
Heim >Technologie-Peripheriegeräte >KI >Durch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.
Durch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.

- 王林nach vorne
- 2023-05-04 15:52:061229Durchsuche
Die erste Version dieses Artikels wurde im Mai 2018 verfasst und kürzlich im Dezember 2022 veröffentlicht. Ich habe in den letzten vier Jahren viel Unterstützung und Verständnis von meinen Vorgesetzten erhalten.
(Ich hoffe auch, dass diese Erfahrung den Studenten, die Arbeiten einreichen, etwas Mut macht. Wenn Sie die Arbeit gut schreiben, werden Sie auf jeden Fall gewinnen, geben Sie nicht so schnell auf!)
Die frühe Version von arXiv ist: Abfrageangriff über Funktion in entgegengesetzter Richtung: Auf dem Weg zu einem robusten Bildabruf
 Papier-Backup-Link: https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
Papier-Backup-Link: https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
Code: https://github.com/layumi/U_turn
Autor: Zhedong Zheng, Liang Zheng, Yi Yang und Fei Wu Mehrskaliger Abfrageangriff/Black-Box-Angriff / Verteidigen Sie Experimente aus drei verschiedenen Blickwinkeln.
Fügen Sie neue Methoden und neuere Visualisierungsmethoden für Food256, Market-1501, CUB, Oxford, Paris und andere Datensätze hinzu.
Die PCB-Struktur in Reid und WiderResNet in Cifar10 angegriffen.Tatsächliche Fälle
Im tatsächlichen Gebrauch. Nehmen wir zum Beispiel an, wir wollen das Bildabrufsystem von Google oder Baidu angreifen, um große Schlagzeilen zu machen (Nebel). Wir können ein Bild eines Hundes herunterladen, die Merkmale mithilfe des Imagenet-Modells (oder anderer Modelle, vorzugsweise eines Modells in der Nähe des Retrievalsystems) berechnen und das gegnerische Rauschen plus berechnen, indem wir die Merkmale umdrehen (die Methode in diesem Artikel). Zurück zum Hund. Nutzen Sie dann nach dem Angriff die Bildsuchfunktion für den Hund. Sie sehen, dass das System von Baidu und Google keine hundebezogenen Inhalte zurückgeben kann. Obwohl wir Menschen immer noch erkennen können, dass es sich hier um ein Bild eines Hundes handelt.
- P.S.: Ich habe auch versucht, Google anzugreifen, um nach Bildern zu suchen. Die Leute können immer noch erkennen, dass es sich um ein Bild eines Hundes handelt, aber Google gibt oft „Mosaik“-bezogene Bilder zurück. Ich schätze, dass Google nicht alle Deep-Features verwendet oder sich stark vom Imagenet-Modell unterscheidet. Daher tendiert es nach einem Angriff oft dazu, „Mosaik“ anstelle anderer Entitätskategorien (Flugzeuge und dergleichen) zu verwenden. Natürlich kann Mosaik bis zu einem gewissen Grad als Erfolg gewertet werden!
- Was
- 1. Die ursprüngliche Absicht dieses Artikels ist eigentlich sehr einfach. Das vorhandene Reid-Modell oder Landschaftsabrufmodell hat eine Rückrufrate von mehr als 95 % erreicht. Können wir also einen Angriffsweg entwickeln? Abruf? Modell? Lassen Sie uns einerseits den Hintergrund des REID-Modells untersuchen. Andererseits dient der Angriff der besseren Verteidigung.
- 2. Der Unterschied zwischen dem Abrufmodell und dem herkömmlichen Klassifizierungsmodell besteht darin, dass das Abrufmodell extrahierte Merkmale verwendet, um die Ergebnisse zu vergleichen (Sortierung), was sich deutlich vom herkömmlichen Klassifizierungsmodell unterscheidet, wie in der folgenden Tabelle dargestellt.
- 3. Ein weiteres Merkmal von Retrieval-Problemen ist die offene Menge, was bedeutet, dass die Kategorien beim Testen während des Trainings oft nicht sichtbar sind. Wenn Sie mit dem Jungtierdatensatz vertraut sind, gibt es unter der Abrufeinstellung mehr als 100 Vogelarten im Trainingssatz und mehr als 100 Vogelarten im Testsatz. Diese beiden 100 Arten überschneiden sich nicht Typen. Matching und Ranking basieren ausschließlich auf extrahierten visuellen Merkmalen. Daher eignen sich einige Klassifizierungsangriffsmethoden nicht für Angriffe auf das Abrufmodell, da der auf der Kategorievorhersage basierende Gradient während des Angriffs häufig ungenau ist.
1. Eine natürliche Idee sind Angriffseigenschaften. Wie kann man also Funktionen angreifen? Basierend auf unseren früheren Beobachtungen zum Kreuzentropieverlust (siehe Artikel „Großmargiger Softmax-Verlust“). Wenn wir Klassifizierungsverlust verwenden, weist Merkmal f häufig eine radiale Verteilung auf. Dies liegt daran, dass beim Lernen die Cos-Ähnlichkeit zwischen dem Merkmal und dem Gewicht W der letzten Klassifizierungsschicht berechnet wird. Wie in der folgenden Abbildung gezeigt, werden Stichproben derselben Klasse nach dem Erlernen des Modells in der Nähe von W dieser Klasse verteilt, sodass f*W den Maximalwert erreichen kann. Wie
2 Also haben wir uns eine sehr einfache Methode ausgedacht, nämlich die Funktionen umzudrehen. Wie in der folgenden Abbildung dargestellt, gibt es tatsächlich zwei gängige Klassifizierungsangriffsmethoden, die auch gemeinsam visualisiert werden können. Beispielsweise dient (a) dazu, die Kategorie mit der höchsten Klassifizierungswahrscheinlichkeit (z. B. Fast Gradient) zu unterdrücken, indem -Wmax angegeben wird, sodass es eine Ausbreitungsrichtung des roten Gradienten entlang des inversen Wmax gibt, während es in (b) eine andere gibt Eine Möglichkeit, die am wenigsten wahrscheinliche Kategorie zu unterdrücken, wird nach oben gezogen (z. B. am wenigsten wahrscheinlich), sodass der rote Farbverlauf entlang von Wmin verläuft.
3. Diese beiden Klassifizierungsangriffsmethoden sind bei herkömmlichen Klassifizierungsproblemen natürlich sehr direkt und effektiv. Da es sich bei den Testsätzen im Retrieval-Problem jedoch ausschließlich um unsichtbare Kategorien (unsichtbare Vogelarten) handelt, passt die Verteilung von natürlichem f nicht genau zu Wmax oder Wmin. Daher ist unsere Strategie sehr einfach. Da wir f haben, können wir es einfach Verschieben Sie f nach -f, wie in Abbildung (c) gezeigt.
Auf diese Weise werden in der Feature-Matching-Phase die ursprünglichen hochrangigen Ergebnisse idealerweise am niedrigsten eingestuft, wenn sie als Cos-Ähnlichkeit mit -f berechnet werden, von nahe 1 bis nahe -1.
Wir haben den Effekt unserer Angriffs-Retrieval-Sortierung erreicht.
4. Eine kleine Erweiterung. Bei Abrufproblemen verwenden wir häufig auch Multiskalen zur Abfrageerweiterung. Daher haben wir auch untersucht, wie der Angriffseffekt in diesem Fall aufrechterhalten werden kann. (Die Hauptschwierigkeit besteht darin, dass der Größenänderungsvorgang einige kleine, aber kritische Schwankungen glätten kann.)
Tatsächlich ist unsere Methode, damit umzugehen, ebenfalls sehr einfach. Genau wie beim Modellensemble mitteln wir die kontradiktorischen Gradienten mehrerer Skalen zu einem Ensemble.
Experiment
1. Unter drei Datensätzen und drei Indikatoren haben wir die Jitter-Amplitude, das Epsilon der Abszisse, festgelegt und verglichen, welche Methode dazu führen kann, dass das Abrufmodell bei derselben Jitter-Amplitude mehr Fehler macht. Unsere Methode besteht darin, dass die gelben Linien alle unten liegen, was bedeutet, dass der Angriffseffekt besser ist.
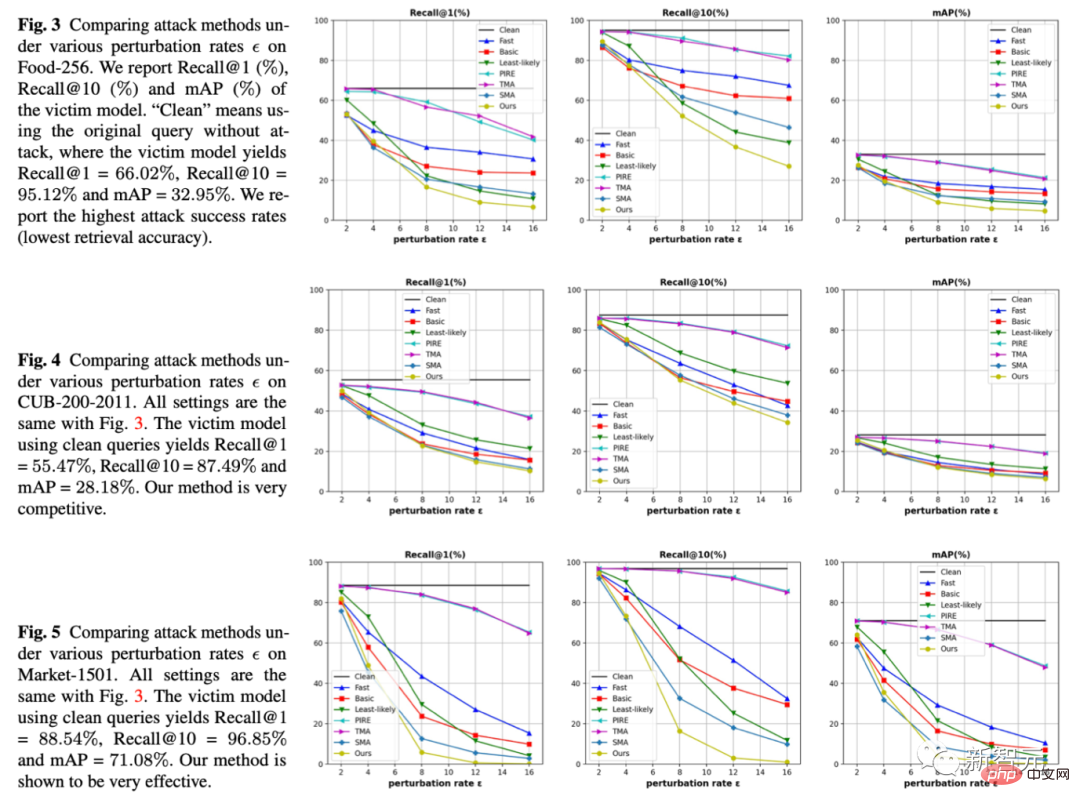
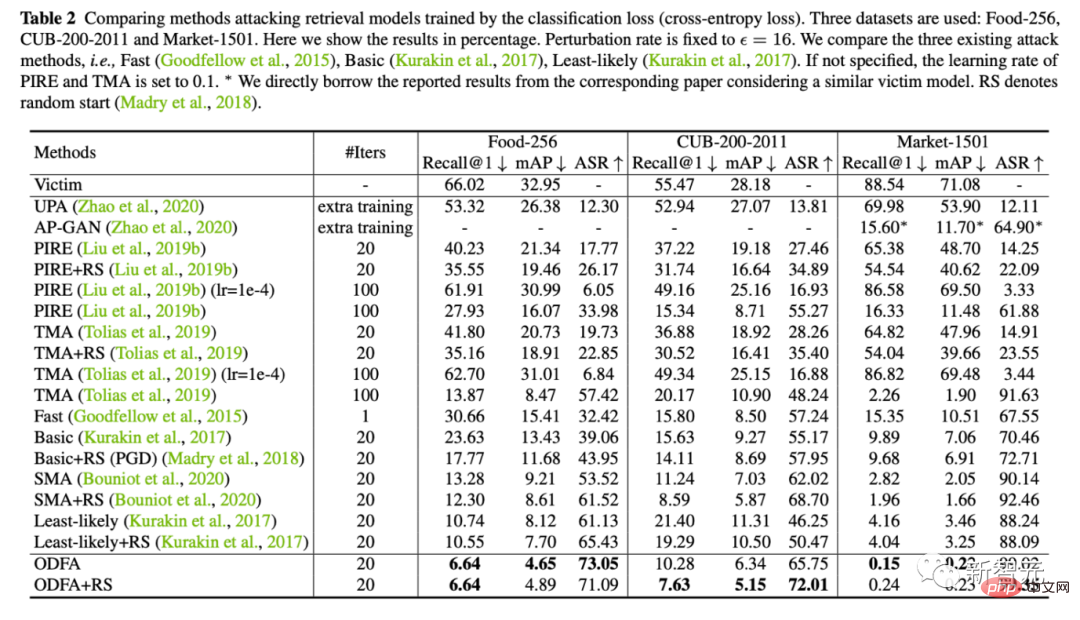
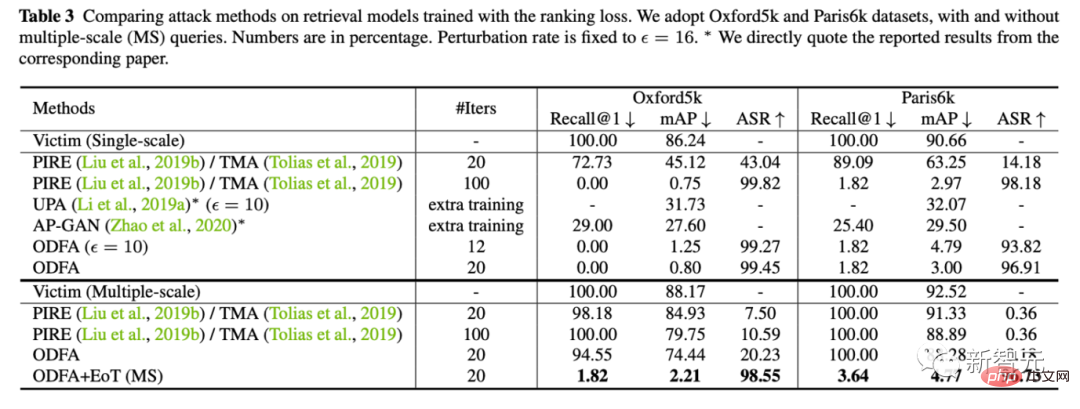
2 Gleichzeitig liefern wir auch quantitative experimentelle Ergebnisse zu 5 Datensätzen (Lebensmittel, CUB, Markt, Oxford, Paris)
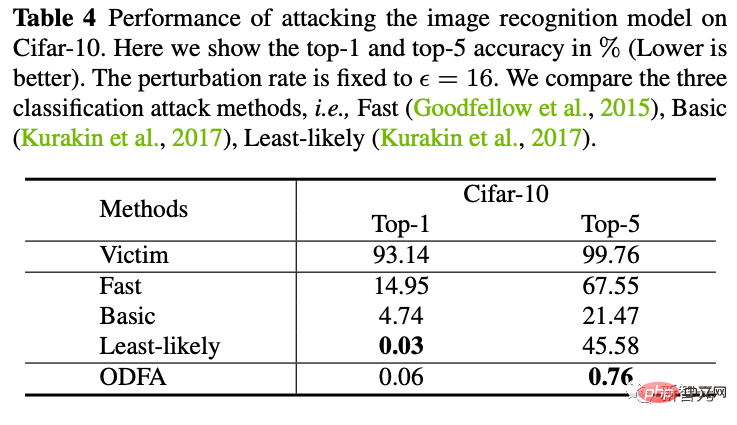
3 Um den Modellmechanismus zu demonstrieren, haben wir auch versucht, das Klassifizierungsmodell auf Cifar10 anzugreifen.
Sie können sehen, dass unsere Strategie, die letzte Funktionsebene zu ändern, auch eine starke Unterdrückungskraft gegenüber den Top 5 hat. Da für die Top-1-Kandidaten keine Kandidatenkategorie herangezogen wird, ist sie etwas niedriger als die am wenigsten wahrscheinliche, aber sie ist fast gleich.
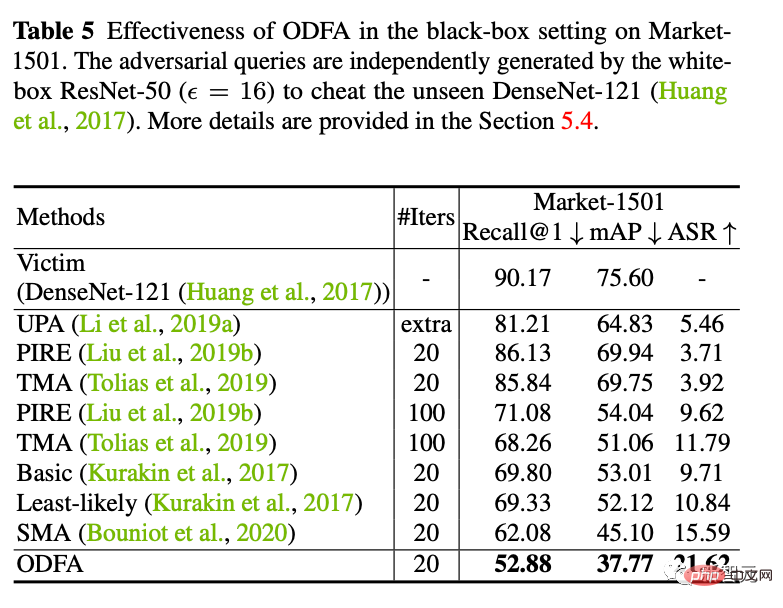
4. Black-Box-Angriff
Wir haben auch versucht, das von ResNet50 generierte Angriffsbeispiel zu verwenden, um ein Black-Box-DenseNet-Modell anzugreifen (die Parameter dieses Modells stehen uns nicht zur Verfügung). Es zeigt sich, dass auch bessere Migrationsangriffsfähigkeiten erreicht werden können.
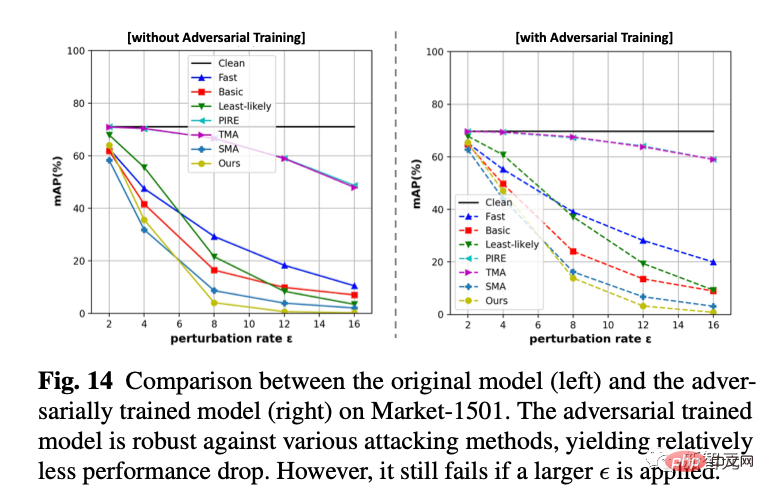
5. Gegenverteidigung
Wir nutzen Online-Gegnertraining, um ein Verteidigungsmodell zu trainieren. Wir haben festgestellt, dass es immer noch ineffektiv ist, wenn es neue White-Box-Angriffe akzeptiert, aber bei kleinen Schwankungen (weniger Punkteverlust) stabiler ist als ein völlig wehrloses Modell.
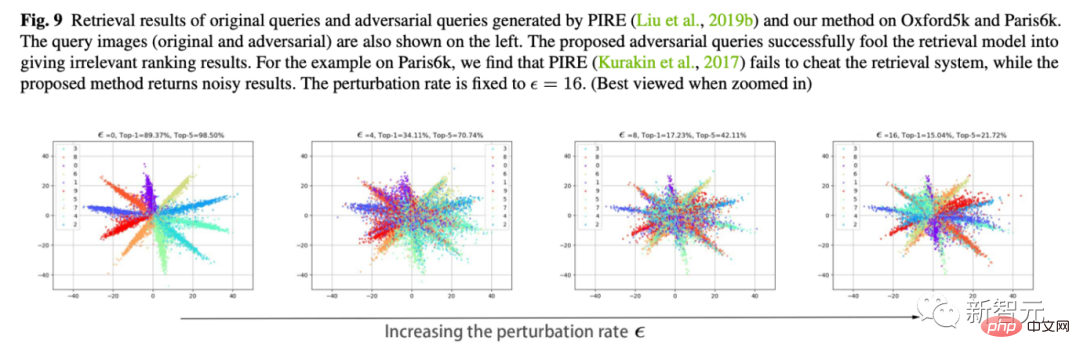
6. Visualisierung von Feature-Bewegungen
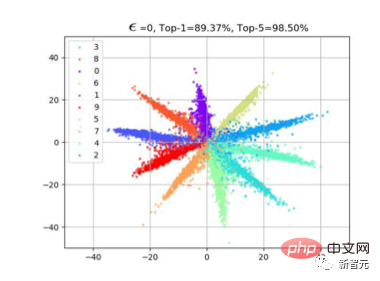
Das ist auch mein Lieblingsexperiment. Wir verwenden Cifar10, um die Dimension der letzten Klassifizierungsschicht auf 2 zu ändern und die Änderungen in den Merkmalen der Klassifizierungsschicht darzustellen.
Wie in der Abbildung unten gezeigt, können wir mit zunehmender Jitter-Amplitude Epsilon sehen, dass sich die Eigenschaften der Probe langsam „umkehren“. Beispielsweise sind die meisten orangefarbenen Merkmale auf die gegenüberliegende Seite verschoben.
Das obige ist der detaillierte Inhalt vonDurch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr