
Heim >Technologie-Peripheriegeräte >KI >Anwendungspraxis des Privacy Computing im Bereich Big Data AI
Anwendungspraxis des Privacy Computing im Bereich Big Data AI

- 王林nach vorne
- 2023-04-28 15:13:061618Durchsuche
01 Der Hintergrund und die aktuelle Situation des Privacy Computing
1. Der Hintergrund des Privacy Computing#🎜 🎜## 🎜🎜#
Privacy Computing ist mittlerweile zu einer Notwendigkeit geworden. Einerseits sind die Ansprüche der einzelnen Nutzer an Privatsphäre und Informationssicherheit gestiegen. Andererseits gibt es eine Vielzahl erlassener Datenschutz- und sicherheitsbezogener Gesetze und Vorschriften, wie beispielsweise die DSGVO der Europäischen Union, das CCPA der Vereinigten Staaten und inländische Gesetze und Richtlinien zum Schutz personenbezogener Daten, die sich nach und nach von lockeren zu strengen geändert haben , spiegelt sich hauptsächlich in Rechten und Interessen, Umsetzungsumfang und Ausführungsstärke usw. wider. Nehmen wir als Beispiel die DSGVO: Seit ihrem Inkrafttreten im Jahr 2018 sind mehr als 1.000 Fälle mit einer Gesamtstrafe von mehr als 11 Milliarden aufgetreten, wobei die höchste Einzelstrafe mehr als 5 Milliarden beträgt (Amazon).

 # 🎜🎜#2. Die aktuelle Situation des Privacy Computing
# 🎜🎜#2. Die aktuelle Situation des Privacy Computing
In diesem Zusammenhang hat sich die Datensicherheit von optional zu geändert optional ist ein Muss geworden. Dies hat dazu geführt, dass eine große Anzahl von Unternehmen, Investitionen, Start-ups und Praktikern in das Ökosystem der Sicherheits- und Datenschutztechnologie investiert, und der akademische Kreis hat viele zukunftsweisende Untersuchungen als Reaktion auf die Bedürfnisse der Branche durchgeführt. Diese Faktoren haben in den letzten Jahren zur starken Entwicklung von Sicherheits- und Datenschutztechnologien und -ökosystemen beigetragen, wobei Technologien wie differenzielle Privatsphäre, vertrauenswürdige Ausführungsumgebungen, homomorphe Verschlüsselung, sichere Mehrparteienberechnung und föderiertes Lernen große Fortschritte gemacht haben. Auch Gartner ist hinsichtlich der Entwicklung dieses Bereichs optimistisch und geht davon aus, dass es sich in Zukunft um einen Markt im zweistelligen oder sogar hunderten Milliardenbereich handeln wird.
 0 2 #? 🎜 #
0 2 #? 🎜 #
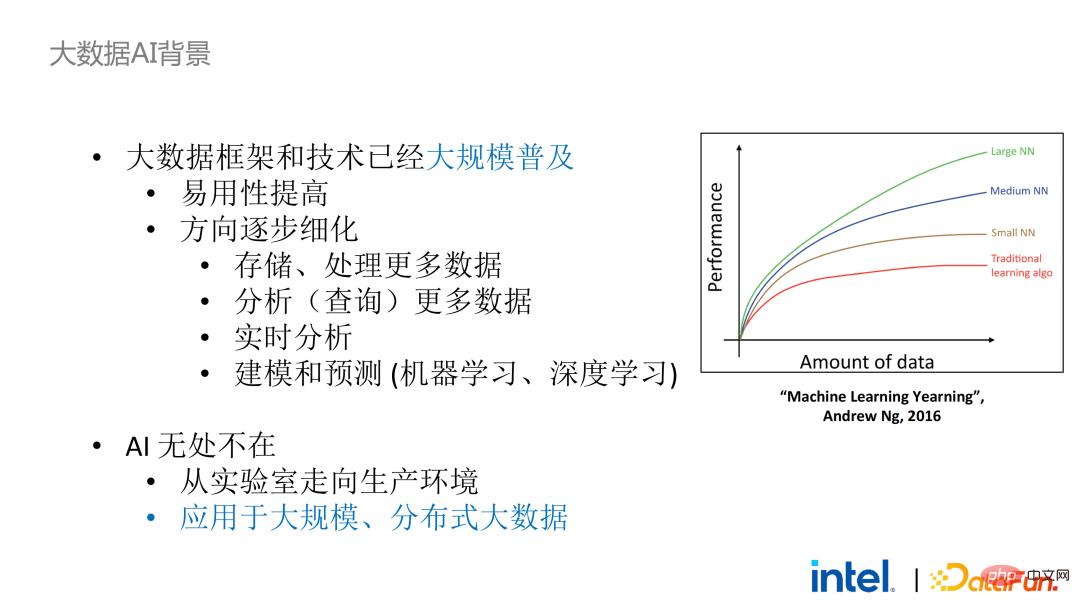
Aus der Perspektive der Kombination mit dem KI-Framework sind Big Data und KI-Ökologie nun eng integriert. Denn bei KI-Modellen ist der Trainingseffekt des Modells umso besser, je größer die Datenmenge und je höher die Qualität, sodass die beiden Bereiche Big Data und KI natürlich kombiniert werden.
# 🎜🎜#Dennoch ist die Integration von Big-Data-Frameworks und KI-Frameworks nicht einfach. Im Prozess der Anwendungsentwicklung, Datenerfassung, Bereinigung, Analyse und Bereitstellung werden viele Big-Data- und KI-Frameworks beteiligt sein. Wenn Sie Datensicherheit und Datenschutz in Schlüsselprozessen gewährleisten müssen, sind viele Verknüpfungen und Frameworks erforderlich, darunter verschiedene Sicherheitstechnologien, Verschlüsselungstechnologien und Schlüsselverwaltungstechnologien, was die Kosten für Transformation und Migration erheblich erhöhen wird.
2. Big Data AI + Privacy Computing
Vor zwei Jahren haben wir während der Kommunikation mit Kunden im Zusammenhang mit Big Data und KI-Anwendungen in der Branche einige Benutzerprobleme festgestellt. Neben allgemeinen Leistungsproblemen sind Kompatibilitätsprobleme die erste Sorge der meisten Kunden. Einige Kunden verfügen beispielsweise bereits über Cluster mit Tausenden oder sogar Zehntausenden von Knoten. Wenn sie einige Module oder Links sicher verarbeiten und Datenschutz-Computing-Technologie anwenden müssen, um Datenschutzfunktionen zu erreichen, müssen sie möglicherweise Änderungen an den vorhandenen Anwendungen vornehmen. oder sogar völlig neue Frameworks oder Infrastrukturen einführen. Diese Auswirkungen sind die Hauptprobleme, die Kunden berücksichtigen müssen. Zweitens werden Kunden die Auswirkungen des Datenumfangs auf die Sicherheitstechnologie berücksichtigen und hoffen, dass die neu eingeführten Frameworks und Technologien die Berechnung großer Datenmengen unterstützen und eine hohe Recheneffizienz aufweisen können. Abschließend werden Kunden überlegen, ob die Technologie des föderierten Lernens das Problem der Dateninseln lösen kann.

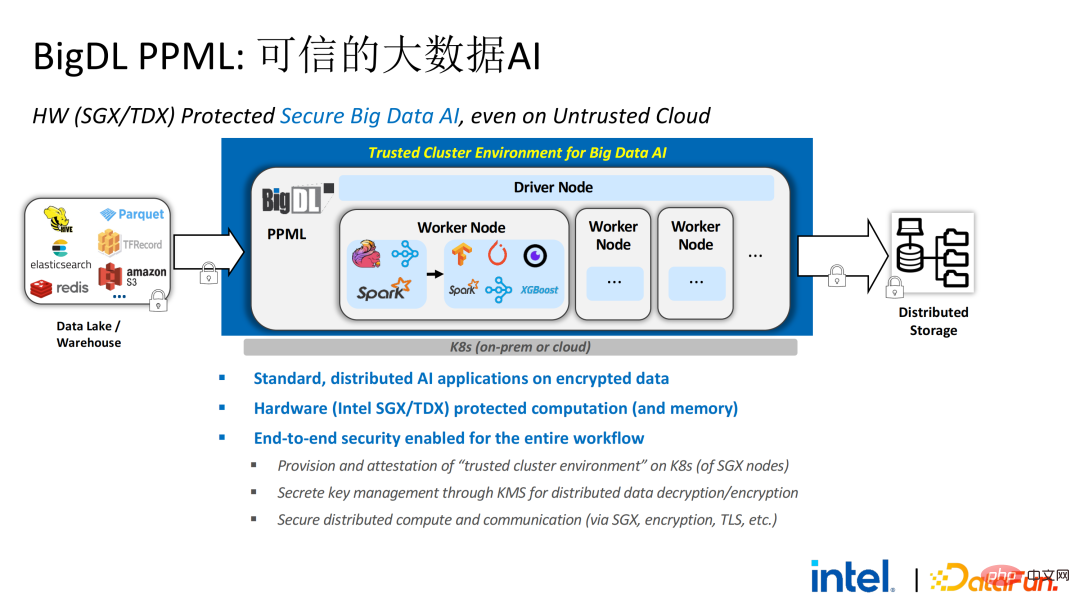
Basierend auf den aus der Umfrage ermittelten Kundenbedürfnissen haben wir die BigDL PPML-Lösung auf den Markt gebracht , Ihr Hauptziel besteht darin, die Ausführung herkömmlicher und standardmäßiger Big-Data- und KI-Lösungen in einer sicheren Umgebung zu ermöglichen Stellen Sie sicher, dass es von Anfang bis Ende sicher ist . Zu diesem Zweck muss der Rechenprozess durch SGX (TEE auf Hardwareebene) geschützt werden. Gleichzeitig muss sichergestellt werden, dass der Speicher und das Netzwerk verschlüsselt sind und die gesamte Verbindung aus der Ferne bestätigt werden muss (auch als Fernsignatur bezeichnet), um die Vertraulichkeit und Integrität der Berechnung sicherzustellen.
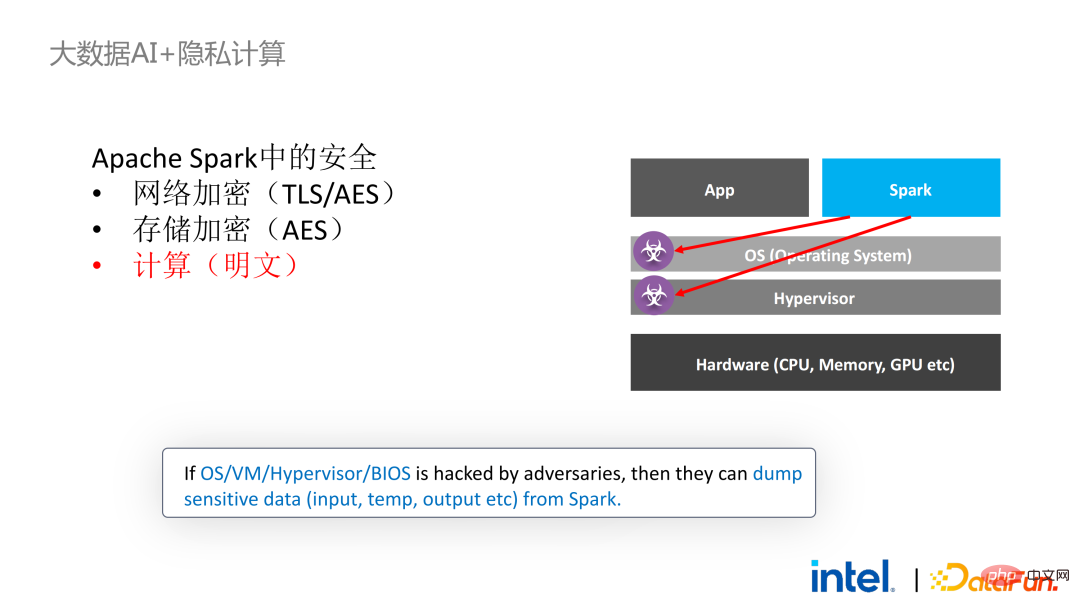
Als nächstes nehmen wir Apache Spark, ein häufig verwendetes Big-Data-Framework, als Beispiel, um die Notwendigkeit dieser Lösung näher zu erläutern . Apache Spark ist ein häufig verwendetes verteiltes Computing-Framework im Bereich der Big-Data-KI. Es verfügt beispielsweise über viele sicherheitsrelevante Funktionen. Beispielsweise können Kommunikation und RPC hauptsächlich durch TLS und AES geschützt werden Der lokale Shuffle-Speicher ist ebenfalls durch AES geschützt. Es gibt jedoch große Probleme bei der Berechnung, da selbst die neueste Version von Spark nur Klartextberechnungen durchführen kann. Wenn die Computerumgebung oder der Knoten kompromittiert wird, kann eine große Menge sensibler Daten abgerufen werden.
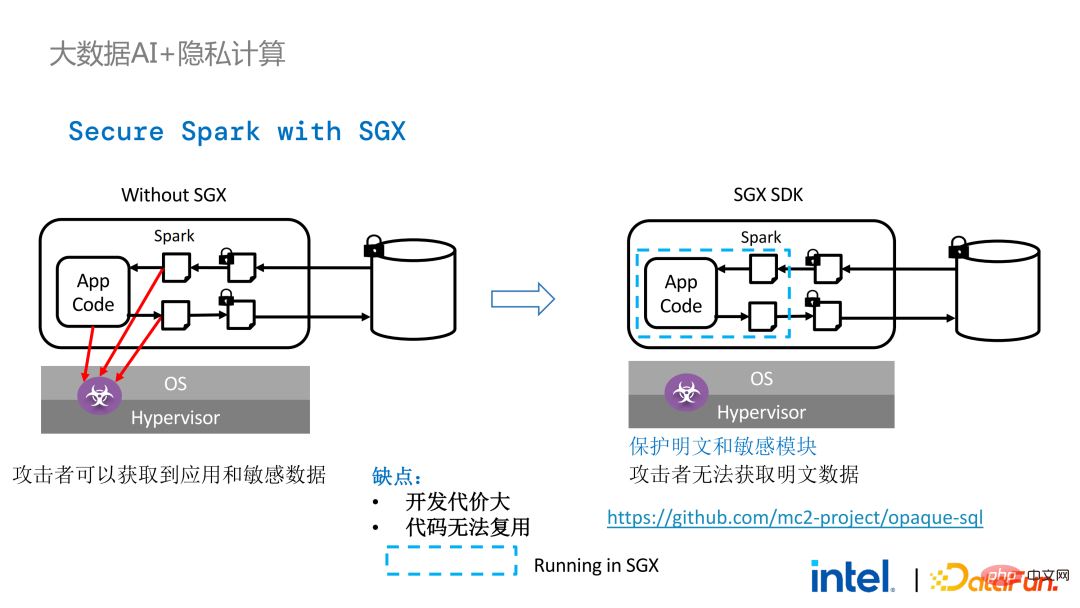
SGX-Technologie ist eine vertrauenswürdige Computerumgebungstechnologie, die Software und Hardware mit Intel-CPU als zugrunde liegender Funktion kombiniert Niveau Vertrauenswürdige Ausführungsumgebung
- Relativ kleine Angriffsfläche: Auch wenn ein Teil des Systems kompromittiert wurde, kann die Sicherheit des gesamten Programms gewährleistet werden, solange die CPU sicher ist.
- Die Auswirkungen auf die Leistung ist klein linke Seite ist der Fall Wenn die Computerumgebung nicht geschützt ist, besteht die Gefahr eines Datenlecks, selbst wenn verschlüsselter Speicher verwendet wird, solange sie während der Klartextberechnungsphase angegriffen wird. Dies sind einige Versuche der Spark-Community, einige Schlüssel zu extrahieren Schritte im Zusammenhang mit SparkSQL durchführen und diese mit dem SGX SDK neu schreiben. Ein Teil der Logik kann nicht nur die Leistung maximieren, sondern auch die Angriffsfläche minimieren. Allerdings liegen auch die Nachteile dieser Methode auf der Hand, nämlich dass die Entwicklungskosten zu hoch und die Kosten zu hoch sind. Die Wiederherstellung der Kernlogik von SparkSQL erfordert ein klares Verständnis von Spark. Gleichzeitig kann der Code nicht in anderen Projekten wiederverwendet werden.
Um die oben genannten Mängel zu beheben, Wir haben die LibOS-Lösung verwendet Kurz gesagt, durch die mittlere Schicht von LibOS reduzieren wir die Schwierigkeiten bei der Entwicklung und Migration und integrieren Die System-API-Aufrufe werden in eine Form umgewandelt, die vom SGX SDK erkannt werden kann, wodurch eine nahtlose Migration einiger gängiger Anwendungen erreicht wird. Zu den gängigen LibOS-Lösungen gehören Occlum von Ant Group, Gramine von Intel und die sgx-lkl-Lösung von Imperial College. Die oben genannten LibOS haben alle ihre eigenen Funktionen und Vorteile und lösen die Probleme der Benutzerfreundlichkeit und Portabilität von SGX auf unterschiedliche Weise.
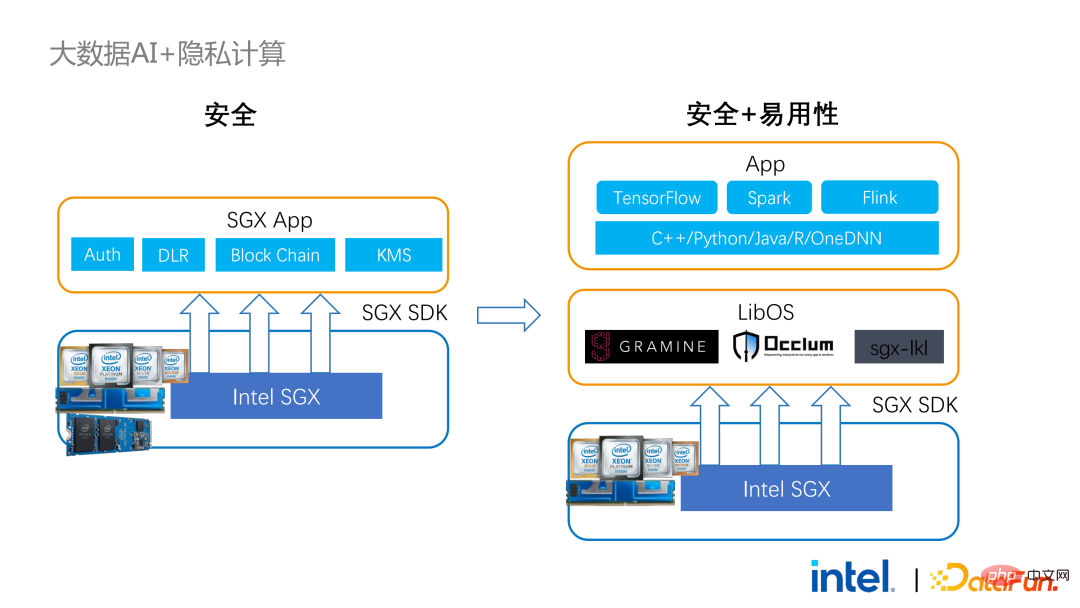
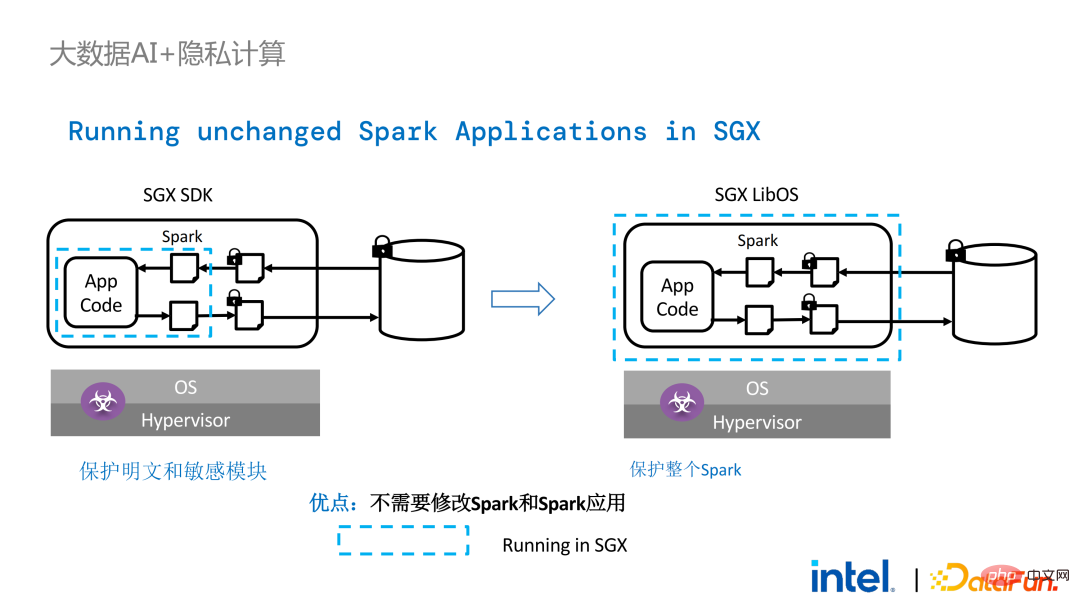
Mit LibOS müssen Sie die Kernlogik in Spark nicht mehr neu schreiben, sondern können den gesamten Spark über LibOS in SGX integrieren, ohne Spark und vorhandene Anwendungen zu ändern.
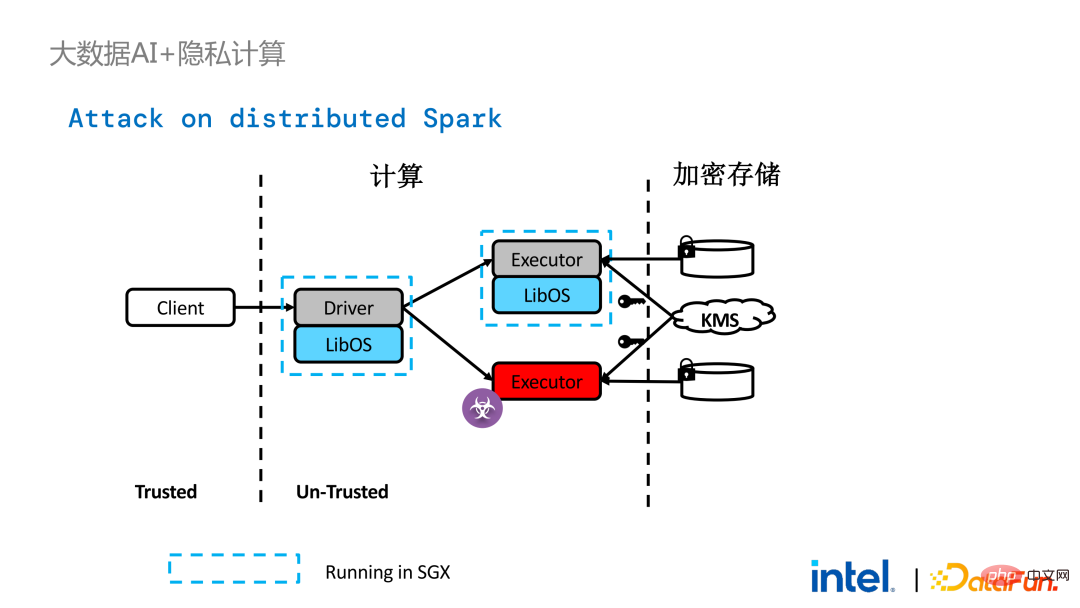
Im verteilten Computing von Spark kann jedes verteilte Modul mit LibOS bzw. SGX geschützt werden. Die Speicherseite kann mit Schlüsselverwaltung und verschlüsseltem Speicher konfiguriert werden, und der Ausführende kann es erhalten . Die Chiffretextdaten werden dann in SGX entschlüsselt und berechnet. Der gesamte Prozess ist für Entwickler relativ unempfindlich und hat weniger Auswirkungen auf bestehende Anwendungen.
Allerdings sind Sicherheitsprobleme in verteilten Anwendungen im Vergleich zu eigenständigen Anwendungen auch komplexer. Angreifer können einige Betriebsknoten kompromittieren oder mit Ressourcenverwaltungsknoten zusammenarbeiten, um die SGX-Umgebung durch eine bösartige Betriebsumgebung zu ersetzen. Auf diese Weise können Schlüssel und verschlüsselte Daten illegal erlangt werden und letztendlich können private Daten durchsickern.
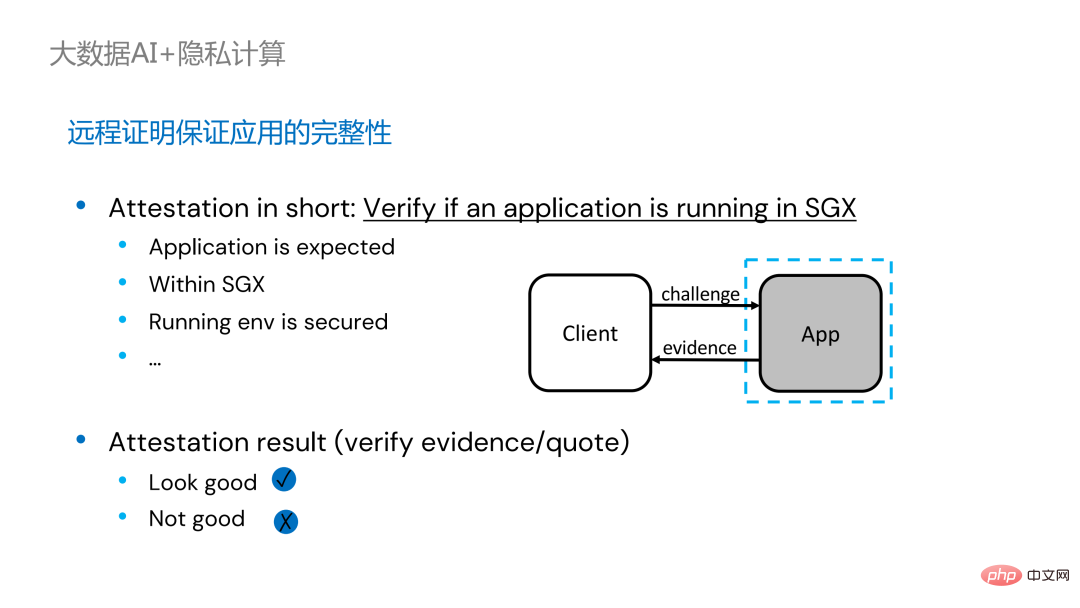
Um dieses Problem zu lösen, muss Fernzertifizierungstechnologie angewendet werden. Einfach ausgedrückt können in SGX ausgeführte Anwendungen Zertifikate oder Zertifikate bereitstellen, und die Zertifikate oder Zertifikate können nicht manipuliert werden. Das Zertifikat kann überprüfen, ob die Anwendung in SGX ausgeführt wird, ob die Anwendung manipuliert wurde und ob die Plattform Sicherheitsstandards erfüllt.
Es gibt zwei Möglichkeiten, den Remote-Proof für verteilte Anwendungen zu implementieren. Auf der linken Seite sehen Sie eine relativ vollständige, aber erheblich modifizierte Lösung. Die Treiber- und Ausführendenseite führen gegenseitig eine Fernzertifizierung durch, was einen gewissen Grad an Modifikation an Spark erfordert. Eine andere Lösung besteht darin, eine zentralisierte Fernzertifizierung über einen Fernzertifizierungsserver eines Drittanbieters zu implementieren und ein unveränderliches Zertifikat zu verwenden, um von Angreifern gesteuerte Module daran zu hindern, Daten abzurufen. Die zweite Option erfordert keine Änderung der Anwendung, sondern nur die Änderung eines kleinen Teils des Startskripts.
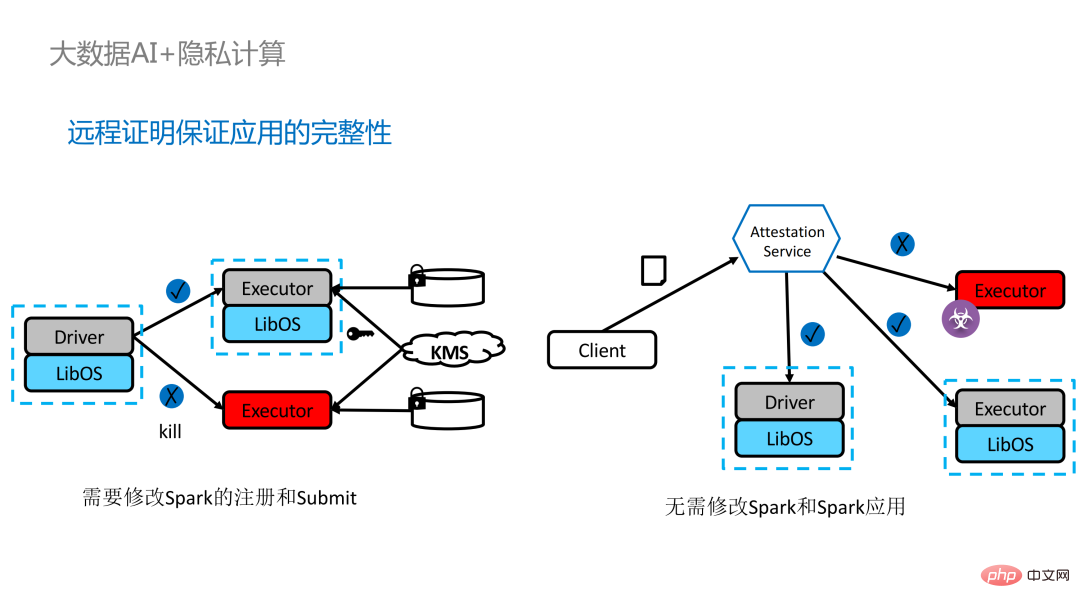
Obwohl LibOS die Ausführung von Spark in SGX ermöglicht, ist dennoch eine gewisse Menge an Personal und Zeit erforderlich, um Spark an LibOS und SGX anzupassen. Zu diesem Zweck haben wir die One-Stop-Lösung von PPML eingeführt, von der viele automatisiert und nahtlos migriert werden können, wodurch die Migrationskosten erheblich gesenkt werden.
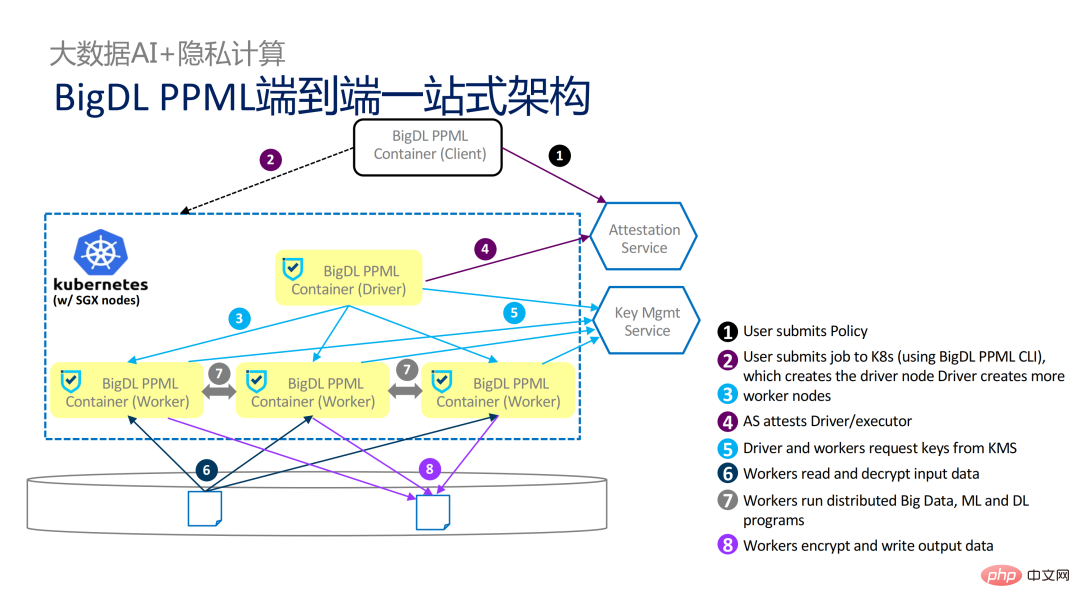
Aus Workflow-Sicht hat diese Lösung einen weiteren Vorteil: Datenwissenschaftler können zugrunde liegende Änderungen nicht wahrnehmen. Nur Clusteradministratoren müssen an der Bereitstellung und Vorbereitung von SGX teilnehmen, und Datenwissenschaftler können normal mit der Modellierungs- und Abfragearbeit fortfahren sind sich überhaupt nicht darüber im Klaren, dass sich die zugrunde liegende Umgebung verändert hat. Dies kann die Kompatibilitäts- und Migrationsprobleme bestehender Anwendungen gut lösen und wird die tägliche Arbeit von Datenwissenschaftlern und Entwicklern nicht behindern.
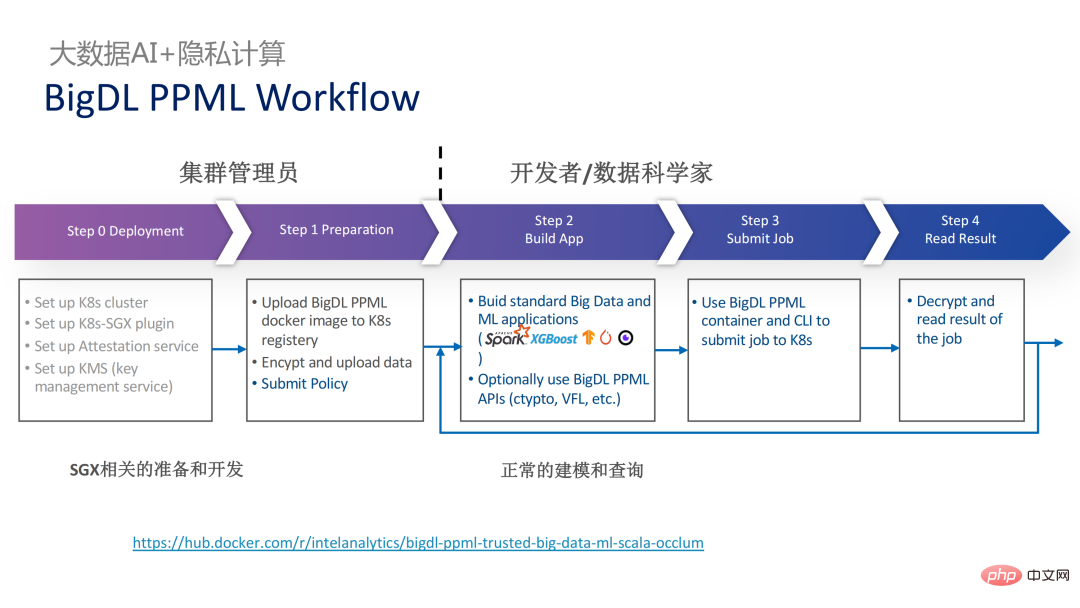
Das Folgende ist ein vollständiges Bild der gesamten PPML-Lösung. Um den unterschiedlichen Bedürfnissen der Kunden gerecht zu werden, wurden die von PPML unterstützten Funktionen in den letzten zwei Jahren kontinuierlich erweitert. Beispielsweise werden in der Mittelschicht-Bibliothek und im Framework häufig verwendete Computer-Frameworks wie Spark, Flink und Ray gleichzeitig unterstützt. PPML unterstützt auch Funktionen für maschinelles Lernen, tiefes Lernen und föderiertes Lernen und ist mit ausgestattet Unterstützung für verschlüsselte Speicherung und homomorphe Verschlüsselung, um eine durchgängige vollständige Verbindungssicherheit zu gewährleisten.
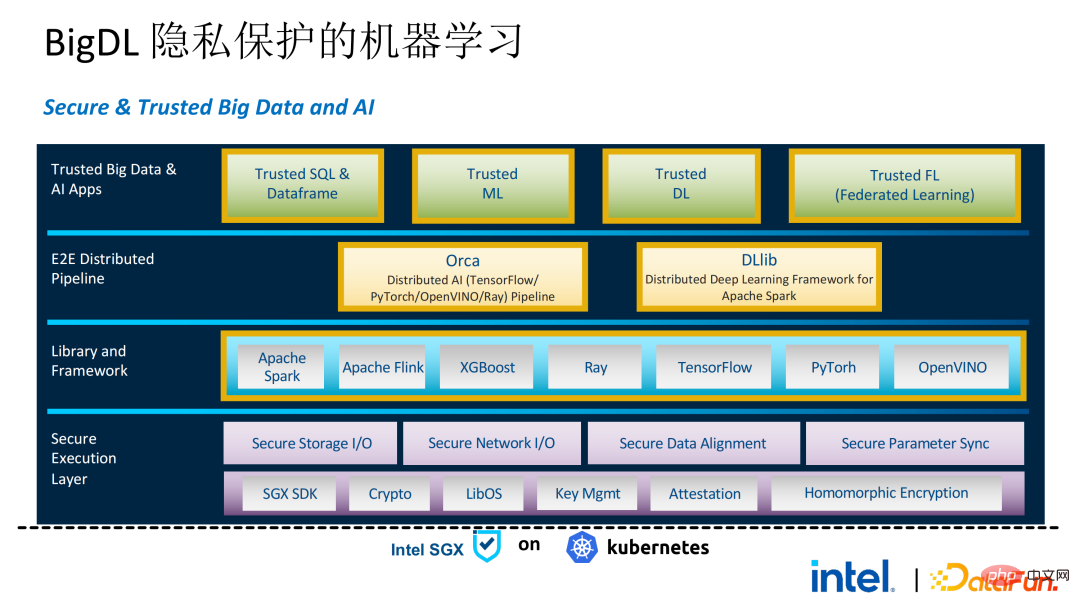
03 Anwendungspraxis
Im Folgenden finden Sie einige Praxisbeispiele für Kundenanwendungen, von denen der berühmtere der letztjährige Tianchi-Wettbewerb ist. In einem Unterwettbewerb im letzten Jahr hofften die Teilnehmer, dass der Trainings- und Modellinferenzprozess vollständig durch SGX geschützt werden könnte. Durch die von PPML bereitgestellte Flink-Funktion und in Kombination mit dem LibOS-Projekt Occlum der Ant Group könnte der Trainings- und Modellinferenzprozess unsichtbar gemacht werden auf Anwendungsebene. Am Ende nahmen mehr als 4.000 Teams am gesamten Wettbewerb teil und Hunderte von Servern wurden verwendet, was beweist, dass PPML eine groß angelegte kommerzielle Nutzung unterstützen kann, und insgesamt nahmen die Betreiber keine großen Veränderungen wahr.

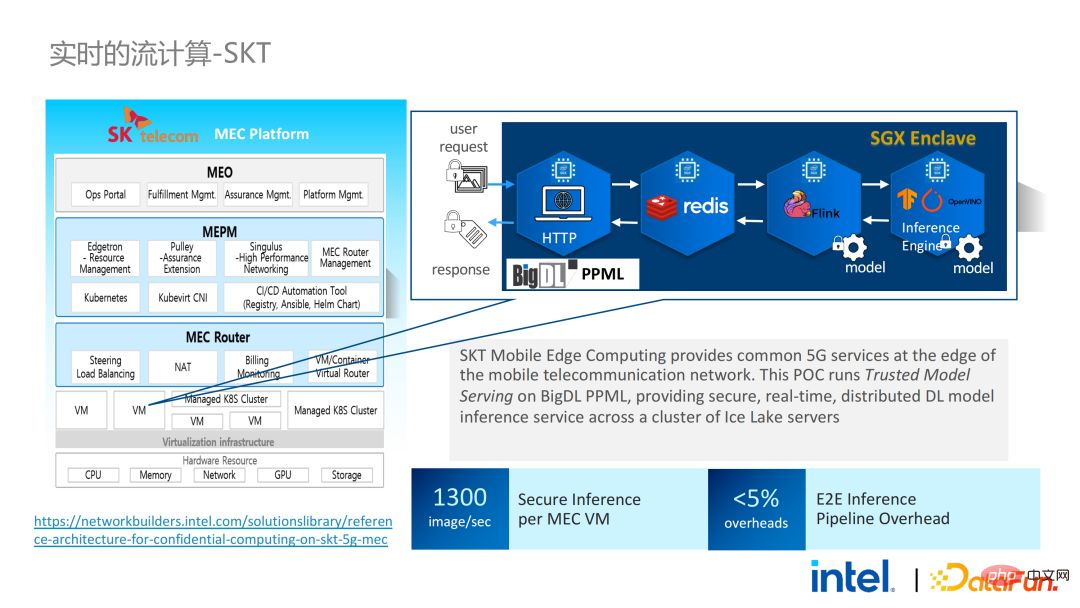
Im September und Oktober desselben Jahres hoffte Korea Telecom, eine durchgängig sichere Echtzeit-Modellinferenzumgebung auf Basis von BigDL und Flink aufzubauen strenger. Nach Tianchis Erfahrung ist die auf Flink und SGX basierende Echtzeit-Modellinferenzlösung ausgereifter. Der End-to-End-Leistungsverlust beträgt weniger als 5 %, und der Durchsatz erfüllt auch die Grundanforderungen von Korea Telecom.
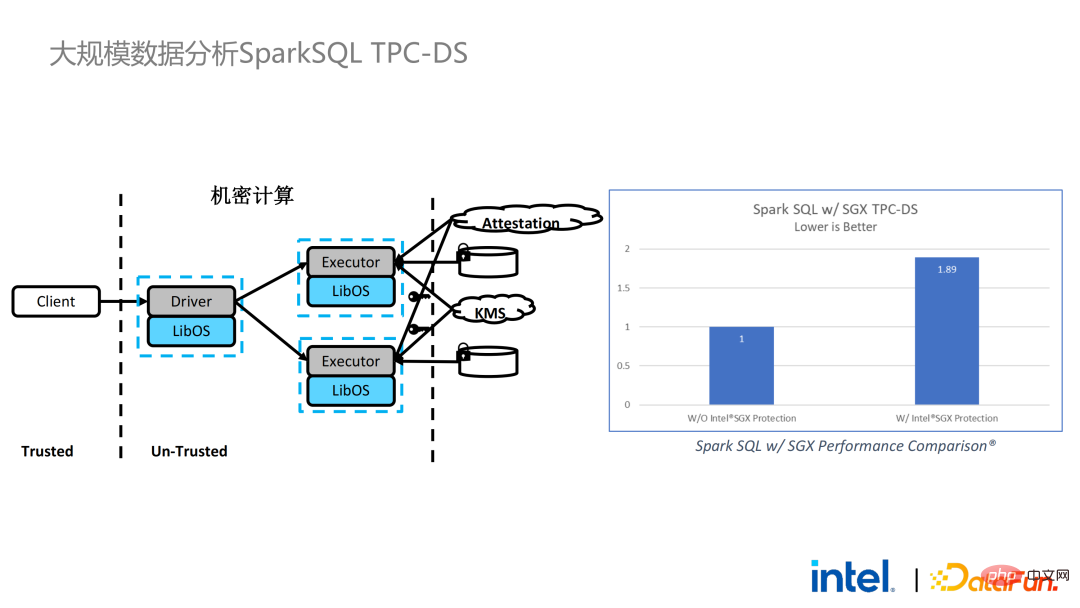
Wir haben auch Spark-Leistungstests durchgeführt. Zusammenfassend lässt sich sagen, dass selbst wenn die Testdaten Hunderte von GB erreichen, es keine Skalierbarkeits- und Leistungsprobleme gibt, wenn die PPML-Lösung Spark ausführt. Basierend auf den Anforderungen des Kunden haben wir uns speziell für TPC-DS entschieden, eine IO-intensive Anwendung, die nicht für SGX geeignet ist. TPC-DS ist ein häufig verwendeter SQL-Benchmark-Standard. Er stellt relativ hohe E/A- und Rechenanforderungen. Bei großen Datenmengen treten umfangreiche Festplatten-, Speicher- und Netzwerk-E/A-Anforderungen auf. Als TEE auf Hardwareebene müssen Daten, die in SGX ein- und ausgehen, entschlüsselt und verschlüsselt werden, sodass die Kosten für das Lesen und Schreiben von Daten höher sind als bei Nicht-SGX. Nach einem vollständigen TPC-DS-Test betrug der gesamte End-to-End-Verlust das Zweifache und entsprach damit den Kundenerwartungen. Durch den TPC-DS-Benchmark haben wir bewiesen, dass wir selbst in diesem schlimmsten Fall sicherstellen können, dass der End-to-End-Verlust auf einen akzeptablen Bereich (1,8) reduziert wird.
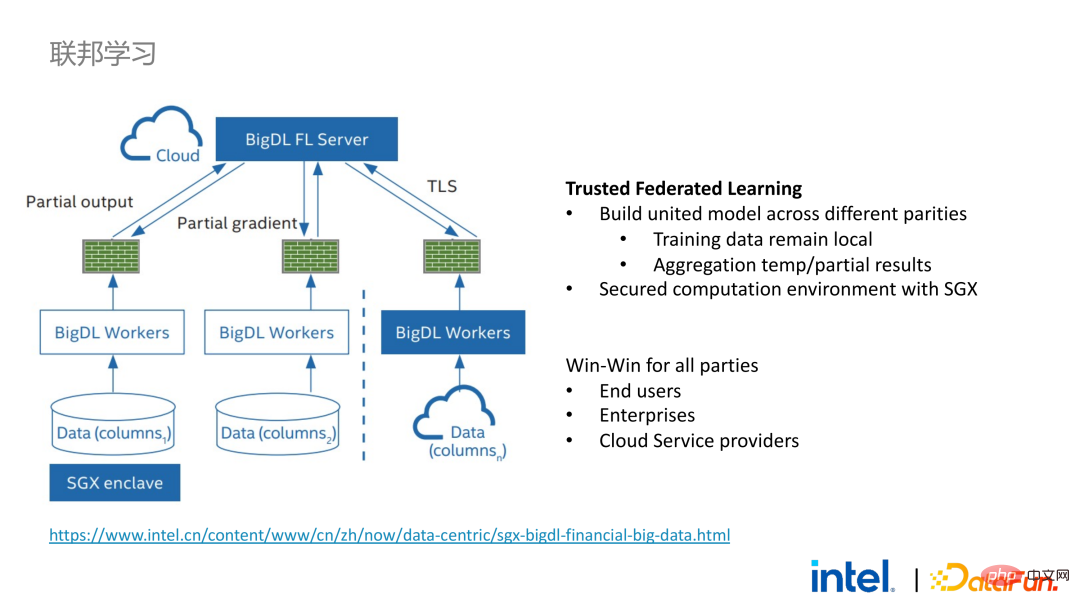
Nachdem wir die nahtlose Migration von Big-Data-Anwendungen erkannt hatten, haben wir mit einigen Kunden auch föderiertes Lernen ausprobiert. Da SGX eine sichere Umgebung bietet, kann es die kritischsten Server- und lokalen Datensicherheitsprobleme im föderierten Lernprozess lösen. Es gibt einen großen Unterschied zwischen der von BigDL bereitgestellten föderierten Lernlösung und der allgemeinen Lösung, das heißt, die gesamte Lösung ist im Wesentlichen eine föderierte Lernlösung für große Datenmengen. Unter diesen sind die Arbeitslast und die Datengröße jedes Arbeiters relativ groß, und jeder Arbeiter entspricht einem kleinen Cluster. Wir haben die Machbarkeit und Wirksamkeit dieser Lösung bei einigen Kunden überprüft.
04 Zusammenfassung und Ausblick
Wie oben erwähnt, haben wir in mehr als zwei Jahren der Kommunikation und Zusammenarbeit mit Kunden mehrere Schwachstellen im Zusammenhang mit Privacy Computing und Big Data AI entdeckt. Diese Schwachstellen können durch Sicherheitstechnologien wie SGX gelöst werden. Unter anderem kann LibOS Kompatibilitätsprobleme lösen, SGX kann Sicherheitsumgebungs- und Leistungsprobleme lösen; Spark- oder Flink-Unterstützung kann Big Data lösen und Migrationsprobleme können das Dateninselproblem lösen; BigDL PPML ist eine One-Stop-Datenschutzlösung, die die oben genannten Dienste integriert.

Die Ökologie von SGX und TEE entwickelt sich derzeit rasant. In absehbarer Zeit wird TEE in Bezug auf Benutzerfreundlichkeit, Sicherheit und Leistung erheblich verbessert. Beispielsweise kann Intels TDX der nächsten Generation direkt Betriebssystemunterstützung bieten, wodurch Probleme mit der Anwendungskompatibilität grundlegend gelöst werden können Unterstützung für vertrauliche Container, um die Containersicherheit zu gewährleisten und die Kosten für die Anwendungsmigration erheblich zu senken. Aus sicherheitstechnischer Sicht scheinen Arbeiten wie Microkernel auch die Sicherheit des TEE-Ökosystems weiter zu stärken. Aus Sicht der Skalierbarkeit fördern Intel und die Community außerdem die Unterstützung von Beschleunigern und E/A-Geräten und bringen sie in die vertrauenswürdige Domäne, um den Leistungsaufwand des Datenflusses zu reduzieren.

Das obige ist der detaillierte Inhalt vonAnwendungspraxis des Privacy Computing im Bereich Big Data AI. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr