
Heim >Technologie-Peripheriegeräte >KI >UC Berkeley veröffentlicht Ranking großer Sprachmodelle! Vicuna gewann die Meisterschaft und Tsinghua ChatGLM landete unter den Top 5
UC Berkeley veröffentlicht Ranking großer Sprachmodelle! Vicuna gewann die Meisterschaft und Tsinghua ChatGLM landete unter den Top 5

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-04 23:04:091620Durchsuche
Kürzlich haben Forscher von LMSYS Org (unter der Leitung der UC Berkeley) eine weitere große Neuigkeit gemacht – den großen Wettbewerb zur Rangliste der Sprachmodellversionen!
Wie der Name schon sagt, besteht das „LLM-Ranking“ darin, eine Gruppe großer Sprachmodelle nach dem Zufallsprinzip Schlachten durchführen zu lassen und diese anhand ihrer Elo-Werte einzustufen.
Dann können wir auf einen Blick erkennen, ob ein bestimmter Chatbot der „König des stärksten Mundes“ oder der „Stärkste König“ ist.
Kernpunkt: Das Team plant auch, all diese „Closed-Source“-Modelle aus dem In- und Ausland einzubeziehen. Sie werden wissen, ob es sich um Maultiere oder Pferde handelt! (GPT-3.5 befindet sich jetzt im anonymen Bereich)

Der anonyme Chatbot-Bereich sieht folgendermaßen aus:
Offensichtlich hat Modell B richtig geantwortet und das Spiel gewonnen; Verstehe die Frage...
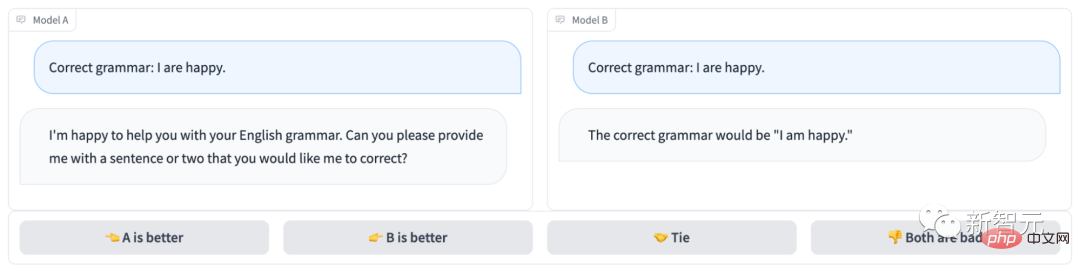
Projektadresse: https://arena.lmsys.org/
In der aktuellen Rangliste belegt Vicuna mit 13 Milliarden Parametern den ersten Platz mit 1169 Punkten Koala, das ebenfalls über 13 Milliarden Parameter verfügt, belegte den zweiten Platz und LAIONs Open Assistant den dritten Platz.
ChatGLM, vorgeschlagen von der Tsinghua-Universität, obwohl es nur 6 Milliarden Parameter hat, schaffte es es dennoch in die Top 5, nur 23 Punkte hinter Alpaca mit 13 Milliarden Parametern.
Im Vergleich dazu belegte Metas ursprüngliches LLaMa nur den achten (vorletzten) Platz, während StableLM von Stability AI nur 800+ Punkte erhielt und damit den vorletzten Platz belegte.
Das Team gab an, dass es nicht nur die Rangliste regelmäßig aktualisieren, sondern auch den Algorithmus und den Mechanismus optimieren und detailliertere Ranglisten basierend auf verschiedenen Aufgabentypen bereitstellen wird.

Derzeit sind alle Auswertungscodes und Datenanalysen veröffentlicht.
LLM in die Rangliste ziehen
In dieser Bewertung hat das Team 9 bekannte Open-Source-Chatbots ausgewählt.
Jedes Mal, wenn es einen 1v1-Kampf gibt, wählt das System zufällig zwei PK-Spieler aus. Benutzer müssen mit beiden Robotern gleichzeitig chatten und dann entscheiden, welcher Chatbot besser ist.
Sie können sehen, dass es unten auf der Seite 4 Optionen gibt: die linke (A) ist besser, die rechte (B) ist besser, gleich gut oder beide sind schlecht.
Nachdem der Benutzer eine Stimme abgegeben hat, zeigt das System den Namen des Modells an. Zu diesem Zeitpunkt kann der Benutzer mit dem Chatten fortfahren oder ein neues Modell auswählen, um eine Kampfrunde neu zu starten.
Bei der Analyse verwendet das Team die Abstimmungsergebnisse jedoch nur, wenn das Modell anonym ist. Nach fast einer Woche Datenerfassung sammelte das Team insgesamt 4,7.000 gültige anonyme Stimmen.
Bevor es losging, erfasste das Team zunächst anhand der Ergebnisse des Benchmark-Tests die mögliche Platzierung jedes Modells.
Basierend auf dieser Rangliste lässt das Team das Modell die Auswahl geeigneterer Gegner priorisieren.
Erzielen Sie dann durch einheitliche Stichproben eine bessere Gesamtabdeckung der Rankings.
Am Ende des Qualifyings stellte das Team ein neues Modell fastchat-t5-3b vor.
Die oben genannten Operationen führen schließlich zu ungleichmäßigen Modellfrequenzen.
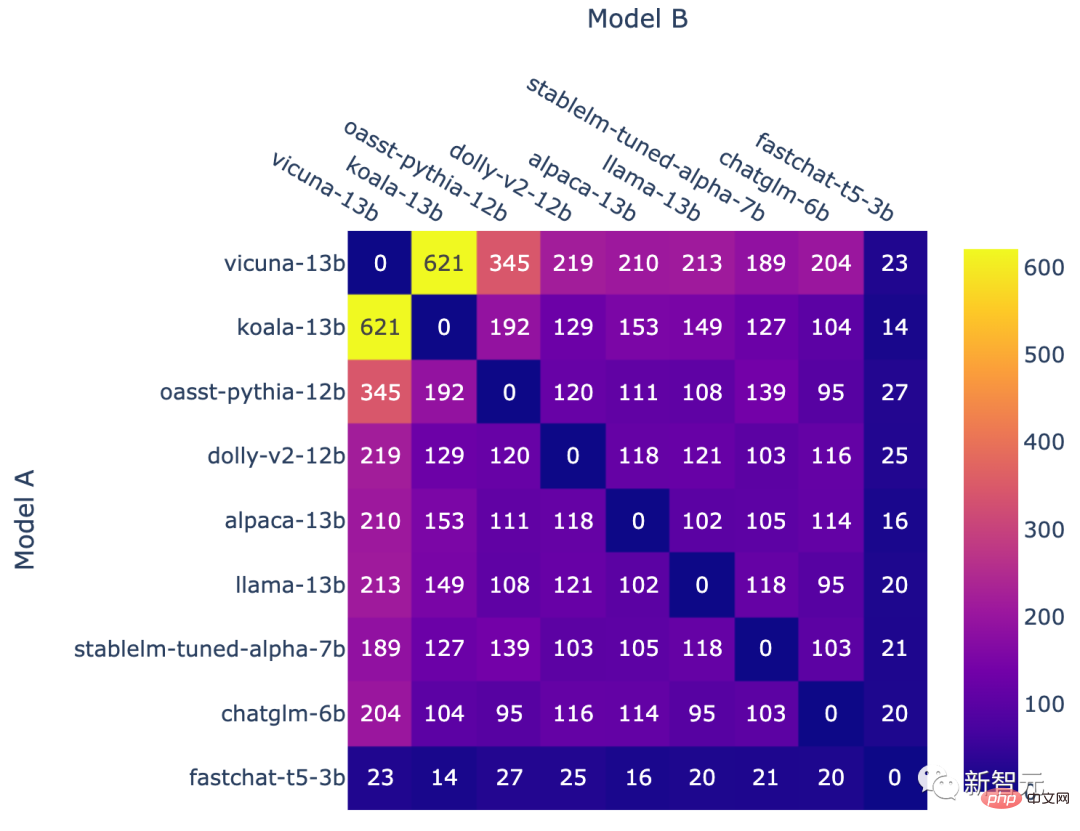
Die Anzahl der Schlachten für jede Modellkombination
Aus den statistischen Daten geht hervor, dass die meisten Benutzer Englisch verwenden, wobei Chinesisch an zweiter Stelle steht.
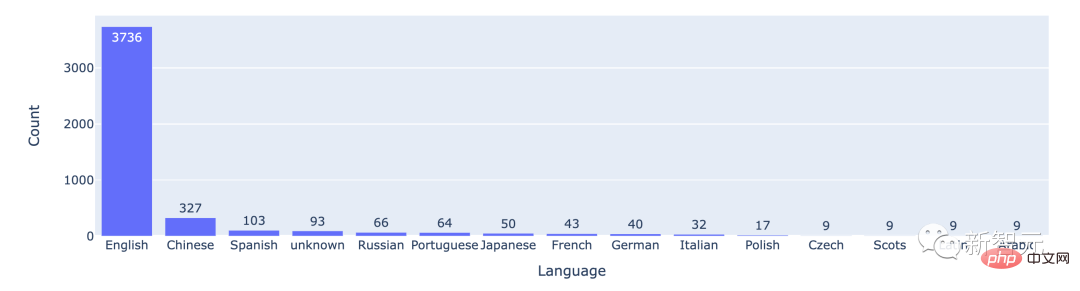
Die Anzahl der Kämpfe zwischen den Top-15-Sprachen
LLM zu bewerten ist wirklich schwierig
Seit ChatGPT populär geworden ist, wurden große Open-Source-Sprachmodelle gemäß den Anweisungen verfeinert sind nach dem Regen wie Pilze aus dem Boden geschossen. Man kann sagen, dass fast jede Woche neue Open-Source-LLMs veröffentlicht werden.
Aber das Problem ist, dass es sehr schwierig ist, diese großen Sprachmodelle zu bewerten.
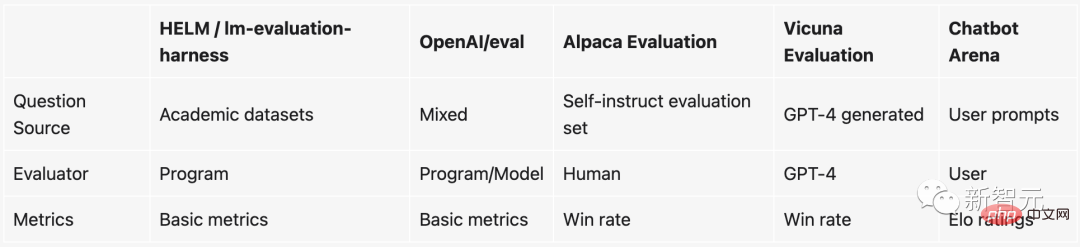
Um genau zu sein: Die Dinge, die derzeit zur Messung der Qualität eines Modells verwendet werden, basieren im Wesentlichen auf einigen akademischen Benchmarks, wie zum Beispiel dem Erstellen eines Testdatensatzes für eine bestimmte NLP-Aufgabe und der anschließenden Prüfung der Genauigkeit der Testdaten Satz. .
Allerdings sind diese akademischen Benchmarks (wie HELM) bei großen Modellen und Chatbots nicht einfach anzuwenden. Die Gründe sind:
1. Da die Beurteilung, ob ein Chatbot gut ist oder nicht, sehr subjektiv ist, ist es schwierig, dies mit bestehenden Methoden zu messen.
2. Diese großen Modelle scannen während des Trainings fast alle Daten im Internet, daher ist es schwierig sicherzustellen, dass der Testdatensatz nicht gesehen wurde. Geht man noch einen Schritt weiter, führt die Verwendung des Testsatzes zum direkten „speziellen Trainieren“ des Modells zu einer besseren Leistung.
3. Theoretisch können wir mit Chatbots über alles chatten, aber viele Themen oder Aufgaben sind in bestehenden Benchmarks einfach nicht vorhanden.
Wenn Sie diese Benchmarks nicht verwenden möchten, gibt es tatsächlich einen anderen Weg: Bezahlen Sie jemanden, der das Modell bewertet.
Tatsächlich ist es das, was OpenAI tut. Aber diese Methode ist offensichtlich sehr langsam und, was noch wichtiger ist, zu teuer...
Um dieses heikle Problem zu lösen, haben Teams von UC Berkeley, UCSD und CMU einen neuen Mechanismus erfunden, der sowohl Spaß macht als auch praktisch ist— — Chatbot-Arena.
Im Vergleich dazu bietet das kampfbasierte Benchmark-System folgende Vorteile:
- Skalierbarkeit
Wenn nicht für alle potenziellen Modellpaare genügend Daten gesammelt werden können, sollte das System auf beliebig viele erweitert werden Modelle wie möglich.
- Inkrementalität
Das System sollte in der Lage sein, neue Modelle anhand einer relativ geringen Anzahl von Versuchen zu bewerten.
- Eindeutige Reihenfolge
Das System sollte eine eindeutige Reihenfolge für alle Modelle bereitstellen. Wenn wir zwei beliebige Modelle haben, sollten wir in der Lage sein zu sagen, welches Modell höher rangiert oder ob sie gleichauf sind.
Elo-Bewertungssystem
Das Elo-Bewertungssystem ist eine Methode zur Berechnung des relativen Fähigkeitsniveaus von Spielern und wird häufig in Wettkampfspielen und verschiedenen Sportarten eingesetzt. Dabei gilt: Je höher der Elo-Score, desto stärker ist der Spieler.
In League of Legends, Dota 2, Chicken Fighting usw. ist dies beispielsweise der Mechanismus, mit dem das System die Spieler einordnet.
Wenn Sie beispielsweise viele Ranglistenspiele in League of Legends spielen, wird ein versteckter Punktestand angezeigt. Dieser versteckte Punktestand bestimmt nicht nur Ihren Rang, sondern bestimmt auch, dass die Gegner, denen Sie beim Ranglistenspiel begegnen, grundsätzlich ein ähnliches Level haben.
Darüber hinaus ist der Wert dieses Elo-Scores absolut. Mit anderen Worten: Wenn in Zukunft neue Chatbots hinzugefügt werden, können wir anhand des Elos-Scores immer noch direkt beurteilen, welcher Chatbot leistungsfähiger ist.
Insbesondere wenn die Wertung von Spieler A Ra und die Wertung von Spieler B Rb ist, lautet die genaue Formel für die Gewinnwahrscheinlichkeit von Spieler A (unter Verwendung einer logistischen Kurve der Basis 10):

Dann die Spielerbewertungen wird nach jedem Spiel linear aktualisiert.
Angenommen, Spieler A (bewertet mit Ra) erwartet Ea-Punkte, hat aber tatsächlich Sa-Punkte erhalten. Die Formel zum Aktualisieren dieser Spielerbewertung lautet:
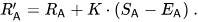
1v1-Gewinnrate
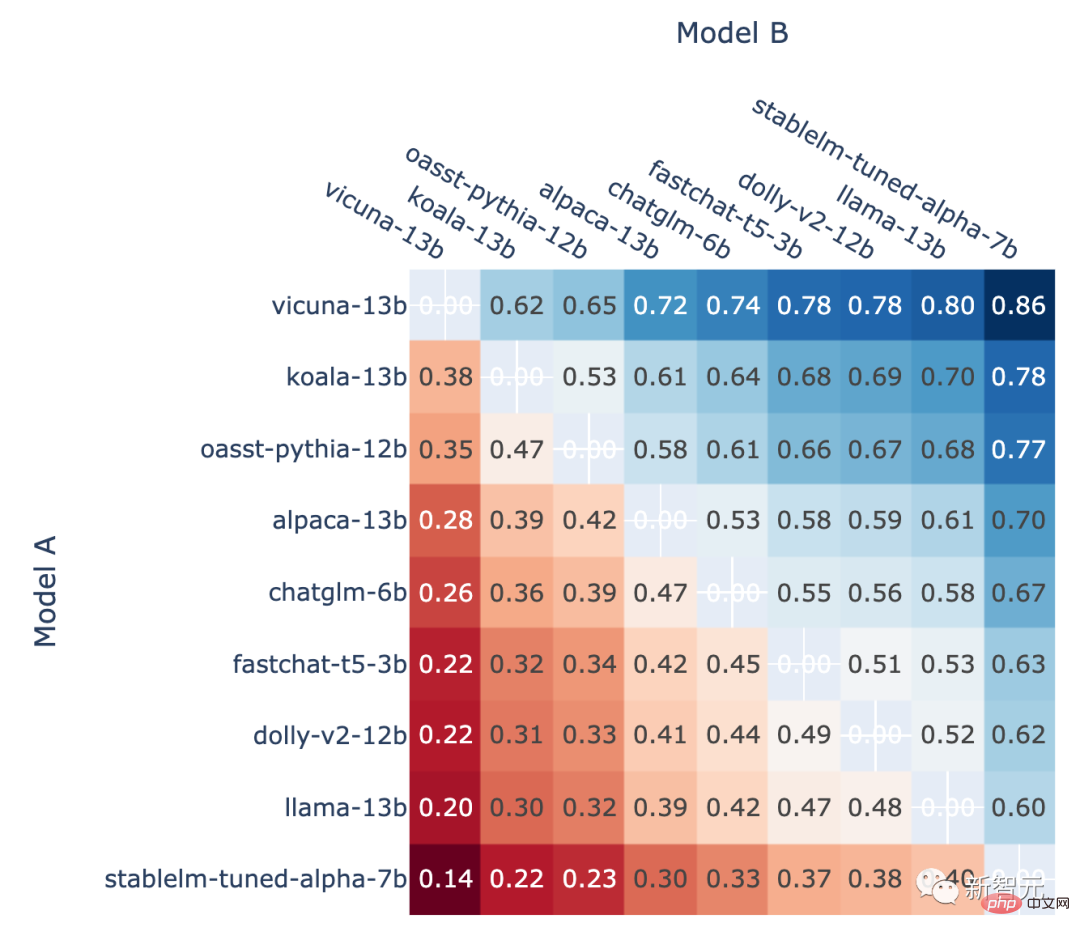
Darüber hinaus zeigt der Autor auch die direkte Siegesrate jedes Modells im Ranglistenspiel und die vorhergesagte Head-to-Head-Gewinnrate an. To-Head-Siegrate, geschätzt anhand der Elo-Bewertung.
Die Ergebnisse zeigen, dass der Elo-Score tatsächlich relativ genau vorhersagen kann
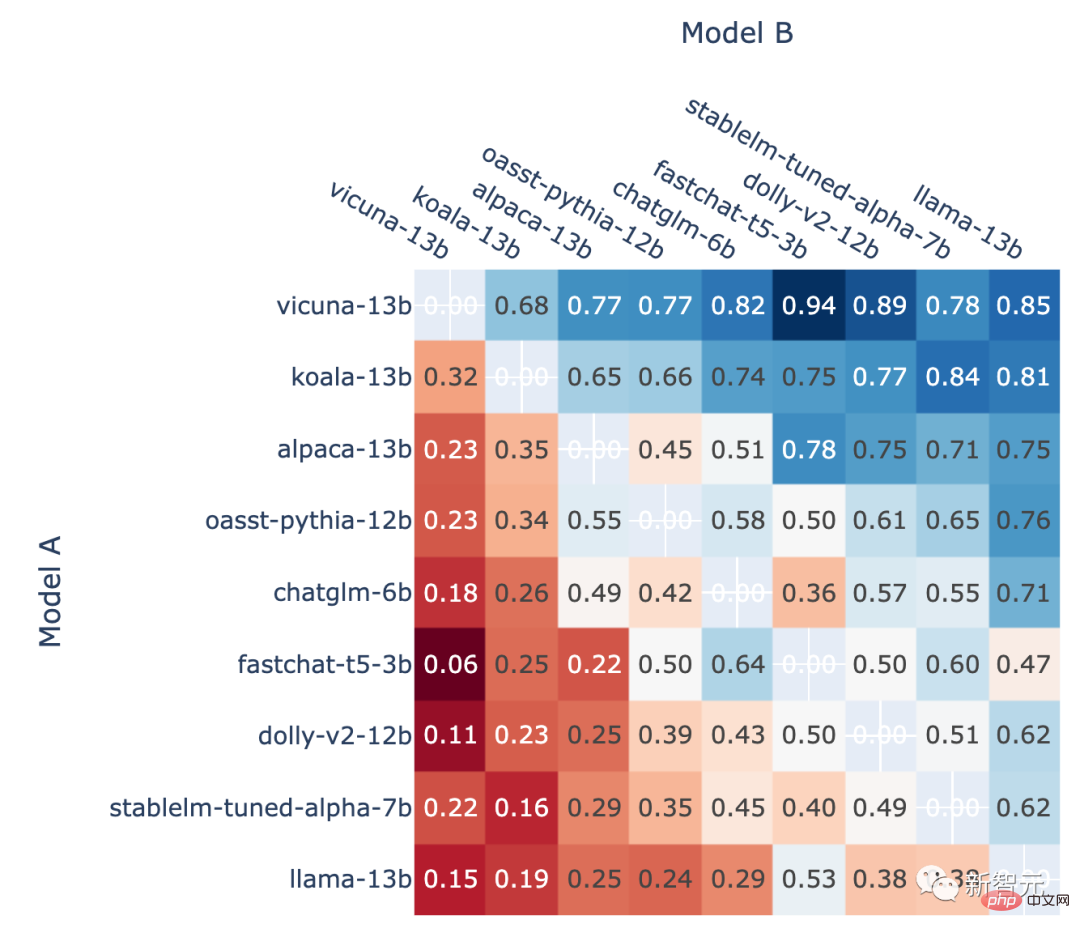
Der Anteil von Modell A, der in allen Nicht-Unentschieden-A-Kämpfen gewinnt, vs. Im Kampf gegen B, die Gewinnquote von Modell A vorhergesagt anhand des Elo-Scores
Einführung in den Autor
Gegründet von UC Berkeley Ph.D. und UCSD-Associate-Professor Hao Zhang, besteht das Ziel darin, durch die gemeinsame Entwicklung offener Datensätze, Modelle, Systeme und Bewertungstools große Modelle für jedermann zugänglich zu machen.
Lianmin Zheng
Lianmin Zheng ist Doktorand in der EECS-Abteilung der University of California, Berkeley. Zu seinen Forschungsinteressen gehören maschinelle Lernsysteme, Compiler und verteilte Systeme.
Hao Zhang ist derzeit Postdoktorand an der University of California, Berkeley. Ab Herbst 2023 wird er als Assistenzprofessor am Halıcıoğlu Data Science Institute und Department of Computer Science der UC San Diego tätig sein.
Das obige ist der detaillierte Inhalt vonUC Berkeley veröffentlicht Ranking großer Sprachmodelle! Vicuna gewann die Meisterschaft und Tsinghua ChatGLM landete unter den Top 5. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr