
Heim >Technologie-Peripheriegeräte >KI >Von PyTorch geschlagen! Google verwirft TensorFlow und setzt auf JAX
Von PyTorch geschlagen! Google verwirft TensorFlow und setzt auf JAX

- 王林nach vorne
- 2023-05-04 08:16:061027Durchsuche
Mir gefällt wirklich, was einige Internetnutzer gesagt haben:
„Diesem Kind geht es wirklich nicht gut, lass uns noch eins bekommen.“
Google hat das wirklich getan.
Nach sieben Jahren Entwicklung wurde TensorFlow schließlich gewissermaßen von Metas PyTorch besiegt.
Als Google sah, dass etwas nicht stimmte, fragte es schnell nach einem anderen – „JAX“, einem brandneuen Framework für maschinelles Lernen.

Sie alle kennen das kürzlich sehr beliebte DALL·E Mini. Sein Modell ist auf JAX-Basis programmiert und nutzt so die Vorteile von Google TPU voll aus.
Die Dämmerung von TensorFlow und der Aufstieg von PyTorch
Im Jahr 2015 kam TensorFlow heraus, das von Google entwickelte Framework für maschinelles Lernen.
Damals war TensorFlow nur ein kleines Projekt von Google Brain.
Niemand hatte erwartet, dass TensorFlow gleich nach seiner Veröffentlichung sehr beliebt werden würde.
Große Unternehmen wie Uber und Airbnb nutzen es, aber auch nationale Agenturen wie die NASA nutzen es. Und sie alle werden bei ihren komplexesten Projekten eingesetzt.
Stand November 2020 wurde TensorFlow 160 Millionen Mal heruntergeladen.
Die Gefühle so vieler Nutzer scheinen Google jedoch wenig zu interessieren.
Die seltsame Benutzeroberfläche und die häufigen Updates machen TensorFlow für Benutzer zunehmend unfreundlich und immer schwieriger zu bedienen.
Sogar innerhalb von Google hat man das Gefühl, dass es mit diesem Rahmenwerk bergab geht.
Tatsächlich ist es für Google wirklich hilflos, so häufig zu aktualisieren. Denn nur so kann man mit der schnellen Iteration im Bereich des maschinellen Lernens Schritt halten.
Dadurch schlossen sich immer mehr Menschen dem Projekt an, wodurch das gesamte Team langsam den Fokus verlor.
Und die leuchtenden Punkte, die TensorFlow ursprünglich zum Tool der Wahl gemacht haben, sind in so vielen Faktoren vergraben und werden nicht mehr ernst genommen.
Dieses Phänomen wird von Insider als „Katz- und Mausspiel“ beschrieben. Das Unternehmen ist wie eine Katze, und die neuen Bedürfnisse, die durch ständige Iteration entstehen, sind wie Mäuse. Katzen sollten immer wachsam und bereit sein, sich auf Mäuse zu stürzen.

Dieses Dilemma ist für Unternehmen, die als erste in einen bestimmten Markt eintreten, unvermeidbar.
Was beispielsweise Suchmaschinen betrifft, ist Google nicht der Erste. Daher kann Google aus den Fehlern seiner Vorgänger (AltaVista, Yahoo usw.) lernen und diese auf die eigene Entwicklung anwenden.
Leider ist Google in der Falle, wenn es um TensorFlow geht.
Gerade aus den oben genannten Gründen verloren Entwickler, die ursprünglich für Google arbeiteten, nach und nach das Vertrauen in ihren alten Arbeitgeber.
Der in der Vergangenheit allgegenwärtige TensorFlow ist allmählich zurückgegangen und hat gegen Metas aufstrebenden Stern PyTorch verloren.

Im Jahr 2017 war die Beta-Version von PyTorch Open Source.
Im Jahr 2018 veröffentlichte das Forschungslabor für künstliche Intelligenz von Facebook eine Vollversion von PyTorch.
Erwähnenswert ist, dass PyTorch und TensorFlow beide auf Python-Basis entwickelt wurden, während Meta mehr Wert auf die Pflege der Open-Source-Community legt und sogar viele Ressourcen investiert.
Darüber hinaus achtet Meta auf die Probleme von Google und glaubt, dass es nicht dieselben Fehler wiederholen kann. Sie konzentrieren sich auf eine kleine Anzahl von Funktionen und machen daraus das Beste, was sie sein können.
Meta tritt nicht in die Fußstapfen von Google. Dieses zunächst bei Facebook entwickelte Framework hat sich langsam zu einem Branchenmaßstab entwickelt.
Ein Forschungsingenieur bei einem Start-up-Unternehmen für maschinelles Lernen sagte: „Wir verwenden grundsätzlich PyTorch. Seine Community und Open Source sind die besten. Sie beantworten nicht nur Fragen, sondern die gegebenen Beispiele sind auch sehr praktisch.“
Angesichts dieser Situation sagten Google-Entwickler, Hardware-Experten, Cloud-Anbieter und alle, die mit maschinellem Lernen von Google zu tun haben, in Interviews alle dasselbe. Sie glauben, dass TensorFlow die Herzen der Entwickler verloren hat.
Nach einer Reihe offener und verdeckter Kämpfe gewann Meta schließlich die Oberhand.
Einige Experten sagen, dass Googles Chance, auch in Zukunft führend beim maschinellen Lernen zu sein, langsam verschwindet.
PyTorch hat sich nach und nach zum Werkzeug der Wahl für normale Entwickler und Forscher entwickelt.
Den von Stack Overflow bereitgestellten Interaktionsdaten nach zu urteilen, gibt es im Entwicklerforum immer mehr Fragen zu PyTorch, während Fragen zu TensorFlow in den letzten Jahren ins Stocken geraten sind.
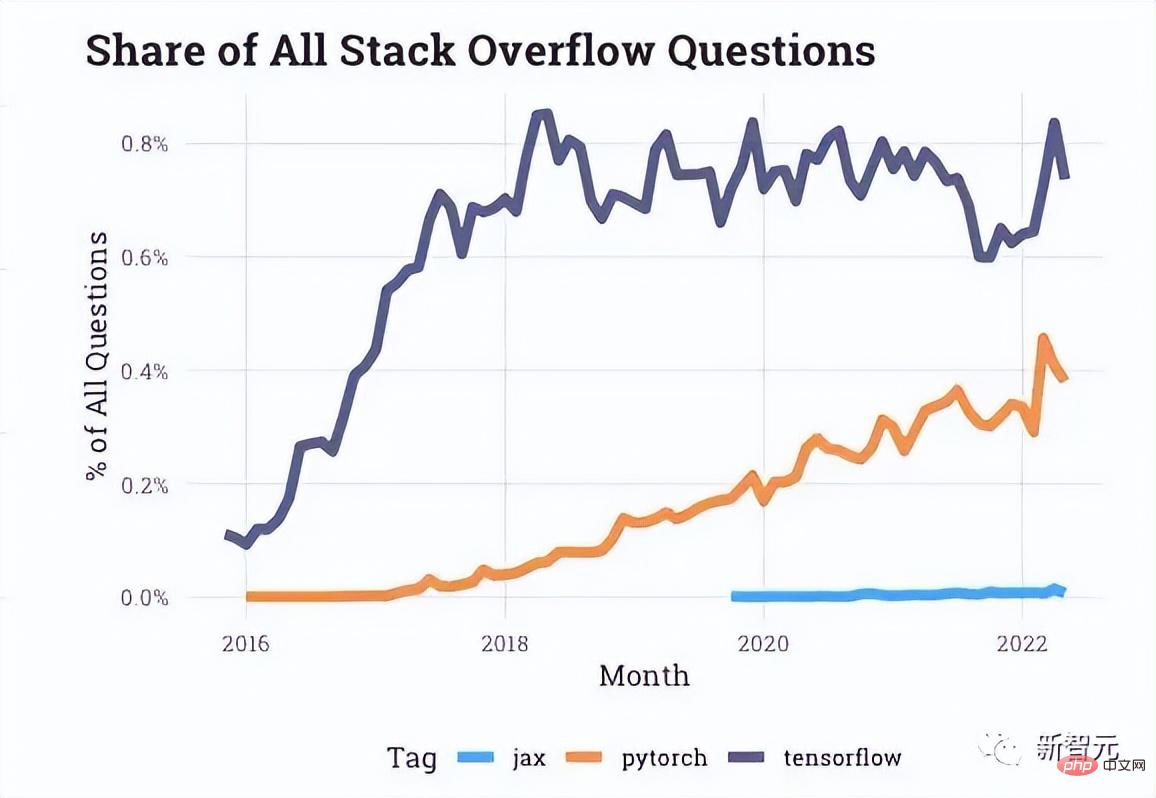
Sogar Unternehmen wie Uber, die am Anfang des Artikels erwähnt wurden, haben sich ebenfalls an PyTorch gewandt.
Tatsächlich scheint jedes weitere Update von PyTorch ein Schlag ins Gesicht von TensorFlow zu sein.
Die Zukunft des maschinellen Lernens von Google – JAX
Gerade als TensorFlow und PyTorch in vollem Gange waren, begann ein „kleines Dark-Horse-Forschungsteam“ innerhalb von Google mit der Entwicklung eines brandneuen Frameworks, das TPU einfacher nutzen kann.

Im Jahr 2018 brachte ein Artikel mit dem Titel „Compiling Machine Learning Programs via High-Level Tracing“ das JAX-Projekt an die Oberfläche. Die Autoren waren Roy Frostig, Matthew James Johnson und Chris Leary.

Von links nach rechts sind diese drei Meister
Dann trat Adam Paszke, einer der ursprünglichen Autoren von PyTorch, Anfang 2020 ebenfalls hauptberuflich dem JAX-Team bei.

JAX bietet eine direktere Möglichkeit, mit einem der komplexesten Probleme beim maschinellen Lernen umzugehen: dem Multi-Core-Prozessor-Planungsproblem.
Je nach Anwendungssituation fasst JAX mehrere Chips automatisch zu einer kleinen Gruppe zusammen, anstatt einen alleine arbeiten zu lassen.
Der Vorteil dabei ist, dass möglichst viele TPUs in einem Moment reagieren können und dadurch unser „Alchemie-Universum“ verbrennt.
Am Ende hat JAX im Vergleich zum aufgeblähten TensorFlow ein großes Problem innerhalb von Google gelöst: wie man schnell auf die TPU zugreifen kann.
Das Folgende ist eine kurze Einführung in Autograd und XLA, die JAX bilden.
Autograd wird hauptsächlich zur verlaufsbasierten Optimierung verwendet und kann automatisch zwischen Python- und Numpy-Code unterscheiden.
Es kann verwendet werden, um eine Teilmenge von Python zu verarbeiten, einschließlich Schleifen, Rekursion und Schließungen, und es kann auch Ableitungen von Ableitungen durchführen.
Darüber hinaus unterstützt Autograd die Backpropagation von Gradienten, was bedeutet, dass es effektiv den Gradienten einer Skalarwertfunktion relativ zu einem Arraywertparameter sowie die Vorwärtsmodusdifferenzierung erhalten kann, und beide können auf beliebige Weise kombiniert werden .
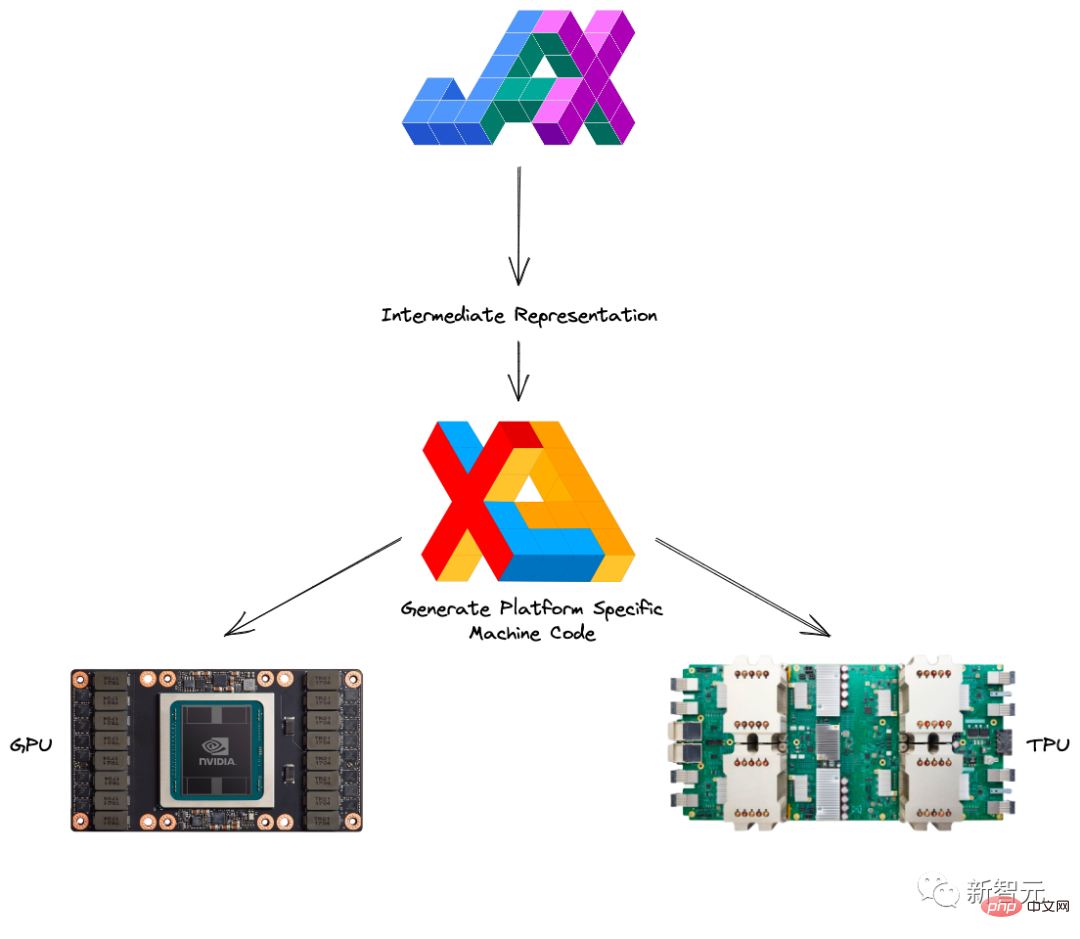
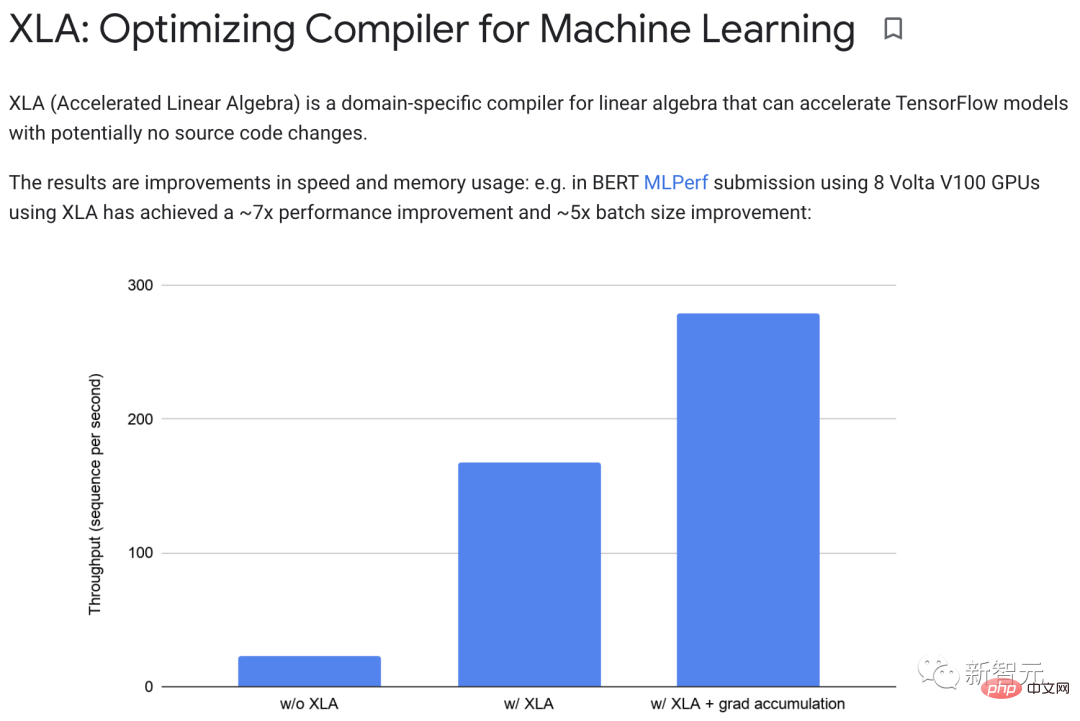
XLA (Accelerated Linear Algebra) kann TensorFlow-Modelle beschleunigen, ohne den Quellcode zu ändern.
Wenn ein Programm ausgeführt wird, werden alle Vorgänge einzeln vom Ausführenden ausgeführt. Jede Operation verfügt über eine vorkompilierte GPU-Kernel-Implementierung, an die Executoren gesendet werden.
Zum Beispiel:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">model_fn</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>):<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">return</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tf</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">reduce_sum</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">+</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">*</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>)
Wenn dieser Teil ohne XLA ausgeführt wird, werden drei Kerne gestartet: einer für die Multiplikation, einer für die Addition und einer für die Subtraktion.
Und XLA kann eine Optimierung erreichen, indem Addition, Multiplikation und Subtraktion in einem einzigen GPU-Kern „zusammengeführt“ werden.
Dieser Fusionsvorgang schreibt die vom Speicher generierten Zwischenwerte nicht in den y*z-Speicher x+y*z, sondern „streamt“ die Ergebnisse dieser Zwischenberechnungen direkt an den Benutzer und speichert sie vollständig darin in der GPU.
In der Praxis kann XLA eine etwa 7-fache Leistungsverbesserung und eine etwa 5-fache Verbesserung der Chargengröße erreichen.
Darüber hinaus können XLA und Autograd beliebig kombiniert werden, und Sie können sogar die pmap-Methode verwenden, um mit mehreren GPU- oder TPU-Kernen gleichzeitig zu programmieren.
Durch die Kombination von JAX mit Autograd und Numpy erhalten Sie ein einfach zu programmierendes und leistungsstarkes maschinelles Lernsystem für CPU, GPU und TPU.
Offensichtlich hat Google dieses Mal seine Lektion gelernt. Neben der vollständigen Einführung seiner eigenen Produkte fördert es auch besonders aktiv den Aufbau eines Open-Source-Ökosystems.
Im Jahr 2020 trat DeepMind offiziell in die Arme von JAX, und dies kündigte auch das Ende von Google selbst an. Seitdem sind unzählige Open-Source-Bibliotheken entstanden.
... 
 Und es lohnt sich, von Googles Pragmatismus zu lernen, der bereit ist, sich selbst zu untergraben.
Und es lohnt sich, von Googles Pragmatismus zu lernen, der bereit ist, sich selbst zu untergraben.


 Zum Laden und Vorverarbeiten von Daten müssen Sie TensorFlow oder PyTorch verwenden, um die meisten Einstellungen zu verwalten.
Zum Laden und Vorverarbeiten von Daten müssen Sie TensorFlow oder PyTorch verwenden, um die meisten Einstellungen zu verwalten.
Offensichtlich ist dies noch weit vom idealen „One-Stop“-Rahmen entfernt.
Zweitens ist JAX hauptsächlich für TPU stark optimiert, aber wenn es um GPU und CPU geht, ist es viel schlechter. Einerseits führte das organisatorische und strategische Chaos von Google von 2018 bis 2021 dazu, dass die Mittel für Forschung und Entwicklung zur Unterstützung von GPUs nicht ausreichten und die Behandlung damit verbundener Probleme nur geringe Priorität hatte. Gleichzeitig konzentrieren sie sich wahrscheinlich zu sehr darauf, dass ihre eigenen TPUs bei der KI-Beschleunigung mehr vom Kuchen bekommen, sodass die Zusammenarbeit mit NVIDIA natürlich sehr mangelhaft ist, ganz zu schweigen von der Verbesserung von Details wie der GPU-Unterstützung.
Gleichzeitig konzentrieren sie sich wahrscheinlich zu sehr darauf, dass ihre eigenen TPUs bei der KI-Beschleunigung mehr vom Kuchen bekommen, sodass die Zusammenarbeit mit NVIDIA natürlich sehr mangelhaft ist, ganz zu schweigen von der Verbesserung von Details wie der GPU-Unterstützung.
Andererseits konzentriert sich Googles eigene interne Forschung zweifellos auf TPU, was dazu führt, dass Google eine gute Feedbackschleife zur GPU-Nutzung verliert.
Darüber hinaus erhöhen längere Debugging-Zeiten, mangelnde Kompatibilität mit Windows, fehlende Überwachung des Risikos von Nebenwirkungen usw. die Nutzungsschwelle und die Benutzerfreundlichkeit von Jax.
Mittlerweile ist PyTorch fast 6 Jahre alt, weist aber nicht den Rückgang auf, den TensorFlow damals zeigte.
Es scheint, dass Jax noch einen langen Weg vor sich hat, wenn er zu den Nachzüglern aufschließen will.
Das obige ist der detaillierte Inhalt vonVon PyTorch geschlagen! Google verwirft TensorFlow und setzt auf JAX. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr