
Heim >Technologie-Peripheriegeräte >KI >Ingenieurspraxis eines groß angelegten Deep-Learning-Modells für Take-Away-Werbung
Ingenieurspraxis eines groß angelegten Deep-Learning-Modells für Take-Away-Werbung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-01 16:43:191128Durchsuche
Autor: Ya Jie Yingliang Chen Long und andere
Einleitung
Mit der kontinuierlichen Weiterentwicklung des Lebensmittelliefergeschäfts von Meituan hat das Team der Werbemaschine für Lebensmittellieferungen technische Untersuchungen und Übungen in mehreren Bereichen durchgeführt und auch Erfolge erzielt einige Ergebnisse Ergebnisse. Wir werden es seriell teilen und der Inhalt umfasst hauptsächlich: ① Die Praxis der groß angelegten Deep-Learning-Modellentwicklung; ④ Die Praxis des großen -Scale-Index-Erstellung und Online-Abrufdienste; ⑤ Mechanism-Engineering-Plattform-Praxis. Vor nicht allzu langer Zeit haben wir die Praxis der Business-Plattformisierung veröffentlicht (Einzelheiten finden Sie im Artikel „Exploration and Practice of Meituan Takeout Advertising Platformization“). Dieser Artikel ist der zweite in einer Reihe von Artikeln. Wir werden uns auf die Herausforderungen konzentrieren, die groß angelegte Deep-Modelle auf der Full-Link-Ebene mit sich bringen. Dabei gehen wir von zwei Aspekten aus: Online-Latenz und Offline-Effizienz und erläutern die Technik der Werbung im Großen und Ganzen Üben Sie, ich hoffe, es kann jedem etwas Hilfe oder Inspiration bringen.
1 Hintergrund
In Kerngeschäftsszenarien des Internets wie Suche, Empfehlung und Werbung (im Folgenden als Suchwerbung bezeichnet) ist die Durchführung von Data Mining und Interessenmodellierung zur Bereitstellung hochwertiger Dienste für Benutzer eine Möglichkeit geworden um die Benutzererfahrung zu verbessern. In den letzten Jahren wurden in der Branche mithilfe von Datendividenden und Hardwaretechnologiedividenden Deep-Learning-Modelle in großem Umfang implementiert. Gleichzeitig hat sich die Branche in CTR-Szenarien schrittweise von einfachen DNN zu kleinen Modellen entwickelt Modelle bis hin zu großen Einbettungsmodellen mit Billionen von Parametern oder sogar supergroßen Modellen. Der Geschäftsbereich Werbung zum Mitnehmen hat hauptsächlich den Evolutionsprozess von „LR-Flachmodell (Baummodell)“ -> „Deep-Learning-Modell“ -> „Groß angelegtes Deep-Learning-Modell“ erlebt. Der gesamte Evolutionstrend geht allmählich von einfachen Modellen, die auf künstlichen Merkmalen basieren, zu komplexen Deep-Learning-Modellen mit Daten als Kern über. Die Verwendung großer Modelle hat die Ausdrucksfähigkeit des Modells erheblich verbessert, die Angebots- und Nachfrageseite genauer aufeinander abgestimmt und mehr Möglichkeiten für die spätere Geschäftsentwicklung bereitgestellt. Da jedoch der Umfang von Modellen und Daten weiter zunimmt, stellen wir fest, dass die folgende Beziehung zwischen Effizienz und Effizienz besteht: werden immer länger. Diese „Dauer“ entspricht der Offline-Ebene, die sich in der Effizienz widerspiegelt; sie entspricht der Online-Ebene, die sich in der Latenz widerspiegelt. Und unsere Arbeit dreht sich um die Optimierung dieser „Dauer“.  2 Analyse
2 Analyse
Im Vergleich zu gewöhnlichen kleinen Modellen besteht das Kernproblem großer Modelle darin, dass mit zunehmender Datenmenge und Modellmaßstab die Speicherung, Kommunikation, Berechnung usw. um das Dutzende oder sogar Hundertfache ansteigen Die Gesamtverbindung wird vor neuen Herausforderungen stehen, was sich wiederum auf die Offline-Iterationseffizienz des Algorithmus auswirkt. Wie kann man eine Reihe von Problemen wie Online-Verzögerungsbeschränkungen überwinden? Analysieren wir es zunächst anhand des vollständigen Links, wie unten gezeigt:
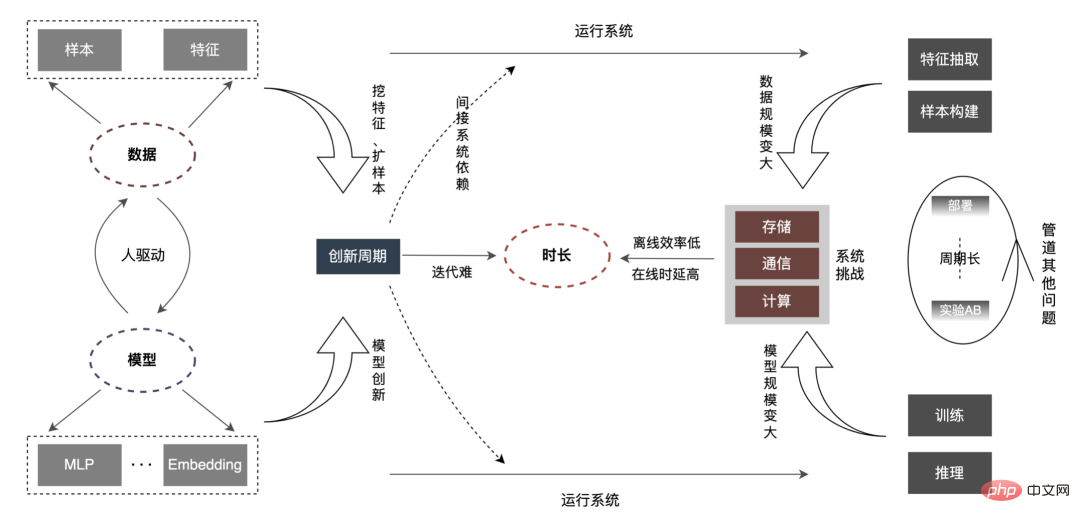 Die „Dauer“ wird länger, was sich hauptsächlich in den folgenden Aspekten widerspiegelt:
Die „Dauer“ wird länger, was sich hauptsächlich in den folgenden Aspekten widerspiegelt:
- Online-Verzögerung: Auf Feature-Ebene, wenn die Online-Anfrage unverändert bleibt, führt die Zunahme des Feature-Volumens zu besonders schwerwiegenden Problemen wie erhöhter E/A und zeitaufwändiger Feature-Berechnung, die eine Analyse und Kompilierung von Features erfordern Operatoren, Merkmalsextraktion, interne Aufgabenplanung, Netzwerk-E/A-Übertragung und andere Aspekte werden neu gestaltet. Auf Modellebene hat das Modell Änderungen von Hunderten von M/G auf Hunderte von G durchlaufen, was zu einer Erhöhung der Speicherkapazität um zwei Größenordnungen geführt hat. Darüber hinaus hat sich auch der Rechenaufwand eines einzelnen Modells um Größenordnungen erhöht (FLOPs von Millionen auf jetzt mehrere zehn Millionen). Der enorme Rechenleistungsbedarf von Building CPU+ kann nicht allein gedeckt werden GPU + hierarchischer Cache Es ist unbedingt erforderlich, eine Inferenzarchitektur zu entwickeln, um groß angelegte Deep-Learning-Inferenzen zu unterstützen. Offline-Effizienz
- : Da die Anzahl der Beispiele und Funktionen um ein Vielfaches zunimmt, verlängert sich die Zeit für die Mustererstellung und das Modelltraining erheblich und kann sogar inakzeptabel werden. Das Hauptproblem des Systems besteht darin, eine umfangreiche Probenkonstruktion und ein Modelltraining mit begrenzten Ressourcen zu lösen. Auf der Datenebene löst die Industrie das Problem im Allgemeinen auf zwei Ebenen. Einerseits optimiert sie kontinuierlich die Einschränkungen im Stapelverarbeitungsprozess. Andererseits „wandelt sie Stapel in Datenströme um, von zentralisiert zu verteilt.“ , was die Effizienz der Datenbereitstellung erheblich verbessert. Auf der Trainingsebene wird die Beschleunigung durch Hardware-GPU in Kombination mit Optimierung auf Architekturebene erreicht. Zweitens werden Algorithmeninnovationen oft von Menschen vorangetrieben. Wie können neue Daten schnell von anderen Unternehmen angewendet werden, wenn N Personen in N Geschäftsbereichen eingesetzt werden, um dieselbe Optimierung durchzuführen? Durch die Optimierung eines Geschäftsbereichs und die gleichzeitige Ausstrahlung auf N Geschäftsbereiche werden N-1-Arbeitskräfte für neue Innovationen freigesetzt, was den Innovationszyklus erheblich verkürzen wird, insbesondere wenn sich der gesamte Modellmaßstab in Zukunft ändert. Dies wird unweigerlich die Kosten für die manuelle Iteration erhöhen, eine tiefgreifende Transformation von „Menschen finden Merkmale/Modelle“ zu „Merkmale/Modelle finden Menschen“ bewirken, „wiederholte Innovationen“ reduzieren und einen intelligenten Abgleich von Modellen und Daten erreichen. Andere Probleme mit der Pipeline und inkrementelle Online-Bereitstellung; ② Die Rollback-Zeit des Modells, die Zeit, um Dinge richtig zu machen, und die Wiederherstellungszeit, nachdem Dinge falsch gemacht wurden. Kurz gesagt, es werden neue Anforderungen in den Bereichen Entwicklung, Test, Bereitstellung, Überwachung, Rollback usw. entstehen. Dieser Artikel konzentriert sich auf zwei Aspekte: Online-Latenz (
- Modellinferenz, Feature-Service), Offline-Effizienz ( Beispielkonstruktion, Datenvorbereitung
) und erklärt schrittweise die groß angelegte und tiefe Anwendung der Werbung Ingenieurpraxis an Modellen. Wir werden in den folgenden Kapiteln erläutern, wie Sie die „Dauer“ und andere damit zusammenhängende Probleme optimieren können. Bleiben Sie also auf dem Laufenden. 3 ModellinferenzAuf der Ebene der Modellinferenz hat die Werbung zum Mitnehmen drei Versionen durchlaufen, von der 1.0-Ära, dargestellt durch DNN-Modelle, die Nischenskalierung unterstützen, bis zur 2.0-Ära, die effizient ist und wenig Code erfordert Unterstützung von Multi-Business-Iterationen und dann In der heutigen 3.0-Ära besteht nach und nach eine Nachfrage nach Deep-Learning-DNN-Rechenleistung und großem Speicher. Die wichtigsten Entwicklungstrends sind in der folgenden Abbildung dargestellt:
Für große Modellinferenzszenarien sind die beiden durch die 3.0-Architektur gelösten Kernprobleme: „Speicherproblem“ und „Leistungsproblem“. Natürlich sind auch die Herausforderungen, mit denen das Projekt konfrontiert ist, die Frage, wie man für N Hundert G+-Modelle iteriert, wie man die Online-Stabilität gewährleistet, wenn die Rechenlast um ein Dutzend Mal zunimmt, wie man die Pipeline verstärkt usw. Im Folgenden konzentrieren wir uns darauf, wie die Model Inference 3.0-Architektur große Modellspeicherprobleme durch „Verteilung“ löst und wie Leistungs- und Durchsatzprobleme durch CPU/GPU-Beschleunigung gelöst werden können.3.1 Verteilt 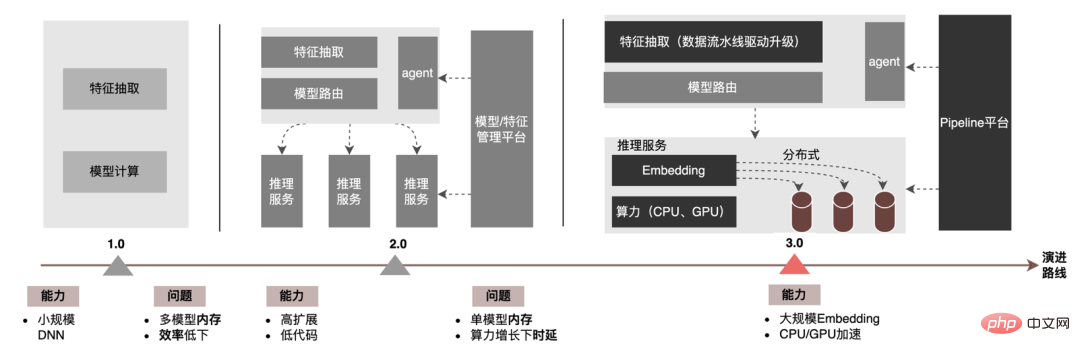 Die Parameter des großen Modells sind hauptsächlich in zwei Teile unterteilt: Sparse-Parameter und Dense-Parameter.
Die Parameter des großen Modells sind hauptsächlich in zwei Teile unterteilt: Sparse-Parameter und Dense-Parameter.
- Sparse-Parameter: Die Parametergröße ist sehr groß, normalerweise im Milliarden-Bereich oder sogar im Milliarden-/Zehntel-Milliarden-Bereich, was zu einer großen Speicherplatzbelegung führt, normalerweise im Hunderter-G-Bereich. oder sogar T-Level. Seine Eigenschaften: ① Schwierigkeiten beim Laden im Standalone-Modus: Im Standalone-Modus müssen alle Sparse-Parameter in den Maschinenspeicher geladen werden, was zu einem ernsthaften Speichermangel führt, der die Stabilität und Iterationseffizienz beeinträchtigt. ② Sparse-Lesen: nur ein Teil des Sparse Parameter müssen für jede Inferenzberechnung gelesen werden. Beispielsweise liegt die volle Anzahl an Benutzerparametern auf der 200-Millionen-Ebene, es muss jedoch nur ein Benutzerparameter für jede Inferenzanforderung gelesen werden.
- Dichte Parameter: Die Parameterskala ist nicht groß, das Modell ist im Allgemeinen vollständig in 2 bis 3 Schichten verbunden und die Parametergröße liegt im Millionen-/Zehnmillionen-Bereich. Merkmale: ① Einzelne Maschine kann geladen werden: Dichte Parameter belegen etwa zehn Megabyte, und der Speicher einer einzelnen Maschine kann normal geladen werden. Beispiel: Die Eingabeschicht ist 2000, die vollständig verbundene Schicht ist [1024, 512, 256] und Die Gesamtparameter sind: 2000 * 1024 + 1024 * 512 + 512 * 256 + 256 = 2703616, insgesamt 2,7 Millionen Parameter, und der belegte Speicher liegt innerhalb von 100 Megabyte; ② Vollständiger Lesevorgang: Für jede Inferenzberechnung die volle Menge Parameter müssen gelesen werden.
Daher besteht der Schlüssel zur Lösung des Problems des Wachstums großer Modellparameter darin, Sparse-Parameter vom Einzelmaschinenspeicher in den verteilten Speicher umzuwandeln. Die Transformationsmethode umfasst zwei Teile: ① Modellnetzwerkstrukturkonvertierung; .
3.1.1 Konvertierung der Modellnetzwerkstruktur
Die Methoden der Branche zum Erhalten verteilter Parameter sind grob in zwei Typen unterteilt: Externe Dienste erhalten Parameter im Voraus und übergeben sie an den Vorhersagedienst; der Vorhersagedienst transformiert TF (TensorFlow). )-Operator zum Abrufen von Parametern aus dem verteilten Speicher. Um die Kosten für Architekturänderungen zu reduzieren und den Eingriff in die vorhandene Modellstruktur zu verringern, haben wir uns dafür entschieden, verteilte Parameter durch Modifizieren des TF-Operators zu erhalten.
Unter normalen Umständen verwendet das TF-Modell native Operatoren zum Lesen von Sparse-Parametern. Der Kernoperator ist der GatherV2-Operator. Die Eingabe des Operators besteht hauptsächlich aus zwei Teilen: ① abzufragende ID-Liste; Parametertabelle. Die Funktion des
-Operators besteht darin, die dem ID-Listenindex entsprechenden Einbettungsdaten aus der Einbettungstabelle zu lesen und zurückzugeben. Es handelt sich im Wesentlichen um einen Hash-Abfrageprozess. Unter anderem werden die in der Einbettungstabelle gespeicherten Sparse-Parameter alle im Einzelmaschinenspeicher im Einzelmaschinenmodell gespeichert.
Die Transformation des TF-Operators ist im Wesentlichen eine Transformation der Modellnetzwerkstruktur. Die Kernpunkte der Transformation umfassen hauptsächlich zwei Teile: ① Netzwerkgraphenrekonstruktion; ② Benutzerdefinierte verteilte Operatoren.
1. Rekonstruktion des Netzwerkdiagramms: Transformieren Sie die Modellnetzwerkstruktur, ersetzen Sie den nativen TF-Operator durch einen benutzerdefinierten verteilten Operator und festigen Sie gleichzeitig die native Einbettungstabelle.
- Verteilter Operator-Ersatz: Durchlaufen Sie das Modellnetzwerk, ersetzen Sie den zu ersetzenden GatherV2-Operator durch den benutzerdefinierten verteilten Operator MtGatherV2 und ändern Sie gleichzeitig die Eingabe/Ausgabe der Upstream- und Downstream-Knoten .
- Verfestigung der nativen Einbettungstabelle: Die native Einbettungstabelle wird als Platzhalter verfestigt, wodurch nicht nur die Integrität der Modellnetzwerkstruktur erhalten bleibt, sondern auch die Belegung des Einzelmaschinenspeichers durch Sparse-Parameter vermieden werden kann.
 2. Benutzerdefinierter verteilter Operator: Ändern Sie den Einbettungsabfrageprozess basierend auf der ID-Liste, fragen Sie aus der lokalen Einbettungstabelle ab und ändern Sie ihn, um eine Abfrage aus dem verteilten KV durchzuführen.
2. Benutzerdefinierter verteilter Operator: Ändern Sie den Einbettungsabfrageprozess basierend auf der ID-Liste, fragen Sie aus der lokalen Einbettungstabelle ab und ändern Sie ihn, um eine Abfrage aus dem verteilten KV durchzuführen.
- Abfrage anfordern: Deduplizieren Sie die Eingabe-ID, um das Abfragevolumen zu reduzieren, und fragen Sie gleichzeitig durch Sharding ab. Der Second-Level-Cache (lokaler Cache + Remote-KV) erhält den Einbettungsvektor.
- Modellverwaltung: Behalten Sie den Modelleinbettungs-Meta-Registrierungs- und Deinstallationsprozess sowie die Erstellung des Caches bei , Zerstörungsfunktion.
- Modellbereitstellung: Löst das Laden von Modellressourceninformationen und den Prozess des parallelen Imports von Einbettungsdaten in KV aus.
3.1.2 Sparse-Parameter-Export
- Sharded-Parallelexport # 🎜🎜#: Analysieren Sie die Checkpoint-Datei des Modells, rufen Sie die Teilinformationen ab, die der Einbettungstabelle entsprechen, teilen Sie sie nach Teil auf und exportieren Sie jede Teildatei parallel über mehrere Worker-Knoten nach HDFS.
- KV importieren: Die Buckets speichern Informationen wie Modellversionen, um Online-Routing-Abfragen zu erleichtern. Gleichzeitig werden auch die Einbettungsdaten des Modells im Bucket gespeichert und parallel per Sharding in KV importiert.
Der Gesamtprozess ist in der folgenden Abbildung dargestellt. Wir verwenden eine Offline-Konvertierung der verteilten Modellstruktur, eine Nearline-Datenkonsistenzgarantie und ein Online-Hotspot-Daten-Caching Andere Mittel, um sicherzustellen, dass die normalen Iterationsanforderungen von Hunderten von Gigabyte großen Modellen erfüllt werden.
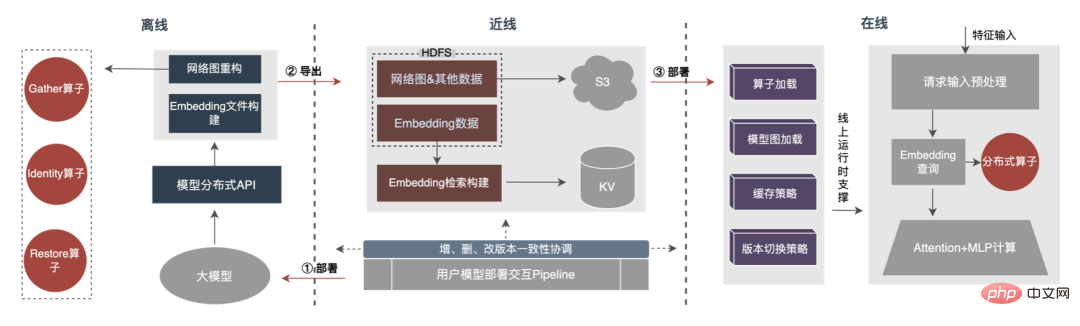
Es ist ersichtlich, dass es sich bei dem von Distributed verwendeten Speicher um eine externe KV-Fähigkeit handelt, die durch eine weitere ersetzt wird Effizienter und flexibler, zukünftig einfach zu verwaltender Einbettungsservice.
3.2 CPU-BeschleunigungZusätzlich zu den Optimierungsmethoden des Modells selbst gibt es zwei gängige Hauptmethoden zur CPU-Beschleunigung: ① Befehlssatz Optimierung, z. B. Verwendung des Befehlssatzes AVX2, AVX512; ② Verwendung der Beschleunigungsbibliothek (TVM, OpenVINO).
- Befehlssatzoptimierung: Wenn Sie das TensorFlow-Modell verwenden, kompilieren Sie den TensorFlow Framework-Code Fügen Sie dazu einfach das Element zur Befehlssatzoptimierung direkt zu den Kompilierungsoptionen hinzu. Die Praxis hat gezeigt, dass die Einführung der Befehlssatzoptimierung AVX2 und AVX512 offensichtliche Auswirkungen hat und der Durchsatz von Online-Inferenzdiensten um über 30 % gestiegen ist.
- Optimierung der Beschleunigungsbibliothek : Die Beschleunigungsbibliothek optimiert und integriert die Netzwerkmodellstruktur, um Inferenzbeschleunigungseffekte zu erzielen. Zu den in der Branche häufig verwendeten Beschleunigungsbibliotheken gehören TVM, OpenVINO usw. Unter diesen unterstützt TVM plattformübergreifend und weist eine gute Vielseitigkeit auf. OpenVINO ist speziell für die Hardware des Intel-Herstellers optimiert. Es bietet allgemeine Vielseitigkeit, aber einen guten Beschleunigungseffekt.
Im Folgenden konzentrieren wir uns auf einige unserer praktischen Erfahrungen bei der Verwendung von OpenVINO zur CPU-Beschleunigung. OpenVINO ist ein von Intel eingeführtes Deep-Learning-basiertes Framework zur Optimierung der Rechenbeschleunigung, das Komprimierungsoptimierung, beschleunigtes Rechnen und andere Funktionen von Modellen für maschinelles Lernen unterstützt. Das Beschleunigungsprinzip von OpenVINO lässt sich einfach in zwei Teile zusammenfassen: lineare Operatorfusion und Datengenauigkeitskalibrierung.
- Lineare Operatorfusion: OpenVINO verwendet den Modelloptimierer, um das Modellnetzwerk zu kombinieren Die mehrschichtigen Operatoren im Operator werden vereinheitlicht und linear zusammengeführt, um den Overhead für die Operatorplanung und den Datenzugriffsoverhead zwischen den Operatoren zu reduzieren. Beispielsweise werden die drei Operatoren Conv+BN+Relu zu einem CBR-Strukturoperator zusammengeführt.
- Datengenauigkeitskalibrierung: Nachdem das Modell offline trainiert wurde, kann dies der Fall sein, da während des Inferenzprozesses keine Backpropagation erforderlich ist Eine entsprechend reduzierte Datengenauigkeit, wie z. B. eine Herabstufung auf FP16- oder INT8-Präzision, führt zu einem geringeren Speicherbedarf und einer geringeren Inferenzlatenz.
Die CPU-Beschleunigung beschleunigt normalerweise die Inferenz für Kandidatenwarteschlangen mit festem Batch, aber in Suchförderungsszenarien sind Kandidatenwarteschlangen oft dynamisch. Dies bedeutet, dass vor der Modellinferenz eine Batch-Matching-Operation hinzugefügt werden muss, d. h. die angeforderte dynamische Batch-Kandidatenwarteschlange wird einem Batch-Modell zugeordnet, das ihr am nächsten liegt. Dies erfordert jedoch die Erstellung von N Matching-Modellen, was zu einer N-fachen Speichernutzung führt . Das Volumen des aktuellen Modells hat Hunderte von Gigabyte erreicht, und der Speicher ist sehr knapp. Daher ist die Auswahl einer angemessenen Netzwerkstruktur zur Beschleunigung ein wichtiger Aspekt, der berücksichtigt werden muss. Das Bild unten zeigt die gesamte Betriebsstruktur: 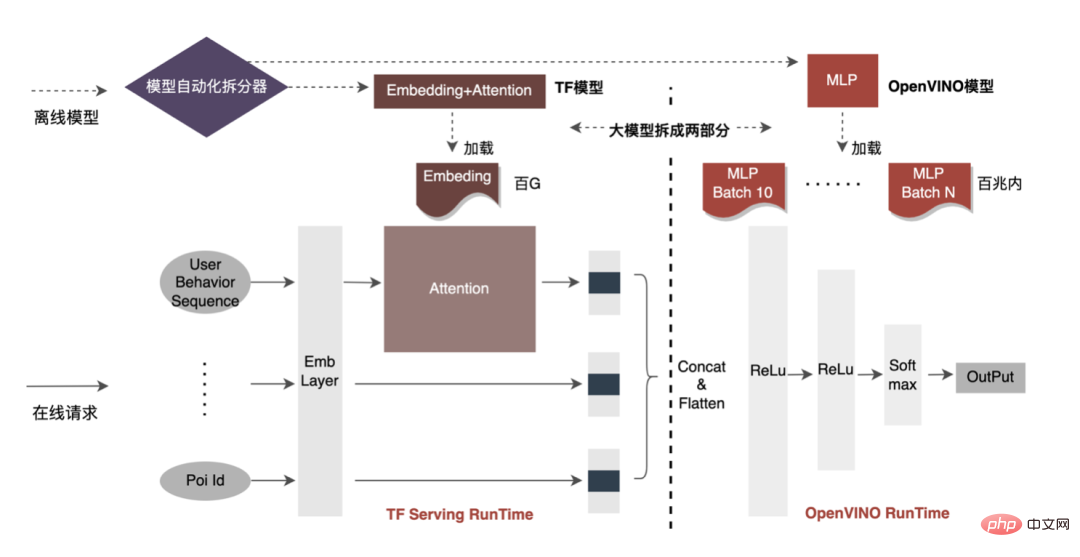
- Netzwerkverteilung: Die gesamte Netzwerkstruktur des CTR-Modells ist in drei Teile abstrahiert: Einbettungsschicht, Aufmerksamkeitsschicht und MLP-Schicht. Die Einbettungsschicht wird für die Datenerfassung verwendet, und die Aufmerksamkeitsschicht enthält weitere logische Operationen Beim Lightweight-Computing handelt es sich bei der MLP-Schicht um ein dichtes Netzwerk-Computing.
- Auswahl des Beschleunigungsnetzwerks: OpenVINO hat einen besseren Beschleunigungseffekt für reine Netzwerkberechnungen und kann gut auf die MLP-Schicht angewendet werden. Darüber hinaus werden die meisten Modelldaten in der Einbettungsschicht gespeichert, und die MLP-Schicht belegt nur einige zehn Megabyte Speicher. Wenn mehrere Stapel für das MLP-Layer-Netzwerk aufgeteilt werden, beträgt die Modellspeichernutzung vor der Optimierung (Einbettung+Aufmerksamkeit+MLP) ≈ nach der Optimierung (Einbettung+Aufmerksamkeit+MLP×Stapelnummer) und die Auswirkung auf die Speichernutzung wird klein sein. Daher haben wir schließlich das MLP-Schichtnetzwerk als Modellbeschleunigungsnetzwerk ausgewählt.
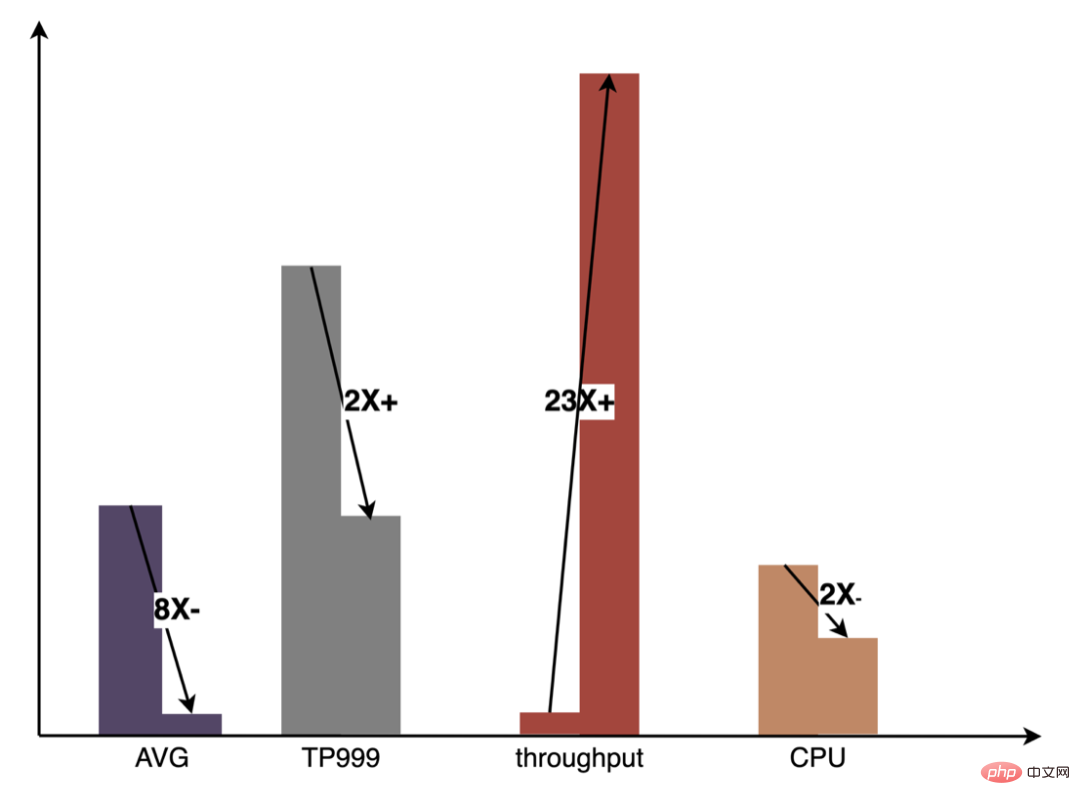
Derzeit hat die auf OpenVINO basierende CPU-Beschleunigungslösung in der Produktionsumgebung gute Ergebnisse erzielt: Wenn die CPU mit der Basislinie übereinstimmt, wird der Servicedurchsatz um 40 % erhöht und die durchschnittliche Verzögerung um reduziert 15 %. Wenn Sie eine gewisse Beschleunigung auf CPU-Ebene erreichen möchten, ist OpenVINO eine gute Wahl.
3.3 GPU-Beschleunigung
Einerseits gibt es mit der Geschäftsentwicklung immer mehr Geschäftsformen, der Verkehr wird immer höher, die Modelle werden breiter und tiefer und der Rechenleistungsverbrauch steigt stark an ; Andererseits verwenden Werbeszenarien hauptsächlich das DNN-Modell und umfassen eine große Anzahl spärlicher Funktionen Einbettung und Gleitkommaoperationen für neuronale Netzwerke. Als speicherzugriffs- und rechenintensiver Onlinedienst muss er die Anforderungen einer geringen Latenz und eines hohen Durchsatzes erfüllen und gleichzeitig die Verfügbarkeit gewährleisten, was auch eine Herausforderung für die Rechenleistung einer einzelnen Maschine darstellt. Wenn diese Konflikte zwischen den Anforderungen an Rechenressourcen und Platz nicht gut gelöst werden, schränken sie die Geschäftsentwicklung erheblich ein: Bevor das Modell erweitert und vertieft wird, können reine CPU-Inferenzdienste einen beträchtlichen Durchsatz liefern, aber nachdem das Modell erweitert und vertieft wird, werden die Berechnungen Um eine hohe Verfügbarkeit zu gewährleisten, müssen große Mengen an Maschinenressourcen verbraucht werden, sodass große Modelle nicht in großem Umfang online angewendet werden können. Derzeit besteht eine in der Branche übliche Lösung darin, dieses Problem mithilfe einer GPU zu lösen. Die GPU selbst eignet sich besser für rechenintensive Aufgaben. Der Einsatz von GPUs erfordert die Lösung folgender Herausforderungen: Wie erreicht man einen möglichst hohen Durchsatz bei gleichzeitiger Sicherstellung von Verfügbarkeit und geringer Latenz und berücksichtigt gleichzeitig Benutzerfreundlichkeit und Vielseitigkeit? Zu diesem Zweck haben wir auch viel praktische Arbeit an GPUs wie TensorFlow-GPU, TensorFlow-TensorRT, TensorRT usw. geleistet. Um die Flexibilität von TF und den Beschleunigungseffekt von TensorRT zu berücksichtigen, übernehmen wir eine Unabhängiges zweistufiges Architekturdesign von TensorFlow+TensorRT.
3.3.1 Beschleunigte Analyse
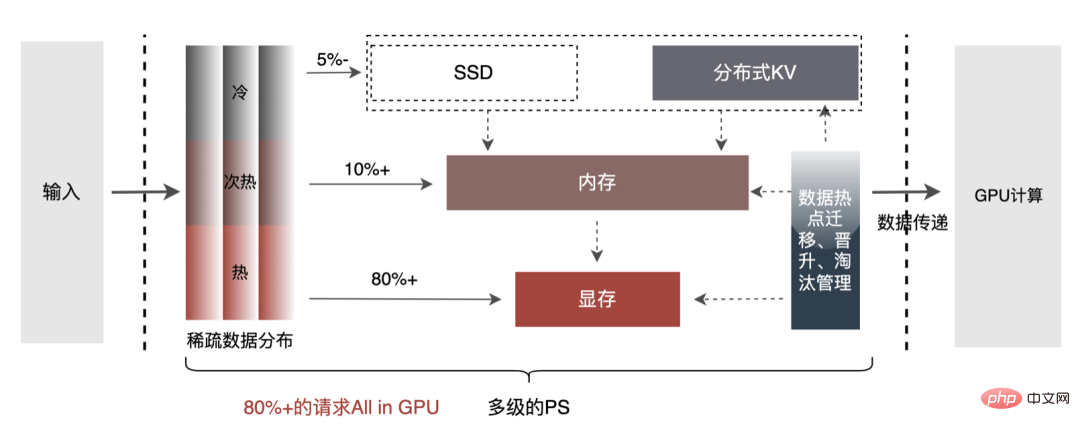
- Heterogenes Computing: Unsere Ideen ähneln der CPU Die Beschleunigung ist relativ konsistent. Das 200G-Deep-Learning-CTR-Modell kann nicht direkt in die GPU eingefügt werden (wie Einbettungsbezogene Vorgänge#🎜 🎜 #) CPU, rechenintensive Operatoren (wie MLP) sind für GPU geeignet.
- Mehrere Punkte, die bei der Verwendung von GPU beachtet werden müssen: ① Häufige Interaktion zwischen Speicher und Videospeicher; ② Latenz und Durchsatz; ③ Kompromiss für Skalierbarkeit und Leistungsoptimierung;
- Auswahl der Inferenz-Engine: Zu den in der Branche häufig verwendeten Inferenzbeschleunigungs-Engines gehören TensorRT, TVM, XLA und ONNXRuntime usw., da TensorRT tiefer in die Operatoroptimierung einsteigt als andere Engines und jeden Operator über ein benutzerdefiniertes Plugin implementieren kann, das über eine starke Skalierbarkeit verfügt. Darüber hinaus unterstützt TensorRT Modelle von gängigen Lernplattformen (Caffe, PyTorch, TensorFlow usw.) und seine Umgebung wird immer vollständiger (#🎜 🎜# Modellkonvertierungstool onnx-tensorrt, Leistungsanalysetool nsys usw. ), sodass die Beschleunigungs-Engine auf der GPU-Seite TensorRT verwendet. Modellanalyse: Die gesamte Netzwerkstruktur des CTR-Modells ist in drei Teile abstrahiert: Einbettungsschicht, Aufmerksamkeitsschicht und MLP-Schicht Die Einbettungsschicht eignet sich für die Datenerfassung und ist für die CPU geeignet. Die Aufmerksamkeitsschicht enthält mehr logische Operationen und einfache Netzwerkberechnungen, während sich die MLP-Schicht auf Netzwerkberechnungen konzentriert. Diese Berechnungen können parallel durchgeführt werden und sind für die GPU geeignet Nutzen Sie den GPU-Kern ( Cuda Core, Tensor Core
- ) voll aus, um die Parallelität zu verbessern. 3.3.2 Optimierungsziel Die Inferenzphase des Deep Learning stellt hohe Anforderungen an Rechenleistung und Latenz Da das trainierte neuronale Netzwerk direkt am Ende der Inferenz eingesetzt wird, können Probleme wie unzureichende Rechenleistung für die Ausführung oder lange Inferenzzeit auftreten. Daher müssen wir bestimmte Optimierungen am trainierten neuronalen Netzwerk durchführen. Die allgemeine Idee der Optimierung neuronaler Netzwerkmodelle in der Branche kann unter verschiedenen Aspekten wie Modellkomprimierung, Zusammenführung verschiedener Netzwerkschichten, Sparsifizierung und Verwendung von Datentypen mit geringer Genauigkeit optimiert werden. Es bedarf sogar einer gezielten Optimierung Hardwareeigenschaften. Zu diesem Zweck optimieren wir hauptsächlich um die folgenden zwei Ziele:
-
Durchsatz bei Verzögerungen und Ressourcenbeschränkungen: Wenn gemeinsam genutzte Ressourcen wie Register und Cache nicht konkurrieren müssen, kann eine Erhöhung der Parallelität die Ressourcennutzung effektiv verbessern ( # 🎜🎜#CPU-, GPU- usw. Auslastung), dies kann jedoch zu einer Erhöhung der Anforderungslatenz führen. Da die Verzögerungsgrenze des Online-Systems sehr streng ist, kann die Durchsatzobergrenze des Online-Systems nicht einfach durch den Ressourcennutzungsindikator umgerechnet werden. Sie muss umfassend unter der Verzögerungsbeschränkung bewertet und mit der Ressourcenobergrenze kombiniert werden. Wenn die Systemlatenz niedrig ist und die Ressourcenauslastung (Speicher/CPU/GPU usw.) eine Einschränkung darstellt, kann das Modell dies tun Die Optimierung reduziert die Ressourcenauslastung. Wenn die Systemressourcenauslastung gering ist und die Verzögerung eine Einschränkung darstellt, kann die Verzögerung durch Fusionsoptimierung und Motoroptimierung reduziert werden. Durch die Kombination der oben genannten verschiedenen Optimierungsmethoden können die umfassenden Fähigkeiten von Systemdiensten effektiv verbessert werden, wodurch das Ziel einer Verbesserung des Systemdurchsatzes erreicht wird.
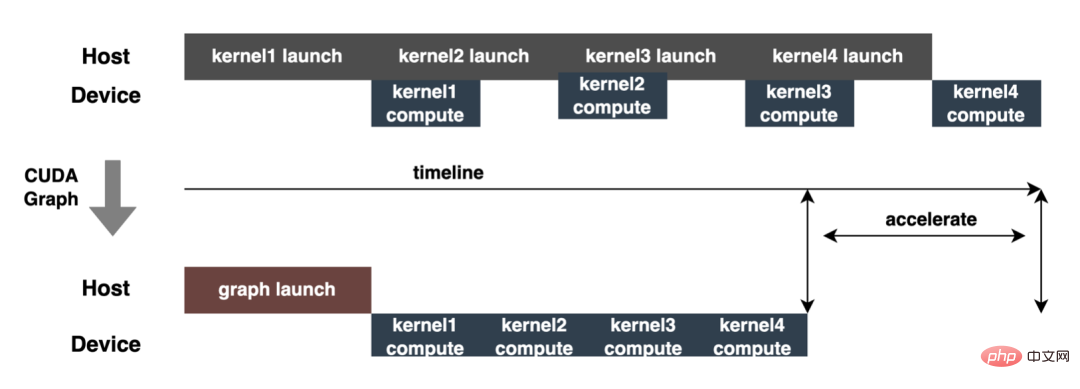
- Rechendichte unter Berechnungsbeschränkungen: Bei heterogenen CPU/GPU-Systemen wird die Modellinferenzleistung hauptsächlich von der Datenkopiereffizienz und der Berechnungseffizienz beeinflusst, die jeweils durch den Speicherzugriff bestimmt werden . Intensive Operatoren und rechenintensive Operatoren werden bestimmt, und die Effizienz der Datenkopie wird durch die PCIe-Datenübertragung, die Lese- und Schreibeffizienz des CPU/GPU-Speichers usw. beeinflusst, und die Recheneffizienz wird durch die Recheneffizienz verschiedener Recheneinheiten wie der CPU beeinflusst Core-, CUDA-Core- und Tensor-Core-Einfluss. Mit der rasanten Entwicklung von Hardware wie GPUs haben die Verarbeitungskapazitäten rechenintensiver Betreiber rapide zugenommen, was zu dem Phänomen geführt hat, dass speicherzugriffsintensive Betreiber die Verbesserung der Systemdienstfunktionen behindern und daher speicherzugriffsintensive Betreiber reduzieren und die Verbesserung der Rechendichte wird auch für die Systemdienstfunktionen immer wichtiger, d. h. die Reduzierung des Datenkopierens und des Kernel-Starts, wenn sich die Menge der Modellberechnungen nicht wesentlich ändert. Beispielsweise werden Modelloptimierung und Fusionsoptimierung verwendet, um den Einsatz von Operatortransformationen (wie Cast/Unsqueeze/Concat und andere Operatoren) zu reduzieren, und CUDA Graph wird verwendet, um den Kernel-Start usw. zu reduzieren.
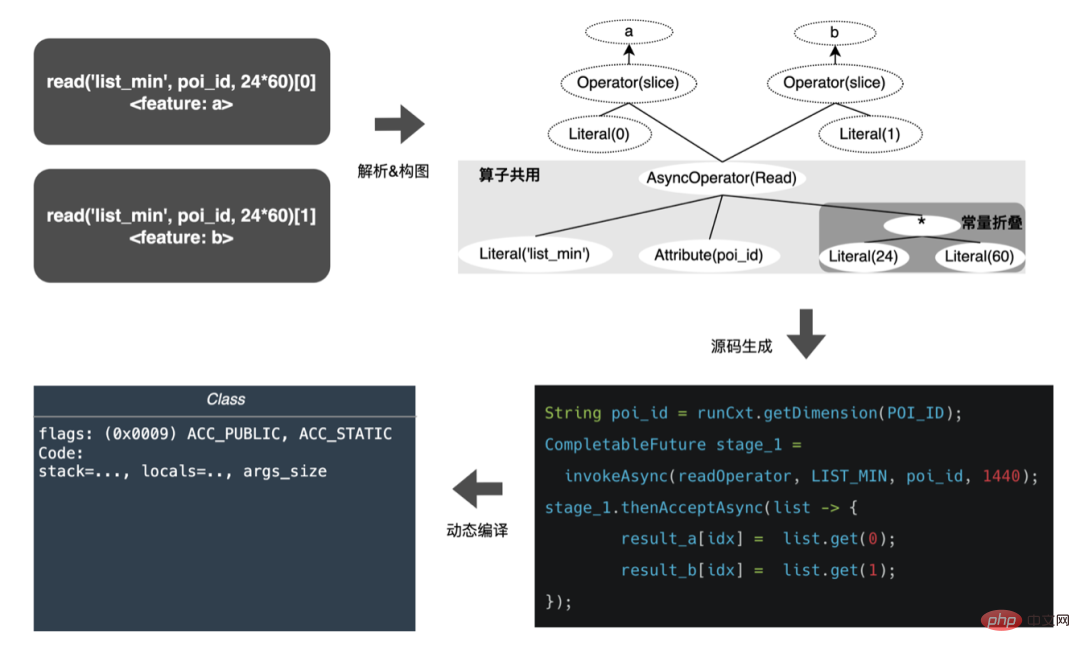
Im Folgenden konzentrieren wir uns auf die beiden oben genannten Ziele und stellen unsere Modelloptimierung, Fusion im Detail vor Optimierung# Ein Teil der Arbeit von 🎜🎜# und MOTOROPTIMIERUNG. 3.3.3 Modelloptimierung
1. Berechnung und Übertragungsdeduplizierung : Inferenz bei Dieses Mal enthält derselbe Batch nur eine Benutzerinformation, sodass die Benutzerinformation vor der Inferenz von der Batch-Größe auf 1 reduziert und dann erweitert werden kann, wenn die Inferenz wirklich benötigt wird, wodurch die Kosten für die Datenübertragung, Kopie und wiederholte Berechnung reduziert werden. Wie in der folgenden Abbildung gezeigt, können Sie die Feature-Informationen der Benutzerklasse vor der Inferenz nur einmal abfragen und sie nur in benutzerbezogene Subnetzwerke schneiden und sie dann erweitern, wenn Sie die Zuordnung berechnen müssen.
- Automatisierter Prozess: Doppelte Berechnungsknoten finden ( #🎜 🎜#Roter Knoten), wenn alle Blattknoten des Knotens wiederholte Berechnungsknoten sind, dann ist der Knoten auch ein wiederholter Berechnungsknoten. Durchsuchen Sie alle doppelten Knoten nach oben Suchen Sie Schicht für Schicht von den Blattknoten bis zum Abschluss der Knotendurchquerungssuche die Verbindungslinien aller roten und weißen Knoten, fügen Sie den Erweiterungsknoten für Benutzerfunktionen ein und erweitern Sie die Benutzerfunktion.
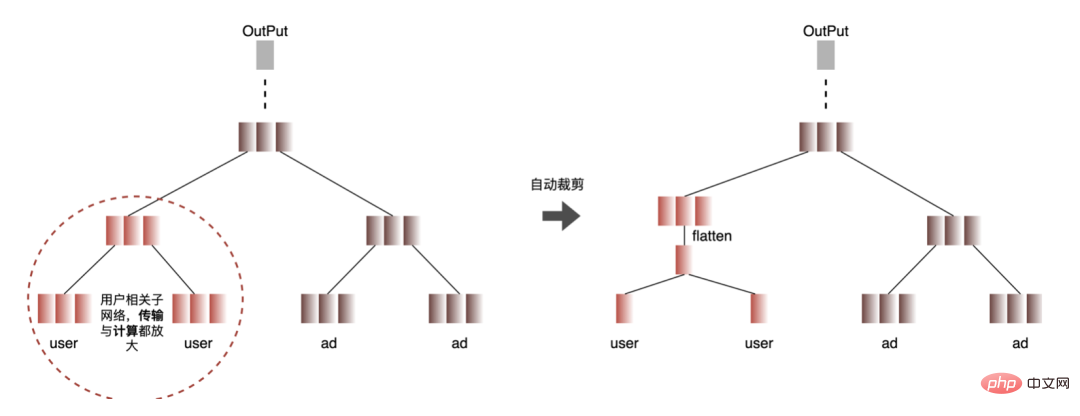
# 🎜🎜#: Da zur Aktualisierung des Gradienten während des Modelltrainings eine Rückwärtsausbreitung erforderlich ist, muss die Datengenauigkeit höher sein, während während der Modellinferenz nur eine Vorwärtsinferenz ohne Aktualisierung des Gradienten durchgeführt wird Der Effekt ist garantiert. Verwenden Sie FP16 oder gemischte Präzision zur Optimierung, um Speicherplatz zu sparen, den Übertragungsaufwand zu reduzieren und die Inferenzleistung und den Durchsatz zu verbessern.
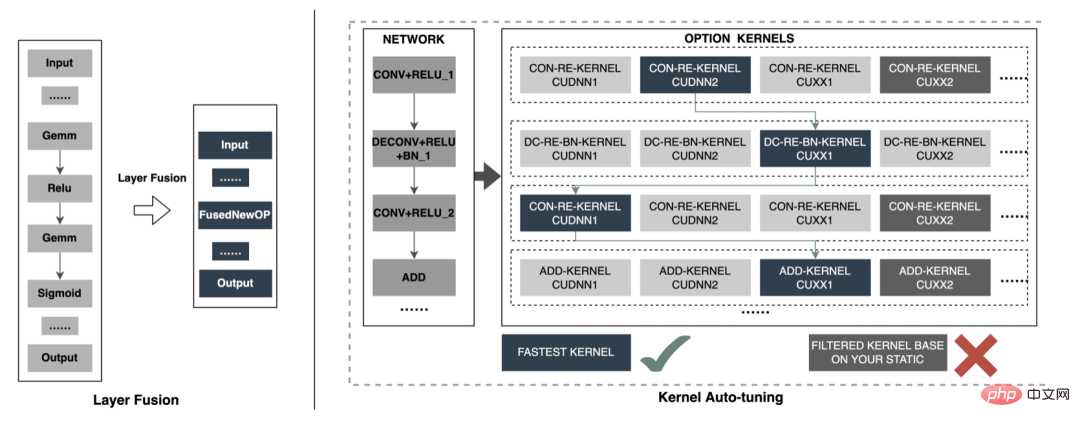
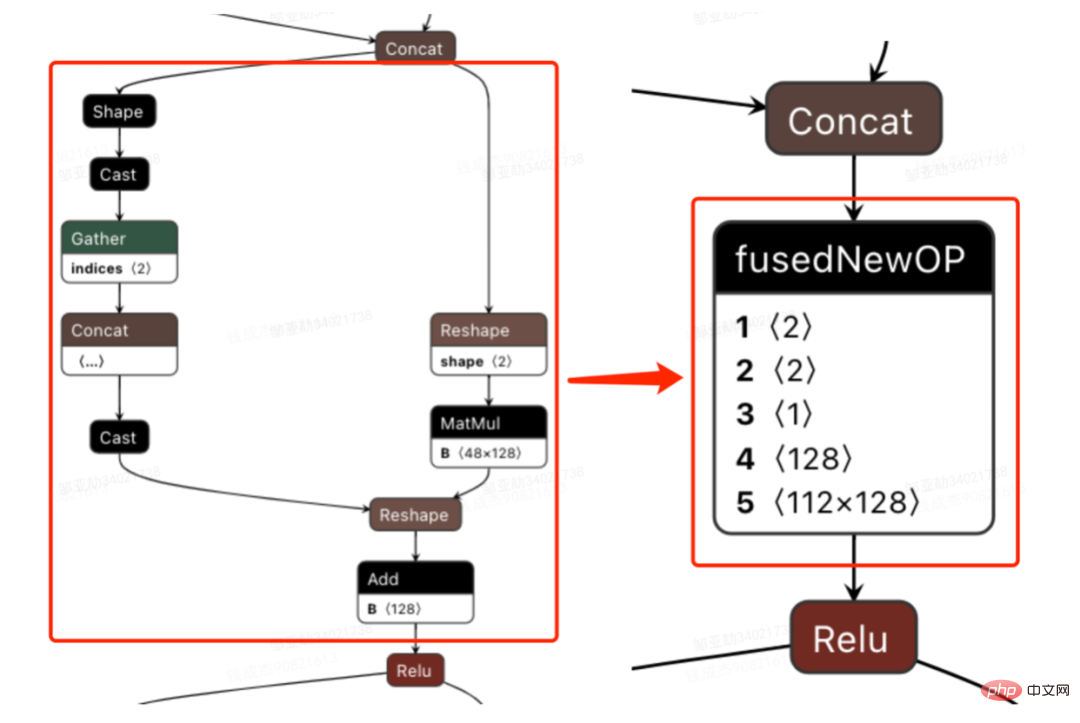
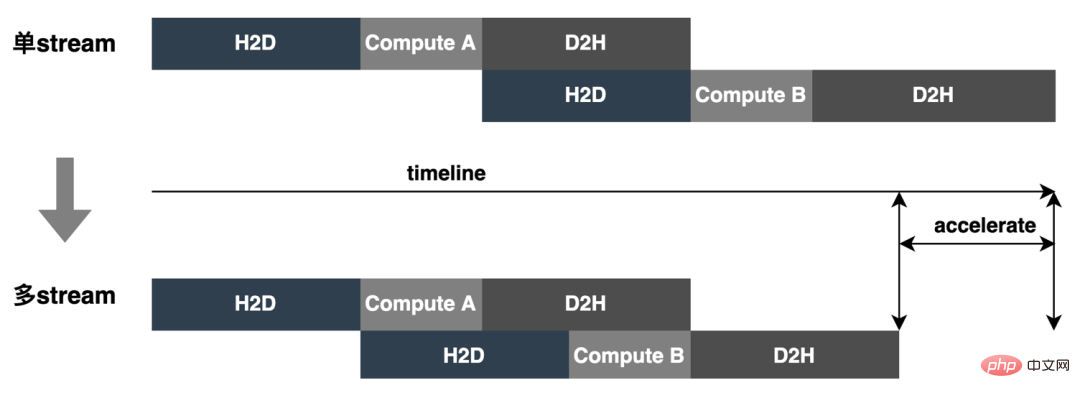
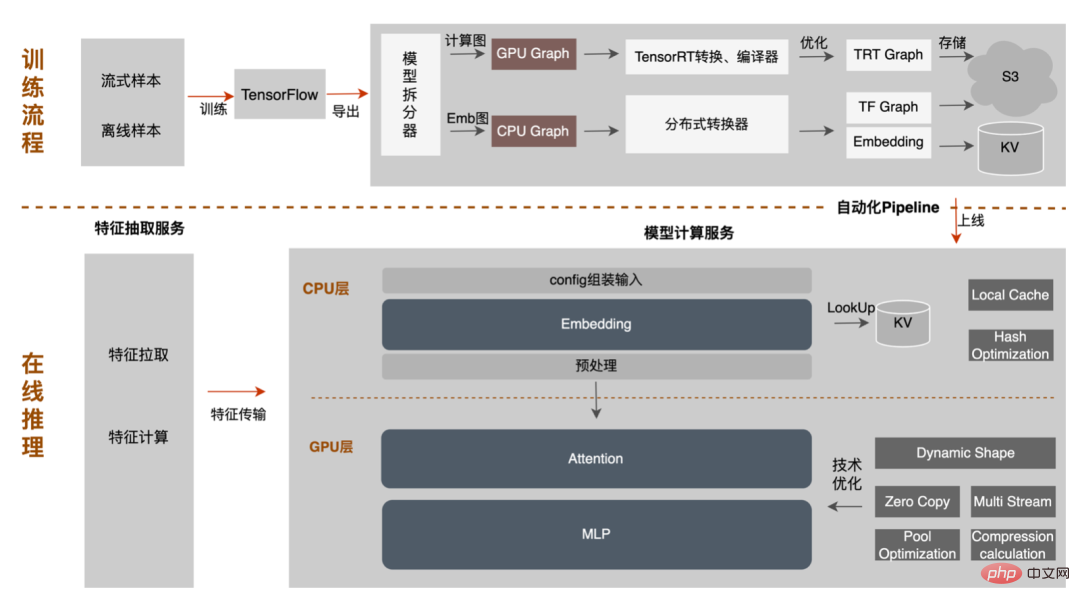
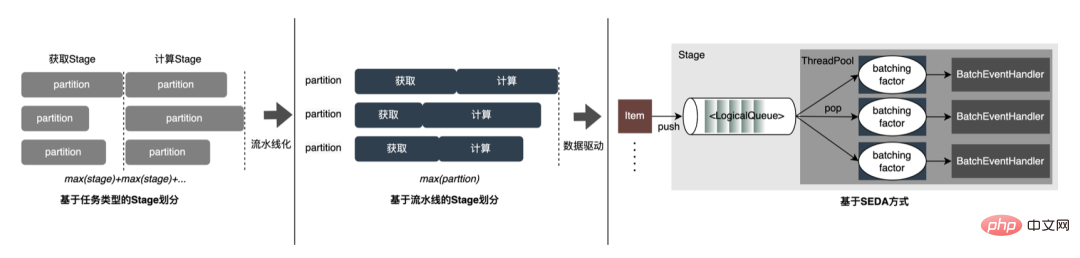
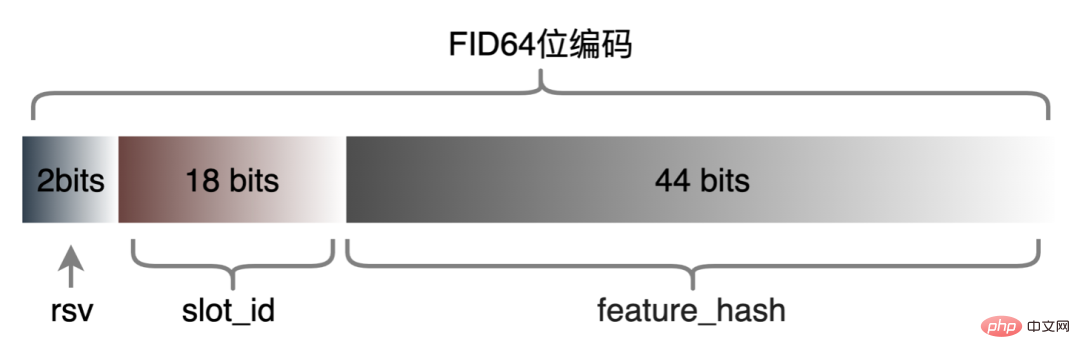
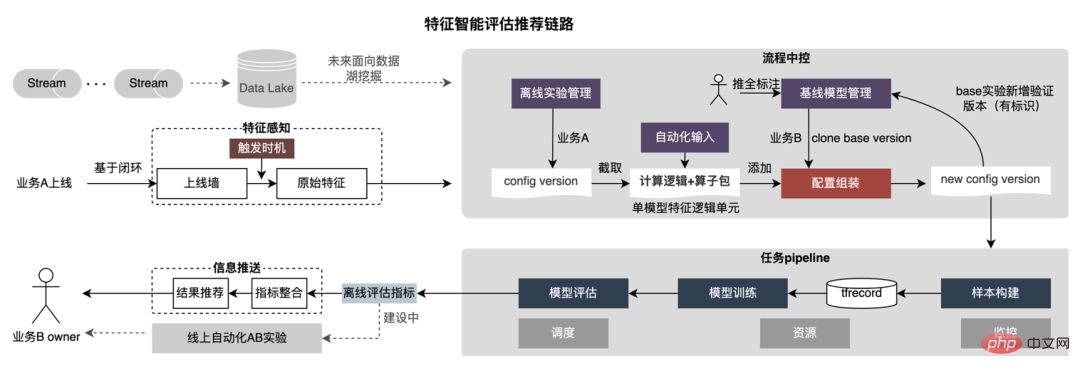
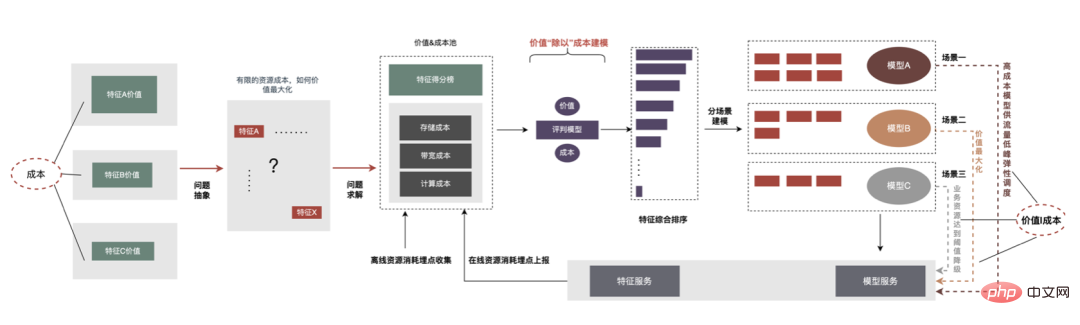
3. Berechnungs-Pushdown: Die CTR-Modellstruktur besteht hauptsächlich aus drei Schichten: Einbettung, Aufmerksamkeit und MLP-Zusammensetzung, die Einbettungsschicht ist auf die Datenerfassung ausgerichtet, und die Aufmerksamkeit ist teilweise auf die Logik und teilweise auf die Berechnung ausgerichtet. Um das Potenzial der GPU voll auszuschöpfen, sind die meisten Berechnungslogiken von Attention und MLP im CTR-Modell enthalten Die Struktur wird zur Berechnung von der CPU auf die GPU verlagert und der Gesamtdurchsatz wird erheblich verbessert. Während der Online-Modellinferenz werden die Rechenvorgänge jeder Schicht von der GPU abgeschlossen. Tatsächlich schließt die CPU sie ab, indem sie verschiedene CUDA-Kernel startet Bei der Berechnung berechnet der CUDA-Kernel Tensoren sehr schnell, es wird jedoch häufig viel Zeit mit dem Starten des CUDA-Kernels und dem Lesen und Schreiben der Eingabe-/Ausgabetensoren jeder Schicht verschwendet, was zu einem Engpass bei der Speicherbandbreite und der Verschwendung von GPU-Ressourcen führt . Hier werden wir hauptsächlich den TensorRT-Teil automatische Optimierung und manuelle Optimierung vorstellen. 1. Automatische Optimierung: TensorRT ist ein leistungsstarker Deep-Learning-Inferenzoptimierer, der eine Inferenzbereitstellung mit geringer Latenz und hohem Durchsatz ermöglichen kann . TensorRT kann verwendet werden, um die Inferenz auf sehr großen Modellen, eingebetteten Plattformen oder autonomen Fahrplattformen zu beschleunigen. TensorRT kann jetzt fast alle Deep-Learning-Frameworks wie TensorFlow, Caffe, MXNet und PyTorch unterstützen. Die Kombination von TensorRT mit NVIDIA-GPUs kann eine schnelle und effiziente Bereitstellung und Inferenz in fast allen Frameworks ermöglichen. Und einige Optimierungen erfordern nicht allzu viel Benutzerbeteiligung, wie etwa Layer Fusion, Kernel Auto-Tuning usw. 2 , GPU ist für rechenintensive Operatoren geeignet, ist jedoch für andere Operatortypen nicht sehr freundlich (leichte Berechnungsoperatoren, logische Operationsoperatoren usw.). Bei Verwendung von GPU-Berechnungen durchläuft jeder Vorgang im Allgemeinen mehrere Prozesse: CPU weist Videospeicher auf der GPU zu -> CPU sendet Daten an GPU -> CPU startet CUDA-Kernel -> CPU ruft Daten ab -> CPU gibt GPU-Videospeicher frei. Um den Overhead wie Planung, Kernel-Start und Speicherzugriff zu reduzieren, ist eine Netzwerkintegration erforderlich. Aufgrund der flexiblen und veränderlichen Struktur des CTR-Großmodells ist es schwierig, die Netzwerkfusionsmethoden zu vereinheitlichen und nur spezifische Probleme im Detail zu analysieren. In vertikaler Richtung werden beispielsweise Cast, Unsqueeze und Less fusioniert, und in horizontaler Richtung werden TensorRT-interne Conv, BN und Relu fusioniert. Eingabeoperatoren derselben Dimension werden fusioniert. Zu diesem Zweck verwenden wir NVIDIA-bezogene Leistungsanalysetools (NVIDIA Nsight Systems, NVIDIA Nsight Compute usw. ), um spezifische Probleme basierend auf tatsächlichen Online-Geschäftsszenarien zu analysieren. Integrieren Sie diese Leistungsanalysetools in die Online-Inferenzumgebung, um während des Inferenzprozesses die GPU-Profing-Datei zu erhalten. Anhand der Profing-Datei können wir den Inferenzprozess deutlich erkennen. Wir haben festgestellt, dass das Kernel-Start-Bound-Phänomen einiger Operatoren in der gesamten Inferenz schwerwiegend ist und die Lücken zwischen einigen Operatoren groß sind und Raum für Optimierung besteht, wie in gezeigt die folgende Abbildung: #🎜🎜 # Analysieren Sie zu diesem Zweck das gesamte Netzwerk basierend auf Leistungsanalysetools und dem konvertierten Modell, ermitteln Sie die Teile, die TensorRT optimiert hat, und führen Sie dann eine Netzwerkintegration auf anderen Unterstrukturen im Netzwerk durch, die optimiert werden können, und stellen Sie gleichzeitig sicher, dass dies der Fall ist Unterstrukturen sind Das gesamte Netzwerk nimmt einen bestimmten Anteil ein, um sicherzustellen, dass die Rechendichte nach der Integration bis zu einem gewissen Grad zunehmen kann. Die zu verwendende Netzwerkintegrationsmethode kann flexibel je nach Szenario verwendet werden. Das folgende Bild ist ein Vergleich der Unterstrukturdiagramme vor und nach unserer Integration: Der gesamte Prozess ist umständlich und fehleranfällig, und das Modell kann nicht universell verwendet werden Unterschiedliche GPU-Karten, unterschiedliche TensorRT- und CUDA-Versionen. Dies bringt mehr Möglichkeiten für Fehler bei der Modellkonvertierung mit sich. Um die Gesamteffizienz der Modelliteration zu verbessern, haben wir daher relevante Funktionen in Pipeline erstellt, wie in der folgenden Abbildung dargestellt: Der Pipeline-Aufbau umfasst zwei Teile: den Offline-Seitenmodellaufteilungs- und -konvertierungsprozess und den Online-Seitenmodellbereitstellungsprozess: #🎜🎜 ## 🎜🎜# Die Merkmalsextraktion ist die Vorstufe der Modellberechnung. Unabhängig davon, ob es sich um ein traditionelles LR-Modell oder ein zunehmend beliebtes Deep-Learning-Modell handelt, muss die Eingabe durch Merkmalsextraktion erfolgen. Im vorherigen Blog In Anlehnung an Sparks WholeStageCodeGen besteht unser Ziel darin, die gesamte Funktionsberechnungs-DSL in eine ausführbare Methode zu kompilieren und so den Leistungsverlust bei der Ausführung des Codes zu reduzieren. Der gesamte Kompilierungsprozess kann unterteilt werden in: Front-End (FrontEnd), Optimierer (Optimizer) und Back-End (BackEnd). Das Front-End ist hauptsächlich für das Parsen des Ziel-DSL und die Konvertierung des Quellcodes in AST oder IR verantwortlich. Der Optimierer optimiert den erhaltenen Zwischencode basierend auf dem Front-End, um den Code effizienter zu machen Code in nativen Code für die jeweilige Plattform umwandeln. Die spezifische Implementierung ist wie folgt: Nach der Optimierung bestimmt die Übersetzung des Knoten-DAG-Diagramms, also die Back-End-Code-Implementierung, die endgültige Leistung. Eine der Schwierigkeiten ist auch der Grund, warum bestehende Open-Source-Expression-Engines nicht direkt genutzt werden können: Die Feature-Berechnung DSL ist kein rein rechnerischer Ausdruck. Es kann den Feature-Erfassungs- und -Verarbeitungsprozess durch eine Kombination aus Leseoperatoren und Konvertierungsoperatoren beschreiben: Bei der tatsächlichen Implementierung ist es daher notwendig, die Planung verschiedener Arten von Aufgaben zu berücksichtigen, die Nutzung der Maschinenressourcen zu maximieren und den gesamten zeitaufwändigen Prozess zu optimieren. Durch die Kombination von Branchenforschung und eigener Praxis wurden die folgenden drei Implementierungen durchgeführt: Die CodeGen-Lösung verringert die Lesbarkeit des Codes und erhöht die Debugging-Kosten Platz für tiefergehende Optimierungen schaffen. Basierend auf CodeGen und der asynchronen, nicht blockierenden Implementierung wurden online gute Vorteile erzielt. Einerseits wird die zeitaufwändige Feature-Berechnung reduziert, andererseits wird auch die CPU-Belastung erheblich reduziert und der Systemdurchsatz verbessert. Auch in Zukunft werden wir die Vorteile von CodeGen nutzen und gezielte Optimierungen im Back-End-Kompilierungsprozess durchführen, beispielsweise die Kombination von Hardwareanweisungen (wie SIMD) oder heterogenes Computing ( wie GPU# 🎜🎜#) für eine tiefere Optimierung. Der Online-Vorhersagedienst verfügt insgesamt über eine zweischichtige Architektur. Die Merkmalsextraktionsschicht ist für das Modellrouting verantwortlich und Feature-Berechnung Modellberechnung Der Layer ist für Modellberechnungen verantwortlich. Der ursprüngliche Systemprozess besteht darin, die Ergebnisse der Merkmalsberechnung in eine Matrix aus M (Vorhergesagte Stapelgröße) × N (Probenbreite) zusammenzufügen und diese dann zu serialisieren. an die Rechenschicht übermittelt. Der Grund dafür sind einerseits historische Gründe. Das Eingabeformat vieler früherer einfacher Nicht-DNN-Modelle ist andererseits eine direkte Verwendung der Routing-Schicht Das Array-Format ist relativ kompakt und kann Zeit bei der Netzwerkübertragung sparen. Um die oben genannten Probleme zu lösen, fügt der optimierte Prozess eine Konvertierungsschicht über der Übertragungsschicht hinzu, um das berechnete Modell gemäß der MDFL-Konfiguration zu konvertieren. Features werden für die Offline-Nutzung in das erforderliche Format konvertiert, z. B. Tensor-, Matrix- oder CSV-Format. Diskrete Features und Sequenzfeatures können in Sparse-Features vereinheitlicht werden, und die ursprünglichen Features werden gehasht In der Feature-Verarbeitungsphase werden sie verarbeitet und in ID-Klassen-Features umgewandelt. Angesichts von Features mit Hunderten von Milliarden Dimensionen kann der Prozess der Zeichenfolgenverkettung und des Hashings die Anforderungen an Ausdrucksraum und Leistung nicht erfüllen. Basierend auf Branchenforschung haben wir ein Feature-Codierungsformat basierend auf der Slot-Codierung entworfen und angewendet: Darunter feature_hash ist der Hash-Wert des ursprünglichen Merkmalswerts. Integer-Features können direkt gefüllt werden. Nicht-Integer-Features oder Cross-Features werden zuerst gehasht und dann gefüllt. Wenn die Anzahl 44 Bit überschreitet, wird sie abgeschnitten. Nach der Einführung des Slot-Codierungsschemas wurde nicht nur die Leistung der Online-Feature-Berechnung verbessert, sondern auch der Modelleffekt erheblich verbessert. Zur Lösung Das Problem, die Branche Um das Problem der Online- und Offline-Konsistenz zu lösen, werden die für die Echtzeitbewertung verwendeten Feature-Daten im Allgemeinen online gespeichert, was als Feature-Snapshot bezeichnet wird, anstatt Beispiele durch einfaches Offline-Label-Spleißen und Feature-Backfilling zu erstellen Die Methode bringt ein größeres Problem mit sich. Die Daten sind inkonsistent. Die ursprüngliche Architektur ist wie in der folgenden Abbildung dargestellt: Dieses Schema wird mit zunehmender Feature-Skala immer iterativer Die Szenarien werden immer komplexer. Das Hauptproblem besteht darin, dass der Online-Funktionsextraktionsdienst unter großem Druck steht, und das zweite darin, dass die gesamten Kosten für die Datenflusserfassung zu hoch sind. Bei diesem Mustersammelplan treten folgende Probleme auf: Um die oben genannten Probleme zu lösen, gibt es in der Branche zwei gängige Lösungen: ①Flink-Echtzeit-Streaming-Verarbeitung; ②KV-Cache-Sekundärverarbeitung. Der spezifische Prozess ist in der folgenden Abbildung dargestellt: Aus Sicht der Reduzierung ungültiger Berechnungen werden nicht alle angeforderten Daten offengelegt. Die Strategie erfordert eine stärkere Nachfrage nach offengelegten Daten, sodass die Weiterleitung der Verarbeitung auf Tagesebene an die Stream-Verarbeitung die Datenbereitstellungszeit erheblich verbessern kann. Zweitens umfassen die Merkmale ausgehend vom Dateninhalt geänderte Daten auf Anforderungsebene und geänderte Daten auf Tagesebene. Die Verknüpfung kann die Verarbeitung der beiden flexibel trennen, was die Ressourcennutzung erheblich verbessern kann : #🎜 🎜# : Lösung des Problems des großen Datenübertragungsvolumens (Feature Snapshot Streaming Großes Problem ), die vorhergesagten Beschriftungen und Echtzeitdaten werden einzeln abgeglichen, und auf die Offline-Daten kann während des Reflows zweimal zugegriffen werden, wodurch die Größe des Links erheblich reduziert werden kann Datenstrom. : Lösen Sie das Problem der großen Speichernutzung. : Durch Label's Join ist die Anzahl der Feature-Anfragen für einen Ergänzungseintrag hier nicht zu 20 % online; die Probe wird verzögert und mit der Belichtung gespleißt, um die Belichtungsmodell-Dienstanforderung herauszufiltern (Kontext+Echtzeitfunktion), und dann werden alle Offline-Funktionen aufgezeichnet Formular vollständige Beispieldaten in HBase schreiben. 5.2 Strukturierter Speicher aus rechnerischer Sicht Es scheint, dass die Verwendung des ursprünglichen Berechnungsprozesses aufgrund der Ressourcenbeschränkungen der Berechnungs-Engine (Spark) (#🎜🎜 # verwendet Shuffle, die Daten in der Shuffle-Schreibphase werden auf die Festplatte geschrieben. Wenn der zugewiesene Speicher nicht ausreicht, kommt es zu mehreren Platzierungen und externer Sortierung ), was einen Speicher mit der gleichen Größe wie seinen eigenen erfordert Daten und mehr Rechen-CUs, um die Berechnung effektiv abzuschließen, beansprucht viel Speicher . Der Kernprozess des Beispielkonstruktionsprozesses ist in der folgenden Abbildung dargestellt: Beim Neuaufzeichnen von Features kommt es zu folgenden Problemen: Um das Problem der langsamen Beispielkonstruktionseffizienz zu lösen, beginnen wir kurzfristig mit der Datenstrukturverwaltung. Der detaillierte Prozess ist in der folgenden Abbildung dargestellt: Die Daten-Offline-Speicherressourcen werden um mehr als 80 % gespart und die Effizienz der Beispielkonstruktion wird um mehr als 200 % erhöht. Derzeit werden auch die gesamten Beispieldaten auf Basis des Data Lake implementiert, um die Dateneffizienz weiter zu verbessern. Die Plattform hat eine große Menge wertvoller Inhalte wie Funktionen, Beispiele und Modelle angesammelt. Man hofft, dass sie durch die Wiederverwendung dieser Datenbestände Strategen dabei helfen kann, Geschäftsiterationen besser durchzuführen und bessere Geschäftseinnahmen zu erzielen . Die Feature-Optimierung macht 40 % aller Methoden aus, die von Algorithmen zur Verbesserung der Modelleffekte verwendet werden. Allerdings weist die traditionelle Feature-Mining-Methode Probleme wie langen Zeitaufwand, geringe Mining-Effizienz und wiederholtes Feature-Mining auf die Feature-Dimension. Wenn es einen automatisierten experimentellen Prozess gibt, um die Wirkung einer Funktion zu überprüfen und den Benutzern die endgültigen Wirkungsindikatoren zu empfehlen, wird dies zweifellos dazu beitragen, dass Strategen viel Zeit sparen. Wenn der gesamte Linkaufbau abgeschlossen ist, müssen Sie nur noch verschiedene Feature-Kandidatensätze eingeben, um die entsprechenden Wirkungsindikatoren auszugeben. Zu diesem Zweck hat die Plattform einen intelligenten Mechanismus zur „Addition“, „Subtraktion“, „Multiplikation“ und „Division“ von Merkmalen und Stichproben entwickelt. Feature-Empfehlung basiert auf Modelltestmethoden, Wiederverwendung von Features für bestehende Modelle anderer Geschäftsbereiche, Erstellen neuer Beispiele und Modelle, Vergleichen der Offline-Effekte des neuen Modells und des Basismodells Die Vorteile neuer Funktionen werden automatisch an relevante Unternehmensleiter weitergegeben. Der spezifische Funktionsempfehlungsprozess ist in der folgenden Abbildung dargestellt: Feature-Empfehlung in der Werbung Nachdem es implementiert wurde und bestimmte Vorteile erzielte, haben wir einige neue Untersuchungen auf der Ebene der Funktionsermächtigung durchgeführt. Durch die kontinuierliche Optimierung des Modells ist die Geschwindigkeit der Funktionserweiterung sehr hoch und der Ressourcenverbrauch von Modelldiensten steigt. Es ist zwingend erforderlich, redundante Funktionen zu eliminieren und das Modell zu „verschlanken“. Aus diesem Grund hat die Plattform eine Reihe von End-to-End-Feature-Screening-Tools entwickelt. #? : Alle Feature-Scores des Modells werden durch verschiedene Bewertungsalgorithmen wie WOE ( Weight Of Evidence, Weight of Evidence
Durch die Wiederverwendung von Nicht-Werbe-Samples in einem Unternehmen innerhalb der Werbung wurde die Anzahl der Samples in Kombination mit dem Transfer-Learning-Algorithmus um ein Vielfaches erhöht, und der CPM hat sich um ein Viertausendstel erhöht um 1 % gestiegen, nachdem eins online gegangen ist. Darüber hinaus bauen wir auch eine Werbebeispiel-Themenbibliothek auf, um die von jedem Unternehmen generierten Beispieldaten einheitlich zu verwalten (einheitliche Metadaten), den Benutzern eine einheitliche Beispiel-Themenklassifizierung zur Verfügung zu stellen, sich schnell zu registrieren, zu suchen und wiederzuverwenden sowie einen einheitlichen Speicher für die zu erstellen Unterste Ebene: Sparen Sie Speicher- und Rechenressourcen, reduzieren Sie die Datenverknüpfung und verbessern Sie die Aktualität. Durch die „Subtraktion“ von Merkmalen können einige Merkmale entfernt werden, die keinen positiven Effekt haben. Durch Beobachtung wird jedoch festgestellt, dass das Modell immer noch viele Merkmale von geringem Wert enthält. Daher können wir einen Schritt weiter gehen, indem wir sowohl den Wert als auch die Kosten umfassend berücksichtigen. Unter den kostenbasierten Einschränkungen der gesamten Verbindung können wir diese Funktionen mit relativ geringem Input und Output herausfiltern und den Ressourcenverbrauch reduzieren. Dieser Lösungsprozess unter Kosteneinschränkungen wird als „Aufteilung“ definiert. Der Gesamtprozess ist in der folgenden Abbildung dargestellt. In der Offline-Dimension haben wir ein Merkmalswertbewertungssystem eingerichtet, um die Kosten und den Wert von Merkmalen anzugeben. Während der Online-Beurteilung können wir die Merkmalswertinformationen verwenden, um Vorgänge wie Verkehrsverschlechterung und Merkmalselastizität durchzuführen Berechnungen und führen Sie eine „Division“ durch. „Die wichtigsten Schritte sind wie folgt: Das Obige ist unsere Anti-„Anstiegs“-Praxis in groß angelegten Deep-Learning-Projekten, um dazu beizutragen, Geschäftskosten zu senken und die Effizienz zu verbessern. In Zukunft werden wir weiterhin die folgenden Aspekte erforschen und praktizieren: 亚, Yingliang, Chen Long, Chengjie, Dengfeng, Dongkui, Tongye, Simin, Lebin usw. gehören alle zum technischen Team für die Lebensmittellieferung in Meituan. 3.3.4 Fusionsoptimierung
3.3.5 Motoroptimierung
3.3.6 Pipeline
 Mit der iterativen Entwicklung von Modellen sind DNN-Modelle jedoch allmählich zum Mainstream geworden, und auch die Nachteile der Matrixübertragung liegen auf der Hand:
Mit der iterativen Entwicklung von Modellen sind DNN-Modelle jedoch allmählich zum Mainstream geworden, und auch die Nachteile der Matrixübertragung liegen auf der Hand:
 Die meisten tatsächlichen Online-Modelle sind TF-Modelle. Um den Übertragungsverbrauch weiter zu senken, hat die Plattform das Tensorsequenzformat zum Speichern jeder Tensormatrix entwickelt: Darunter wird r_flag verwendet Markieren Sie, ob es sich um ein Artikelklassenmerkmal handelt. Die Länge stellt die Länge des Artikelmerkmals dar. Der Wert ist M (Artikelnummer ) × NF (Merkmalslänge ), die Daten sind Wird zum Speichern des tatsächlichen Merkmalswerts verwendet. Für das Elementmerkmal werden M-Merkmalswerte flach gespeichert, und für das Anforderungstypmerkmal werden sie direkt gefüllt. Basierend auf dem kompakten Tensor-Sequenz-Format ist die Datenstruktur kompakter und die über das Netzwerk übertragene Datenmenge wird reduziert. Das optimierte Übertragungsformat hat auch online gute Ergebnisse erzielt. Die Anforderungsgröße der Routing-Schicht, die die Computerschicht aufruft, wurde um mehr als 50 % reduziert und die Netzwerkübertragungszeit wurde erheblich verkürzt.
Die meisten tatsächlichen Online-Modelle sind TF-Modelle. Um den Übertragungsverbrauch weiter zu senken, hat die Plattform das Tensorsequenzformat zum Speichern jeder Tensormatrix entwickelt: Darunter wird r_flag verwendet Markieren Sie, ob es sich um ein Artikelklassenmerkmal handelt. Die Länge stellt die Länge des Artikelmerkmals dar. Der Wert ist M (Artikelnummer ) × NF (Merkmalslänge ), die Daten sind Wird zum Speichern des tatsächlichen Merkmalswerts verwendet. Für das Elementmerkmal werden M-Merkmalswerte flach gespeichert, und für das Anforderungstypmerkmal werden sie direkt gefüllt. Basierend auf dem kompakten Tensor-Sequenz-Format ist die Datenstruktur kompakter und die über das Netzwerk übertragene Datenmenge wird reduziert. Das optimierte Übertragungsformat hat auch online gute Ergebnisse erzielt. Die Anforderungsgröße der Routing-Schicht, die die Computerschicht aufruft, wurde um mehr als 50 % reduziert und die Netzwerkübertragungszeit wurde erheblich verkürzt. 4.3 Hochdimensionale ID-Feature-Codierung
5 Beispielkonstruktion
5.1 Fließbeispiel

5.1.1 Gemeinsame Lösungen
5.1.2 Verbesserung und Optimierung
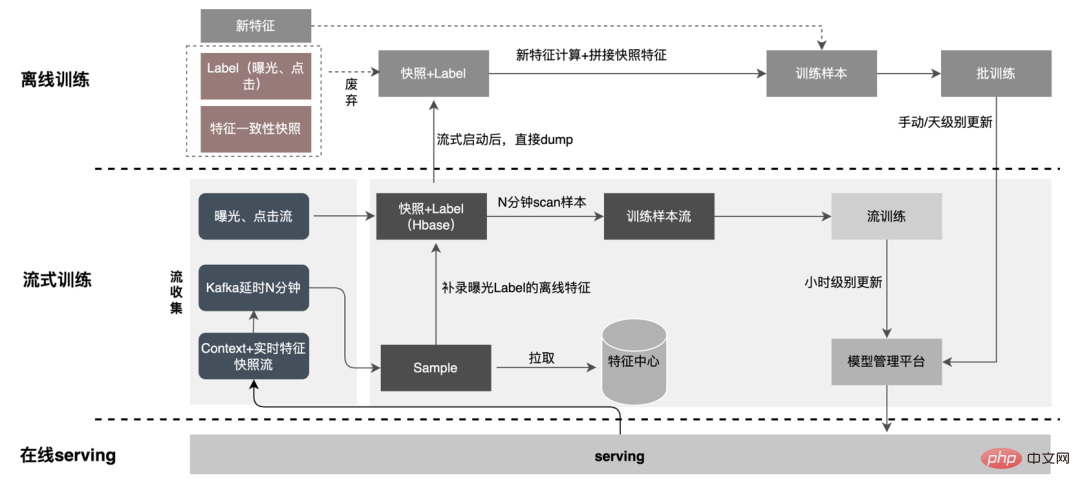
2. Verzögerter Verbrauch Join-Methode
3. Beispiel für einen Feature-Ergänzungseintrag Mit der Geschäftsiteration wird die Anzahl der Features im Feature-Snapshot immer größer, wodurch der gesamte Feature-Snapshot entsteht In einem einzigen Geschäftsszenario erreicht es Dutzende von TB pro Tag. Aus Speichersicht befinden sich die Feature-Snapshots eines einzelnen Unternehmens über mehrere Tage bereits auf dem PB-Niveau und stehen kurz vor dem Erreichen der Speicherschwelle des Werbealgorithmus ,
enormer Speicherdruck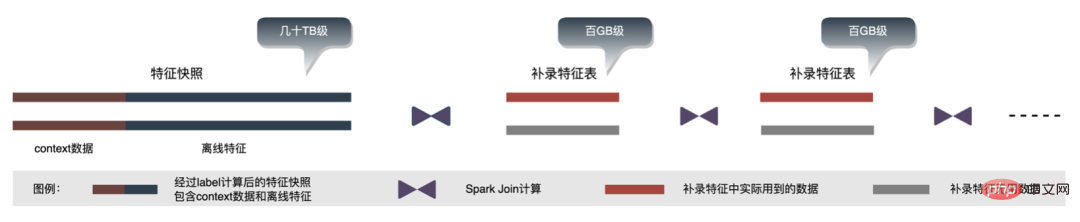
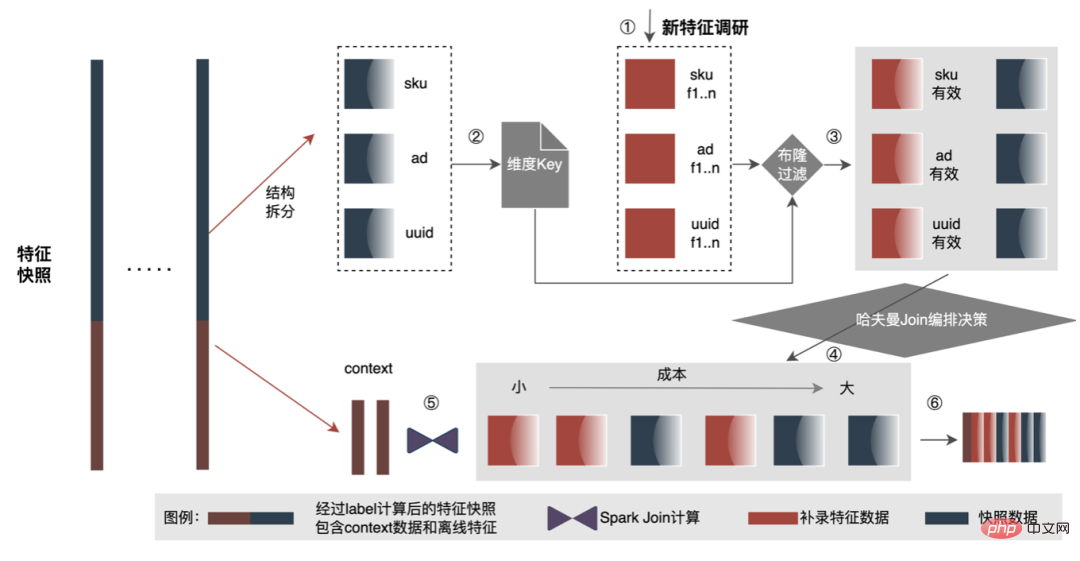
6.2 „Subtraktion“ durchführen

) ermittelt. und die Bewertungen sind relativ hoch. Merkmale haben eine höhere Qualität und eine höhere Bewertungsgenauigkeit.
Auf dieser Plattform haben wir eine universelle Muster-Sharing-Plattform eingerichtet Geschäftsvolumen können ausgeliehen werden, um inkrementelle Stichproben zu generieren. Außerdem wird eine gemeinsame Embedding-Sharing-Architektur erstellt, um die Integration großer und kleiner Unternehmen zu realisieren. Das Folgende ist ein Beispiel für die Wiederverwendung von Nicht-Werbemustern im Werbegeschäft. Die spezifische Methode ist wie folgt:
6.4 Führen Sie eine „Division“ durch
7 Zusammenfassung und Ausblick
8 Der Autor dieses Artikels ist
Das obige ist der detaillierte Inhalt vonIngenieurspraxis eines groß angelegten Deep-Learning-Modells für Take-Away-Werbung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr