
Heim >Technologie-Peripheriegeräte >KI >Eine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig
Eine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig

- 王林nach vorne
- 2023-05-05 14:55:061046Durchsuche
Einfach eine Textzeile eingeben, um eine dynamische 3D-Szene zu generieren?
Ja, einige Forscher haben es bereits getan. Es ist ersichtlich, dass der aktuelle Generationseffekt noch in den Kinderschuhen steckt und nur einige einfache Objekte generieren kann. Diese „einstufige“ Methode erregte jedoch immer noch die Aufmerksamkeit einer großen Anzahl von Forschern: 🎜# In einem aktuellen Artikel schlugen Forscher von Meta erstmals MAV3D (Make-A-Video3D) vor, eine Methode, die aus Textbeschreibungen dreidimensionale dynamische Szenen generieren kann.

Papierlink: https:/ / /arxiv.org/abs/2301.11280

- Projektlink: https://make-a-video3d.github.io/ # 🎜🎜# Konkret nutzt diese Methode 4D Dynamic Neural Radiation Field (NeRF), um text-to-video (T2V) diffusionsbasiert abzufragen Modell zur Optimierung der Konsistenz von Szenenerscheinung, Dichte und Bewegung. Die durch den bereitgestellten Text erzeugte dynamische Videoausgabe kann aus jedem Kamerawinkel oder Winkel betrachtet und in jede 3D-Umgebung synthetisiert werden.
- MAV3D benötigt keine 3D- oder 4D-Daten, das T2V-Modell wird nur auf Text-Bild-Paare und unbeschriftete Videos trainiert. Werfen wir einen Blick auf die Wirkung der Generierung dynamischer 4D-Szenen aus Text durch MAV3D: 🎜🎜#
Darüber hinaus kann auch direkt vom Bild in 4D gewechselt werden, der Effekt ist wie folgt:
#🎜 Die Forscher haben die Wirksamkeit der Methode durch umfassende quantitative und qualitative Experimente nachgewiesen und auch die zuvor ermittelte interne Basislinie wurde verbessert. Es wird berichtet, dass dies die erste Methode ist, dynamische 3D-Szenen basierend auf Textbeschreibungen zu generieren.
 Methode
Methode
Das Ziel dieser Forschung ist die Entwicklung einer Methode, die dynamische 3D-Szenendarstellungen aus Beschreibungen in natürlicher Sprache generieren kann. Dies ist äußerst anspruchsvoll, da weder Text- oder 3D-Paare noch dynamische 3D-Szenendaten für das Training vorhanden sind. Aus diesem Grund haben wir uns entschieden, uns auf ein vorab trainiertes Text-zu-Video-Diffusionsmodell (T2V) als Szene zu verlassen, das gelernt hat, das realistische Erscheinungsbild und die Bewegung der Szene durch Training an großformatigen Bildern, Texten usw. zu modellieren Videodaten.
Auf einer höheren Ebene kann die Studie bei gegebener Textaufforderung p eine 4D-Darstellung anpassen, die das Erscheinungsbild der mit der Aufforderung übereinstimmenden Szene zu jedem Zeitpunkt in Raum und Zeit simuliert. Ohne gepaarte Trainingsdaten kann die Studie die Ausgabe von 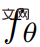 nicht direkt überwachen; bei gegebener Sequenz von Kamerapositionen
nicht direkt überwachen; bei gegebener Sequenz von Kamerapositionen 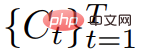 ist es jedoch möglich, daraus zu rendern
ist es jedoch möglich, daraus zu rendern 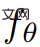 Nehmen Sie eine Bildfolge auf
Nehmen Sie eine Bildfolge auf 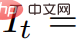
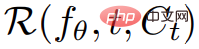 und stapeln Sie sie zu einem Video V. Der Text-Prompt p und das Video V werden dann an das eingefrorene und vorab trainierte T2V-Diffusionsmodell übergeben, das die Authentizität und Prompt-Ausrichtung des Videos bewertet und mithilfe von SDS (Score Distillation Sampling) die Aktualisierungsrichtung des Szenenparameters θ berechnet.
und stapeln Sie sie zu einem Video V. Der Text-Prompt p und das Video V werden dann an das eingefrorene und vorab trainierte T2V-Diffusionsmodell übergeben, das die Authentizität und Prompt-Ausrichtung des Videos bewertet und mithilfe von SDS (Score Distillation Sampling) die Aktualisierungsrichtung des Szenenparameters θ berechnet.
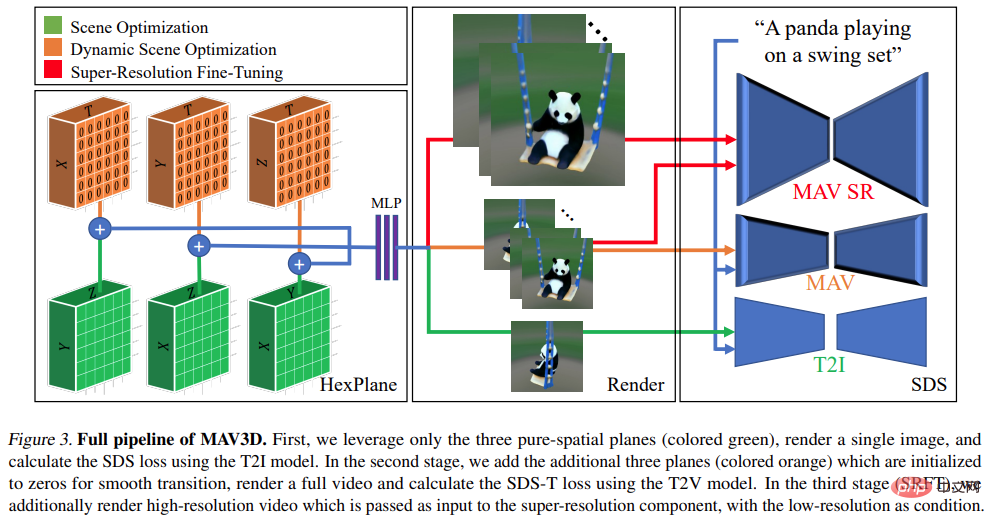
Die obige Pipeline kann als Erweiterung von DreamFusion gezählt werden, indem sie dem Szenenmodell eine zeitliche Dimension hinzufügt und zur Überwachung ein T2V-Modell anstelle eines Text-to-Image (T2I)-Modells verwendet. Um eine qualitativ hochwertige Text-zu-4D-Generierung zu erreichen, sind jedoch weitere Innovationen erforderlich:
- Erstens sind neue 4D-Darstellungen erforderlich, die eine flexible Szenenbewegungsmodellierung ermöglichen.
- Zweitens: Ein mehrstufiges statisches bis dynamisches Optimierungsschema wird benötigt, um die Videoqualität zu verbessern und die Modellkonvergenz zu verbessern.
- Drittens muss Super-Resolution Fine-Tuning (SRFT) verwendet werden, um die Modellauflösung zu verbessern.
Spezifische Anweisungen finden Sie in der Abbildung unten:
Experiment
In dem Experiment bewerteten die Forscher die Fähigkeit von MAV3D, dynamische Szenen aus Textbeschreibungen zu generieren. Zunächst bewerteten die Forscher die Wirksamkeit der Methode bei der Text-To-4D-Aufgabe. Es wird berichtet, dass MAV3D die erste Lösung für diese Aufgabe ist, daher wurden im Rahmen der Forschung drei alternative Methoden als Basis entwickelt. Zweitens evaluieren wir vereinfachte Versionen der T2V- und Text-To-3D-Teilaufgabenmodelle und vergleichen sie mit bestehenden Basislinien in der Literatur. Drittens rechtfertigen umfassende Ablationsstudien das Methodendesign. Viertens beschreiben Experimente den Prozess der Konvertierung von dynamischem NeRF in dynamische Netze, wodurch das Modell letztendlich auf Bild-zu-4D-Aufgaben erweitert wird.
Metriken
Die Studie wertet die generierten Videos mit CLIP R-Precision aus, das die Konsistenz zwischen Text und generierten Szenen misst. Die gemeldete Metrik ist die Genauigkeit des Abrufens der Eingabeaufforderung aus dem gerenderten Frame. Wir haben die ViT-B/32-Variante von CLIP verwendet und Frames in verschiedenen Ansichten und Zeitschritten extrahiert und außerdem vier qualitative Metriken verwendet, indem wir menschliche Bewerter nach ihren Präferenzen für zwei generierte Videos gefragt haben: (i) Videoqualität ( ii) Treue zu Textaufforderungen; (iii) Ausmaß der Aktivität; (iv) Realismus der Bewegung. Wir haben alle bei der Textaufforderungssegmentierung verwendeten Basislinien und Ablationen ausgewertet.
Abbildung 1 und 2 sind Beispiele. Detailliertere Visualisierungen finden Sie unter make-a-video3d.github.io.

Ergebnis# 🎜🎜#
Tabelle 1 zeigt den Vergleich mit der Basislinie (R – Genauigkeit und menschliche Präferenz). Menschliche Bewertungen werden als Prozentsatz der Stimmen dargestellt, die die Basismehrheit im Vergleich zum Modell in einer bestimmten Umgebung befürworten.
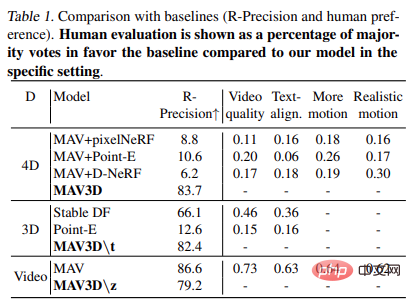
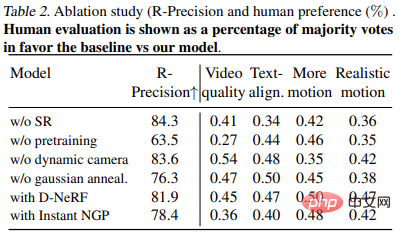
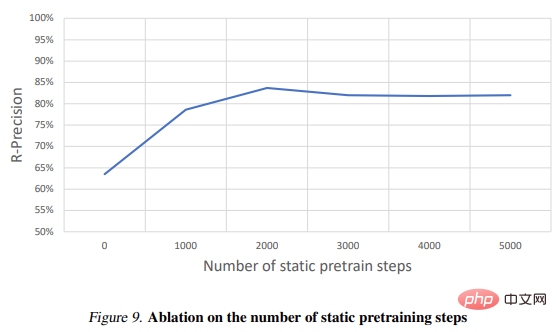
Tabelle 2 zeigt die Ergebnisse des Ablationsexperiments: # 🎜🎜#
Echtzeit-Rendering#🎜 🎜## 🎜🎜# Anwendungen wie Virtual Reality und Spiele, die herkömmliche Grafik-Engines verwenden, erfordern Standardformate wie Texturnetze. HexPlane-Modelle können wie unten gezeigt einfach in animierte Netze umgewandelt werden. Zunächst wird mithilfe des Marching-Cube-Algorithmus ein einfaches Netz aus dem zu jedem Zeitpunkt t erzeugten Opazitätsfeld extrahiert, gefolgt von der Netzextraktion (aus Effizienzgründen) und der Entfernung kleiner, verrauschter verbundener Komponenten. Der XATLAS-Algorithmus wird verwendet, um Netzscheitelpunkte einem Texturatlas zuzuordnen, wobei die Textur mithilfe der HexPlane-Farbe initialisiert wird, die in einer kleinen Kugel gemittelt wird, die an jedem Scheitelpunkt zentriert ist. Abschließend werden die Texturen weiter optimiert, um besser zu einigen Beispielframes zu passen, die von HexPlane mithilfe differenzierbarer Netze gerendert wurden. Dadurch wird eine Sammlung von Texturnetzen erstellt, die in jeder handelsüblichen 3D-Engine wiedergegeben werden können.
Bild zu 4D
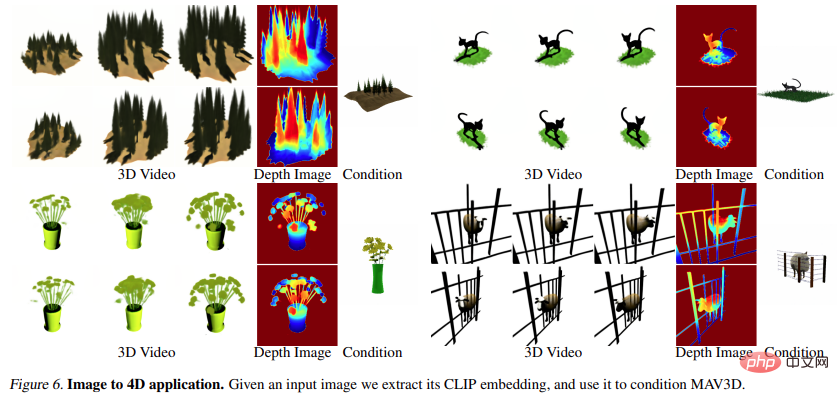
Abbildung 6 und Abbildung 10 zeigen dies Die Methode ist in der Lage, aus einem gegebenen Eingabebild Tiefe und Bewegung zu erzeugen und so 4D-Assets zu generieren.
# 🎜 🎜#


Weitere Forschungsdetails finden Sie im Original Papier.

Das obige ist der detaillierte Inhalt vonEine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr