
Heim >Technologie-Peripheriegeräte >KI >Untersuchungen zeigen: Datenquellen bleiben der größte Engpass für KI
Untersuchungen zeigen: Datenquellen bleiben der größte Engpass für KI

- 王林nach vorne
- 2023-04-28 11:49:061301Durchsuche
Daten sind das Lebenselixier von Maschinen. Ohne sie können Sie nichts im Zusammenhang mit KI entwickeln. Laut dem diese Woche veröffentlichten Bericht „State of AI and Machine Learning“ von Appen haben viele Unternehmen immer noch Schwierigkeiten, gute, saubere Daten zu erhalten, um ihre KI- und maschinellen Lerninitiativen aufrechtzuerhalten.
Laut Appens Umfrage zur künstlichen Intelligenz verbraucht die Datenbeschaffung von den vier Phasen der künstlichen Intelligenz – Datenbeschaffung, Datenvorbereitung, Modellschulung und -bereitstellung sowie menschengesteuerte Modellevaluierung – die meisten Ressourcen, nimmt die meiste Zeit in Anspruch und ist auch die am meisten benötigte Zeit die anspruchsvollste. 504 Wirtschaftsführer und Technologieexperten.
Im Durchschnitt verschlingt die Datenbeschaffung 34 % des KI-Budgets eines Unternehmens, während Datenaufbereitung sowie Modelltests und -bereitstellung jeweils 24 % und die Modellbewertung 15 % ausmachen, laut Appens Umfrage, die von Harris Poll durchgeführt wurde und die IT einbezieht Entscheidungsträger, Wirtschaftsführer und Manager sowie Technologiepraktiker aus den USA, Großbritannien, Irland und Deutschland.
Was die Zeit betrifft, nimmt die Datenbeschaffung etwa 26 % der Zeit eines Unternehmens in Anspruch, während die Datenvorbereitung sowie Modelltests, -bereitstellung und -bewertung 24 % bzw. 23 % ausmachen. Schließlich betrachten 42 % der Technologen die Datenbeschaffung als die schwierigste Phase des KI-Lebenszyklus, verglichen mit der Modellbewertung (41 %), Modelltests und -bereitstellung (38 %) und Datenaufbereitung (34 %).
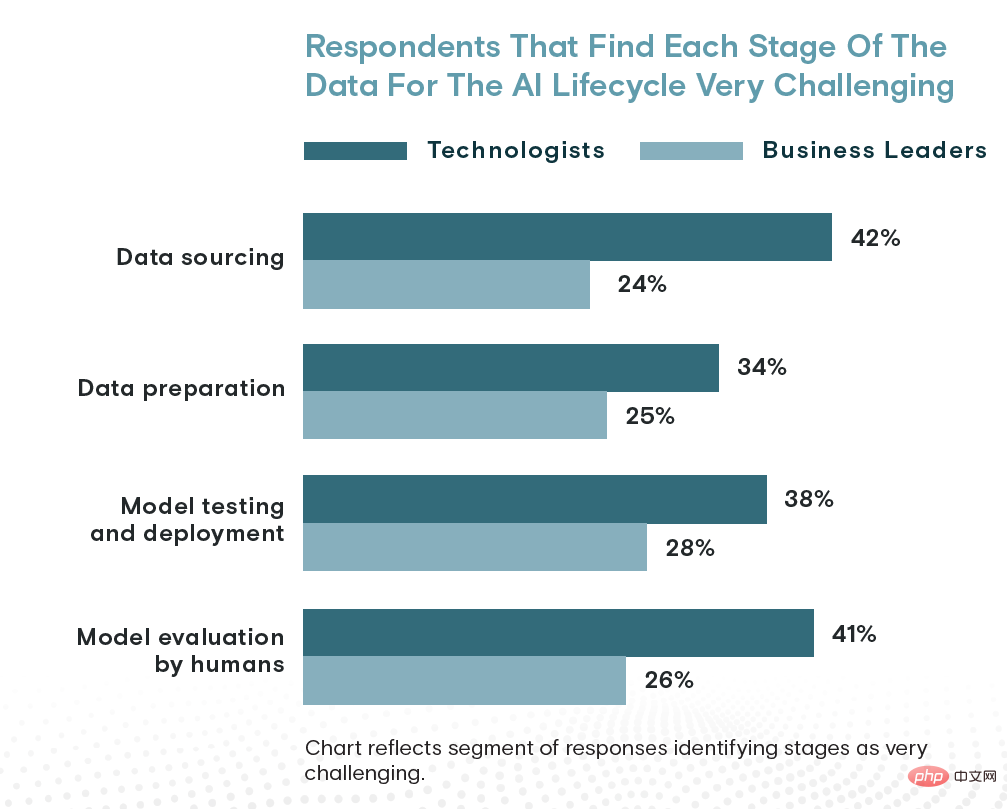
Laut Technologieexperten ist die Datenbeschaffung die größte Herausforderung für künstliche Intelligenz. Aber Unternehmensführer sehen die Dinge anders ...
Trotz der Herausforderungen schaffen es Unternehmen, dass es gelingt. Laut Appen gaben vier Fünftel (81 %) der Befragten an, zuversichtlich zu sein, dass sie über genügend Daten verfügen, um ihre KI-Initiativen zu unterstützen. Vielleicht der Schlüssel zu diesem Erfolg: Die überwiegende Mehrheit (88 %) erweitert ihre Daten durch den Einsatz externer Anbieter von KI-Trainingsdaten wie Appen.
Allerdings ist die Genauigkeit der Daten fraglich. Appen stellte fest, dass nur 20 % der Befragten eine Datengenauigkeit von mehr als 80 % angaben. Nur 6 % (etwa 1 von 10) gaben an, dass ihre Daten zu 90 % oder besser seien. Mit anderen Worten: Bei mehr als 80 % der Unternehmen enthält jede fünfte Daten Fehler.
Vor diesem Hintergrund ist es vielleicht nicht verwunderlich, dass laut Appens Umfrage fast die Hälfte (46 %) der Befragten der Meinung sind, dass Datengenauigkeit wichtig ist, „aber wir können sie beheben“. Nur 2 % gaben an, dass Datengenauigkeit kein großes Bedürfnis sei, während 51 % zustimmten, dass es sich um ein entscheidendes Bedürfnis handele.
Es scheint, dass die Meinung von Appen-CTO Wilson Pang zur Bedeutung der Datenqualität mit der Meinung von 48 % der Kunden übereinstimmt, die glauben, dass Datenqualität nicht wichtig ist.
„Datengenauigkeit ist entscheidend für den Erfolg von KI- und ML-Modellen, da qualitativ hochwertige Daten zu einer besseren Modellausgabe und einer konsistenten Verarbeitung und Entscheidungsfindung führen“, sagte Pang in dem Bericht. „Um gute Ergebnisse zu erzielen, müssen Datensätze genau, umfassend und skalierbar sein.“
Über 90 % der Appen-Befragten gaben an, dass sie vorab gekennzeichnete Daten verwenden
Pang sagte kürzlich in einem Interview: Der Aufstieg des Deep Learning und datenzentrierte KI hat den Treiber des KI-Erfolgs von guter Datenwissenschaft und Modellierung des maschinellen Lernens hin zu guter Datenerfassung, -verwaltung und -kennzeichnung verlagert. Dies gilt insbesondere für die heutigen Transferlerntechniken, bei denen KI-Praktiker auf eine große vorab trainierte Sprache oder ein Computer-Vision-Modell aufspringen und einen kleinen Satz von Schichten mit ihren eigenen Daten neu trainieren.
Bessere Daten können auch dazu beitragen, zu verhindern, dass sich unnötige Verzerrungen in KI-Modelle einschleichen, und generell schlechte KI-Ergebnisse verhindern. Dies gilt insbesondere für große Sprachmodelle, sagte Ilia Shifrin, Senior Director of AI bei Appen.
„Mit dem Aufkommen großer Sprachmodelle (Large Language Models, LLMs), die auf mehrsprachigen Webcrawler-Daten trainiert werden, stehen Unternehmen vor einer weiteren Herausforderung“, sagte Shifrin in dem Bericht. „Diese Modelle zeigen oft schlechtes Verhalten aufgrund der Fülle an giftiger Sprache sowie rassistischer, geschlechtsspezifischer und religiöser Voreingenommenheit im Trainingskorpus.“ Shifrin sagte, dass mehr Forschung erforderlich sei, um einen guten Standard für „menschenzentrierte“ LLM-Benchmarks und Modellbewertungsmethoden zu etablieren.
Laut Appen bleibt das Datenmanagement das größte Hindernis für KI. Die Umfrage ergab, dass 41 % der Menschen im KI-Zyklus glauben, dass die Datenverwaltung den größten Engpass darstellt. Der Mangel an Daten lag an vierter Stelle, wobei 30 % ihn als größtes Hindernis für den KI-Erfolg nannten.
Aber es gibt eine gute Nachricht: Die Zeit, die Unternehmen mit der Verwaltung und Aufbereitung von Daten verbringen, geht tendenziell zurück. In diesem Jahr waren es etwas mehr als 47 %, verglichen mit 53 % im letztjährigen Bericht, sagte Appen.
Die Datengenauigkeit ist möglicherweise nicht so hoch, wie manche Organisationen es gerne hätten
„Da die Mehrheit der Befragten externe Datenanbieter nutzt, kann gefolgert werden, dass Datenwissenschaftler durch die Auslagerung der Datenbeschaffung und -aufbereitung Zeit sparen, die für eine ordnungsgemäße Verwaltung erforderlich ist „Es ist Zeit erforderlich, Daten zu bereinigen und zu kennzeichnen“, sagte das Datenkennzeichnungsunternehmen.
Angesichts der relativ hohen Fehlerraten in den Daten sollten Unternehmen ihre Prozesse zur Datenbeschaffung und -aufbereitung (ob intern oder extern) vielleicht nicht reduzieren. Beim Aufbau und der Wartung von KI-Prozessen gibt es viele konkurrierende Anforderungen – die Einstellung qualifizierter Datenexperten war ein weiterer wichtiger Bedarf, den Appen identifizierte. Bis jedoch wesentliche Fortschritte im Datenmanagement erzielt werden, sollten Unternehmen weiterhin Druck auf ihre Teams ausüben, um die Bedeutung der Datenqualität weiter voranzutreiben.
Die Umfrage ergab außerdem, dass 93 % der Organisationen voll und ganz oder eher der Aussage zustimmen, dass ethische KI die „Grundlage“ von KI-Projekten sein sollte. Mark Brayan, CEO von Appen, sagte, es sei ein guter Anfang gewesen, aber es gebe noch viel zu tun. „Das Problem besteht darin, dass viele Menschen vor der Herausforderung stehen, mit schlechten Datensätzen eine großartige KI aufzubauen, was ein erhebliches Hindernis für das Erreichen ihrer Ziele darstellt“, sagte Brayan in einer Pressemitteilung.
Intern, individuell erfasste Daten stellen nach wie vor den Großteil der für KI verwendeten Datensätze von Unternehmen dar und machen laut Appens Bericht 38 % bis 42 % der Daten aus. Synthetische Daten schnitten überraschend gut ab und machten 24 bis 38 % der Daten einer Organisation aus, während vorgekennzeichnete Daten (in der Regel von Datendienstanbietern bezogen) 23 bis 31 % der Daten ausmachten.
Insbesondere synthetische Daten haben das Potenzial, das Auftreten von Verzerrungen in sensiblen KI-Projekten zu reduzieren. 97 % der Appen-Befragten gaben an, dass sie synthetische Daten „bei der Entwicklung inklusiver Trainingsdatensätze“ verwenden.
Weitere interessante Erkenntnisse aus dem Bericht sind:
- 77 % der Unternehmen schulen ihre Modelle monatlich oder vierteljährlich; Organisationen berichten von einer „breiten“ Einführung von KI, verglichen mit 51 % im Bericht „State of Artificial Intelligence“ 2021.
- 7 % der Organisationen geben an, dass ihr KI-Budget 5 Millionen US-Dollar übersteigt, verglichen mit 9 % im letzten Jahr.
Das obige ist der detaillierte Inhalt vonUntersuchungen zeigen: Datenquellen bleiben der größte Engpass für KI. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr