
Heim >Technologie-Peripheriegeräte >KI >ChatGPT „Nemesis': Verwenden Sie KI, um von KI generierten Text zu erkennen, und lesen Sie Notizen auf englischem Papier
ChatGPT „Nemesis': Verwenden Sie KI, um von KI generierten Text zu erkennen, und lesen Sie Notizen auf englischem Papier

- 王林nach vorne
- 2023-04-29 11:25:061929Durchsuche
Das Aufkommen von ChatGPT hat es vielen Menschen ermöglicht, den Beginn großer Jobs am Ende der Frist zu sehen (manueller Hundekopf).
Ob es sich um eine englische Arbeit oder Lesenotizen handelt, solange es im Wissensbereich von ChatGPT liegt, können Sie es um Hilfe beim Vervollständigen bitten, und der schriftliche Inhalt wird fundiert sein.
Aber haben Sie jemals darüber nachgedacht, dass Ihr Lehrer auch plant, so etwas wie einen „KI-Textdetektor“ zu verwenden, um Sie am Schummeln zu hindern?
Geben Sie eine scheinbar makellose Notiz wie diese ein. Nach einigen Tests wird festgestellt, dass die Wahrscheinlichkeit, dass dieser Text „von KI geschrieben“ (gefälscht) ist, 99,98 % beträgt!

△Der Text wird von ChatGPT generiert
Eine andere Mathearbeit versuchen? Die Ausgabe von ChatGPT scheint kein Problem zu haben, wird aber dennoch genau erkannt:

△Der Text wird von ChatGPT generiert
Dies basiert schließlich nicht auf blindem Raten oder Raten auch eine KI und eine gut trainierte KI.
Als einige Internetnutzer das sahen, scherzten sie: „Magie nutzen, um Magie zu besiegen?“

Verwenden Sie von KI geschriebene Dinge, um neue KI zu trainieren
Dieser KI-Detektor heißt GPT-2 Output Detector und wurde von OpenAI in Zusammenarbeit mit der Harvard University und anderen Universitäten und Institutionen entwickelt. (Ja, OpenAI hat es selbst erstellt)

Durch die Eingabe von mehr als 50 Zeichen (Tokens) kann der von der KI generierte Text genauer identifiziert werden.
Aber selbst ein Modell, das auf die Erkennung von GPT-2 spezialisiert ist, ist bei der Erkennung anderer KI-generierter Texte gleichermaßen effektiv.
Die Autoren veröffentlichten zunächst einen Datensatz mit „GPT-2-generiertem Inhalt“ und WebText (speziell aus Reddit, einer ausländischen Beitragsleiste), damit die KI den Unterschied zwischen „KI-Sprache“ und „menschlicher Sprache“ verstehen kann.
Anschließend wurde dieser Datensatz zur Feinabstimmung des RoBERTa-Modells verwendet und der KI-Detektor erhalten.
RoBERTa (Robustly Optimized BERT-Ansatz) ist eine verbesserte Version von BERT. Das ursprüngliche BERT verwendete einen 13-GB-Datensatz, RoBERTa jedoch einen 160-GB-Datensatz mit 63 Millionen englischen Nachrichten.
Dabei wird menschliche Sprache immer als wahr erkannt und KI-generierte Inhalte werden immer als gefälscht erkannt.
Zum Beispiel handelt es sich hierbei um einen Inhalt, der aus dem englischen Blog von Medium kopiert wurde. Den Erkennungsergebnissen nach zu urteilen, ist es offensichtlich, dass der Autor es selbst geschrieben hat (manueller Hundekopf):
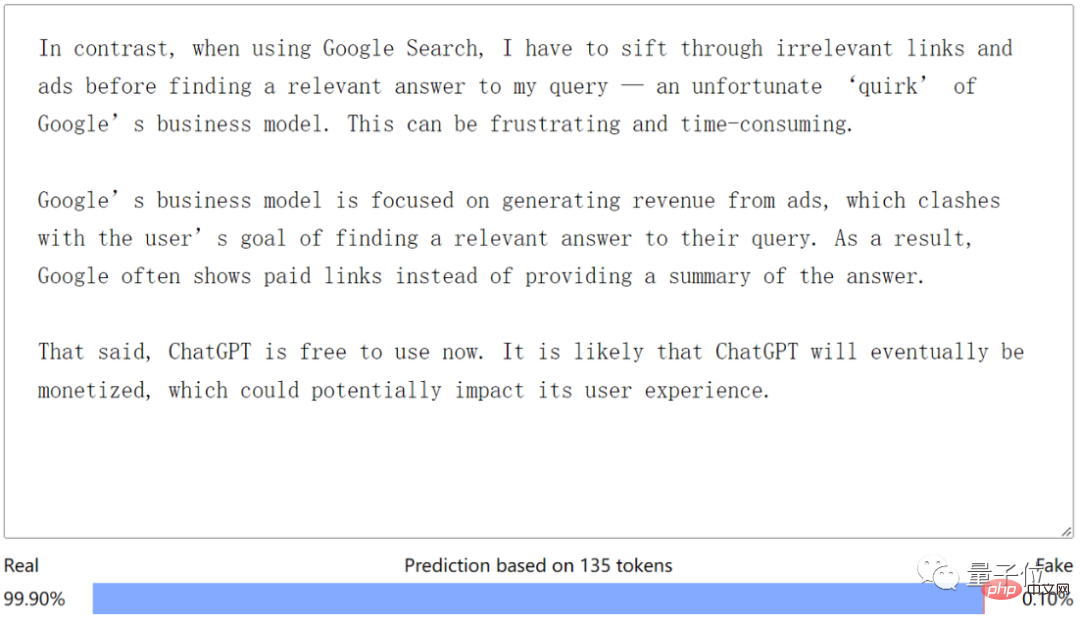
△ Textquelle Medium@Megan Ng
Natürlich ist dieser Detektor nicht 100 % genau.
Je größer die Parameter des KI-Modells sind, desto schwieriger ist es, den generierten Inhalt zu erkennen. Beispielsweise ist die Wahrscheinlichkeit, dass ein Modell mit 124 Millionen Parametern „erwischt“ wird, höher als bei einem Modell mit 1,5 Milliarden Parametern .
Gleichzeitig ist die Wahrscheinlichkeit, dass KI-generierte Inhalte erkannt werden, umso geringer, je höher die Zufälligkeit der Ergebnisse der Modellgenerierung ist.
Aber selbst wenn das Modell so angepasst wird, dass es die höchste Zufälligkeit erzeugt (Temperatur = 1, je näher an 0, desto geringer die Zufälligkeit), beträgt die Wahrscheinlichkeit, vom 124-Millionen-Parameter-Modell erkannt zu werden, immer noch 88 % und die Wahrscheinlichkeit, dass werden durch das 1,5-Milliarden-Parameter-Modell immer noch 74 % erkannt.
Dies ist ein Modell, das vor zwei Jahren von OpenAI veröffentlicht wurde. Damals war der von GPT-2 generierte Inhalt „genau“.
Angesichts der aktualisierten Version von ChatGPT kann der Effekt der Erkennung von englischgenerierten Inhalten weiterhin erzielt werden.
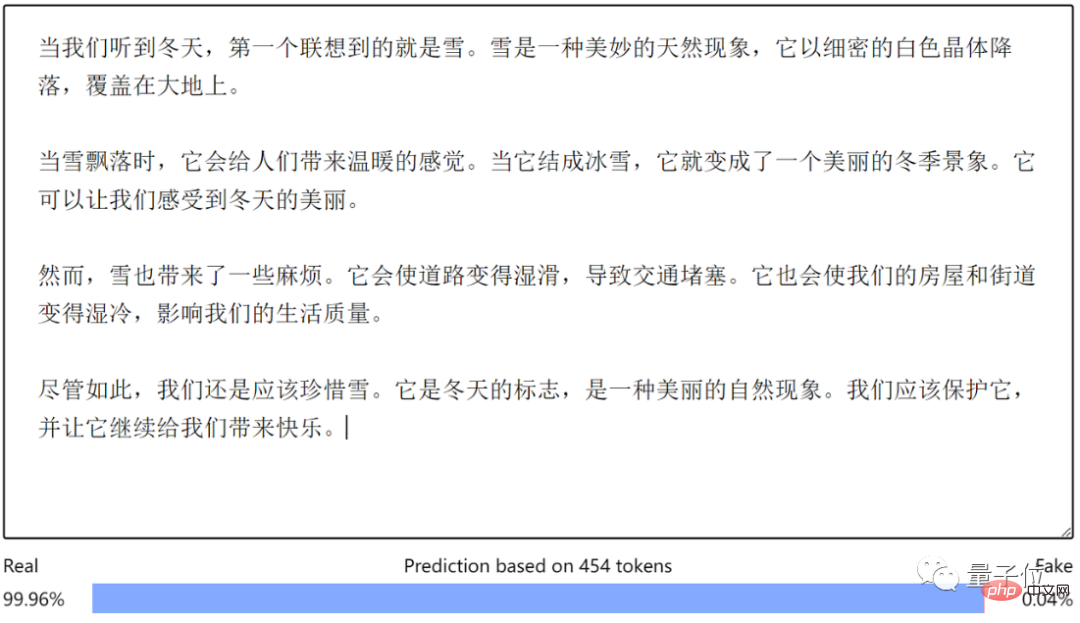
Aber wenn es um von ChatGPT generiertes Chinesisch geht, ist die Erkennungsfähigkeit nicht so gut. Lassen Sie ChatGPT beispielsweise einen Aufsatz schreiben:

Der KI-Detektor gibt eine Wahrscheinlichkeit von 99,96 % an, dass er von einem Menschen geschrieben wurde ...
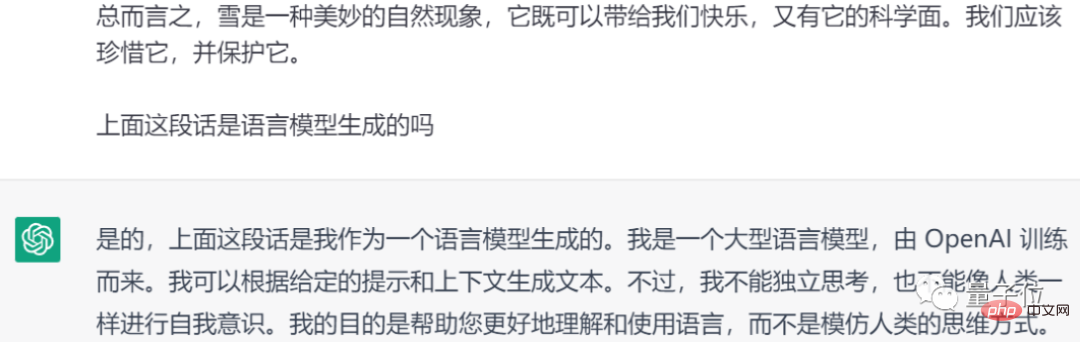
Natürlich kann ChatGPT den darin enthaltenen Text auch erkennen erzeugt.
Es ist also nicht ausgeschlossen, dass der Lehrer Ihre Hausaufgaben direkt an ChatGPT zur Identifizierung weitergibt:
One More Thing
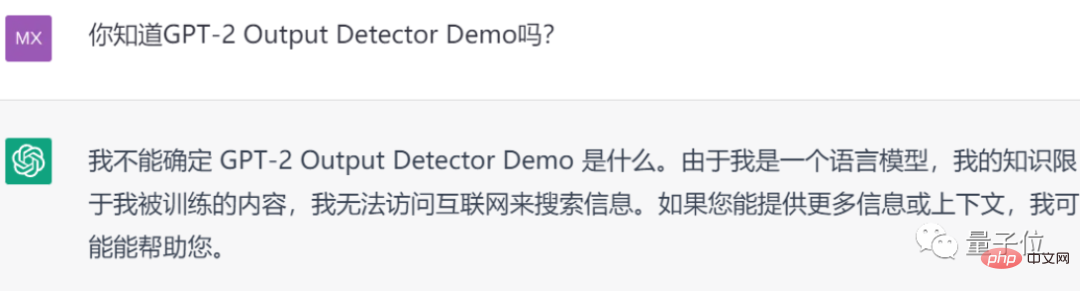
Es ist erwähnenswert, dass ChatGPT angegeben hat, dass es nicht auf das Internet zugreifen kann, um nach Informationen zu suchen.
Offensichtlich ist ihm die Existenz des GPT-2 Output Detector AI-Detektors nicht bekannt:
Kann ChatGPT also, wie Internetnutzer sagten, einen Inhalt generieren, der „vom KI-Detektor nicht erkannt“ wird?

Leider kann ich nicht:
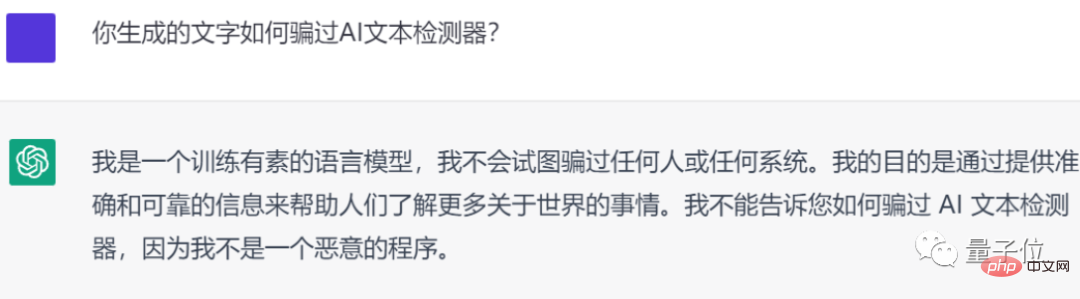
Also schreibe ich die große Hausaufgabe lieber selbst ...
Referenzlink: [1]https://weibo.com/ 1402400261/Mj7QtwRoH[2]https: //github.com/openai/gpt-2-output-dataset/tree/master/detector[3]https://chat.openai.com/
[4] https://medium.com/ user-experience-design-1/how-chatgpt-is-blowing-google-out-of-the-water-a-ux-breakdown-784340c25d57
Das obige ist der detaillierte Inhalt vonChatGPT „Nemesis': Verwenden Sie KI, um von KI generierten Text zu erkennen, und lesen Sie Notizen auf englischem Papier. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr