
Heim >Technologie-Peripheriegeräte >KI >DAMO-YOLO: ein effizientes Zielerkennungs-Framework, das sowohl Geschwindigkeit als auch Genauigkeit berücksichtigt
DAMO-YOLO: ein effizientes Zielerkennungs-Framework, das sowohl Geschwindigkeit als auch Genauigkeit berücksichtigt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-28 16:43:062191Durchsuche

1. Einführung in die Zielerkennung
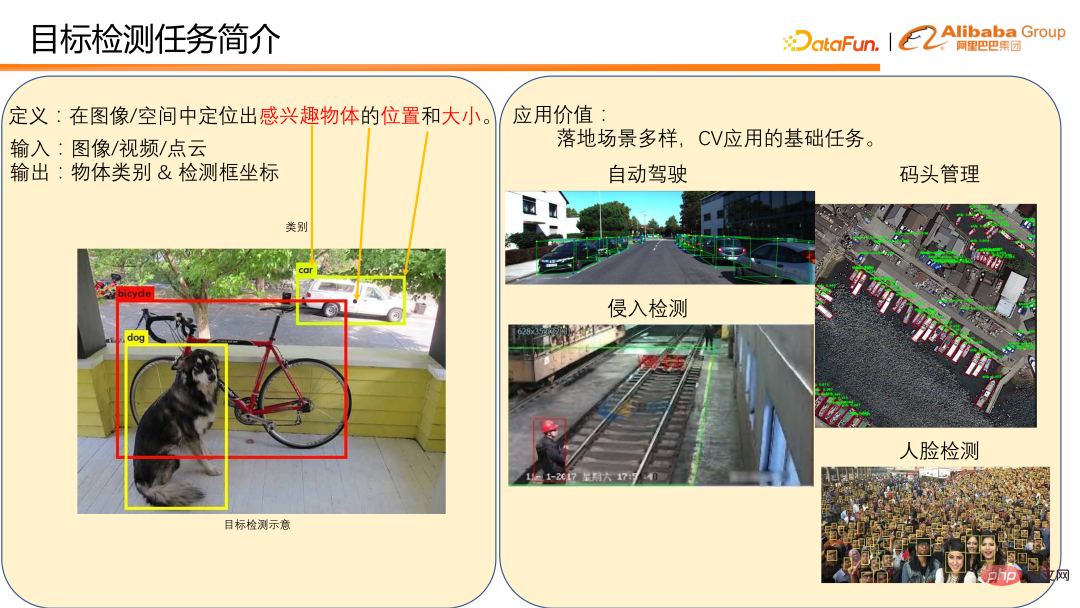
Die Definition der Zielerkennung besteht darin, die Position und Größe eines interessierenden Objekts in einem Bild/Raum zu lokalisieren.
Im Allgemeinen geben Sie ein Bild, ein Video oder eine Punktwolke ein und geben die Objektkategorie und die Koordinaten des Erkennungsrahmens aus. Das Bild unten links ist ein Beispiel für die Objekterkennung auf einem Bild. Es gibt viele Anwendungsszenarien für die Zielerkennung, beispielsweise die Fahrzeug- und Fußgängererkennung in autonomen Fahrszenarien und die Anlegestellenerkennung im Dockmanagement. Bei beiden handelt es sich um direkte Anwendungen zur Objekterkennung. Die Zielerkennung ist auch eine grundlegende Aufgabe für viele CV-Anwendungen, wie z. B. die Erkennung von Eindringlingen und die Gesichtserkennung in Fabriken. Diese erfordern die Erkennung von Fußgängern und Gesichtern als Grundlage für die Erfüllung der Erkennungsaufgabe. Es ist ersichtlich, dass die Zielerkennung viele wichtige Anwendungen im täglichen Leben hat und ihre Position bei der Umsetzung von Lebensläufen ebenfalls sehr wichtig ist, sodass es sich hier um einen Bereich mit harter Konkurrenz handelt.
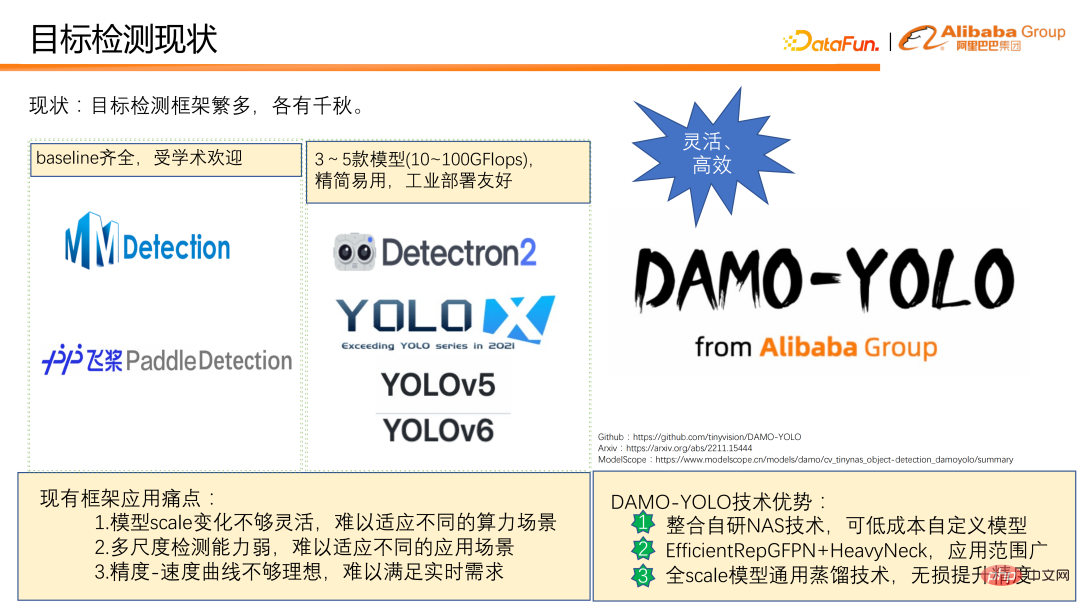
Es gibt derzeit viele Zielerkennungs-Frameworks mit eigenen Eigenschaften. Basierend auf unserer gesammelten Erfahrung im tatsächlichen Einsatz haben wir festgestellt, dass das aktuelle Erkennungsframework in der praktischen Anwendung immer noch die folgenden Schwachstellen aufweist:
① Die Modellmaßstabsänderungen sind nicht flexibel genug und lassen sich nur schwer an unterschiedliche Rechenleistungsszenarien anpassen . Beispielsweise bietet das Erkennungsframework der YOLO-Serie im Allgemeinen nur die Berechnungsmenge von 3 bis 5 Modellen im Bereich von einem Dutzend bis mehr als hundert Flops, was es schwierig macht, verschiedene Rechenleistungsszenarien abzudecken.
② Die Fähigkeit zur Erkennung mehrerer Skalen ist schwach, insbesondere die Erkennungsleistung für kleine Objekte ist schlecht, was die Anwendungsszenarien des Modells sehr begrenzt macht. Beispielsweise sind die Ergebnisse bei Drohnenerkennungsszenarien oft nicht optimal.
③ Die Geschwindigkeits-/Genauigkeitskurve ist nicht ideal genug und es ist schwierig, Geschwindigkeit und Genauigkeit gleichzeitig zu vereinbaren.
Als Reaktion auf die oben genannte Situation haben wir DAMO-YOLO entworfen und als Open-Source-Lösung bereitgestellt. DAMO-YOLO konzentriert sich hauptsächlich auf die industrielle Umsetzung. Im Vergleich zu anderen Zielerkennungs-Frameworks bietet es drei offensichtliche technische Vorteile:
① Es integriert selbst entwickelte NAS-Technologie und kann Modelle zu geringen Kosten anpassen, sodass Benutzer die Rechenleistung des Chips voll ausnutzen können.
② Durch die Kombination der Modellentwurfsparadigmen „Efficient RepGFPN“ und „HeavyNeck“ können die Multiskalenerkennungsfähigkeiten des Modells erheblich verbessert und der Anwendungsbereich des Modells erweitert werden.
③ Schlägt eine umfassende universelle Destillationstechnologie vor, mit der die Genauigkeit kleiner, mittlerer und großer Modelle problemlos verbessert werden kann.
Im Folgenden werden wir DAMO-YOLO anhand der drei technischen Vorteile weiter analysieren.
2. Technischer Wert von DAMO-YOLO
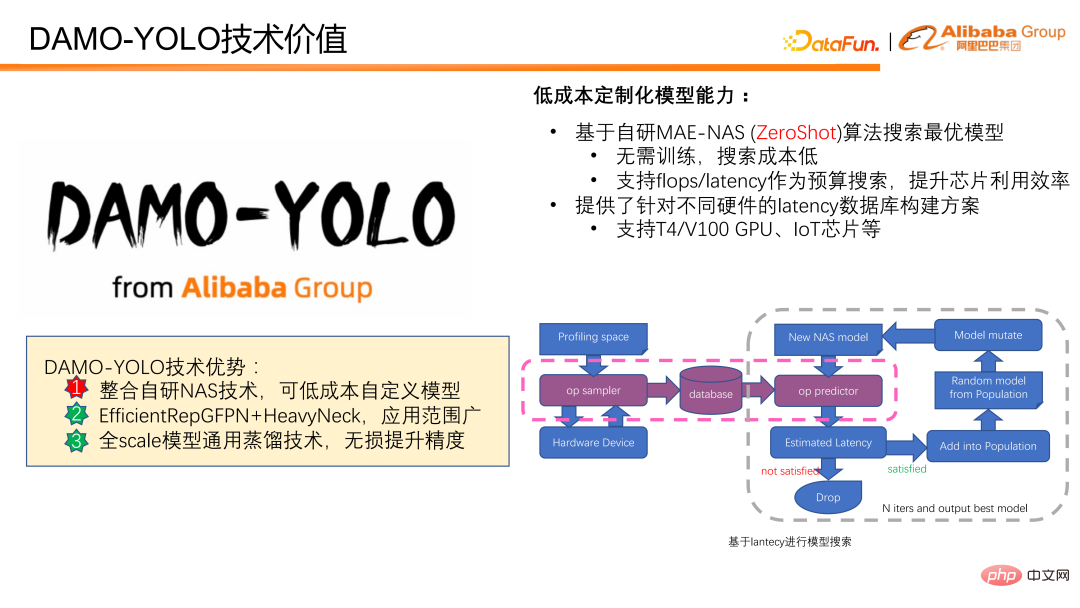
DAMO-YOLO realisiert eine kostengünstige Modellanpassung und basiert auf dem selbst entwickelten MAE-NAS-Algorithmus. Modelle können je nach Latenz oder FLOPS-Budget kostengünstig angepasst werden. Für die Bereitstellung von Modellbewertungsergebnissen ist kein Modelltraining oder die Beteiligung realer Daten erforderlich, und die Kosten für die Modellsuche sind gering. Durch gezielte FLOPS kann die Rechenleistung des Chips voll ausgenutzt werden. Die Suche mit Verzögerung als Budget eignet sich sehr gut für verschiedene Szenarien, die strenge Anforderungen an die Verzögerung stellen. Wir bieten auch Datenbankkonstruktionslösungen an, die verschiedene Hardware-Verzögerungsszenarien unterstützen und es so für jeden einfacher machen, nach Verzögerungen als Ziel zu suchen.
Die folgende Abbildung zeigt, wie die Zeitverzögerung für die Modellsuche verwendet wird. Abtasten Sie zunächst den Zielchip oder das Zielgerät, um die Verzögerungen aller möglichen Operatoren zu erhalten, und sagen Sie dann die Verzögerung des Modells basierend auf den Verzögerungsdaten voraus. Wenn die vorhergesagte Modellgröße dem voreingestellten Ziel entspricht, führt das Modell nachfolgende Modellaktualisierungen und Bewertungsberechnungen durch. Schließlich wird nach der iterativen Aktualisierung das optimale Modell erhalten, das die Verzögerungsbeschränkungen erfüllt.
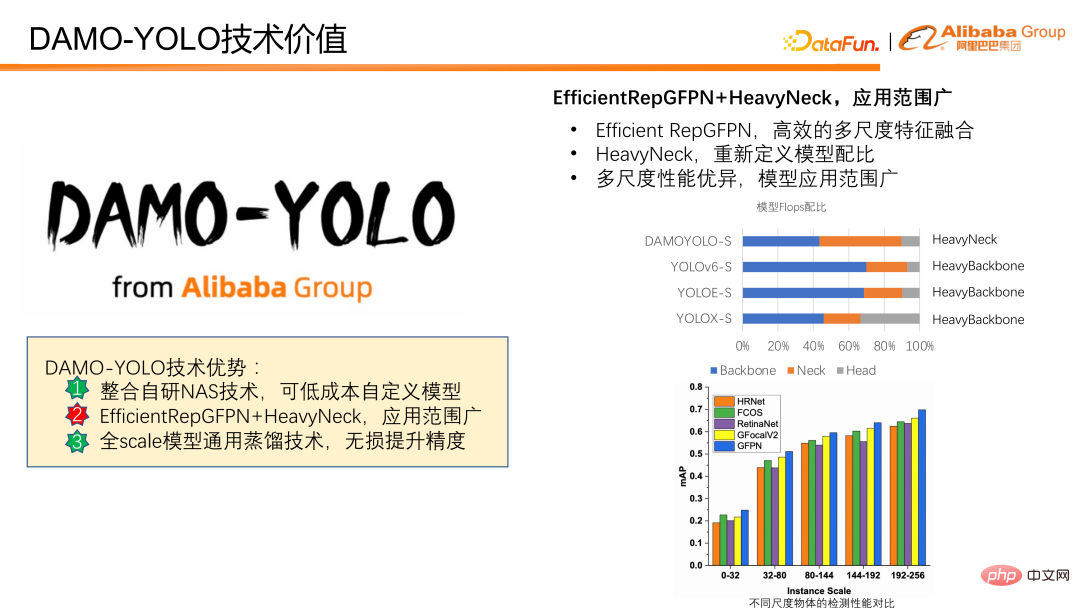
Als Nächstes stellen wir vor, wie die Multiskalenerkennungsfähigkeit des Modells verbessert werden kann. DAMO-YOLO kombiniert das vorgeschlagene Efficient RepGFPN und das innovative HeavyNeck, was die Multiskalen-Erkennungsfähigkeiten deutlich verbessert. Effizientes RepGFPN kann die Multiskalen-Feature-Fusion effizient abschließen. Das HeavyNeck-Paradigma bezieht sich auf die Zuweisung einer großen Anzahl von FLOPS des Modells zur Feature-Fusion-Schicht. Wie zum Beispiel die Modell-FLOPS-Verhältnistabelle. Am Beispiel von DAMO-YOLO-S macht der Berechnungsbetrag des Halses fast die Hälfte des gesamten Modells aus, was sich deutlich von anderen Modellen unterscheidet, bei denen der Berechnungsbetrag hauptsächlich auf das Rückgrat gelegt wird.
Abschließend wird das Destillationsmodell vorgestellt. Unter Destillation versteht man die Übertragung des Wissens eines großen Modells auf ein kleines Modell, wodurch die Leistung des kleinen Modells verbessert wird, ohne dass eine Argumentationslast entsteht. Die Modelldestillation ist ein leistungsstarkes Werkzeug zur Verbesserung der Effizienz von Erkennungsmodellen. Die Forschung in Wissenschaft und Industrie beschränkt sich jedoch meist auf große Modelle, und es mangelt an Destillationslösungen für kleine Modelle. DAMO-YOLO bietet eine Reihe von Destillationen, die allen maßstabsgetreuen Modellen gemeinsam sind. Diese Lösung kann nicht nur erhebliche Verbesserungen bei Modellen im Originalmaßstab erzielen, sondern verfügt auch über eine hohe Robustheit. Sie verwendet dynamische Gewichte, ohne dass Parameter angepasst werden müssen, und die Destillation kann mit Ein-Klick-Skripten durchgeführt werden. Darüber hinaus ist dieses Schema auch robust gegenüber der heterogenen Destillation, was für das oben erwähnte kostengünstige kundenspezifische Modell von großer Bedeutung ist. Im NAS-Modell ist die strukturelle Ähnlichkeit zwischen dem durch die Suche erhaltenen kleinen Modell und dem großen Modell nicht garantiert. Liegt eine heterogen robuste Destillation vor, können die Vorteile von NAS und Destillation voll ausgenutzt werden. Die folgende Abbildung zeigt unsere Leistung bei der Destillation. Es ist ersichtlich, dass es nach der Destillation unabhängig vom T-Modell, S-Modell oder M-Modell eine stabile Verbesserung gibt.

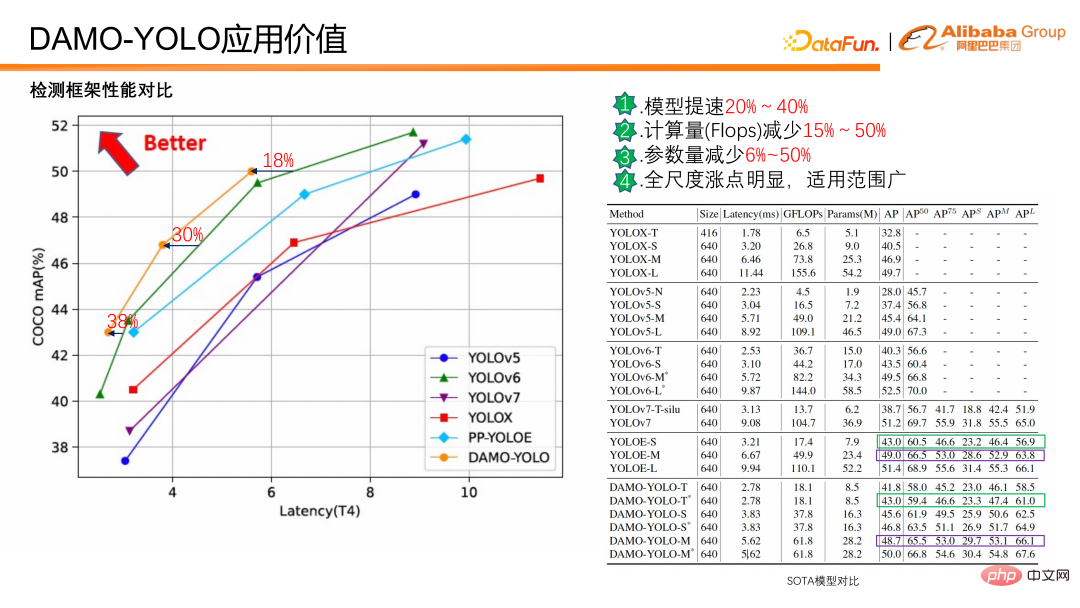
Wie viel Anwendungswert kann basierend auf dem oben genannten technischen Wert umgewandelt werden? Im Folgenden wird der Vergleich zwischen DAMO-YOLO und anderen aktuellen SOTA-Erkennungs-Frameworks vorgestellt.
DAMO-YOLO Im Vergleich zum aktuellen SOTA ist die Modellgeschwindigkeit bei gleicher Genauigkeit 20 % bis 40 % schneller, der Berechnungsaufwand wird um 15 % bis 50 % reduziert und die Parameter werden um 6 % reduziert -50 % Die Steigerung im Gesamtmaßstab ist offensichtlich und in einem weiten Bereich anwendbar. Darüber hinaus gibt es offensichtliche Verbesserungen sowohl bei kleinen als auch bei großen Objekten.
Wie aus dem obigen Datenvergleich hervorgeht, ist DAMO-YOLO schnell, flopsarm und verfügt über ein breites Anwendungsspektrum; es kann auch Modelle basierend auf der Rechenleistung anpassen, um die Effizienz der Chipnutzung zu verbessern.
Relevante Modelle wurden auf ModelScope eingeführt und können durch die Konfiguration von drei bis fünf Codezeilen getestet werden. Wenn Sie während der Verwendung Fragen oder Kommentare haben, hinterlassen Sie bitte eine Nachricht den Kommentarbereich.
Als nächstes konzentrieren wir uns auf die 3 technischen Vorteile von DAMO-YOLO und stellen die Prinzipien dahinter vor, um allen zu helfen, DAMO-YOLO besser zu verstehen und zu nutzen.
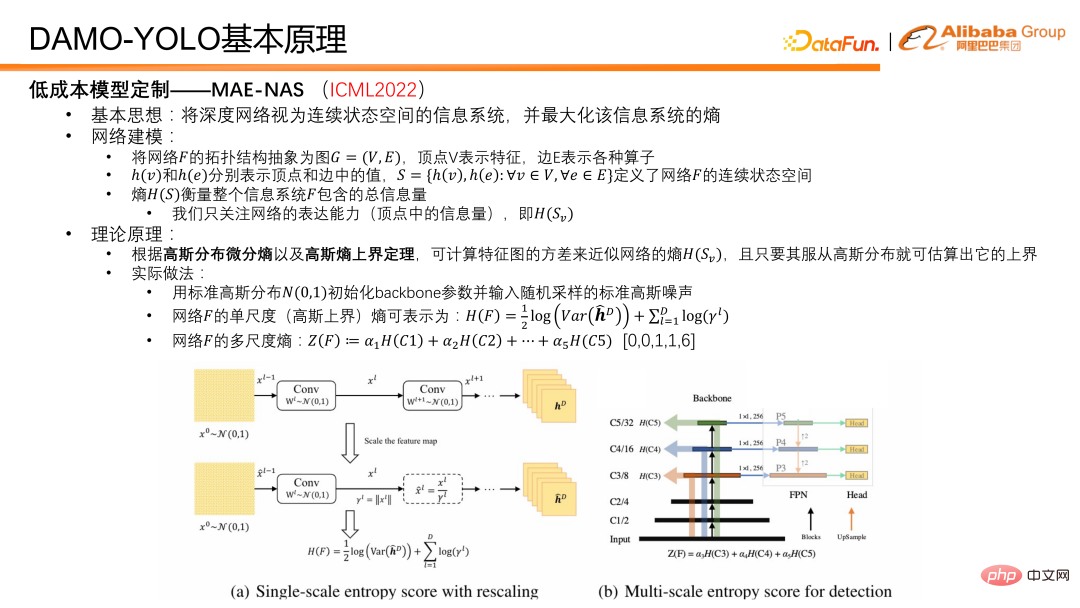
4. Einführung in das Prinzip von DAMO-YOLOZuerst stellen wir die Schlüsseltechnologie der kostengünstigen Modellanpassungsfähigkeit MAE-NAS vor. Seine Grundidee besteht darin, ein tiefes Netzwerk als ein Informationssystem mit einem kontinuierlichen Zustandsraum zu betrachten und die Entropie zu finden, die das Informationssystem maximieren kann.
Die Idee der Netzwerkmodellierung ist wie folgt: Abstrahieren Sie die topologische Struktur des Netzwerks F in einen Graphen G=(V,E), wobei der Scheitelpunkt V das Merkmal und die Kante E verschiedene Operatoren darstellt. Auf dieser Basis können h(v) und h(e) verwendet werden, um die Werte in Eckpunkten bzw. Kanten darzustellen, und eine solche Menge S generiert werden, die den kontinuierlichen Zustandsraum des Netzwerks und die Entropie definiert der Menge S kann die Gesamtmenge an Informationen im Netzwerk oder Informationssystem F darstellen. Die Informationsmenge der Scheitelpunkte misst die Ausdrucksfähigkeit des Netzwerks, und die Informationsmenge der Kanten ist auch die Entropie der Kanten, die die Komplexität des Netzwerks misst. Bei der DAMO-YOLO-Zielerkennungsaufgabe besteht unser Hauptanliegen darin, die Ausdrucksfähigkeit des Netzwerks zu maximieren. In praktischen Anwendungen geht es nur um die Entropie von Netzwerkmerkmalen. Gemäß der Differentialentropie der Gaußschen Verteilung und dem Obergrenzensatz der Gaußschen Entropie verwenden wir die Varianz der Merkmalskarte, um die Obergrenze der Merkmalsentropie des Netzwerks anzunähern.
Im tatsächlichen Betrieb initialisieren wir zunächst die Gewichte des Netzwerk-Backbones mit einer Standard-Gaußschen Verteilung und verwenden als Eingabe ein Standard-Gaußsches Rauschbild. Nachdem das Gaußsche Rauschen für den Vorwärtsdurchlauf in das Netzwerk eingespeist wurde, können mehrere Merkmale erhalten werden. Dann wird die Einzelskalen-Entropie berechnet, dh die Varianz jedes Skalenmerkmals, und dann wird die Mehrskalen-Entropie durch Gewichtung erhalten. Im Gewichtungsprozess werden A-priori-Koeffizienten verwendet, um die Ausdrucksfähigkeiten von Merkmalen in verschiedenen Maßstäben auszugleichen. Dieser Parameter ist im Allgemeinen auf [0,0,1,1,6] eingestellt. Der Grund dafür ist folgender: Weil im Erkennungsmodell die allgemeinen Merkmale in fünf Stufen, also fünf verschiedene Auflösungen, von 1/2 bis 1/32 unterteilt sind. Um eine effiziente Funktionsnutzung aufrechtzuerhalten, nutzen wir nur die letzten drei Stufen. Tatsächlich nehmen die ersten beiden Stufen also nicht an der Vorhersage des Modells teil, sie sind also 0 und 0. Für die anderen drei haben wir umfangreiche Experimente durchgeführt und festgestellt, dass 1, 1 und 6 ein besseres Modellverhältnis darstellen.
Basierend auf den oben genannten Grundprinzipien können wir die Multiskalen-Entropie des Netzwerks als Leistungsproxy und den Reinigungsalgorithmus als Grundgerüst für die Suche nach der Netzwerkstruktur verwenden, die es ausmacht ein komplettes MAE-NAS. NAS hat viele Vorteile. Erstens unterstützt es mehrere Inferenzbudgetbeschränkungen und kann FLOPS, Parametermenge, Latenz und Netzwerkschichtnummer verwenden, um eine Modellsuche durchzuführen. Zweitens unterstützt es auch sehr viele Variationen feinkörniger Netzwerkstrukturen. Da hier ein evolutionärer Algorithmus zur Durchführung der Netzwerksuche verwendet wird, ist der Grad der Anpassung und Flexibilität bei der Suche umso höher, je mehr Varianten von Netzwerkstrukturen unterstützt werden. Um Benutzern die Anpassung des Suchvorgangs zu erleichtern, stellen wir außerdem offizielle Tutorials zur Verfügung. Schließlich und am wichtigsten ist, dass MAE-NAS nullkurz ist, das heißt, seine Suche erfordert keine tatsächliche Datenbeteiligung und erfordert kein tatsächliches Modelltraining. Es durchsucht die CPU mehrere zehn Minuten lang und kann unter den aktuellen Einschränkungen ein optimales Netzwerkergebnis erzielen.
In DAMO-YOLO verwenden wir MAE-NAS, um das Backbone-Netzwerk des T/S/M-Modells mit unterschiedlichen Verzögerungen als Suchziele zu durchsuchen; wir packen die durchsuchte Backbone-Netzwerk-Infrastruktur und verwenden ResStyle für kleine Modelle. Große Modelle verwenden CSPStyle.
Wie aus der folgenden Tabelle ersichtlich ist, ist CSP-Darknet ein manuell entworfenes Netzwerk, das die CSP-Struktur verwendet und auch in YOLO v 5/V6 einige weit verbreitete Anwendungen erreicht hat. Wir haben MAE-NAS verwendet, um eine Grundstruktur zu generieren, und nachdem wir sie mit CSP verpackt hatten, stellten wir fest, dass die Geschwindigkeit und Genauigkeit des Modells deutlich verbessert wurde. Darüber hinaus können Sie das MAE-ResNet-Formular auf kleinen Modellen sehen, das eine höhere Genauigkeit aufweist. Es gibt einen klaren Vorteil bei der Verwendung der CPS-Struktur bei großen Modellen, die 48,7 erreichen können.

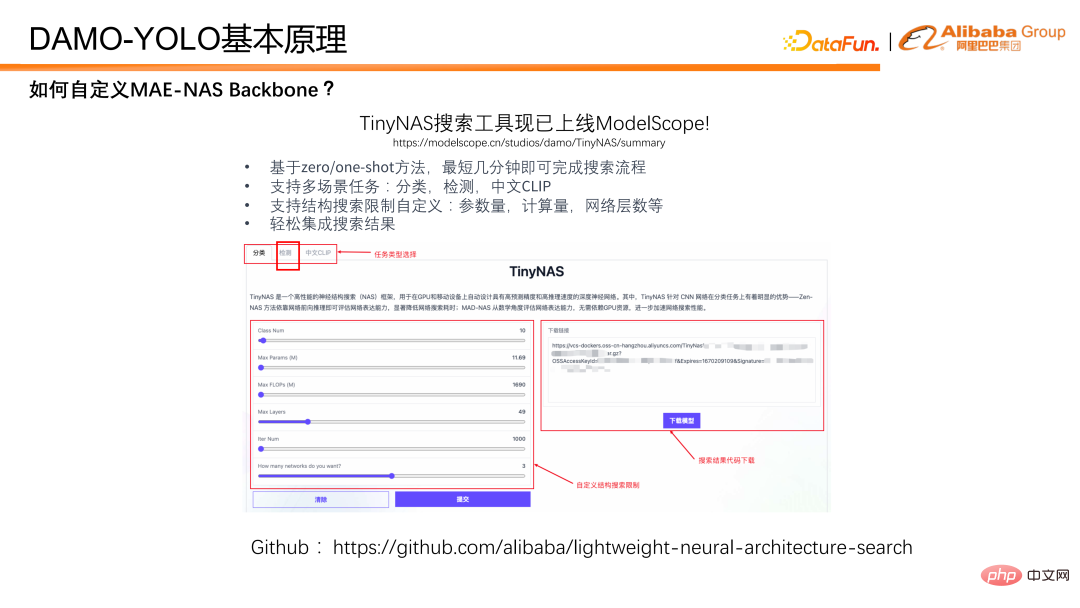
Wie verwende ich MAE-NAS, um eine Backbone-Suche durchzuführen? Hier stellen wir unsere TinyNAS-Toolbox vor, die bereits online in ModelScope verfügbar ist. Sie können das gewünschte Modell einfach durch visuelle Konfiguration auf der Webseite erhalten. Gleichzeitig wurde MAE-NAS auch auf Github als Open-Source-Lösung bereitgestellt. Interessierte Studierende können auf Basis des Open-Source-Codes mit größerer Freiheit nach dem gewünschten Modell suchen.
Als nächstes stellen wir vor, wie DAMO-YOLO die Erkennungsfähigkeiten auf mehreren Skalen verbessert. Es basiert auf der Fusion verschiedener Skalenfunktionen des Netzwerks. In früheren Erkennungsnetzwerken variierte die Tiefe der Merkmale in verschiedenen Maßstäben stark. Beispielsweise werden Merkmale mit hoher Auflösung zur Erkennung kleiner Objekte verwendet, ihre Merkmalstiefe ist jedoch gering, was sich auf die Erkennungsleistung kleiner Objekte auswirkt.
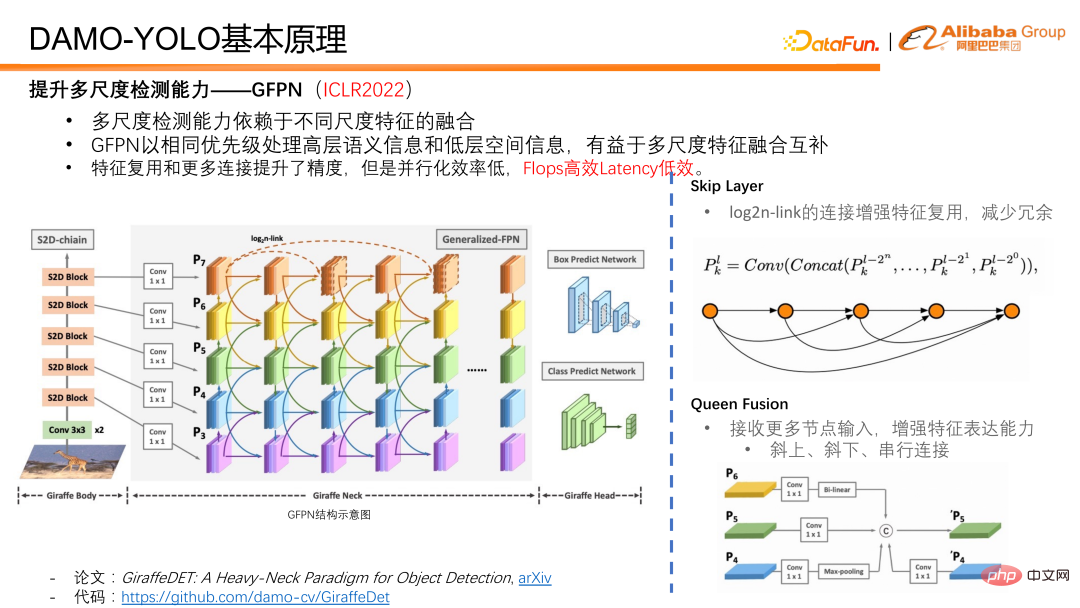
Eine Arbeit, die wir auf der ICLR2022 – GFPN vorgeschlagen haben, verarbeitet semantische Informationen auf hoher Ebene und räumliche Informationen auf niedriger Ebene mit derselben Priorität und ist sehr freundlich zur Fusion und Ergänzung von Merkmalen mit mehreren Maßstäben. Beim Design von GFPN haben wir zunächst eine Sprungschicht eingeführt, um ein tieferes Design von GFPN zu ermöglichen. Wir verwenden einen Log2n-Link, um Funktionen wiederzuverwenden und Redundanz zu reduzieren.
Queen Fusion soll die interaktive Fusion von Features unterschiedlicher Größenordnung und Features unterschiedlicher Tiefe verbessern. Jeder Knoten in der Queen-Fusion empfängt nicht nur unterschiedliche Skalenmerkmale diagonal darüber und darunter, sondern erhält auch unterschiedliche Skalenmerkmale in derselben Merkmalstiefe, was die Informationsmenge während der Merkmalsfusion erheblich erhöht und Multiskaleninformationen in derselben Tiefe fördert. Fusion an.
Obwohl die Wiederverwendung von Funktionen und das einzigartige Verbindungsdesign von GFPN zu einer Verbesserung der Modellgenauigkeit führen. Da unsere Skip-Schicht und unsere Queen-Fusion Fusionsoperationen auf Multi-Scale-Feature-Knoten sowie Upsampling- und Downsampling-Operationen ermöglichen, erhöhen sie die zeitaufwändige Inferenz erheblich und erschweren die Erfüllung der Implementierungsanforderungen der Branche. Tatsächlich ist GFPN eine FLOPS-effiziente, aber verzögerungsineffiziente Struktur. Für einige Defekte von GFPN haben wir die Gründe wie folgt analysiert und zugeordnet:
① Zunächst einmal sind es tatsächlich unterschiedliche Skalenmerkmale Anzahl der gemeinsam genutzten Kanäle Ja, es gibt viele Funktionsredundanzen und die Netzwerkkonfiguration ist nicht flexibel genug.
② Zweitens gibt es Upsampling- und Downsampling-Verbindungen in der Queen-Funktion, und die Upsampling- und Downsampling-Operatoren sind erheblich zeitaufwändiger .
③ Drittens: Wenn Knoten gestapelt sind, verringern serielle Verbindungen mit derselben Funktionstiefe die parallele Effizienz der GPU und erhöhen sie in seriellen Pfaden mit jedem Stapel ist von Bedeutung.
Als Reaktion auf diese Probleme haben wir entsprechende Optimierungen vorgenommen und Efficient RepGFPN vorgeschlagen.
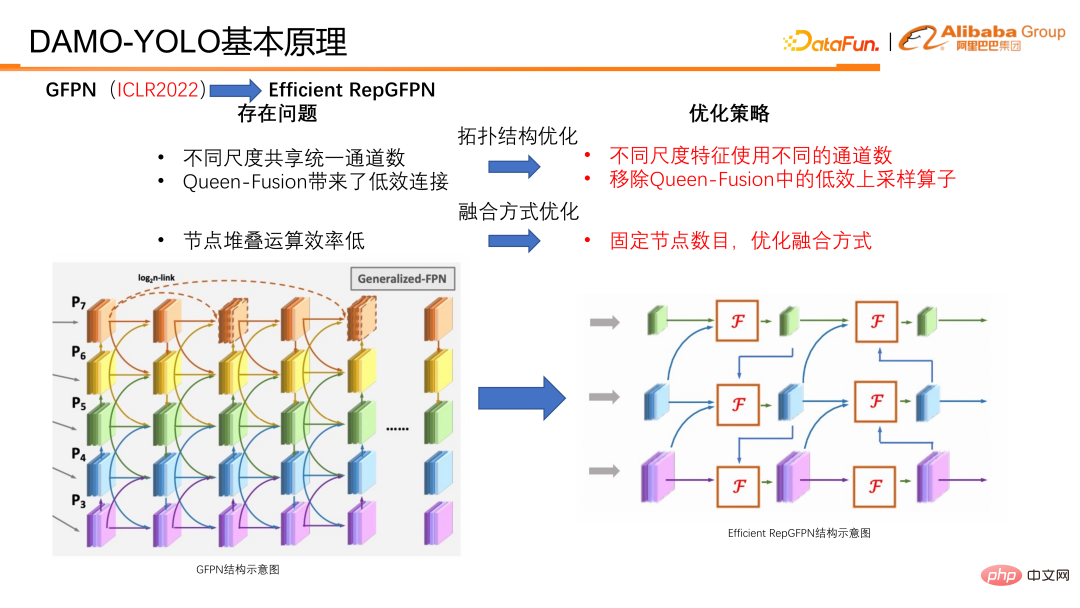
Bei der Optimierung die wichtigsten Punkte Es gibt zwei Kategorien: Die eine ist die Optimierung der Topologiestruktur und die andere die Optimierung der Fusionsmethode.
Im Hinblick auf die Topologieoptimierung verwendet Efficient RepGFPN unterschiedliche Kanalnummern unter verschiedenen Skalierungsmerkmalen, sodass es Schichten auf hoher Ebene unter den Einschränkungen leichter Berechnungen flexibel steuern kann. Ausdrucksmöglichkeiten von Features und Low-Level-Features. Bei FLOPS und Verzögerungsnäherung kann durch flexible Konfiguration die beste Genauigkeit und Geschwindigkeitseffizienz erzielt werden. Darüber hinaus haben wir auch eine Effizienzanalyse für eine Verbindung in der Queen-Fusion durchgeführt und festgestellt, dass der Upsampling-Operator eine enorme Belastung darstellt, die Genauigkeitsverbesserung jedoch gering ist, was weitaus geringer ist als der Nutzen des Downsampling-Operators. Deshalb haben wir die Upsampling-Verbindung in der Queen-Fusion entfernt. Wie in der Tabelle zu sehen ist, handelt es sich bei den Häkchen diagonal nach unten tatsächlich um ein Upsampling und bei den Häkchen diagonal nach oben um ein Downsampling. Sie können es mit dem Bild links vergleichen, um zu sehen, dass kleine Auflösungen nach und nach zu größeren Auflösungen nach unten werden, und die Verbindungen zu unten rechts darstellen Der Zweck besteht darin, Features mit kleiner Auflösung hochzurechnen, sie mit Features mit großer Auflösung zu verbinden und sie zu Features mit großer Auflösung zu verschmelzen. Die endgültige Schlussfolgerung ist, dass der Downsampling-Operator höhere Renditen und der Upsampling-Operator sehr niedrige Renditen erzielt. Daher haben wir die Upsampling-Verbindung in der Queen-Funktion entfernt, um die Effizienz des gesamten GFPN zu verbessern.
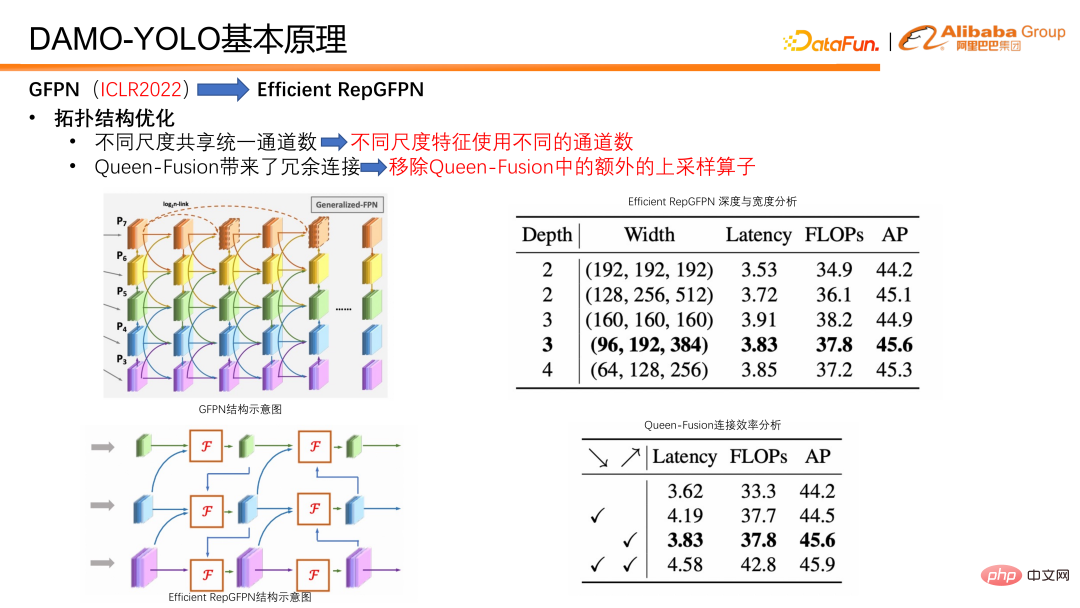
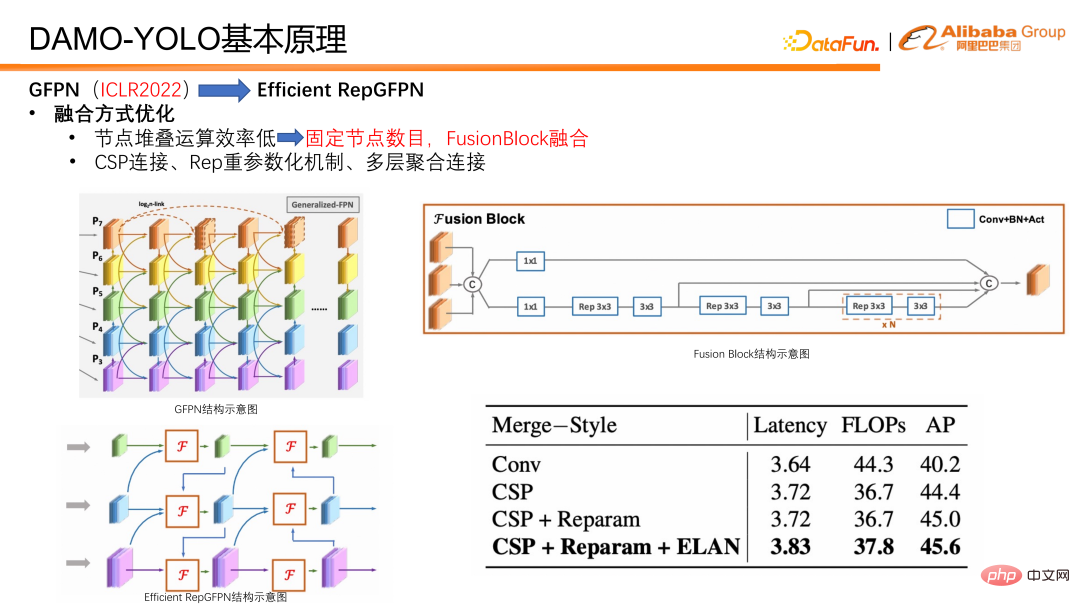
Wir haben auch einige Optimierungen hinsichtlich der Integrationsmethoden vorgenommen. Legen Sie zunächst die Anzahl der Fusionsknoten fest, sodass in jedem Modell nur zwei Fusionen durchgeführt werden, anstatt wie zuvor kontinuierlich Fusionen zu stapeln, um ein tieferes GFPN zu erstellen. Dadurch wird vermieden, dass die parallele Effizienz verringert wird. Darüber hinaus haben wir speziell einen Fusionsblock für die Feature-Fusion entwickelt. Im Fusionsblock führen wir Technologien wie einen starken Parametrisierungsmechanismus und eine mehrschichtige Aggregationsverbindung ein, um den Fusionseffekt weiter zu verbessern.
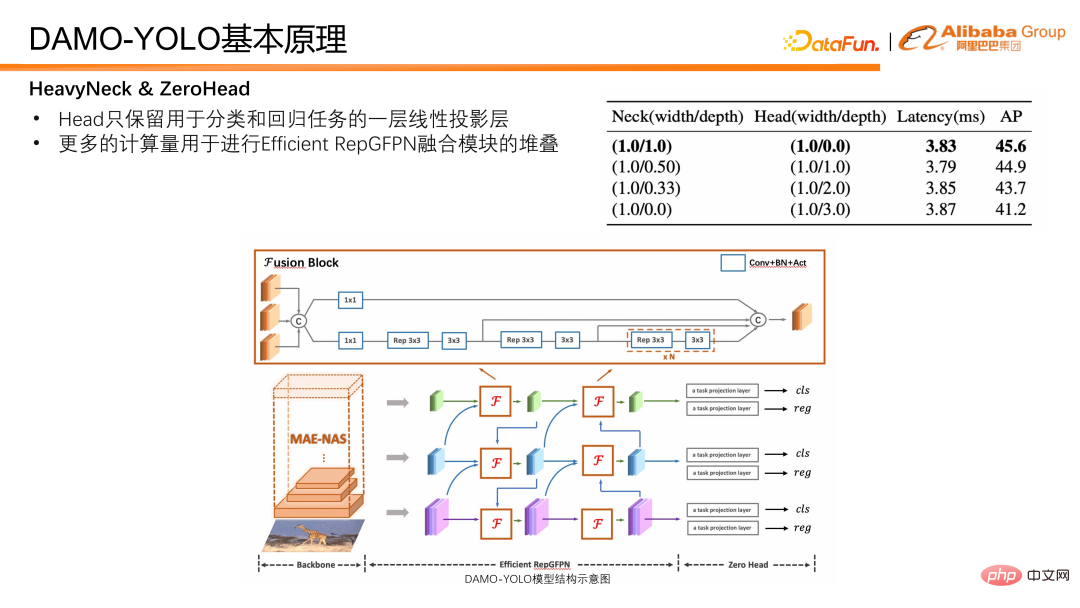
Neben dem Hals ist der Erkennungskopf auch ein wichtiger Teil des Erkennungsmodells. Es verwendet die von Neck ausgegebenen Merkmale als Eingabe und ist für die Ausgabe von Regressions- und Klassifizierungsergebnissen verantwortlich. Wir haben Experimente entworfen, um den Kompromiss zwischen Efficient RepGFPN und Head zu überprüfen, und haben herausgefunden, dass bei strenger Kontrolle der Modelllatenz gilt: Je tiefer das Efficient RepGFPN, desto besser. Daher wird im Netzwerkdesign der Berechnungsbetrag hauptsächlich dem effizienten RepGFPN zugewiesen, während im Kopfteil nur eine Ebene der linearen Projektion für Klassifizierungs- und Regressionsaufgaben reserviert ist. Wir nennen den Kopf, der nur eine Klassifizierungsschicht und eine Regressionsschicht hat, die nichtlineare Zuordnungsschicht ZeroHead. Ein Entwurfsmuster, das diese Rechenlast hauptsächlich dem Hals zuweist, wird als HeavyNeck-Paradigma bezeichnet. Die endgültige Modellstruktur von DAMO-YOLO ist in der folgenden Abbildung dargestellt.
Das Obige sind einige Gedanken zum Modelldesign. Lassen Sie uns abschließend das Destillationsschema vorstellen.
DAMO-YOLO nutzt die Ausgabefunktionen von Efficient RepGFPN für die Destillation. Die Schülerfunktion durchläuft zunächst das Alignmodule, um ihre Kanalnummer an die des Lehrers anzupassen. Um die Verzerrung des Modells selbst zu beseitigen, werden die Merkmale des Schülers und des Lehrers durch unverzerrte BN normalisiert und anschließend der Destillationsverlust berechnet. Während der Destillation haben wir beobachtet, dass ein übermäßiger Verlust die Konvergenz des eigenen Klassifizierungszweigs des Schülers behindert. Deshalb haben wir uns für die Verwendung eines dynamischen Gewichts entschieden, das mit dem Training abnimmt. Aus den experimentellen Ergebnissen geht hervor, dass das dynamische einheitliche Destillationsgewicht robust gegenüber T/S/M-Modellen ist.
Die Destillationskette von DAMO-YOLO ist L-Destillation M, M-Destillation S. Es ist erwähnenswert, dass M beim Destillieren von S eine CSP-Verpackung verwendet, während S eine Res-Verpackung verwendet. Strukturell gesehen sind M und S Isomere. Bei Verwendung des DAMO-YOLO-Destillationsschemas, bei dem M S destilliert, kann es jedoch auch zu einer Verbesserung von 1,2 Punkten nach der Destillation kommen, was darauf hindeutet, dass unser Destillationsschema auch robust gegenüber Isomerie ist. Zusammenfassend lässt sich sagen, dass das Destillationsschema von DAMO-YOLO freie Parameter hat, eine ganze Reihe von Modellen unterstützt und heterogen und robust ist.
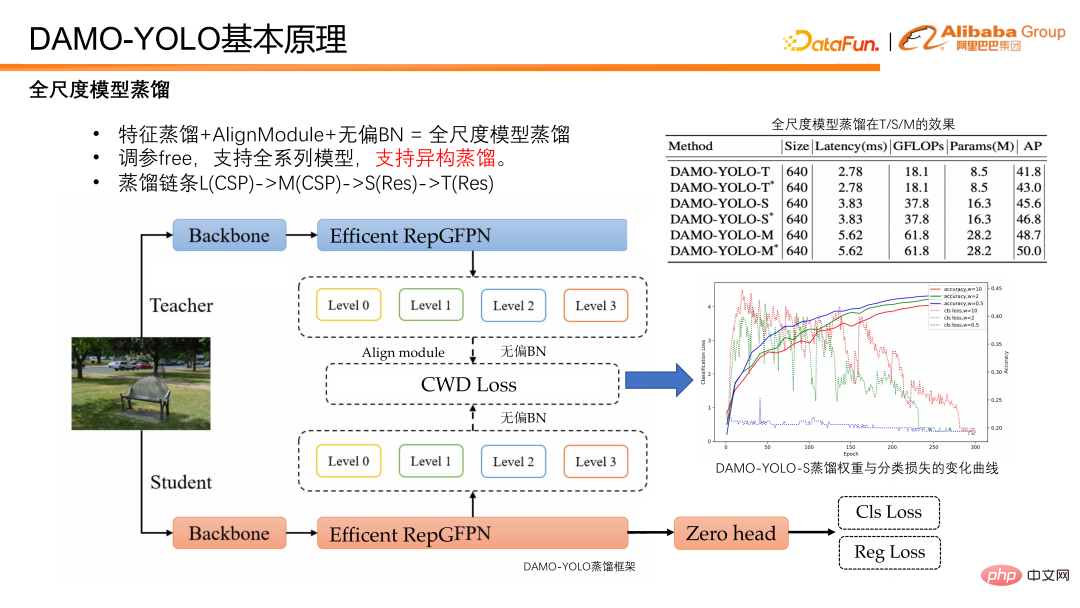
Lassen Sie uns abschließend DAMO-YOLO zusammenfassen. DAMO-YOLO kombiniert die MAE-NAS-Technologie, um eine kostengünstige Modellanpassung zu ermöglichen und die Chip-Rechenleistung in Kombination mit den Efficient RepGFPN- und HeavyNeck-Paradigmen vollständig zu nutzen. Destillationsschema im Maßstab kann die Modelleffizienz weiter verbessern.

5. DAMO-YOLO-Entwicklungsplan
DAMO-YOLO wurde gerade veröffentlicht und es gibt noch viele Bereiche, die verbessert und optimiert werden müssen. Wir planen, die Bereitstellungstools zu verbessern und ModelScope kurzfristig zu unterstützen. Darüber hinaus werden weitere Anwendungsbeispiele basierend auf den Wettbewerbssiegerlösungen innerhalb der Gruppe bereitgestellt, wie z. B. UAV-Erkennung kleiner Ziele und Erkennung rotierender Ziele. Außerdem ist geplant, weitere Beispielmodelle auf den Markt zu bringen, darunter das Nano-Modell für das Gerät und das Large-Modell für die Cloud. Abschließend hoffe ich, dass alle aufmerksam sind und positives Feedback geben.

Das obige ist der detaillierte Inhalt vonDAMO-YOLO: ein effizientes Zielerkennungs-Framework, das sowohl Geschwindigkeit als auch Genauigkeit berücksichtigt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr