
Heim >Technologie-Peripheriegeräte >KI >Möchten Sie die Hälfte von „A Dream of Red Mansions' in das ChatGPT-Eingabefeld verschieben? Lassen Sie uns zunächst dieses Problem lösen
Möchten Sie die Hälfte von „A Dream of Red Mansions' in das ChatGPT-Eingabefeld verschieben? Lassen Sie uns zunächst dieses Problem lösen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-01 21:01:05925Durchsuche

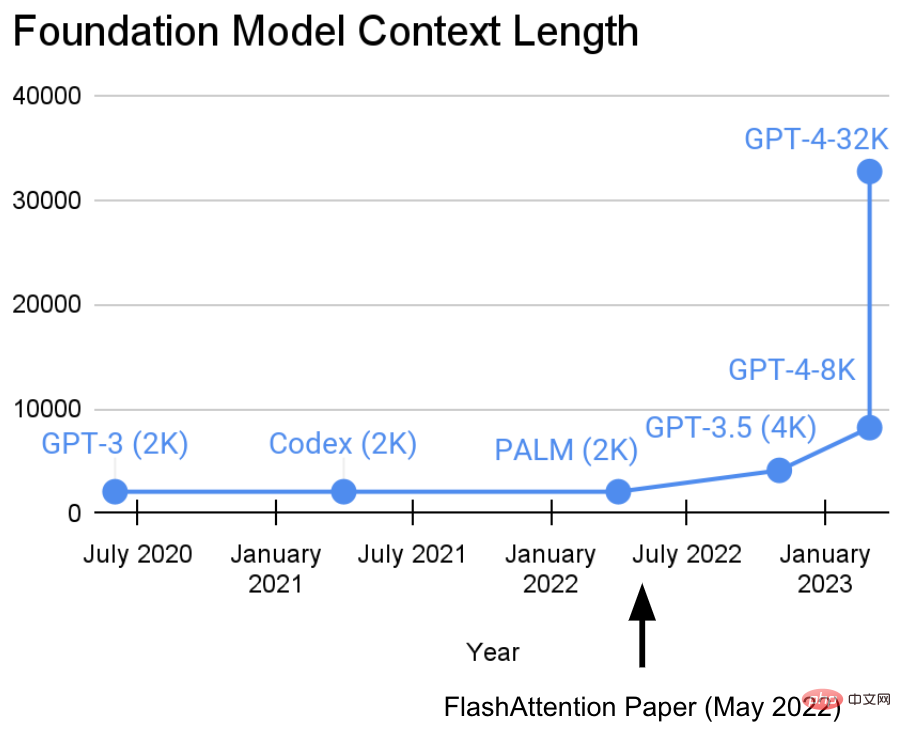
In den letzten zwei Jahren war das Hazy Research Laboratory an der Stanford University mit einer wichtigen Arbeit beschäftigt: Erhöhung der Sequenzlänge.
Sie haben eine Ansicht: Längere Sequenzen werden eine neue Ära grundlegender Modelle für maschinelles Lernen einläuten – Modelle, die aus längeren Kontexten, mehreren Medienquellen, komplexen Demonstrationen usw. lernen können.Derzeit hat diese Forschung neue Fortschritte gemacht. Tri Dao und Dan Fu vom Hazy Research-Labor leiteten die Forschung und Förderung des FlashAttention-Algorithmus. Sie haben bewiesen, dass eine Sequenzlänge von 32 KB möglich ist und in der aktuellen Basismodellära weit verbreitet sein wird (OpenAI, Microsoft, NVIDIA und andere Unternehmen). Modelle verwenden den FlashAttention-Algorithmus).
- Papieradresse: https://arxiv.org/abs/2205.14135
- Codeadresse: https://github.com/HazyResearch/flash-attention
In diesem Artikel stellt der Autor neue Methoden zur Erhöhung der Sequenzlänge auf hoher Ebene vor und bietet eine „Brücke“ zu einem neuen Satz von Grundelementen.
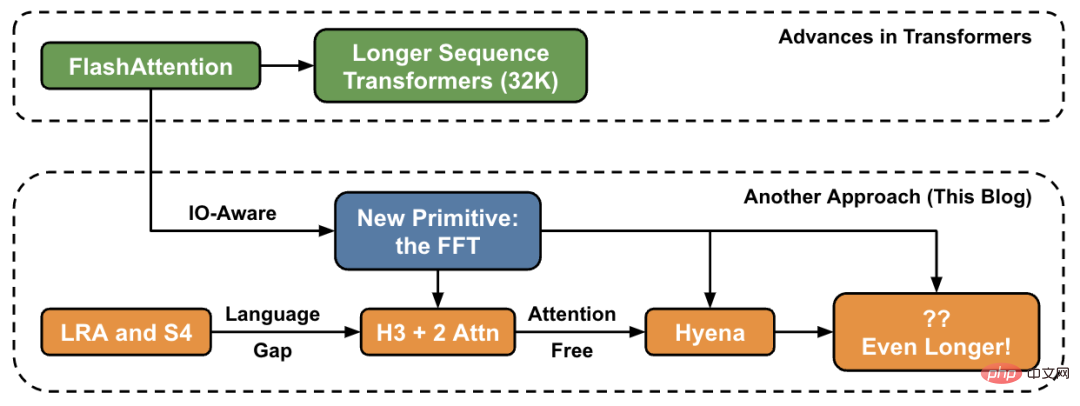
Im Hazy Research-Labor begann diese Arbeit mit Hippo, dann S4, H3 und jetzt Hyena. Diese Modelle haben das Potenzial, Kontextlängen im Millionen- oder sogar Milliardenbereich zu verarbeiten.
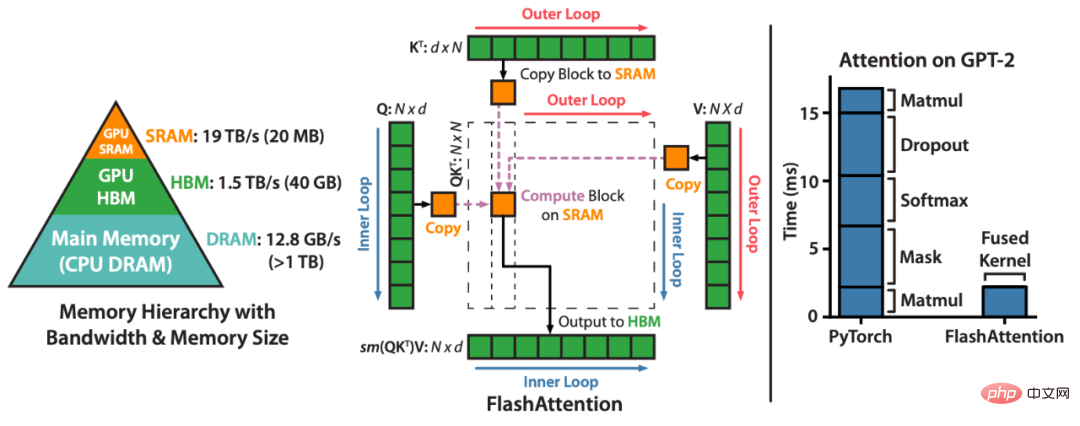
FlashAttention beschleunigt die Aufmerksamkeit und reduziert den Speicherbedarf – ohne jede Annäherung. „Seit wir FlashAttention vor sechs Monaten veröffentlicht haben, freuen wir uns, dass viele Organisationen und Forschungslabore FlashAttention übernehmen, um ihre Schulung und Inferenz zu beschleunigen“, heißt es im Blogbeitrag.FlashAttention ist ein Algorithmus, der Aufmerksamkeitsberechnungen neu ordnet und klassische Techniken (Kacheln, Neuberechnen) nutzt, um die Speichernutzung zu beschleunigen und von quadratisch auf linear in der Sequenzlänge zu reduzieren. Um die Lese-/Schreibvorgänge im Speicher zu reduzieren, nutzt FlashAttention für jeden Aufmerksamkeitskopf klassische Kacheltechniken, um Abfrage-, Schlüssel- und Werteblöcke vom GPU-HBM (dem Hauptspeicher) in den SRAM (den schnellen Cache) zu laden, die Aufmerksamkeit zu berechnen und die Ausgabe zurückzuschreiben HBM. Diese Reduzierung der Lese-/Schreibvorgänge im Speicher führt in den meisten Fällen zu erheblichen Geschwindigkeitssteigerungen (2- bis 4-fach).
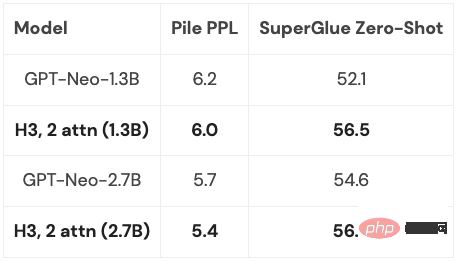
Forscher bei Google haben 2020 den Long Range Arena (LRA) Benchmark eingeführt, um zu bewerten, wie gut verschiedene Modelle mit Fernabhängigkeiten umgehen. LRA ist in der Lage, eine Reihe von Aufgaben zu testen, die viele verschiedene Datentypen und -modalitäten wie Text, Bilder und mathematische Ausdrücke mit Sequenzlängen von bis zu 16 KB abdecken (Pfad-X: Klassifizierung von in Pixel entfalteten Bildern ohne räumliche Generalisierungsverzerrung). Es wurde viel daran gearbeitet, Transformers auf längere Sequenzen zu skalieren, aber vieles davon scheint auf Kosten der Genauigkeit zu gehen (wie im Bild unten gezeigt). Beachten Sie die Path-X-Spalte: Alle Transformer-Methoden und ihre Varianten schneiden noch schlechter ab als zufällige Schätzungen. Jetzt lernen wir den S4 kennen, der unter der Leitung von Albert Gu entwickelt wurde. Inspiriert von den LRA-Benchmark-Ergebnissen wollte Albert Gu herausfinden, wie langfristige Abhängigkeiten besser modelliert werden können. Basierend auf langfristigen Untersuchungen zur Beziehung zwischen orthogonalen Polynomen und rekursiven Modellen und Faltungsmodellen startete er S4 – ein neues Sequenzmodell basierend auf strukturierten Zustandsraummodellen (SSMs). Der entscheidende Punkt ist, dass die zeitliche Komplexität von SSM bei der Erweiterung einer Sequenz der Länge N auf 2N Außerdem war es bereits möglich, die Sequenzlänge von Transformer zu erhöhen, als Hazy Research FlashAttention veröffentlichte. Sie fanden außerdem heraus, dass Transformer auch auf Path-X eine überlegene Leistung (63 %) erzielte, indem einfach die Sequenzlänge auf 16 KB erhöht wurde. Aber die Lücke in der Qualität von S4 bei der Sprachmodellierung beträgt bis zu 5 % (im Kontext ist dies die Lücke zwischen dem 125M-Modell und dem 6,7B-Modell). Um diese Lücke zu schließen, haben Forscher synthetische Sprachen wie den assoziativen Rückruf untersucht, um zu bestimmen, welche Eigenschaften eine Sprache besitzen sollte. Das endgültige Design war H3 (Hungry Hungry Hippos): eine neue Schicht, die zwei SSMs stapelt und ihre Ausgänge mit einem Multiplikationsgatter multipliziert. Mit H3 ersetzten die Forscher von Hazy Research nahezu alle Aufmerksamkeitsschichten in einem Transformer im GPT-Stil und konnten beim Training mit 400B-Tokens von Pile den Transformer in Bezug auf Verwirrung und nachgelagerte Auswertung erreichen. Long Range Arena Benchmark und S4
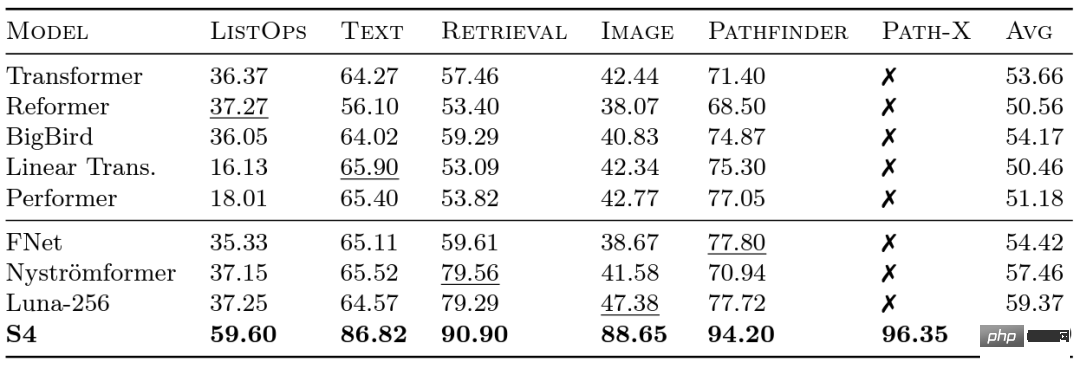
 beträgt, im Gegensatz zum Aufmerksamkeitsmechanismus, der auf quadratischer Ebene zunimmt! S4 modelliert erfolgreich langfristige Abhängigkeiten in LRA und erreicht als erstes Modell eine überdurchschnittliche Leistung auf Path-X (jetzt erreicht es eine Genauigkeit von 96,4 %!). Seit der Veröffentlichung von S4 haben viele Forscher auf dieser Grundlage neue Modelle entwickelt und innoviert, wie das S5-Modell von Scott Lindermans Team, Ankit Guptas DSS (und das nachfolgende S4D von Hazy Research Laboratory), Hasani und Lechners Liquid-S4, usw. Modell.
beträgt, im Gegensatz zum Aufmerksamkeitsmechanismus, der auf quadratischer Ebene zunimmt! S4 modelliert erfolgreich langfristige Abhängigkeiten in LRA und erreicht als erstes Modell eine überdurchschnittliche Leistung auf Path-X (jetzt erreicht es eine Genauigkeit von 96,4 %!). Seit der Veröffentlichung von S4 haben viele Forscher auf dieser Grundlage neue Modelle entwickelt und innoviert, wie das S5-Modell von Scott Lindermans Team, Ankit Guptas DSS (und das nachfolgende S4D von Hazy Research Laboratory), Hasani und Lechners Liquid-S4, usw. Modell. Mängel bei der Modellierung
Da die H3-Schicht auf SSM aufbaut, wächst auch ihre Rechenkomplexität in Bezug auf die Sequenzlänge mit einer Rate von  . Die beiden Aufmerksamkeitsebenen machen die Komplexität des gesamten Modells noch
. Die beiden Aufmerksamkeitsebenen machen die Komplexität des gesamten Modells noch
 Auf dieses Problem wird später noch näher eingegangen.
Auf dieses Problem wird später noch näher eingegangen.
Natürlich ist Hazy Research nicht der einzige, der diese Richtung in Betracht zieht: GSS hat auch herausgefunden, dass SSM mit Gates gut mit Aufmerksamkeit in der Sprachmodellierung funktionieren kann (dies inspirierte H3), Meta veröffentlichte das Mega-Modell, es kombiniert auch SSM und Aufmerksamkeit, Das BiGS-Modell ersetzt die Aufmerksamkeit im BERT-Modell, und RWKV hat an einem vollständig Schleifenansatz gearbeitet.
Neuer Fortschritt: Hyena
Basierend auf einer Reihe früherer Arbeiten wurden Forscher von Hazy Research dazu inspiriert, eine neue Architektur zu entwickeln: Hyena. Sie haben versucht, die letzten beiden Aufmerksamkeitsschichten in H3 loszuwerden und ein Modell zu erhalten, das für längere Sequenzlängen nahezu linear wächst. Es stellt sich heraus, dass zwei einfache Ideen der Schlüssel zur Antwort sind:
- Jedes SSM kann als Faltungsfilter mit der gleichen Länge wie die Eingabesequenz betrachtet werden. Daher kann der SSM durch eine Faltung mit einer Größe ersetzt werden, die der Eingabesequenz entspricht, um mit demselben Rechenaufwand ein leistungsfähigeres Modell zu erhalten. Insbesondere wird der Faltungsfilter implizit über ein weiteres kleines neuronales Netzwerk parametrisiert, wobei leistungsstarke Methoden aus der Literatur zu neuronalen Feldern und Arbeiten zu CKConv/FlexConv zum Einsatz kommen. Darüber hinaus kann die Faltung in O (NlogN) Zeit berechnet werden, wobei N die Sequenzlänge ist, wodurch eine nahezu lineare Skalierung erreicht wird; das Gating-Verhalten in
- H3 lässt sich wie folgt zusammenfassen: H3 nimmt drei Projektionen der Eingabe und zwar iterativ Führen Sie Faltungen durch und wenden Sie Gating an. Bei Hyena hilft das einfache Hinzufügen weiterer Vorsprünge und Tore dabei, auf ausdrucksstärkere Architekturen zu verallgemeinern und die Lücke durch Aufmerksamkeit zu schließen.
Hyena schlug erstmals ein vollständig nahezu lineares zeitliches Faltungsmodell vor, das in Bezug auf Ratlosigkeit und nachgelagerte Aufgaben mit Transformer mithalten kann, und erzielte in Experimenten gute Ergebnisse. Und kleine und mittelgroße Modelle wurden auf einer Teilmenge von PILE trainiert, und ihre Leistung war mit Transformer vergleichbar:
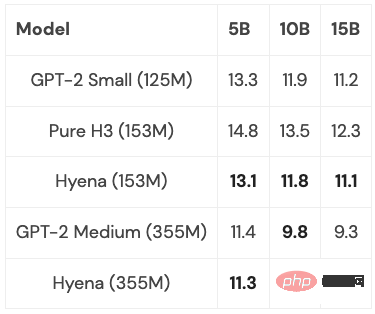
Mit einigen Optimierungen (mehr unten), wenn die Sequenzlänge 2K beträgt, Hyena Das Modell ist etwas langsamer als ein Transformer gleicher Größe, aber über längere Sequenzlängen schneller.
Als nächstes muss noch bedacht werden, inwieweit können diese Modelle verallgemeinert werden? Ist es möglich, sie auf die volle Größe von PILE (400B Token) zu skalieren? Was passiert, wenn Sie die besten Ideen von H3 und Hyena kombinieren, und wie weit können Sie gehen?
FFT oder ein einfacherer Ansatz?
In all diesen Modellen ist die FFT eine gemeinsame Grundoperation, die eine effiziente Methode zur Berechnung der Faltung darstellt und nur O (NlogN) Zeit benötigt. Allerdings wird FFT auf moderner Hardware nur unzureichend unterstützt, da die vorherrschende Architektur aus spezialisierten Matrixmultiplikationseinheiten und GEMMs (z. B. Tensorkernen auf NVIDIA-GPUs) besteht.
Die Effizienzlücke kann geschlossen werden, indem die FFT als eine Reihe von Matrixmultiplikationsoperationen umgeschrieben wird. Mitglieder des Forschungsteams erreichten dieses Ziel, indem sie Schmetterlingsmatrizen verwendeten, um spärliches Training zu untersuchen. Kürzlich haben Forscher von Hazy Research diese Verbindung genutzt, um schnelle Faltungsalgorithmen wie FlashConv und FlashButterfly zu entwickeln, indem sie mithilfe der Butterfly-Zerlegung FFT-Berechnungen in eine Reihe von Matrixmultiplikationsoperationen umwandeln.
Darüber hinaus können tiefere Zusammenhänge hergestellt werden, indem auf frühere Arbeiten zurückgegriffen wird: einschließlich des Erlernens dieser Matrizen, was ebenfalls die gleiche Zeit in Anspruch nimmt, aber zusätzliche Parameter hinzufügt. Forscher haben begonnen, diesen Zusammenhang anhand einiger kleiner Datensätze zu untersuchen und haben erste Ergebnisse erzielt. Wir können deutlich sehen, was diese Verbindung bringen kann (z. B. wie man sie für Sprachmodelle geeignet macht):

Diese Erweiterung ist es wert, genauer untersucht zu werden: Diese Erweiterung lernt, welche Art von Konvertierung und Was können Sie damit tun? Was passiert, wenn Sie es auf die Sprachmodellierung anwenden?
Das sind spannende Richtungen, und was folgen wird, werden immer längere Sequenzen und neue Architekturen sein, die es uns ermöglichen, dieses neue Gebiet weiter zu erkunden. Besonderes Augenmerk müssen wir auf Anwendungen legen, die von Langsequenzmodellen profitieren können, wie z. B. hochauflösende Bildgebung, neue Datenformate, Sprachmodelle, die ganze Bücher lesen können usw. Stellen Sie sich vor, Sie geben einem Sprachmodell ein ganzes Buch zum Lesen und lassen es die Handlung zusammenfassen, oder Sie lassen ein Codegenerierungsmodell neuen Code basierend auf dem von Ihnen geschriebenen Code generieren. Es gibt so viele mögliche Szenarien und sie sind alle sehr spannend.
Das obige ist der detaillierte Inhalt vonMöchten Sie die Hälfte von „A Dream of Red Mansions' in das ChatGPT-Eingabefeld verschieben? Lassen Sie uns zunächst dieses Problem lösen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr