
Heim >Technologie-Peripheriegeräte >KI >Das Shanghai Digital Brain Research Institute veröffentlicht DB1, Chinas erstes großes multimodales Entscheidungsmodell, das eine schnelle Entscheidungsfindung bei äußerst komplexen Problemen ermöglichen kann
Das Shanghai Digital Brain Research Institute veröffentlicht DB1, Chinas erstes großes multimodales Entscheidungsmodell, das eine schnelle Entscheidungsfindung bei äußerst komplexen Problemen ermöglichen kann

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-04 09:58:061708Durchsuche
Kürzlich hat das Shanghai Digital Brain Research Institute (im Folgenden als „Digital Brain Research Institute“ bezeichnet) das erste groß angelegte multimodale Entscheidungsfindungsmodell für das digitale Gehirn (als DB1 bezeichnet) auf den Markt gebracht und damit die inländische Lücke in diesem Bereich geschlossen und weitere Überprüfung des Einsatzpotenzials vorab trainierter Modelle in der Text-, Grafiktext-, Reinforcement-Learning-Entscheidungsfindung und Betriebsoptimierungsentscheidungsfindung. Derzeit haben wir den DB1-Code als Open Source auf Github bereitgestellt, Projektlink: https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1.
Zuvor schlug das Institut für Mathematische Wissenschaften in einigen Fällen Multiagentenmodelle wie MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs/2205.14953) vor Große Offline-Modelle Durch Sequenzmodellierung hat das Transformer-Modell bei einigen Einzel-/Multi-Agent-Aufgaben bemerkenswerte Ergebnisse erzielt, und die Forschung und Erforschung in dieser Richtung wird fortgesetzt.
In den letzten Jahren haben Wissenschaft und Industrie mit dem Aufkommen groß angelegter Vortrainingsmodelle weiterhin neue Fortschritte bei der Parametermenge und den multimodalen Aufgaben von Vortrainingsmodellen erzielt -Trainingsmodelle wurden auf riesigen Datenmengen trainiert. Die tiefe Modellierung von Wissen und Wissen gilt als einer der wichtigen Wege zur allgemeinen künstlichen Intelligenz. Das Digital Research Institute, das sich auf die Entscheidungsintelligenzforschung konzentriert, versuchte auf innovative Weise, den Erfolg des vorab trainierten Modells auf Entscheidungsaufgaben zu übertragen, und erzielte einen Durchbruch.
Multimodales Entscheidungsfindungs-Großmodell DB1
Zuvor hat DeepMind Gato gestartet, das Einzelagenten-Entscheidungsaufgaben, Mehrrundengespräche und Bild-Text-Generierungsaufgaben in einem Transformer-basierten autoregressiven Problem vereint und weiterführt 604 Es hat bei verschiedenen Aufgaben eine gute Leistung erzielt und gezeigt, dass einige einfache Entscheidungsprobleme beim Verstärkungslernen durch Sequenzvorhersage gelöst werden können, wodurch die Richtigkeit der Forschungsrichtung groß angelegter Entscheidungsmodelle des Instituts für Mathematik überprüft wird.
Diesmal reproduziert und verifiziert DB1 vom Mathematical Research Institute hauptsächlich Gato und versucht, es in Bezug auf Netzwerkstruktur und Parametermenge, Aufgabentyp und Aufgabennummer zu verbessern:
-
Parametermenge und Netzwerkstruktur : DB1-Parametermenge erreicht 1,21 Milliarden. Versuchen Sie, in Bezug auf die Parameter so nah wie möglich an Gato zu sein. Im Allgemeinen verwendet das Institute of Numerical Research eine ähnliche Struktur wie Gato (gleiche Anzahl von Decoder-Blöcken, gleiche Größe der verborgenen Ebenen usw.), jedoch in FeedForwardNetwork, da die GeGLU-Aktivierungsfunktion ein zusätzliches Drittel der Anzahl der Parameter einführt Das Institut für Mathematische Wissenschaften möchte, dass die Parametermenge nahe an Gato liegt und der verborgene Schichtzustand von 4 * n_embed-Dimensionen durch die GeGLU-Aktivierungsfunktion in 2 * n_embed-dimensionale Merkmale umgewandelt wird. Ansonsten teilen wir die Einbettungsparameter auf der Eingabe- und Ausgabekodierungsseite mit der Gato-Implementierung. Anders als bei Gato verwenden wir bei der Auswahl der Schichtnormalisierung die PostNorm-Lösung und verwenden in Attention Berechnungen mit gemischter Genauigkeit, um die numerische Stabilität zu verbessern.
- Aufgabentyp und Anzahl der Aufgaben: Die Anzahl der experimentellen Aufgaben in DB1 erreicht 870, was 44,04 % mehr als bei Gato und 2,23 % mehr als bei Gato bei >=50 % Expertenleistung ist. In Bezug auf bestimmte Aufgabentypen übernimmt DB1 größtenteils Gatos Entscheidungs-, Bild- und Textaufgaben, und die Anzahl der verschiedenen Aufgaben bleibt im Wesentlichen gleich. Aber in Bezug auf Entscheidungsaufgaben hat DB1 auch mehr als 200 reale Szenarioaufgaben eingeführt, nämlich das Travelling Salesman Problem (TSP) mit einer Skala von 100 und 200 Knoten. Bei dieser Art von Aufgabe werden 100–200 geografische Standorte zufällig ausgewählt Knoten in allen großen Städten Chinas.
Es ist ersichtlich, dass die Gesamtleistung von DB1 das gleiche Niveau wie die von Gato erreicht hat und begonnen hat, sich zu einem Domänenkörper zu entwickeln, der den tatsächlichen Geschäftsanforderungen näher kommt und NP-harte TSP-Probleme lösen kann Sehr gut, während vor Gato diese Richtung noch nicht erforscht wurde.
 Vergleich der Indikatoren DB1 (rechts) und GATO (links)
Vergleich der Indikatoren DB1 (rechts) und GATO (links)
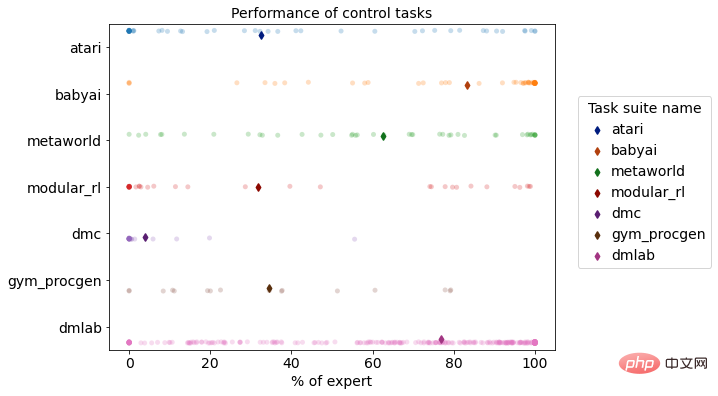
Multitask-Leistungsverteilung von DB1 in der Simulationsumgebung für Verstärkungslernen
Im Vergleich zu herkömmlichen Entscheidungsalgorithmen bietet DB1 eine gute Leistung bei der aufgabenübergreifenden Entscheidungsfindung und bei der schnellen Migration. In Bezug auf aufgabenübergreifende Entscheidungsfähigkeiten und Parametermengen hat es einen Sprung von mehreren zehn Millionen Parametern für eine einzelne komplexe Aufgabe auf Milliarden von Parametern für mehrere komplexe Aufgaben geschafft und wächst weiter und verfügt über die Fähigkeit zur Lösung Probleme in komplexen Geschäftsumgebungen. In Bezug auf die Migrationsfähigkeiten hat DB1 den Sprung von der intelligenten Vorhersage zur intelligenten Entscheidungsfindung und vom Einzelagenten zum Multiagenten geschafft und die Mängel traditioneller Methoden bei der aufgabenübergreifenden Migration ausgeglichen, sodass große Modelle erstellt werden können innerhalb des Unternehmens.
Es ist unbestreitbar, dass DB1 im Entwicklungsprozess auch auf viele Schwierigkeiten gestoßen ist. Das Institute of Digital Research hat viele Versuche unternommen, der Industrie einige Standardlösungen für das groß angelegte Modelltraining und die Speicherung von Multitask-Trainingsdaten bereitzustellen . Da die Modellparameter 1 Milliarde Parameter erreicht haben und der Aufgabenumfang riesig ist und das Training auf mehr als 100T (300B+ Tokens) Expertendaten erfolgen muss, kann das gewöhnliche Deep-Reinforcement-Learning-Trainingsframework die Anforderungen eines schnellen Trainings nicht mehr erfüllen diese Situation. Zu diesem Zweck berücksichtigt das Institut für Mathematikforschung einerseits die Rechenstruktur des verstärkenden Lernens, der Betriebsoptimierung und des Trainings großer Modelle in einer Umgebung mit einer einzelnen Maschine und mehreren Karten Es nutzt die Hardware-Ressourcen voll aus und gestaltet Module geschickt. Der Kommunikationsmechanismus zwischen den Modellen maximiert die Trainingseffizienz des Modells und verkürzt die Trainingszeit von 870 Aufgaben auf eine Woche. Andererseits sind bei der verteilten Zufallsstichprobe auch die im Trainingsprozess erforderliche Datenindizierung, -speicherung, -ladung und -vorverarbeitung zu entsprechenden Engpässen geworden. Das Forschungsinstitut des Instituts für Mathematik verwendet beim Laden des Datensatzes den verzögerten Lademodus, um das Problem zu lösen Beseitigen Sie Speicherbeschränkungen und maximieren Sie die volle Nutzung des verfügbaren Speichers. Darüber hinaus werden die verarbeiteten Daten nach der Vorverarbeitung der geladenen Daten auf der Festplatte zwischengespeichert, sodass die vorverarbeiteten Daten später direkt geladen werden können, wodurch die durch wiederholte Vorverarbeitung verursachten Zeit- und Ressourcenkosten reduziert werden.
Derzeit haben führende internationale und inländische Unternehmen und Forschungseinrichtungen wie OpenAI, Google, Meta, Huawei, Baidu und die DAMO Academy Forschungen zu multimodalen Großmodellen durchgeführt und bestimmte Kommerzialisierungsversuche unternommen, darunter „Anwenden oder Bereitstellen von Modellen“. APIs und verwandte Branchenlösungen in Ihren eigenen Produkten. Im Gegensatz dazu konzentriert sich das Institut für Mathematische Wissenschaften mehr auf Entscheidungsfragen und unterstützt Anwendungsversuche bei Entscheidungsaufgaben für Spiel-KI, TSP-Lösungsaufgaben zur Operations Research-Optimierung, Steuerungsaufgaben für Roboterentscheidungen, Lösungsaufgaben zur Black-Box-Optimierung und Multi- Runde Dialogaufgaben.
Aufgabenleistung
Betriebsoptimierung: TSP-Problemlösung
TSP-Problem mit einigen Städten in China als Knoten
Videodemonstration der Verstärkungslernaufgabe
DB1-Modell ist im Werden abgeschlossen Nach dem Offline-Lernen von 870 verschiedenen Entscheidungsaufgaben zeigten die Bewertungsergebnisse, dass 76,67 % der Aufgaben das Expertenniveau von 50 % erreichten oder übertrafen. Im Folgenden werden die Auswirkungen einiger Aufgaben demonstriert.
- Videospielszene: DB1 kann 2D-/3D-Bildeingaben empfangen und 2D-Pixelspiele wie Atari und Procgen gut ausführen. Gleichzeitig ist es auch für DMLab geeignet, eine ähnliche 3D-Bildeingabeaufgabe In der realen Welt zeigte DB1 ebenfalls eine gute Leistung.

Atari Breakout

DMLab Objektstandorte erkunden

Procgen DogBall
- Kontinuierliche Kontrollszenen: Für kontinuierliche Steuerungsaufgaben im Bereich der Robotik kann DB1 auch die Richtlinienausgabe kontinuierlicher Aktionen modellieren und Simulationsaufgaben gut abschließen.

Metaworld PlateSlide

ModularRL Cheetah
文本 - 图像任务...
- 文本生成:给出一段文字提示,生成长文本描述
- 输入提示:Digital Brain Laboratory ist ein in Shanghai ansässiges Unternehmen sind ein digitales Gehirnlabor und wir suchen eine hochqualifizierte und erfahrene Person zur Verstärkung unseres Teams in Shanghai, China.
- Dies ist eine Gelegenheit, für ein bekanntes und wachsendes Unternehmen zu arbeiten, das sich in einer schnellen Wachstumsphase befindet und um auf dem Markt Einfluss zu nehmen.
-
Dies ist eine unbefristete Vollzeitstelle.
Wir suchen einen hochqualifizierten, motivierten und erfahrenen Softwareentwickler, der ein Team von 5-10 Personen in einem hart umkämpften Umfeld leiten kann Umwelt前决策大模型的局限性与未来方向
虽然当前多模态决策预训练模型DB1 ist eine neue Version von DB1序列建模困难、专家数据强依赖等.虽然存在众多挑战,但现阶段看来多模态决策大模型是实现决策智能体从游戏走向更广泛场景, 从虚拟走向现实,在现实开放动态环境中进行自主感觉与决策,最终实现更加通用人工智能的关键探索方向之一.未来数研院将持续迭代数字大脑决策大模型, 通过更大参数量, 更有效的序列表征, 接入和支持更多任务,结合离线 / 线训练与微调,实现跨域、跨模态、跨任务的知识泛化与迁移,最终在现实应用场景下提供更通用、更高效、更低成本的决策智能决策解决方案.
Das obige ist der detaillierte Inhalt vonDas Shanghai Digital Brain Research Institute veröffentlicht DB1, Chinas erstes großes multimodales Entscheidungsmodell, das eine schnelle Entscheidungsfindung bei äußerst komplexen Problemen ermöglichen kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr