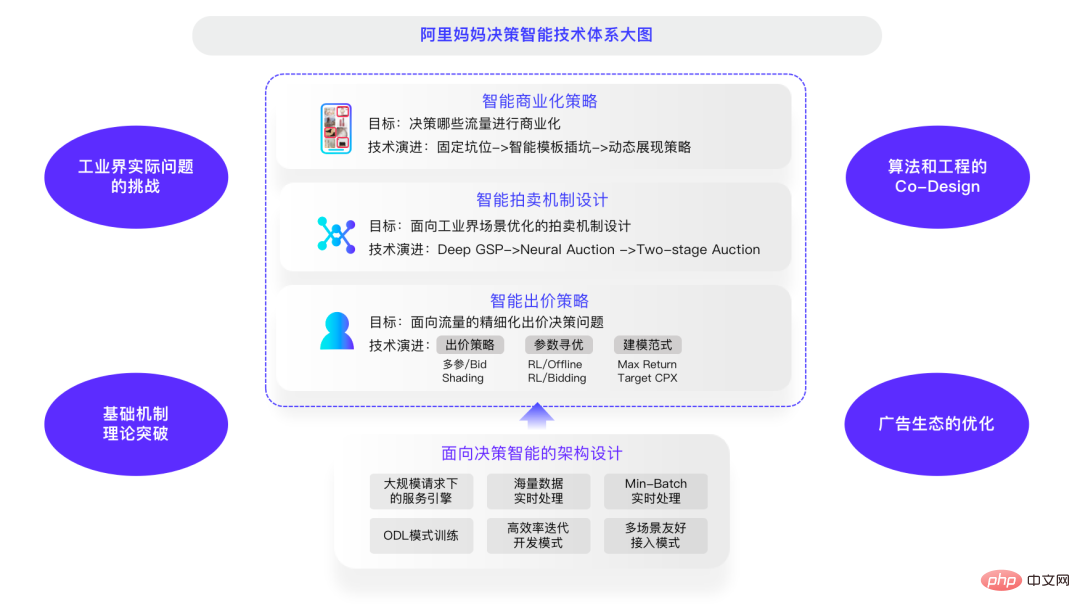
Insgesamt hat Alimama in diesen drei Hauptaspekten ein intelligentes Systemdiagramm zur Entscheidungsfindung erstellt, das in drei Ebenen unterteilt ist. Der intelligente Auktionsmechanismus ist die Brücke in der Mitte und die von ihm gelösten Probleme Intelligente Kommerzialisierungsstrategien sind die effizienteste Art von Ressourcenauktion, bei der Benutzererfahrung und kommerzielle Einnahmen am besten in Einklang gebracht werden können Lernparameter basierend auf der realen Umgebung oder Optimierung mithilfe von Modellierungsparadigmen wie Target CPX und Max Return.
Angesichts der aktuellen Mehrrunden-Auktionen und Hochfrequenzauktionen müssen viele grundlegende Theorien weiter durchbrochen werden. Wenn es um theoretische Durchbrüche bei grundlegenden Mechanismen geht, ist Lehrer Deng ein Experte auf diesem Gebiet, und wir freuen uns darauf, mit ihm zusammenzuarbeiten, um Spitzenforschung auf diesem Gebiet durchzuführen. Aus der Sicht der Herausforderungen bei praktischen technischen Problemen erfordert die tatsächliche Umgebung, dass Ergebnisse innerhalb von 200 Millisekunden zurückgegeben werden, sodass ein gewisses Gleichgewicht zwischen Effizienz und Wirkung bestehen muss, nachdem ich lange in der Branche gearbeitet habe.
Die Optimierung der Werbeökologie ist relativ unabhängig. Das ultimative Ziel der Plattform besteht darin, dass die Ökologie gedeiht und sich friedlich entwickelt. Wenn diese gut gemacht werden, kann die Ökologie die Erwartungen erfüllen? Ich glaube nicht, dass es eine direkte Gleichung zwischen den beiden geben könnte. Was die ökologische Optimierung betrifft, müssen noch viele theoretische und praktische Probleme gelöst werden. Ich hoffe, dass Freunde in der Branche sie in Zukunft gemeinsam diskutieren und lösen können.
In den letzten drei Jahren hat Alimama fast 20 Artikel auf internationalen Top-Konferenzen (NeurIPS, ICML, KDD, WWW usw.) zum Thema Entscheidungsintelligenz veröffentlicht und mit vielen Universitäten wie der Peking-Universität in Shanghai zusammengearbeitet Die Jiao-Tong-Universität, die Chinesische Akademie der Wissenschaften und die Zhejiang-Universität haben in Zusammenarbeit mit Forschungseinrichtungen breite Beachtung gefunden und werden von der Industrie und der Wissenschaft weiterverfolgt Industrie.
Im Vergleich zu Deep Learning hat Entscheidungsintelligenz in der Industrie und der Wissenschaft nicht so viel Aufmerksamkeit erhalten, daher möchte ich diese Gelegenheit nutzen, um alle über dieses sehr interessante und vielversprechende Gebiet zu informieren. Das Obige ist Alimamas Denken und Arbeit zum Thema Entscheidungsintelligenz. Ich hoffe, es mit Freunden aus der Industrie und der Wissenschaft zu teilen praktische Anwendungen in der Industrie.
Das obige ist der detaillierte Inhalt vonWie reagiert das Geschäftsfeld Digital Intelligence auf die Herausforderungen der Decision-Making-Intelligence-Technologie? Antworten von drei Experten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr