
Heim >Technologie-Peripheriegeräte >KI >Eine Verbraucher-GPU führt erfolgreich ein großes Modell mit 176 Milliarden Parametern aus
Eine Verbraucher-GPU führt erfolgreich ein großes Modell mit 176 Milliarden Parametern aus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-28 12:19:061281Durchsuche
Das Ausführen großer Modelle auf Verbraucher-GPUs ist eine ständige Herausforderung für die Community des maschinellen Lernens.
Die Größe der Sprachmodelle ist immer größer geworden, PaLM hat 540B Parameter, OPT, GPT-3 und BLOOM haben etwa 176B Parameter. Das Modell entwickelt sich immer noch in eine größere Richtung.

Diese Modelle sind auf leicht zugänglichen Geräten nur schwer auszuführen. Beispielsweise muss BLOOM-176B auf acht 80-GB-A100-GPUs (ca. 15.000 US-Dollar pro Stück) laufen, um die Inferenzaufgabe abzuschließen, während für die Feinabstimmung von BLOOM-176B 72 solcher GPUs erforderlich sind. Größere Modelle wie PaLM erfordern mehr Ressourcen.
Wir müssen Wege finden, den Ressourcenbedarf dieser Modelle zu reduzieren und gleichzeitig die Modellleistung aufrechtzuerhalten. Auf diesem Gebiet wurden verschiedene Techniken entwickelt, mit denen versucht wird, die Modellgröße zu reduzieren, beispielsweise Quantisierung und Destillation.
BLOOM wurde letztes Jahr von mehr als 1.000 freiwilligen Forschern im Rahmen eines Projekts namens „BigScience“ ins Leben gerufen. Das Projekt wird vom Startup für künstliche Intelligenz Hugging Face mit Mitteln der französischen Regierung betrieben. Das BLOOM-Modell wurde am 12. Juli dieses Jahres offiziell veröffentlicht . .
Durch die Verwendung von Int8-Inferenz wird der Speicherbedarf des Modells erheblich reduziert, ohne die Vorhersageleistung des Modells zu beeinträchtigen. Auf dieser Grundlage führten Forscher der University of Washington, des Meta AI Research Institute (ehemals Facebook AI Research) und anderer Institutionen gemeinsam eine Studie mit HuggingFace durch und versuchten, den trainierten BLOOM-176B auf weniger GPUs laufen zu lassen und die vorgeschlagene Methode vollständig zu integrieren in HuggingFace Transformers.

- Papieradresse: https://arxiv.org/pdf/2208.07339.pdf
- Github-Adresse: https://github.com/timdettmers/bitsandbytes
Diese Forschung ist transformativ Schlug den ersten Int8-Quantisierungsprozess im Milliardenmaßstab vor, der die Inferenzleistung des Modells nicht beeinträchtigt. Es kann einen 175B-Parametertransformator mit 16-Bit- oder 32-Bit-Gewichten laden und Feedforward- und Aufmerksamkeitsprojektionsebenen in 8-Bit konvertieren. Es reduziert den für die Inferenz erforderlichen Speicher um die Hälfte und behält gleichzeitig die volle Präzisionsleistung bei.
Die Studie nannte die Kombination aus Vektorquantisierung und Zerlegung mit gemischter Präzision LLM.int8(). Experimente zeigen, dass es durch die Verwendung von LLM.int8() möglich ist, Rückschlüsse mit einem LLM von bis zu 175B Parametern auf einer Consumer-GPU ohne Leistungseinbußen durchzuführen. Dieser Ansatz wirft nicht nur ein neues Licht auf die Auswirkungen von Ausreißern auf die Modellleistung, sondern ermöglicht auch erstmals die Verwendung sehr großer Modelle wie OPT-175B/BLOOM auf einem einzigen Server mit GPUs der Verbraucherklasse.
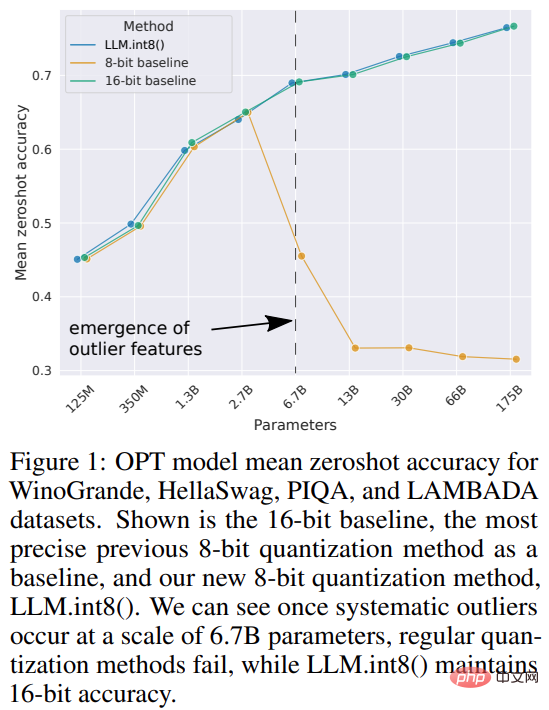
Methodeneinführung
Die Größe des maschinellen Lernmodells hängt von der Anzahl der Parameter und ihrer Präzision ab, normalerweise von float32, float16 oder bfloat16. float32 (FP32) steht für die standardisierte IEEE 32-Bit-Gleitkommadarstellung, und mit diesem Datentyp kann eine Vielzahl von Gleitkommazahlen dargestellt werden. FP32 reserviert 8 Bits für den „Exponenten“, 23 Bits für die „Mantisse“ und 1 Bit für das Vorzeichen der Zahl. Außerdem unterstützt die meiste Hardware FP32-Operationen und -Anweisungen.
Und float16 (FP16) reserviert 5 Bits für den Exponenten und 10 Bits für die Mantisse. Dadurch ist der darstellbare Bereich der FP16-Zahlen viel geringer als der von FP32, wodurch das Risiko eines Überlaufs (Versuch, eine sehr große Zahl darzustellen) und eines Unterlaufs (Versuch einer sehr kleinen Zahl darzustellen) besteht.
Wenn ein Überlauf auftritt, erhalten Sie ein NaN-Ergebnis (keine Zahl), und wenn Sie sequentielle Berechnungen wie in neuronalen Netzen durchführen, wird viel Arbeit zusammenbrechen. bfloat16 (BF16) vermeidet dieses Problem. BF16 reserviert 8 Bits für den Exponenten und 7 Bits für die Dezimalzahl, was bedeutet, dass BF16 den gleichen Dynamikbereich wie FP32 beibehalten kann.
Idealerweise sollten Training und Inferenz in FP32 durchgeführt werden, aber es ist langsamer als FP16/BF16, also verwenden Sie gemischte Präzision, um die Trainingsgeschwindigkeit zu verbessern. Aber in der Praxis liefern Gewichte mit halber Genauigkeit bei der Inferenz auch eine ähnliche Qualität wie FP32. Das bedeutet, dass wir die Hälfte der Präzisionsgewichte und die Hälfte der GPU verwenden können, um die gleichen Ergebnisse zu erzielen.
Aber was wäre, wenn wir verschiedene Datentypen verwenden könnten, um diese Gewichte mit weniger Speicher zu speichern? Eine Methode namens Quantisierung ist beim Deep Learning weit verbreitet.
Diese Studie verwendete im Experiment zunächst 2-Byte-BF16/FP16-Halbpräzision anstelle von 4-Byte-FP32-Präzision und erzielte fast die gleichen Inferenzergebnisse. Dadurch wird das Modell um die Hälfte reduziert. Wenn Sie diese Zahl jedoch weiter reduzieren, nimmt die Genauigkeit ab und die Qualität der Schlussfolgerung nimmt stark ab.
Um dies auszugleichen, führt diese Studie die 8-Bit-Quantisierung ein. Diese Methode nutzt ein Viertel der Präzision und benötigt daher nur ein Viertel der Modellgröße, was jedoch nicht durch Entfernen der anderen Hälfte der Bits erreicht wird.
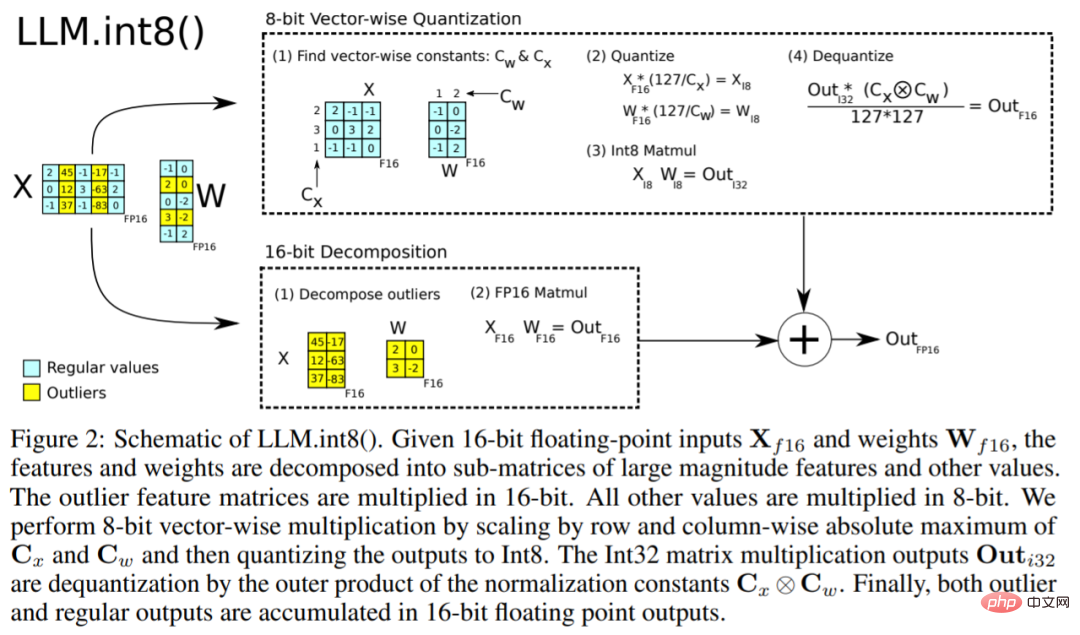
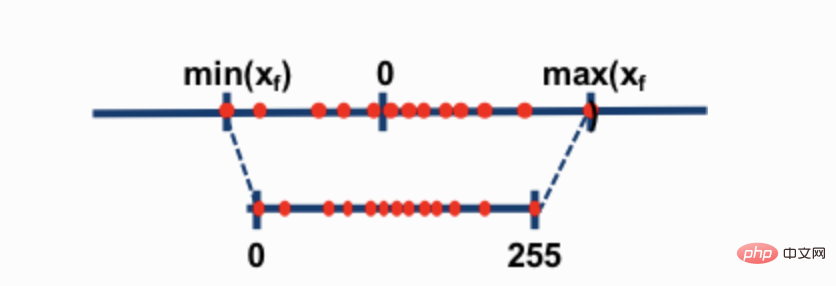
Die beiden gebräuchlichsten 8-Bit-Quantisierungstechniken sind die Nullpunktquantisierung und die Absmax-Quantisierung (absolutes Maximum). Beide Methoden ordnen Gleitkommawerte kompakteren int8-Werten (1 Byte) zu.
Wenn beispielsweise bei der Nullpunktquantisierung der Datenbereich -1,0-1,0 beträgt und auf -127-127 quantisiert wird, beträgt der Erweiterungsfaktor 127. Bei diesem Erweiterungsfaktor wird beispielsweise ein Wert von 0,3 auf 0,3*127 = 38,1 erweitert. Bei der Quantisierung wird normalerweise gerundet, was 38 ergibt. Wenn wir dies umkehren, erhalten wir 38/127=0,2992 – ein Quantisierungsfehler von 0,008 in diesem Beispiel. Diese scheinbar kleinen Fehler neigen dazu, sich anzusammeln und zu wachsen, während sie sich durch die Modellebenen ausbreiten, und führen zu Leistungseinbußen.
Obwohl diese Techniken in der Lage sind, Deep-Learning-Modelle zu quantifizieren, führen sie häufig zu einer verringerten Modellgenauigkeit. Aber LLM.int8(), integriert in die Hugging Face Transformers- und Accelerate-Bibliotheken, ist die erste Technik, die die Leistung selbst für große Modelle mit 176B-Parametern (wie BLOOM) nicht beeinträchtigt. Der
LLM.int8()-Algorithmus kann wie folgt erklärt werden. Im Wesentlichen versucht LLM.int8(), Matrixmultiplikationsberechnungen in drei Schritten durchzuführen:
- Extrahieren Sie Ausreißer (d. h. größer als ein bestimmter Wert) spaltenweise aus Schwellenwert für den verborgenen Zustand eingeben).
- Matrixmultiplikation von Ausreißern in FP16 und Nicht-Ausreißern in int8.
- Dequantisieren Sie Nicht-Ausreißer in FP16 und addieren Sie die Ausreißer und Nicht-Ausreißer, um das vollständige Ergebnis zu erhalten.
Diese Schritte können in der folgenden Animation zusammengefasst werden:

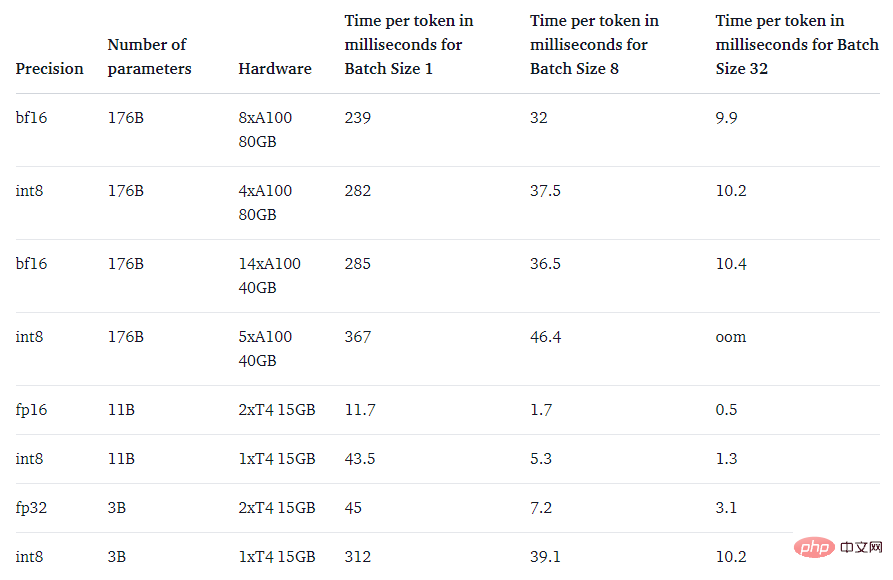
Abschließend ging die Studie auch der Frage nach: Ist es schneller als das native Modell?
Der Hauptzweck der LLM.int8()-Methode besteht darin, große Modelle zugänglicher zu machen, ohne die Leistung zu beeinträchtigen. Wenn es jedoch sehr langsam ist, ist es nicht sehr nützlich. Das Forschungsteam hat die Generierungsgeschwindigkeit mehrerer Modelle verglichen und festgestellt, dass BLOOM-176B mit LLM.int8() etwa 15 % bis 23 % langsamer war als die fp16-Version – was völlig akzeptabel ist. Und kleinere Modelle wie der T5-3B und der T5-11B verfügen über noch größere Verzögerungen. Das Forschungsteam arbeitet hart daran, diese kleinen Modelle schneller zu machen.
Das obige ist der detaillierte Inhalt vonEine Verbraucher-GPU führt erfolgreich ein großes Modell mit 176 Milliarden Parametern aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr