
Heim >Technologie-Peripheriegeräte >KI >Umfassender Vergleich von vier „ChatGPT-Such'-Modellen! Handkommentiert von einem chinesischen Arzt aus Stanford: New Bing spricht am wenigsten fließend und fast die Hälfte der Sätze wird nicht zitiert.
Umfassender Vergleich von vier „ChatGPT-Such'-Modellen! Handkommentiert von einem chinesischen Arzt aus Stanford: New Bing spricht am wenigsten fließend und fast die Hälfte der Sätze wird nicht zitiert.

- 王林nach vorne
- 2023-05-01 23:28:09965Durchsuche
Kurz nach der Veröffentlichung von ChatGPT startete Microsoft erfolgreich das „Neue Bing“. Nicht nur, dass sein Aktienkurs stark anstieg, es drohte sogar, Google zu ersetzen und eine neue Ära der Suchmaschinen einzuläuten.
Aber ist New Bing wirklich die richtige Art, ein großes Sprachmodell zu spielen? Sind die generierten Antworten für Benutzer tatsächlich nützlich? Wie glaubwürdig ist das Zitat im Satz?
Kürzlich haben Stanford-Forscher eine große Anzahl von Benutzeranfragen aus verschiedenen Quellen gesammelt und künstliche Suchen in vier beliebten generativen Suchmaschinen durchgeführt: Bing Chat, NeevaAI, perplexity.ai und YouChat Evaluate.
... und ungenaue Zitate.
Im Durchschnitt können nur 51,5 % der Zitate die generierten Sätze vollständig stützen und nur 74,5 % der Zitate können als Beweismittel für die relevanten Sätze verwendet werden. Die Forscher glauben, dass dieses Ergebnis für Systeme, die zum Hauptwerkzeug für informationssuchende Benutzer werden könnten, zu niedrig ist, insbesondere angesichts der Tatsache, dass einige Sätze nur plausibel sind und generative Suchmaschinen noch weiter optimiert werden müssen.
Persönliche Homepage: https://cs.stanford.edu/~nfliu/
Der Erstautor Nelson Liu ist Doktorand im vierten Jahr in der Natural Language Processing Group der Stanford University , und sein Betreuer ist Percy Liang, der einen Bachelor-Abschluss von der University of Washington hat. Seine Hauptforschungsrichtung ist der Aufbau praktischer NLP-Systeme, insbesondere Anwendungen für die Informationssuche.

Im März 2023 berichtete Microsoft, dass „ungefähr ein Drittel der Daily Preview-Benutzer täglich [Bing] Chat verwenden“ und dass Bing Chat in seiner ersten öffentlichen Vorschau verfügbar war 45 Millionen Chats pro Monat Mit anderen Worten: Die Integration großer Sprachmodelle in Suchmaschinen ist sehr marktfähig und wird mit hoher Wahrscheinlichkeit den Suchzugang zum Internet verändern.
Aber derzeit haben die bestehenden generativen Suchmaschinen, die auf der Technologie großer Sprachmodelle basieren, immer noch das Problem der geringen Genauigkeit, aber die spezifische Genauigkeit wurde noch nicht vollständig bewertet, und es ist unmöglich, die Grenzen neuer zu verstehen Suchmaschinen.
Überprüfbarkeit
ist der Schlüssel zur Verbesserung der Glaubwürdigkeit von Suchmaschinen, d der Genauigkeit.
Die Forscher führten eine manuelle Auswertung bei vier kommerziellen generativen Suchmaschinen (Bing Chat, NeevaAI, perplexity.ai, YouChat) durch, indem sie Fragen verschiedener Typen und Quellen sammelten.
Bewertungsindikatoren umfassen hauptsächlich
Flüssigkeit, also ob der generierte Text kohärent ist, also ob die Antwort der Suchmaschine für den Benutzer hilfreich ist, und die Inhalt der Antwort Ob die Informationen das Problem lösen können; 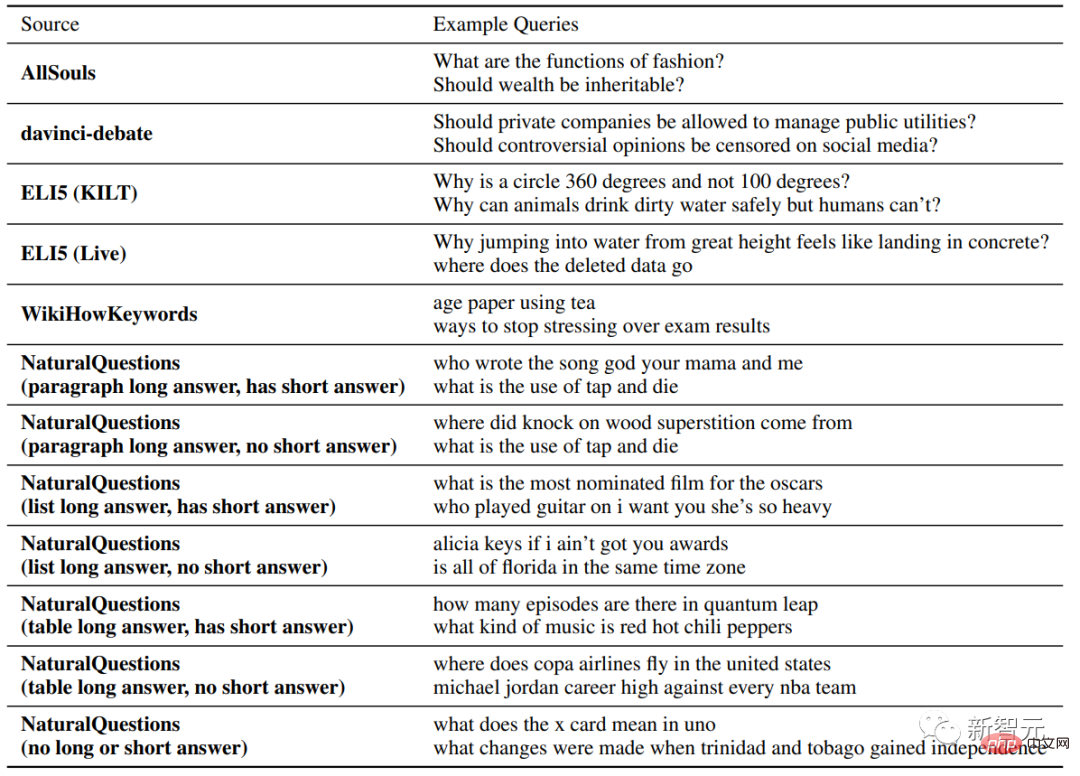 Citation Recall
Citation Recall
Citation Precision
, d verwandte Sätze.
fluency
Zeigt außerdem die Benutzeranfrage, die generierte Antwort und die Aussage „Diese Antwort“ an fließend und semantisch kohärent.“ Die Kommentatoren bewerteten die Daten auf einer fünfstufigen Likert-Skala.
Nützlichkeit (wahrgenommener Nutzen)
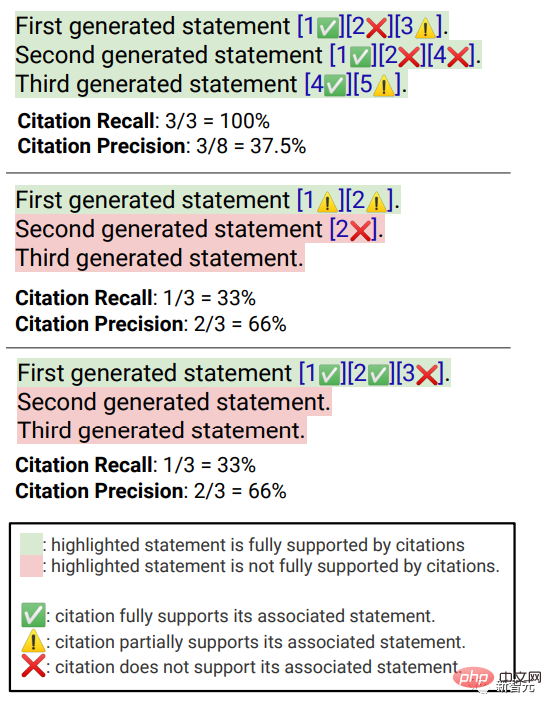
# 🎜🎜#Ähnlich wie bei Sprachkompetenz müssen Annotatoren ihre Zustimmung zu der Aussage bewerten, dass die Antwort nützlich und informativ für die Anfrage des Benutzers ist. Zitiererinnerung Bezieht sich auf den Anteil der verifizierungswürdigen Sätze, die vollständig durch ihre relevanten Zitate gestützt werden. Die Berechnung dieses Indikators erfordert daher die Identifizierung der verifizierungswürdigen Sätze in den Antworten und die Beurteilung, ob jeder verifizierungswürdige Satz durch relevante Zitate gestützt werden kann Zitate.
Im Prozess der „Identifizierung von Sätzen, die es wert sind, überprüft zu werden“
, glauben die Forscher Jeder generierte Satz über die Außenwelt ist einer Überprüfung wert, selbst diejenigen, die für den gesunden Menschenverstand offensichtlich und trivial erscheinen, denn was für manche Leser als offensichtlicher „gesunder Menschenverstand“ erscheinen mag, ist möglicherweise nicht tatsächlich richtig.Das Ziel eines Suchmaschinensystems sollte darin bestehen, eine Referenzquelle für alle generierten Sätze über die Außenwelt bereitzustellen, damit die Leser jede Erzählung in der generierten Antwort leicht überprüfen können , Überprüfbarkeit darf nicht der Einfachheit halber geopfert werden.
Die Annotatoren überprüfen also tatsächlich alle generierten Sätze, mit Ausnahme der Antworten, bei denen das System die erste Person ist, wie zum Beispiel „Als Sprachmodell habe ich keine.“ Fähigkeit Do..." oder Fragen an Benutzer, wie zum Beispiel „Möchten Sie mehr wissen?" usw. Beurteilen Sie
„Ob eine verifizierungswürdige Aussage durch ihre relevanten Zitate ausreichend gestützt wird“kann basierend auf Identifiziert zugeordnet werden Quelle (AIS, auf identifizierte Quellen zurückzuführen) Bewertungsrahmen, der Annotator führt eine binäre Annotation durch, das heißt, wenn ein normales Publikum zustimmt, dass „basierend auf der zitierten Webseite eine Schlussfolgerung gezogen werden kann ...“, dann Zitat kann vollständig unterstützt werden Die Antwort.
Zitierbarkeit # Um die Genauigkeit von Zitaten zu messen, müssen Kommentatoren beurteilen, ob jedes Zitat den zugehörigen Satz vollständig, teilweise oder irrelevant unterstützt. Volle Unterstützung : Alle Informationen im Satz werden durch das Zitat gestützt.
Teilweise Unterstützung : Einige Informationen im Satz werden durch das Zitat gestützt, andere Teile können jedoch fehlen oder widersprüchlich sein.
Irrelevanter Support (Kein Support) : Wenn die referenzierte Webseite völlig irrelevant oder widersprüchlich ist.
Bei Sätzen mit mehreren relevanten Zitaten müssen Annotatoren zusätzlich das AIS-Bewertungsframework verwenden, um festzustellen, ob alle relevanten Zitationswebseiten insgesamt ausreichende Informationen bieten der Satz. Unterstützung (binäres Urteil).
Experimentelle ErgebnisseIn der Bewertung der Sprachkompetenz und Nützlichkeit zeigt sich, dass jede Suchmaschine in der Lage ist, sehr reibungslose und nützliche Antworten zu generieren .
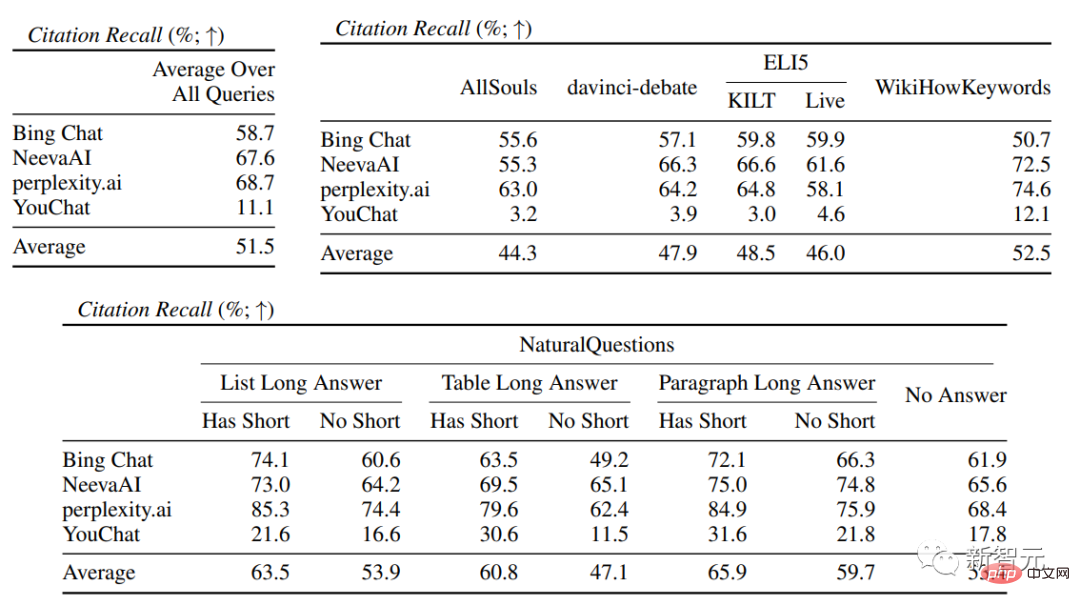
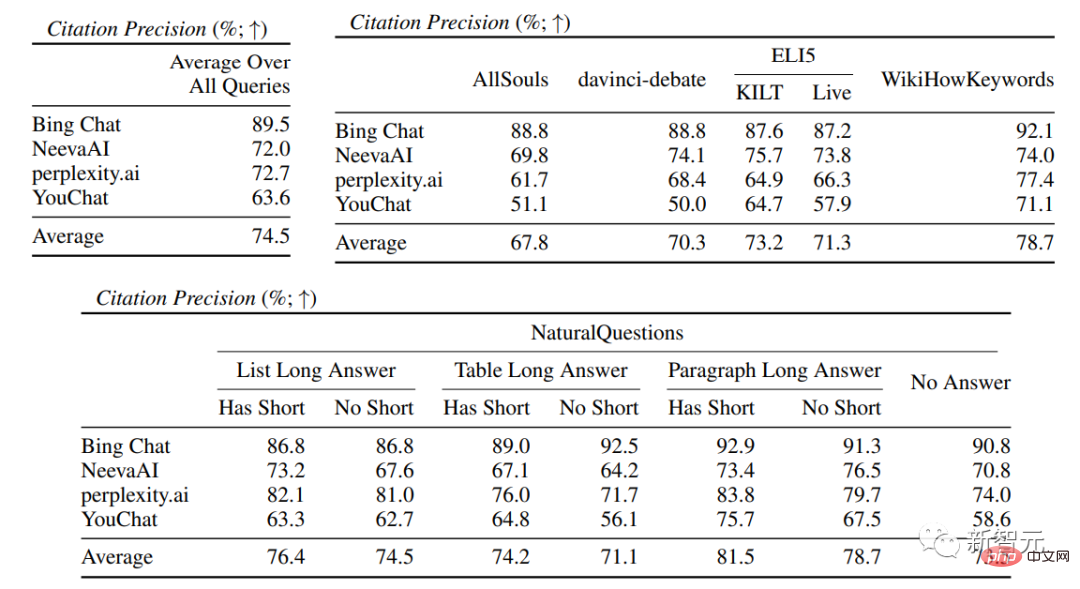
In der spezifischen Suchmaschinenauswertung können Sie Bing Chat sehen niedrigste Sprachkompetenz-/Nützlichkeitsbewertung (4,40/4,34), gefolgt von NeevaAI (4,43/4,48), perplexity.ai (4,51/4,56) und YouChat (4,59/4,62). In verschiedenen Kategorien von Benutzeranfragen ist zu erkennen, dass kürzere extraktive Fragen normalerweise flüssiger sind als lange Fragen und normalerweise nur Sachwissen beantworten erfordern die Aggregation verschiedener Tabellen oder Webseiten, und der Syntheseprozess verringert die Gesamtkompetenz. In der Zitationsauswertung zeigt sich, dass bestehende generative Suchmaschinen Webseiten häufig nicht vollständig oder korrekt zitieren, wobei nur 51,5 % der generierten Sätze zitiert werden Durchschnittlich unterstützen nur 74,5 % der Zitate die zugehörigen Sätze vollständig (Präzision). Dieser Wert ist für diejenigen, die bereits Millionen haben ist für das Suchmaschinensystem des Benutzers inakzeptabel, insbesondere wenn die generierten Antworten relativ informativ sind. und Es gibt große Unterschiede in der Zitiererinnerung und Präzision zwischen verschiedenen generativen Suchmaschinen, die von perplexity.ai implementiert wird, weist die höchste Erinnerungsrate auf (68,7), während NeevaAI (67,6), Bing Chat (58,7) und YouChat (11,1) niedriger sind. Andererseits erreichte Bing Chat die höchste Genauigkeit (89,5) , gefolgt von perplexity.ai (72,7), NeevaAI ( 72,0) und YouChat (63,6). Die Zitiererinnerungsrate zwischen ihnen liegt bei nahezu 11 % (58,5 bzw. 47,8); Kurze Antwort Die Zitationserinnerungslücke zwischen der NaturalQuestions-Abfrage Zitierraten werden bei Fragen ohne Web-Unterstützung niedriger sein, beispielsweise bei der Bewertung offener AllSouls-Aufsatzfragen, der generativen Suchmaschine Die Zitiererinnerungsrate beträgt nur 44,3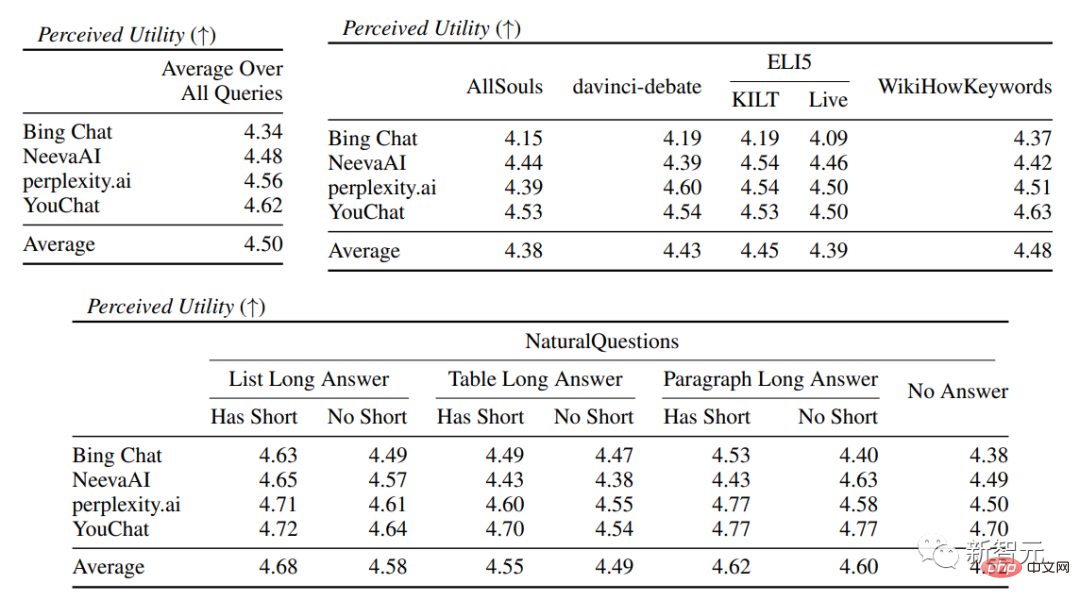
Das obige ist der detaillierte Inhalt vonUmfassender Vergleich von vier „ChatGPT-Such'-Modellen! Handkommentiert von einem chinesischen Arzt aus Stanford: New Bing spricht am wenigsten fließend und fast die Hälfte der Sätze wird nicht zitiert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr