
Heim >Technologie-Peripheriegeräte >KI >Die Parameter sind halbiert und genauso gut wie CLIP. Der visuelle Transformer realisiert die Vereinheitlichung von Bild und Text ausgehend von Pixeln.
Die Parameter sind halbiert und genauso gut wie CLIP. Der visuelle Transformer realisiert die Vereinheitlichung von Bild und Text ausgehend von Pixeln.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-05 20:43:051631Durchsuche
In den letzten Jahren hat ein groß angelegtes multimodales Training auf Basis von Transformer zu Verbesserungen modernster Technologie in verschiedenen Bereichen geführt, darunter Vision, Sprache und Audio. Insbesondere im Bereich Computer Vision und Bildsprachenverständnis kann ein einzelnes vorab trainiertes großes Modell ein Expertenmodell für eine bestimmte Aufgabe übertreffen.
Große multimodale Modelle verwenden jedoch häufig modalitäts- oder datensatzspezifische Encoder und Decoder und führen entsprechend zu aufwändigen Protokollen. Bei solchen Modellen geht es beispielsweise häufig darum, verschiedene Teile des Modells in unterschiedlichen Phasen anhand ihrer jeweiligen Datensätze zu trainieren, eine datensatzspezifische Vorverarbeitung durchzuführen oder verschiedene Teile auf aufgabenspezifische Weise zu übertragen. Dieses Muster und die aufgabenspezifischen Komponenten können zu zusätzlicher technischer Komplexität und Herausforderungen führen, wenn neue Verluste vor dem Training oder nachgelagerte Aufgaben eingeführt werden.
Daher wird die Entwicklung eines einzigen End-to-End-Modells, das jede Modalität oder Kombination von Modalitäten bewältigen kann, ein wichtiger Schritt in Richtung multimodales Lernen sein. In diesem Artikel konzentrieren sich Forscher von Google Research (Google Brain-Team) in Zürich hauptsächlich auf Bilder und Text.

Papieradresse: https://arxiv.org/pdf/2212.08045.pdf
Viele wichtige Vereinheitlichungen beschleunigen den Prozess des multimodalen Lernens. Erstens wurde nachgewiesen, dass die Transformer-Architektur als allgemeines Rückgrat dienen und in den Bereichen Text, Bild, Audio und anderen Bereichen gute Leistungen erbringen kann. Zweitens untersuchen viele Arbeiten die Zuordnung verschiedener Modalitäten in einem einzigen gemeinsamen Einbettungsraum, um Eingabe-/Ausgabeschnittstellen zu vereinfachen oder eine einzelne Schnittstelle für mehrere Aufgaben zu entwickeln. Drittens ermöglichen alternative Darstellungen von Modalitäten die Nutzung neuronaler Architekturen oder Trainingsverfahren, die in einem anderen Bereich entwickelt wurden, in einem Bereich. Beispielsweise stellen [54] und [26,48] Text bzw. Audio dar, die verarbeitet werden, indem diese Formen als Bilder (Spektrogramme im Fall von Audio) gerendert werden.
In diesem Artikel wird das multimodale Lernen von Text und Bildern mithilfe rein pixelbasierter Modelle untersucht. Das Modell ist ein separater visueller Transformer, der visuelle Eingaben oder Text oder beides zusammen verarbeitet und alles als RGB-Bilder gerendert. Alle Modalitäten verwenden die gleichen Modellparameter, einschließlich der Low-Level-Feature-Verarbeitung; das heißt, es gibt keine modalitätsspezifischen anfänglichen Faltungen, Tokenisierungsalgorithmen oder Eingabeeinbettungstabellen. Das Modell wird mit nur einer Aufgabe trainiert: kontrastivem Lernen, wie es von CLIP und ALIGN populär gemacht wird. Daher heißt das Modell CLIP-Pixels Only (CLIPPO).
Bei den Hauptaufgaben, für die CLIP zur Bildklassifizierung und Text-/Bildabfrage entwickelt wurde, verhält sich CLIPPO ebenfalls ähnlich wie CLIP (innerhalb von 1–2 % Ähnlichkeit), obwohl es keine spezifische Turmmodalität hat. Überraschenderweise kann CLIPPO komplexe Sprachverständnisaufgaben durchführen, ohne dass eine Sprachmodellierung von links nach rechts, eine maskierte Sprachmodellierung oder explizite Verluste auf Wortebene erforderlich sind. Vor allem beim GLUE-Benchmark übertrifft CLIPPO klassische NLP-Baselines wie ELMO+BiLSTM+Attention. Darüber hinaus übertrifft CLIPPO auch pixelbasierte Maskensprachenmodelle und nähert sich dem Ergebnis von BERT.
Interessanterweise erzielt CLIPPO auch bei VQA eine gute Leistung, wenn Bilder und Text einfach zusammen gerendert werden, obwohl es noch nie mit solchen Daten vorab trainiert wurde. Ein unmittelbarer Vorteil pixelbasierter Modelle im Vergleich zu herkömmlichen Sprachmodellen besteht darin, dass kein vorgegebenes Vokabular erforderlich ist. Dadurch wird die Leistung des mehrsprachigen Abrufs im Vergleich zu gleichwertigen Modellen mit klassischen Tokenizern verbessert. Abschließend stellte die Studie auch fest, dass in einigen Fällen die zuvor beobachteten Modal Gaps durch das Training von CLIPPO reduziert wurden.
Methodenübersicht
CLIP hat sich zu einem leistungsstarken und skalierbaren Paradigma für das Training vielseitiger Visionsmodelle auf Datensätzen entwickelt. Konkret basiert dieser Ansatz auf Bild/Alt-Text-Paaren, die automatisch in großem Maßstab aus dem Web erfasst werden können. Daher sind Textbeschreibungen oft verrauscht und können aus einzelnen Schlüsselwörtern, Schlüsselwortsätzen oder potenziell langen Beschreibungen bestehen. Anhand dieser Daten werden zwei Encoder gemeinsam trainiert, nämlich ein Text-Encoder, der Alt-Text einbettet, und ein Bild-Encoder, der das entsprechende Bild in einen gemeinsamen latenten Raum einbettet. Die beiden Encoder werden mithilfe eines Kontrastverlusts trainiert, der dafür sorgt, dass die Einbettungen entsprechender Bilder und Alternativtexte ähnlich sind, sich jedoch von den Einbettungen aller anderen Bilder und Alternativtexte unterscheiden.
Ein solches Encoderpaar kann nach dem Training auf verschiedene Arten verwendet werden: Es kann einen festen Satz visueller Konzepte anhand von Textbeschreibungen klassifizieren (Zero-Shot-Klassifizierung); die Einbettung kann zum Abrufen von Bildern mit Textbeschreibungen verwendet werden und umgekehrt Alternativ kann der visuelle Encoder überwacht auf nachgelagerte Aufgaben übertragen werden, indem eine Feinabstimmung an einem beschrifteten Datensatz vorgenommen oder der Kopf anhand einer eingefrorenen Bild-Encoder-Darstellung trainiert wird. Im Prinzip kann der Text-Encoder als unabhängige Texteinbettung verwendet werden. Es wird jedoch berichtet, dass in einigen Studien Alttexte von geringer Qualität angegeben wurden, was zu einer schwachen Sprachmodellierungsleistung führte der Text-Encoder.
Frühere Arbeiten haben gezeigt, dass Bild- und Text-Encoder mit einem gemeinsamen Transformatormodell (auch als Single-Tower-Modell oder 1T-CLIP bekannt) implementiert werden können, bei dem Bilder mithilfe von Patch-Einbettung und tokenisierter Text mithilfe von Separat eingebettet werden Worteinbettung. Mit Ausnahme modalitätsspezifischer Einbettungen werden alle Modellparameter von den beiden Modalitäten gemeinsam genutzt. Während diese Art der Freigabe typischerweise zu Leistungseinbußen bei Bild-/Bild-zu-Sprache-Aufgaben führt, reduziert sie auch die Anzahl der Modellparameter um die Hälfte.
CLIPPO führt diese Idee noch einen Schritt weiter: Texteingaben werden auf einem leeren Bild gerendert und dann vollständig als Bild verarbeitet, einschließlich der anfänglichen Patch-Einbettung (siehe Abbildung 1). Durch vergleichendes Training mit früheren Arbeiten wird ein einzelnes visuelles Transformatormodell generiert, das Bilder und Text über eine einzige visuelle Schnittstelle verstehen kann und eine Lösung bietet, mit der Bild-, Bildsprache- und reine Sprachverständnisaufgaben gelöst werden können.
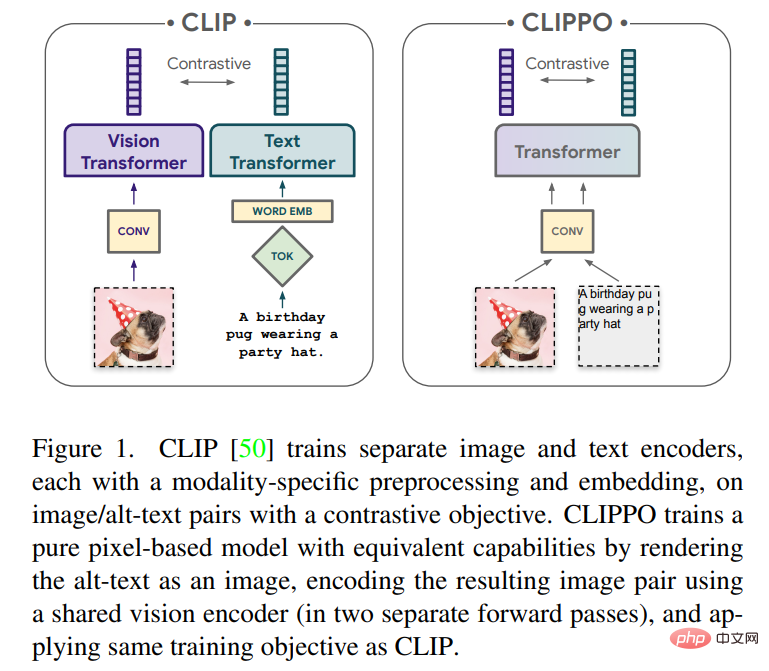
Zusätzlich zur multimodalen Vielseitigkeit lindert CLIPPO häufige Schwierigkeiten bei der Textverarbeitung, nämlich die Entwicklung geeigneter Tokenizer und Vokabulare. Dies ist besonders interessant im Zusammenhang mit umfangreichen mehrsprachigen Umgebungen, in denen Textencoder Dutzende von Sprachen verarbeiten müssen.
Es zeigt sich, dass CLIPPO, das auf Bild/Alt-Text-Paaren trainiert wurde, bei öffentlichen Bild- und Bildsprachen-Benchmarks auf Augenhöhe mit 1T-CLIP abschneidet und beim GLUE-Benchmark mit leistungsstarken Basissprachmodellen konkurriert. Da Alttexte jedoch von geringerer Qualität sind und es sich in der Regel nicht um grammatikalische Sätze handelt, ist das Erlernen des Sprachverständnisses allein aus Alttexten grundsätzlich eingeschränkt. Daher kann ein sprachbasiertes Kontrasttraining zum Bild-/Alttext-Kontrast-Vortraining hinzugefügt werden. Insbesondere müssen aufeinanderfolgende Satzpaare aus einem Textkorpus, übersetzte Satzpaare in verschiedenen Sprachen, nachübersetzte Satzpaare und Satzpaare mit fehlenden Wörtern berücksichtigt werden.
Experimentelle Ergebnisse
Visuelles und visuell-sprachliches Verständnis
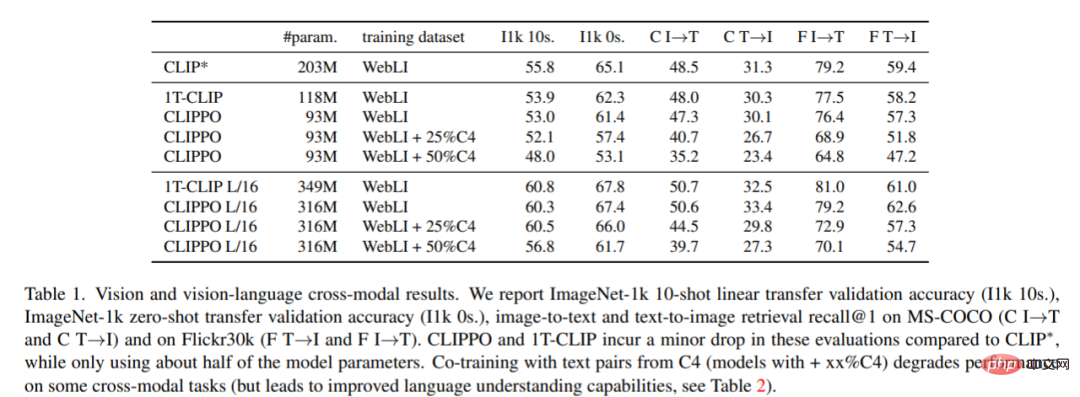
Bildklassifizierung und -abruf. Tabelle 1 zeigt die Leistung von CLIPPO und es ist ersichtlich, dass CLIPPO und 1T-CLIP im Vergleich zu CLIP* einen absoluten Rückgang von 2–3 Prozentpunkten bewirken.
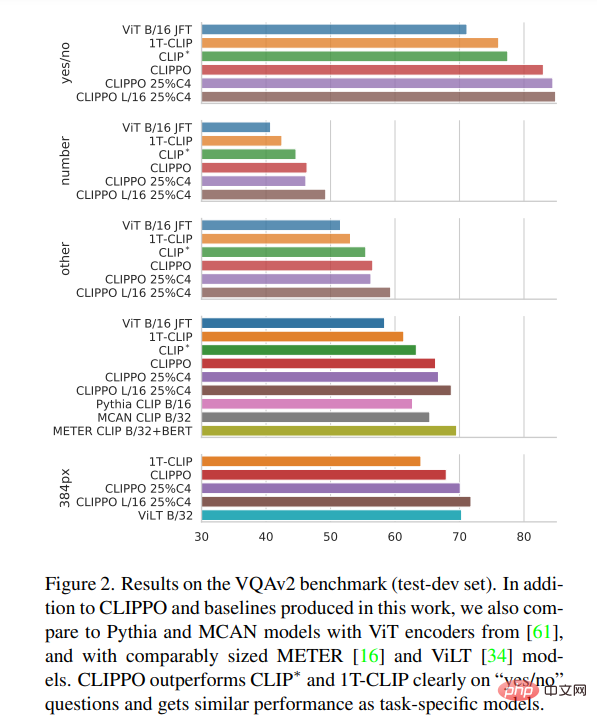
VQA. Die VQAv2-Scores des Modells und der Baseline sind in Abbildung 2 dargestellt. Es ist ersichtlich, dass CLIPPO CLIP∗, 1T-CLIP und ViT-B/16 übertrifft und einen Wert von 66,3 erreicht.
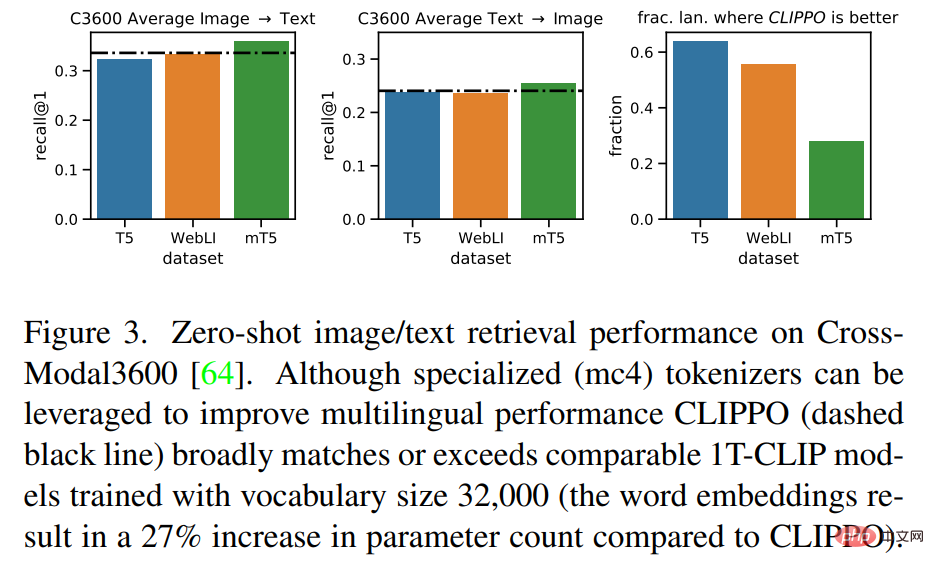
Mehrsprachiges Sehen – Sprachverständnis
Abbildung 3 zeigt, dass CLIPPO eine mit diesen Basislinien vergleichbare Abrufleistung erreicht. Im Fall von mT5 kann die Nutzung zusätzlicher Daten die Leistung verbessern; die Nutzung dieser zusätzlichen Parameter und Daten in einem mehrsprachigen Kontext wird eine interessante zukünftige Richtung für CLIPPO sein.
Sprachverständnis
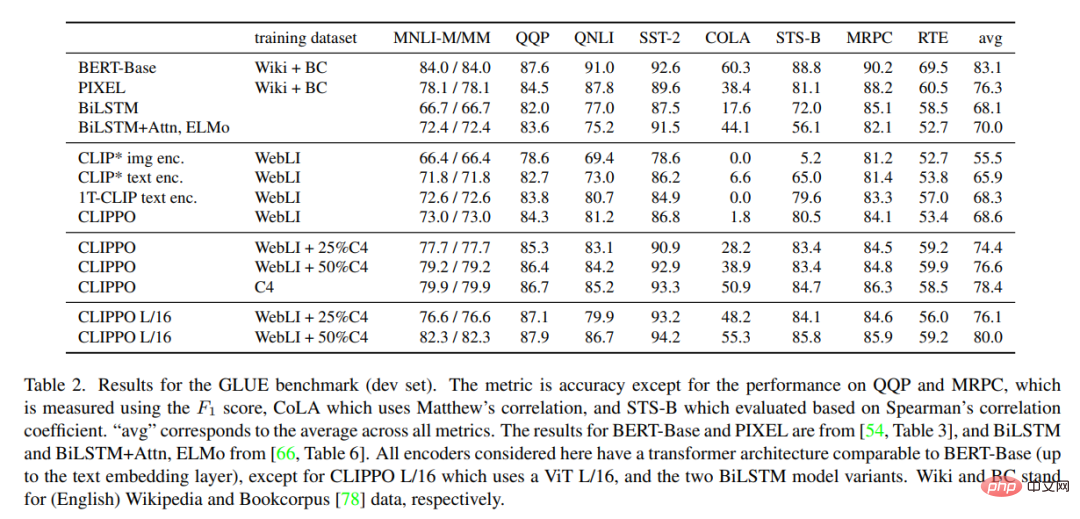
Tabelle 2 zeigt die GLUE-Benchmark-Ergebnisse für CLIPPO und die Basislinie. Es ist zu beobachten, dass CLIPPO, das auf WebLI trainiert wurde, mit der BiLSTM+Attn+ELMo-Basislinie konkurriert, die über tiefe Worteinbettungen verfügt, die auf einem großen Sprachkorpus trainiert wurden. Darüber hinaus können wir sehen, dass CLIPPO und 1T-CLIP Sprachkodierer übertreffen, die mit standardmäßigem kontrastivem Sprachsehen vor dem Training trainiert wurden.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonDie Parameter sind halbiert und genauso gut wie CLIP. Der visuelle Transformer realisiert die Vereinheitlichung von Bild und Text ausgehend von Pixeln.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr