
Heim >Technologie-Peripheriegeräte >KI >Kann Menschen ohne RLHF ausrichten, Leistung vergleichbar mit ChatGPT! Chinesisches Team schlägt Wombat-Modell vor
Kann Menschen ohne RLHF ausrichten, Leistung vergleichbar mit ChatGPT! Chinesisches Team schlägt Wombat-Modell vor

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-03 11:46:061386Durchsuche
ChatGPT von OpenAI ist in der Lage, eine Vielzahl menschlicher Anweisungen zu verstehen und verschiedene Sprachaufgaben gut zu bewältigen. Dies ist dank einer neuartigen Methode zur Feinabstimmung groß angelegter Sprachmodelle namens RLHF (Aligned Human Feedback via Reinforcement Learning) möglich.
Die RLHF-Methode erschließt die Fähigkeit von Sprachmodellen, menschlichen Anweisungen zu folgen, wodurch die Fähigkeiten von Sprachmodellen mit menschlichen Bedürfnissen und Werten in Einklang gebracht werden.
Derzeit verwendet die Forschungsarbeit von RLHF hauptsächlich den PPO-Algorithmus zur Optimierung von Sprachmodellen. Der PPO-Algorithmus enthält jedoch viele Hyperparameter und erfordert die Zusammenarbeit mehrerer unabhängiger Modelle während des Iterationsprozesses des Algorithmus, sodass falsche Implementierungsdetails zu schlechten Trainingsergebnissen führen können.
Gleichzeitig sind Lernalgorithmen zur Verstärkung aus Sicht der menschlichen Ausrichtung nicht erforderlich.

Papieradresse: https://arxiv.org/abs/2304.05302v1
Projektadresse: https://github.com/GanjinZero/RRHF
Zu diesem Zweck schlugen Autoren der Alibaba Damo Academy und der Tsinghua University eine Methode namens Ranking-based Human Preference Alignment – RRHF – vor.
RRHF Es ist kein Verstärkungslernen erforderlich und die von verschiedenen Sprachmodellen generierten Antworten können genutzt werden, einschließlich ChatGPT, GPT-4 oder aktuellen Trainingsmodellen. RRHF funktioniert, indem es Antworten bewertet und die Antworten durch einen Ranking-Verlust an menschliche Vorlieben anpasst.
Im Gegensatz zu PPO kann der Trainingsprozess von RRHF die Ergebnisse menschlicher Experten oder GPT-4 als Vergleich verwenden. Das trainierte RRHF-Modell kann sowohl als generatives Sprachmodell als auch als Belohnungsmodell verwendet werden.
Der CEO von Playgound AI sagte, dass dies der interessanteste Artikel der letzten Zeit sei
Die folgende Abbildung vergleicht den Unterschied zwischen dem PPO-Algorithmus und dem RRHF-Algorithmus.
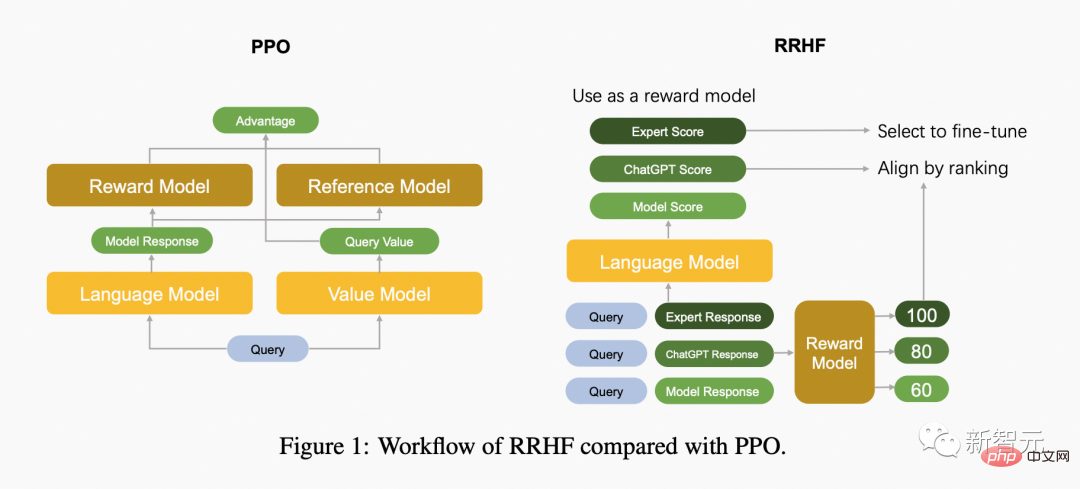
RRHF erhält zunächst k Antworten über verschiedene Methoden für die Eingabeabfrage und verwendet dann das Belohnungsmodell, um diese k Antworten jeweils zu bewerten. Jede Antwort wird mit logarithmischer Wahrscheinlichkeit bewertet:
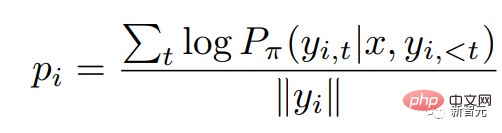
Dabei ist die Wahrscheinlichkeitsverteilung des autoregressiven Sprachmodells.
Wir hoffen, Antworten mit hohen Punktzahlen aus dem Belohnungsmodell eine größere Wahrscheinlichkeit zu geben, das heißt, wir hoffen, die Belohnungspunktzahl zu erreichen. Wir optimieren dieses Ziel durch Ranking-Verlust:
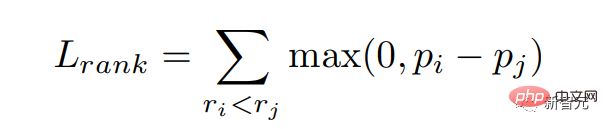
Darüber hinaus geben wir dem Modell auch das Ziel, direkt die Antwort mit der höchsten Punktzahl zu lernen:
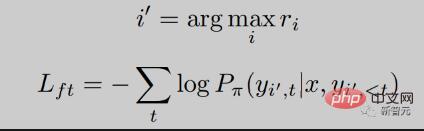
Sie können sehen, dass die RRHF Der Trainingsprozess ist sehr einfach. Es ist ersichtlich, dass der Rückgang während des RRHF-Trainings sehr stabil ist und der Belohnungswert mit abnehmendem Verlust stetig zunimmt.
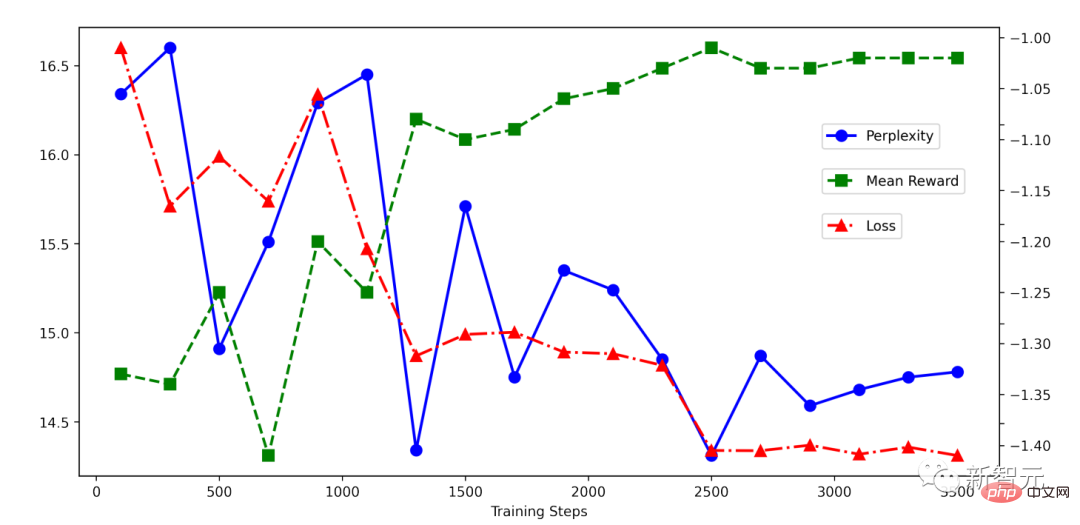
Der Autor des Artikels führte Experimente mit dem HH-Datensatz durch und kann auch mit PPO vergleichbare Ergebnisse sehen:
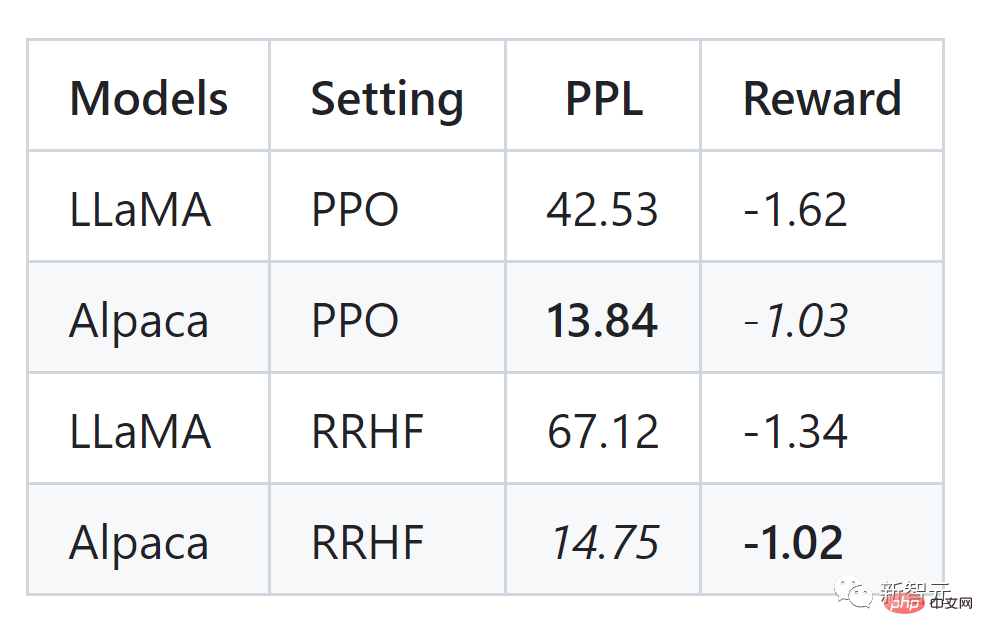
Der RRHF-Algorithmus kann die Ausgabewahrscheinlichkeit des Sprachmodells effektiv mit der des Menschen abgleichen Präferenzen Ausrichtung, seine Trainingsidee ist sehr einfach und das trainierte Modell weist mehrere Merkmale auf:
- erfordert nur 1 bis 2 Modelle, während PPO 4 Modelle erfordert, sodass der RRHF-Algorithmus einfacher und effizienter ist.
- Supervised Fine-Tuning (SFT) kann als Sonderform des RRHF-Algorithmus angesehen werden.
- Der RRHF-Algorithmus kann sowohl als Sprachmodell als auch als Belohnungsmodell verwendet werden.
- Der RRHF-Algorithmus kann die Präferenz des Belohnungsmodells bei einem geringeren Trainingsschwierigkeitsgrad anpassen, die Wirkung des PPO-Algorithmus erzielen und die Komplexitäts- und Instabilitätsprobleme im PPO-Algorithmus vermeiden. Die
RRHF-Methode verwendet chatGPT oder GPT-4 von OpenAI als Bewertungsmodell und die Ausgabe von ChatGPT, Alpaca und anderen Modellen als Trainingsbeispiele, um zwei neue Sprachmodelle zu entwickeln, nämlich Wombat-7B und Wombat-7B -GPT4 . Die Trainingszeit liegt zwischen 2 und 4 Stunden und ist sehr gering.
Wombat kann als neues Open-Source-Pre-Training-Modell im Vergleich zu LLaMA, Alpaca usw. besser auf menschliche Vorlieben eingehen. Die Autoren fanden experimentell heraus, dass Wombat-7B über komplexe Fähigkeiten wie Rollenspiele und die Durchführung von kontrafaktischem Denken verfügt.
Wenn Sie Wombat bitten, die Zukunftstechnologie aus dem Jahr 3000 vorzustellen, wird Wombat wie folgt antworten (übersetzt aus dem Englischen):
- Als Zeitreisender aus dem Jahr 3000 habe ich das Glück, viele Revolutionäre miterlebt zu haben technologische Fortschritte. Einer der wichtigsten technologischen Fortschritte, den ich mit modernen Menschen teilen möchte, ist die Entwicklung der Technologie der künstlichen Intelligenz (KI). Die KI-Technologie ist so weit fortgeschritten, dass sie zu einem integralen Bestandteil unseres täglichen Lebens geworden ist. Damit wurden intelligente Maschinen entwickelt, die ein breites Spektrum an Aufgaben erfüllen können, vom Autofahren bis zur Diagnose von Erkrankungen. Mithilfe der KI-Technologie werden auch virtuelle Assistenten wie Siri und Alexa entwickelt, die Fragen beantworten, Termine vereinbaren und sogar Lebensmittel bestellen können. Ein weiterer technologischer Fortschritt, den ich hervorheben möchte, ist die Entwicklung erneuerbarer Energien. Im Jahr 3000 wurde fast unser gesamter Energiebedarf durch erneuerbare Energiequellen wie Sonne, Wind und Wasserkraft gedeckt. Dies reduziert unseren CO2-Fußabdruck erheblich und trägt dazu bei, die Auswirkungen des Klimawandels abzumildern. Abschließend möchte ich die Fortschritte in der Weltraumforschung erwähnen. Im Jahr 3000 gelang es den Menschen, mehrere Planeten außerhalb unseres Sonnensystems zu erforschen und zu besiedeln. Dank fortschrittlicher Antriebssysteme und dem Einsatz künstlicher Intelligenz zur Navigation und Erkundung neuer Welten ist die Raumfahrt schneller, sicherer und einfacher geworden. Insgesamt sind die von mir erwähnten technologischen Fortschritte nur einige Beispiele für die vielen Innovationen, die im Laufe der Jahre entwickelt wurden. Als Zeitreisende haben wir aus erster Hand die erstaunlichen technologischen Fortschritte der Menschen miterlebt.
Ich hoffe, dass unsere Zukunft immer besser wird, wie Wombat es vorhersagt.

Referenz:
https://github.com/GanjinZero/RRHF
Das obige ist der detaillierte Inhalt vonKann Menschen ohne RLHF ausrichten, Leistung vergleichbar mit ChatGPT! Chinesisches Team schlägt Wombat-Modell vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr