
Heim >Technologie-Peripheriegeräte >KI >GMMSeg, ein neues Paradigma der generativen semantischen Segmentierung, kann sowohl die Erkennung geschlossener als auch offener Mengen verarbeiten
GMMSeg, ein neues Paradigma der generativen semantischen Segmentierung, kann sowohl die Erkennung geschlossener als auch offener Mengen verarbeiten

- PHPznach vorne
- 2023-05-02 08:34:131756Durchsuche
Der aktuelle gängige semantische Segmentierungsalgorithmus ist im Wesentlichen ein diskriminierendes Klassifizierungsmodell basierend auf dem Softmax-Klassifikator, der p (Klasse|Pixelmerkmal) direkt modelliert und die zugrunde liegende Pixeldatenverteilung, d. h. p( Klasse|Pixel-Funktion). Dies schränkt die Aussagekraft und Verallgemeinerung des Modells auf OOD-Daten (Out-of-Distribution) ein.
In einer aktuellen Studie schlugen Forscher der Zhejiang University, der University of Technology Sydney und des Baidu Research Institute ein neues semantisches Segmentierungsparadigma vor – das generative semantische Segmentierungsmodell GMMSeg basierend auf Gaußsches Mischungsmodell (GMM).

- Papierlink: https://arxiv.org/abs/2210.02025
- Code-Link: https://github.com/leonnnop/GMMSeg
GMMSeg modelliert die gemeinsame Verteilung von Pixeln und Kategorien, lernt durch den EM-Algorithmus einen Gaußschen Mischungsklassifikator (GMM-Klassifikator) im Pixelmerkmalsraum und verwendet ein generatives Paradigma zum Modellieren Die Verteilung der Pixelmerkmale jeder Kategorie wird genau erfasst. Unterdessen nutzt GMMSeg den diskriminierenden Verlust, um Deep-Feature-Extraktoren durchgängig zu optimieren. Dadurch bietet GMMSeg die Vorteile sowohl diskriminierender als auch generativer Modelle.
Experimentelle Ergebnisse zeigen, dass GMMSeg gleichzeitig Leistungsverbesserungen bei einer Vielzahl von Segmentierungsarchitekturen und Backbone-Netzwerken erzielt hat Durch die Feinabstimmung kann GMMSeg direkt auf Anomaliesegmentierungsaufgaben angewendet werden.
Bis heute ist dies das erste Mal, dass eine semantische Segmentierungsmethode eine einzelne Modellinstanz in einem verwenden kann Geschlossenes Set Erzielen Sie gleichzeitig eine höhere Leistung unter (geschlossenen) und Open-World-Bedingungen . Dies ist auch das erste Mal, dass generative Klassifikatoren Vorteile bei groß angelegten Bildverarbeitungsaufgaben gezeigt haben.
Diskriminierender vs. generativer Klassifikator
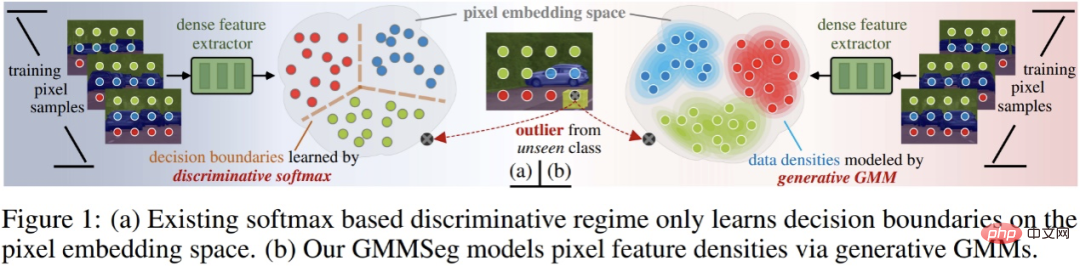
Eingehende Untersuchung bestehender Segmentierungsparadigmen Vorher Die vorgeschlagene Methode sowie die Konzepte der diskriminanten und generativen Klassifikatoren werden hier kurz vorgestellt.
Angenommen, es gibt einen Datensatz D, der Probenpaare enthält – Etikettenpaare (x, y); Der Klassifizierer ist die Vorhersage der Probenklassifizierungswahrscheinlichkeit p (y|x). Klassifizierungsmethoden können in zwei Kategorien unterteilt werden: diskriminierende Klassifikatoren und generative Klassifikatoren.
- Diskriminanzklassifikator: Direkte Modellierung der bedingten Wahrscheinlichkeit p (y|x); es lernt nur die maximale Klassifizierung Entscheidungsgrenze ohne Berücksichtigung der Verteilung der Stichprobe selbst und kann daher die Merkmale der Stichprobe nicht widerspiegeln.
- Generativer Klassifikator: Modellieren Sie zunächst die gemeinsame Wahrscheinlichkeitsverteilung p (x, y) und leiten Sie dann die Klassifizierung mithilfe des Satzes von Bayes ab Bedingte Wahrscheinlichkeit Es modelliert explizit die Verteilung der Daten selbst und erstellt häufig ein entsprechendes Modell für jede Kategorie. Im Vergleich zum diskriminierenden Klassifikator werden die charakteristischen Informationen der Probe vollständig berücksichtigt.
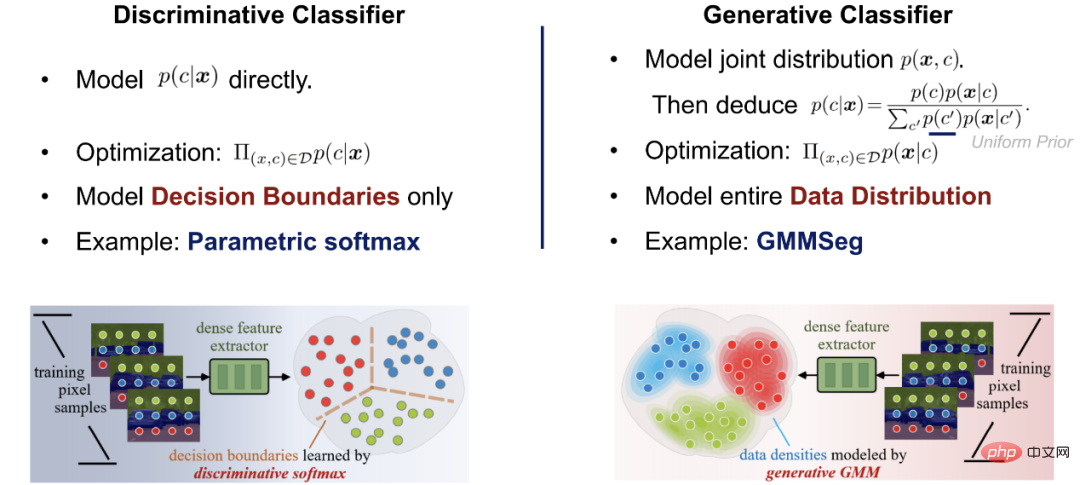
Mainstream-Paradigma der semantischen Segmentierung: diskriminierender Softmax-Klassifikator
Die meisten davon Die aktuellen gängigen Pixel-für-Pixel-Segmentierungsmodelle verwenden tiefe Netzwerke, um Pixelmerkmale zu extrahieren, und verwenden dann Softmax-Klassifizierer, um Pixelmerkmale zu klassifizieren. Seine Netzwerkarchitektur besteht aus zwei Teilen:
Der erste Teil ist Pixel-Feature-Extraktor typisch Die Architektur ist ein Encoder-Decoder-Paar, das Pixelmerkmale erhält, indem die Pixeleingabe im RGB-Raum einem D-dimensionalen hochdimensionalen Raum zugeordnet wird.
Der zweite Teil ist Pixelklassifikator, der der gängige Softmax-Klassifikator ist Pixelmerkmale werden als reale C-Klasse-Ausgabe (Logits) codiert, und dann wird die Softmax-Funktion verwendet, um die Ausgabe (Logits) zu normalisieren und die Wahrscheinlichkeitsbedeutung anzugeben, d. h. Logits werden verwendet, um die hintere Wahrscheinlichkeit der Pixelklassifizierung zu berechnen: #🎜 🎜#
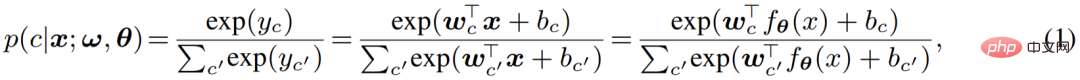
Abschließend wird das aus zwei Teilen bestehende Gesamtmodell durch Kreuzentropieverlust Ende-zu-Ende optimiert: # 🎜🎜#
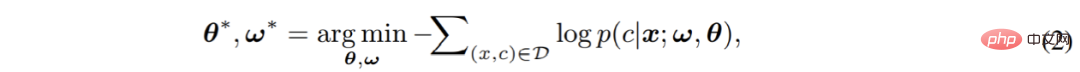
Der Diskriminanzklassifikator hat eine einfache Struktur, und da sein Optimierungsziel direkt auf die Reduzierung des Diskriminierungsfehlers abzielt, kann er häufig eine hervorragende Diskriminanzleistung erzielen. Gleichzeitig weist es jedoch einige schwerwiegende Mängel auf, die die Aufmerksamkeit bestehender Arbeiten nicht auf sich gezogen haben, was sich stark auf die Klassifizierungsleistung und die Verallgemeinerung des Softmax-Klassifikators auswirkt: #🎜🎜 # Erstens modelliert es nur die Entscheidungsgrenze; es ignoriert vollständig die Verteilung von Pixelmerkmalen und kann daher die spezifischen Merkmale jeder Kategorie nicht modellieren und nutzen, wodurch ihre Verallgemeinerungs- und Ausdrucksfähigkeiten geschwächt werden.
Zweitens wird ein einzelnes Parameterpaar (w
,b) verwendet, um eine Klasse zu modellieren auf einem einzelnen Parameterpaar (- w
- ,b) Die Annahme einer modularen Verteilung (Unimodalität) trifft in praktischen Anwendungen oft nicht zu, was nur zu einer suboptimalen Leistung führt.
- Schließlich kann die Ausgabe des Softmax-Klassifikators die wahre Wahrscheinlichkeitsbedeutung nicht genau widerspiegeln; seine endgültige Vorhersage kann nur als Referenz beim Vergleich mit anderen Kategorien verwendet werden. Dies ist auch der Hauptgrund, warum es für viele gängige Segmentierungsmodelle schwierig ist, OOD-Eingaben zu erkennen. Als Reaktion auf diese Probleme ist der Autor der Ansicht, dass das aktuelle Mainstream-Diskriminanzparadigma überdacht werden sollte, und die entsprechende Lösung wird in diesem Artikel gegeben: Generieren Formelsemantisches Segmentierungsmodell – GMMSeg.
- Generatives semantisches Segmentierungsmodell: GMMSeg
Der Autor hat den semantischen Segmentierungsprozess aus der Perspektive eines generativen Modells neu organisiert. Im Vergleich zur direkten Modellierung der Klassifizierungswahrscheinlichkeit p (c|x) modelliert der generative Klassifikator die gemeinsame Verteilung p (
x, c) und leitet dann mithilfe des Baye-Theorems die Klassifizierungswahrscheinlichkeit ab :
Unter diesen wird aus Verallgemeinerungsgründen die Kategorie vor p (c) häufig als Gleichverteilung festgelegt und wie man die kategoriebedingte Verteilung p (x
|c) von Pixelmerkmalen modelliert, ist zum aktuellen Hauptproblem geworden.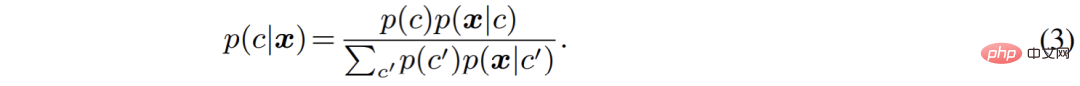
In diesem Artikel wird in GMMSeg ein Gaußsches Mischungsmodell verwendet, um p (x|c) zu modellieren die folgende Form:
Wenn die Anzahl der Komponenten nicht begrenzt ist, kann das Gaußsche Mischungsmodell theoretisch beliebig angepasst werden Die Verteilung ist daher sehr elegant und leistungsstark. Gleichzeitig macht die Natur ihres Hybridmodells auch die Modellierung von Multimodalität (Multimodalität), dh der Modellierung von Variationen innerhalb der Klasse, möglich. Auf dieser Grundlage verwendet dieser Artikel die Maximum-Likelihood-Schätzung, um die Parameter des Modells zu optimieren:
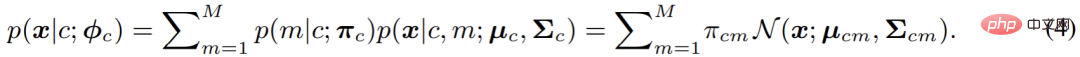
Die klassische Lösung ist EM-Algorithmus, d. h. durch abwechselndes Ausführen von E-M – zweistufige schrittweise Optimierung der F-Funktion:
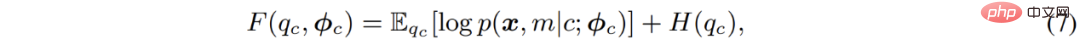
Speziell für die Optimierung von Gaußschen Mischungsmodellen bewertet der EM-Algorithmus tatsächlich die Wahrscheinlichkeit von Datenpunkten, die zu jedem Untermodell im E-Schritt gehören . Neu schätzen. Mit anderen Worten: Es entspricht der Durchführung von Soft-Clustering für Pixel im E-Schritt. Anschließend können die Clustering-Ergebnisse im M-Schritt verwendet werden, um die Modellparameter erneut zu aktualisieren.
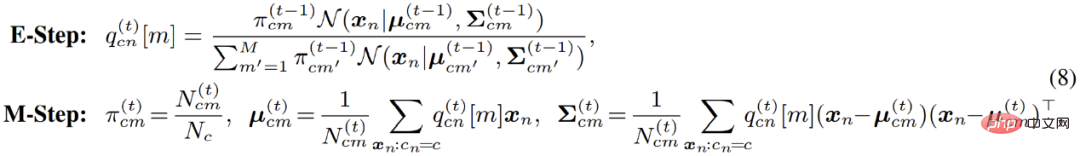
In praktischen Anwendungen stellte der Autor jedoch fest, dass der Standard-EM-Algorithmus langsam konvergierte und die Endergebnisse schlecht waren . Der Autor vermutet, dass der EM-Algorithmus zu empfindlich auf die Anfangswerte der Parameteroptimierung reagiert, was die Konvergenz zu einem besseren lokalen Extrempunkt erschwert. Inspiriert durch eine Reihe aktueller Clustering-Algorithmen, die auf der Theorie des optimalen Transports basieren, führt der Autor eine zusätzliche Uniform vor der Mischungsmodellverteilung ein:
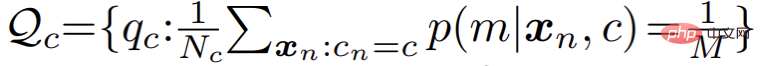
Entsprechend wird der E-Schritt im Parameteroptimierungsprozess wie folgt in ein eingeschränktes Optimierungsproblem umgewandelt:
#🎜 🎜##🎜🎜 #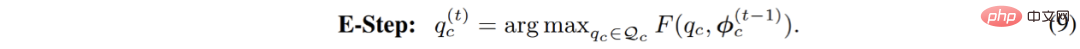 Dieser Prozess kann intuitiv so verstanden werden, dass er eine Gleichverteilungsbeschränkung für den Clustering-Prozess einführt: Während des Clustering-Prozesses können die Datenpunkte gleichmäßig auf jedes Untermodell verteilt werden. Nach Einführung dieser Einschränkung entspricht dieser Optimierungsprozess dem in der folgenden Formel aufgeführten Problem der optimalen Übertragung: Diese Gleichung kann mit dem Sinkhorn-Knopp-Algorithmus schnell gelöst werden. Der gesamte verbesserte Optimierungsprozess trägt den Namen Sinkhorn EM. Einige theoretische Arbeiten haben gezeigt, dass er dieselbe globale optimale Lösung wie der Standard-EM-Algorithmus hat und weniger wahrscheinlich in die lokale optimale Lösung fällt.
Dieser Prozess kann intuitiv so verstanden werden, dass er eine Gleichverteilungsbeschränkung für den Clustering-Prozess einführt: Während des Clustering-Prozesses können die Datenpunkte gleichmäßig auf jedes Untermodell verteilt werden. Nach Einführung dieser Einschränkung entspricht dieser Optimierungsprozess dem in der folgenden Formel aufgeführten Problem der optimalen Übertragung: Diese Gleichung kann mit dem Sinkhorn-Knopp-Algorithmus schnell gelöst werden. Der gesamte verbesserte Optimierungsprozess trägt den Namen Sinkhorn EM. Einige theoretische Arbeiten haben gezeigt, dass er dieselbe globale optimale Lösung wie der Standard-EM-Algorithmus hat und weniger wahrscheinlich in die lokale optimale Lösung fällt.
Online-Hybrid-Optimierung
Danach wurde während des gesamten Optimierungsprozesses ein Online-Hybrid im Artikel-Hybrid-Optimierungsmodus verwendet: durch Generatives Sinkhorn EM, der Gaußsche Mischungsklassifikator, wird kontinuierlich im schrittweise aktualisierten Merkmalsraum optimiert, während er für einen anderen Teil des gesamten Frameworks, den Pixel-Feature-Extraktor-Teil, auf der generativen Klassifizierung basiert. Die Vorhersageergebnisse der Maschine werden mithilfe von diskriminierendem Kreuz optimiert -Entropieverlust. Die beiden Teile werden abwechselnd optimiert und aneinander ausgerichtet, wodurch das gesamte Modell eng gekoppelt und für ein End-to-End-Training geeignet ist: #In diesem Prozess wird der Merkmalsextraktionsteil nur durch Gradienten-Backpropagation optimiert, während dies für den generativen Klassifikatorteil der Fall ist nur optimiert durch SinkhornEM. Es ist dieses alternierende Optimierungsdesign, das es ermöglicht, das gesamte Modell kompakt zu integrieren und die Vorteile der diskriminierenden und generativen Modelle zu übernehmen. 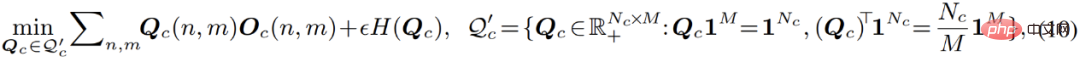
Letztendlich profitiert GMMSeg von seiner generativen Klassifizierungsarchitektur und seiner Online-Hybrid-Trainingsstrategie, um die diskriminierenden Leistungsvorteile des Softmax zu demonstrieren Klassifikator hat nicht:
- Erstens ist GMMSeg aufgrund seiner universellen Architektur mit den meisten gängigen Segmentierungsmodellen kompatibel, dh mit Modellen, die Softmax zur Klassifizierung verwenden: Nur der diskriminierende Softmax-Klassifikator muss ersetzt werden , wodurch die Leistung bestehender Modelle problemlos verbessert werden kann.
- Zweitens kombiniert GMMSeg durch die Anwendung des Hybrid-Trainingsmodus die Vorteile generativer und diskriminierender Klassifikatoren und löst bis zu einem gewissen Grad das Problem, dass Softmax keine Klassen modellieren kann Das Problem interner Veränderungen verbessert seine Unterscheidungsleistung erheblich.
- Drittens modelliert GMMSeg explizit die Verteilung von Pixelmerkmalen, das heißt, p (x|c); kann GMMSeg direkt angeben Die Wahrscheinlichkeit Die Zugehörigkeit einer Stichprobe zu jeder Kategorie ermöglicht den natürlichen Umgang mit unsichtbaren OOD-Daten.
Experimentelle Ergebnisse
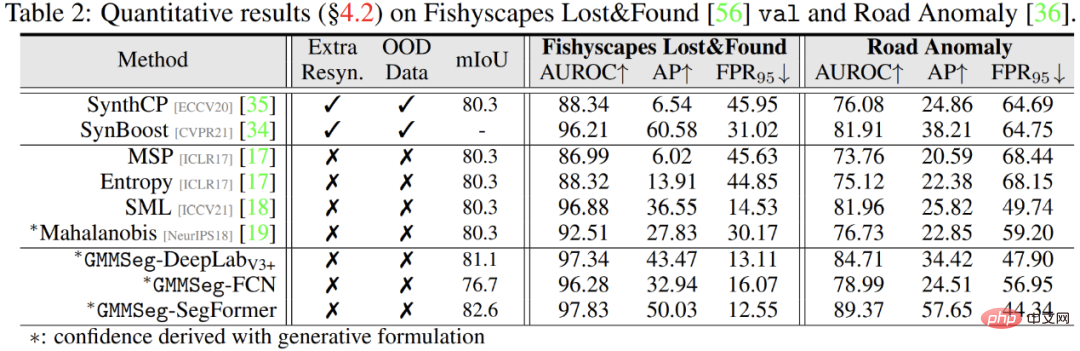
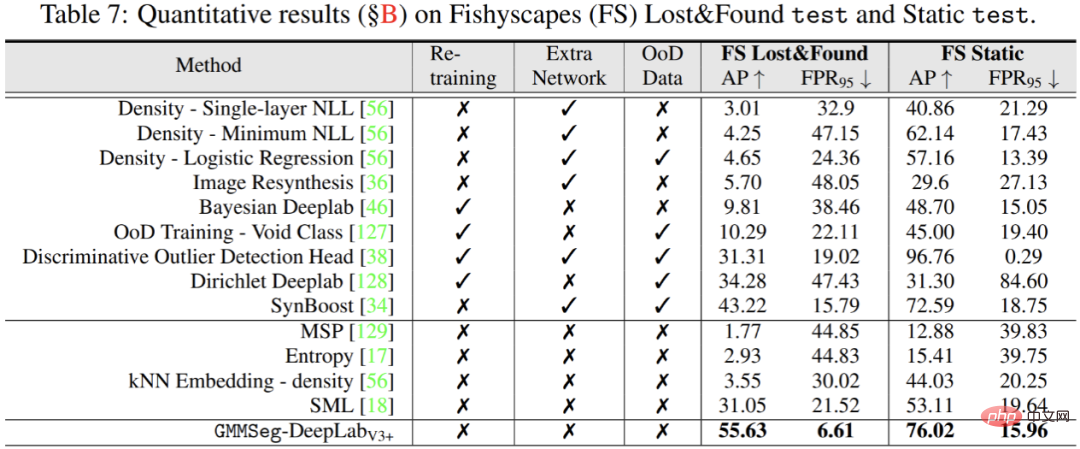
Die experimentellen Ergebnisse zeigen, dass die weit verbreitete Semantik unabhängig davon ist, ob sie auf der CNN-Architektur oder der Transformer-Architektur basiert Bei segmentierten Datensätzen (ADE20K, Cityscapes, COCO-Stuff) kann GMMSeg stabile und offensichtliche Leistungsverbesserungen erzielen.
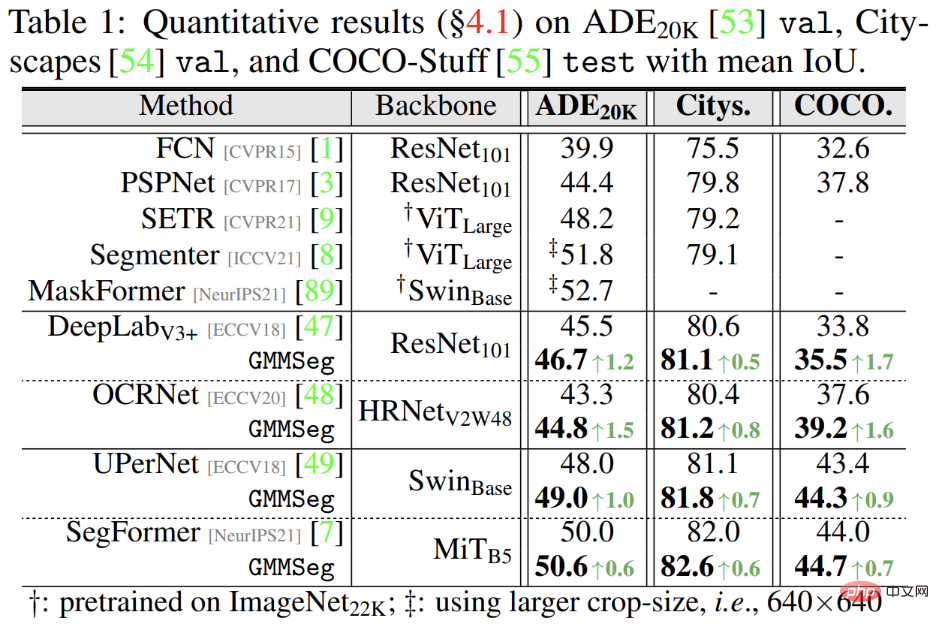

Außerdem in der Ausnahmesegmentierungsaufgabe, ohne Jede Änderung des in der Closed-Set-Aufgabe trainierten Modells, also der herkömmlichen semantischen Segmentierungsaufgabe, kann GMMSeg andere Methoden übertreffen, die eine spezielle Nachbearbeitung in allen gängigen Bewertungsindikatoren erfordern.

# 🎜 🎜#
Das obige ist der detaillierte Inhalt vonGMMSeg, ein neues Paradigma der generativen semantischen Segmentierung, kann sowohl die Erkennung geschlossener als auch offener Mengen verarbeiten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr