
Heim >Technologie-Peripheriegeräte >KI >Echtes Quantengeschwindigkeitslesen: Neue Forschungen durchbrechen die Grenze von GPT-4, die nur 50 Textseiten gleichzeitig verstehen kann, und dehnen sich auf Millionen von Token aus
Echtes Quantengeschwindigkeitslesen: Neue Forschungen durchbrechen die Grenze von GPT-4, die nur 50 Textseiten gleichzeitig verstehen kann, und dehnen sich auf Millionen von Token aus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-28 10:37:241129Durchsuche
Vor mehr als einem Monat kam GPT-4 von OpenAI heraus. Neben verschiedenen hervorragenden visuellen Demonstrationen implementiert es auch ein wichtiges Update: Es kann standardmäßig Kontext-Tokens mit einer Länge von 8 KB verarbeiten, kann jedoch bis zu 32 KB (ca. 50 Textseiten) lang sein. Das bedeutet, dass wir bei Fragen an GPT-4 viel längeren Text eingeben können als zuvor. Dies erweitert die Anwendungsszenarien von GPT-4 erheblich und kann lange Gespräche, lange Texte sowie die Dateisuche und -analyse besser bewältigen.
Dieser Rekord wurde jedoch schnell gebrochen: CoLT5 von Google Research erweiterte die Kontext-Token-Länge, die das Modell verarbeiten kann, auf 64k.
Ein solcher Durchbruch ist nicht einfach, da diese Modelle, die die Transformer-Architektur verwenden, alle mit einem Problem konfrontiert sind: Die Verarbeitung langer Dokumente durch Transformer ist rechenintensiv, da die Aufmerksamkeitskosten quadratisch mit der Eingabelänge steigen, was große Modelle immer schwieriger macht auf längere Eingaben anzuwenden.
Trotzdem erzielen Forscher immer noch Durchbrüche in dieser Richtung. Vor ein paar Tagen zeigte eine Studie des Open-Source-Conversational-AI-Technologie-Stacks DeepPavlov und anderer Institutionen, dass: Durch die Verwendung einer Architektur namens Recurrent Memory Transformer (RMT) können sie die effektive Kontextlänge des BERT-Modells auf 2 Millionen erhöhen Token (gemäß der Berechnungsmethode von OpenAI entspricht dies ungefähr 3200 Seiten Text) und behält gleichzeitig eine hohe Speicherabrufgenauigkeit bei (Hinweis: Recurrent Memory Transformer ist eine Methode, die von Aydar Bulatov et al. in einem Artikel bei NeurIPS 2022 vorgeschlagen wurde) . Die neue Methode ermöglicht die Speicherung und Verarbeitung lokaler und globaler Informationen sowie den Informationsfluss zwischen Segmenten der Eingabesequenz durch die Verwendung von Wiederholungen.

Der Autor gab an, dass sie RMT mit einem vorab trainierten Transformer-Modell wie BERT kombinieren können, indem sie den von Bulatov et al. im Artikel „Recurrent Memory Transformer“ eingeführten einfachen tokenbasierten Speichermechanismus verwenden , Eine einzelne Nvidia GTX 1080Ti-GPU kann Operationen mit voller Aufmerksamkeit und höchster Präzision für Sequenzen von mehr als 1 Million Token ausführen.

Papieradresse: https://arxiv.org/pdf/2304.11062.pdf
Einige Leute haben jedoch daran erinnert, dass dies kein echtes „kostenloses Mittagessen“ ist, wie erwähnt oben Die Verbesserung der Arbeit wird im Austausch für „längere Argumentationszeit + erhebliche Qualitätsminderung“ erreicht. Daher ist es noch keine Revolution, aber es könnte die Grundlage für das nächste Paradigma werden (Token können unendlich lang sein).
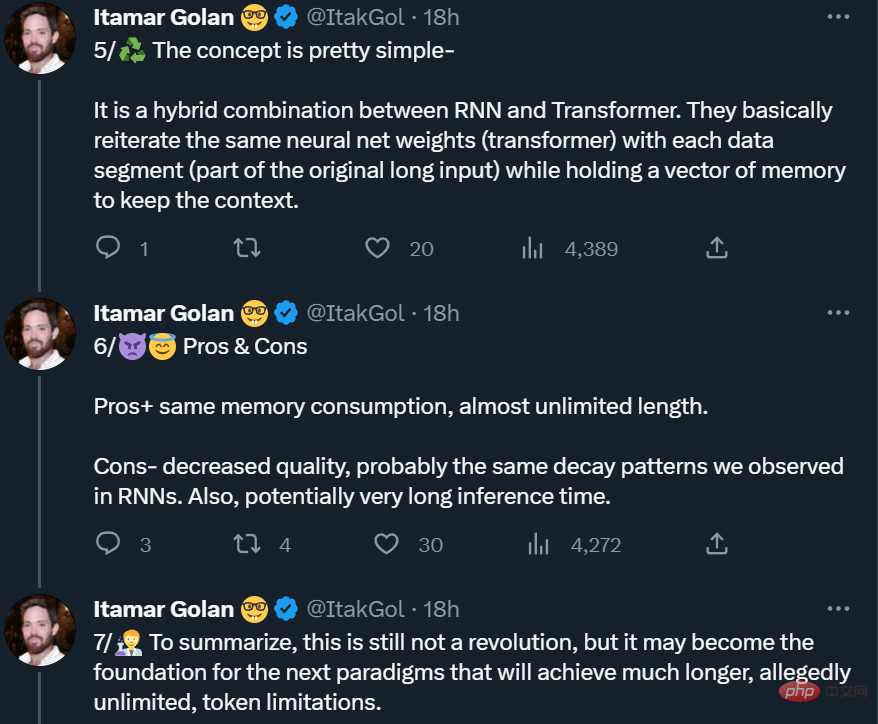
Recurrent Memory Transformer
Diese Studie übernimmt die von Bulatov et al. vorgeschlagene Methode Recurrent Memory Transformer (RMT) und wandelt sie in eine Plug-and-Play-Methode um Wie in der folgenden Abbildung gezeigt:
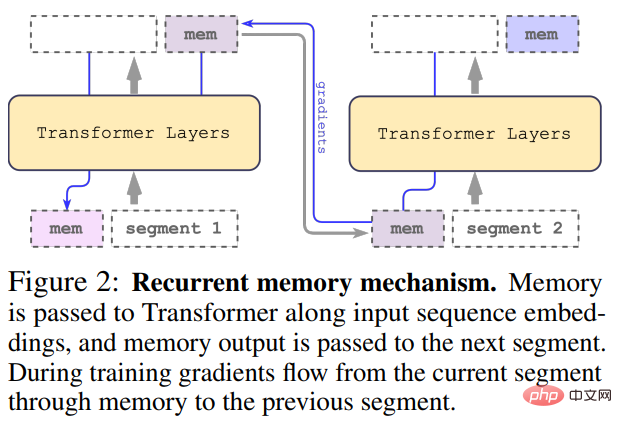
Die lange Eingabe wird in mehrere Segmente unterteilt, und der Speichervektor wird vor dem Einbetten zum ersten Segment hinzugefügt und zusammen mit dem Segment-Token verarbeitet. Bei reinen Encoder-Modellen wie BERT wird der Speicher nur einmal am Anfang des Segments hinzugefügt, im Gegensatz zu (Bulatov et al., 2022), wo das reine Decoder-Modell den Speicher in Lese- und Schreibteile unterteilt. Für den Zeitschritt τ und das Segment
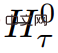
wird die Schleife wie folgt ausgeführt:

wobei N die Anzahl der Transformatorschichten ist. Nach der Vorwärtspropagierung enthält
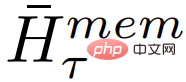
das aktualisierte Speichertoken von Segment τ.
Die Segmente der Eingabesequenz werden der Reihe nach verarbeitet. Um Schleifenverbindungen zu ermöglichen, übergibt die Studie die Ausgabe von Speichertokens aus dem aktuellen Segment an die Eingabe des nächsten Segments:
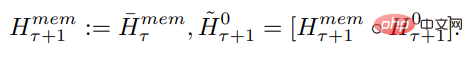
Sowohl Speicher als auch Schleifen in RMT basieren nur auf globalen Speichertokens. Dadurch bleibt der Backbone-Transformer unverändert, sodass die Speichererweiterungsfunktionen von RMT mit jedem Transformer-Modell kompatibel sind.
Recheneffizienz
Diese Studie schätzt die erforderlichen FLOPs für RMT- und Transformer-Modelle unterschiedlicher Größe und Sequenzlänge.
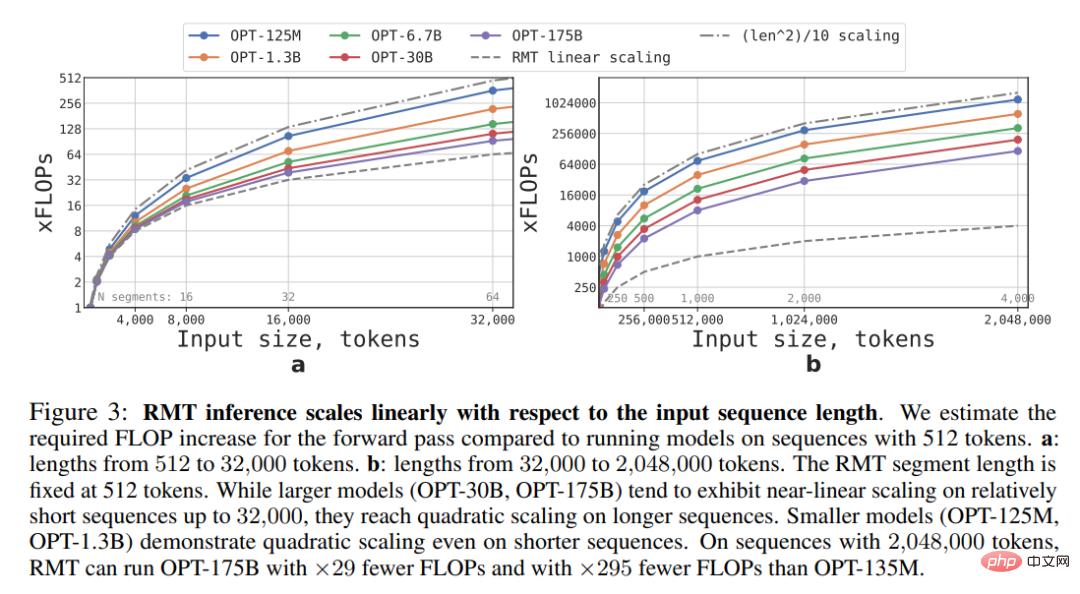
Wie in Abbildung 3 unten dargestellt, kann RMT für jede Modellgröße linear skaliert werden, wenn die Länge des Segments festgelegt ist. Diese Studie erreicht eine lineare Skalierung, indem die Eingabesequenz in Segmente unterteilt und die vollständige Aufmerksamkeitsmatrix nur innerhalb der Segmentgrenzen berechnet wird.
Aufgrund der hohen Rechenkomplexität der FFN-Schicht weisen größere Transformer-Modelle tendenziell eine langsamere quadratische Skalierung mit der Sequenzlänge auf. Bei sehr langen Sequenzen größer als 32000 greifen sie jedoch auf die quadratische Entwicklung zurück. Für Sequenzen mit mehr als einem Segment (> 512 in dieser Studie) erfordert RMT weniger FLOPs als azyklische Modelle und kann die Anzahl der FLOPs um das bis zu 295-fache reduzieren. RMT bietet eine größere relative Reduzierung des FLOP für kleinere Modelle, aber die 29-fache Reduzierung des FLOP für das Modell OPT-175B ist in absoluten Zahlen signifikant.
Gedächtnisaufgabe
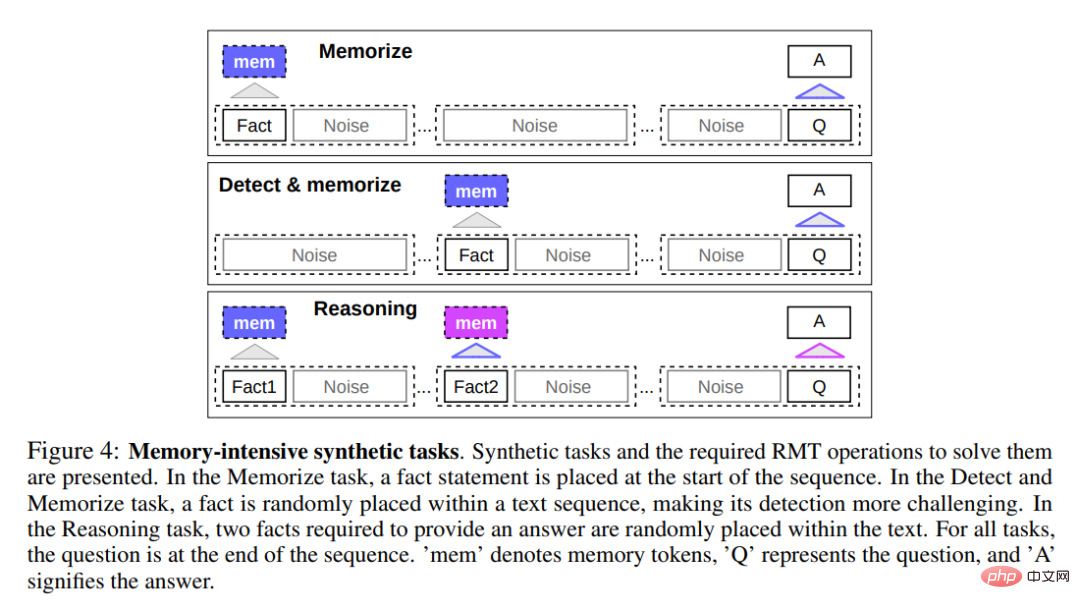
Um die Gedächtnisfähigkeiten zu testen, erstellte die Studie synthetische Datensätze, die das Auswendiglernen einfacher Fakten und grundlegender Überlegungen erforderten. Die Aufgabeneingabe besteht aus einem oder mehreren Fakten und einer Frage, die nur mit allen Fakten beantwortet werden kann. Um die Schwierigkeit der Aufgabe zu erhöhen, fügte die Studie auch Text in natürlicher Sprache hinzu, der nichts mit der Frage oder Antwort zu tun hatte, um als Rauschen zu fungieren. Daher wurde das Modell damit beauftragt, Fakten von irrelevantem Text zu trennen und die Fakten zur Beantwortung der Frage zu verwenden.

Faktisches Gedächtnis
Die erste Aufgabe bestand darin, die Fähigkeit von RMT zu untersuchen, Informationen über lange Zeiträume zu schreiben und im Gedächtnis zu speichern, wie oben in Abbildung 4 unten dargestellt. Im einfachsten Fall stehen die Fakten meist am Anfang der Eingabe, die Fragen immer am Ende. Die Menge an irrelevantem Text zwischen Fragen und Antworten nimmt allmählich zu, bis die gesamte Eingabe nicht mehr in eine einzelne Modelleingabe passt.

Faktenerkennung und Erinnerung
Die Faktenerkennung erhöht die Schwierigkeit der Aufgabe, indem sie einen Fakt an eine zufällige Position in der Eingabe verschiebt, wie in der Mitte von Abbildung 4 oben dargestellt. Dies erfordert, dass das Modell zunächst die Tatsache von irrelevantem Text unterscheidet, die Tatsache ins Gedächtnis schreibt und sie dann am Ende zur Beantwortung der Frage verwendet.
Auswendig gelernte Fakten zum Denken nutzen
Eine weitere Operation des Gedächtnisses besteht darin, auswendig gelernte Fakten und den aktuellen Kontext zum Denken zu nutzen. Um diese Funktionalität zu bewerten, verwendeten die Forscher eine komplexere Aufgabe, bei der zwei Fakten generiert und in eine Eingabesequenz eingefügt wurden, wie unten in Abbildung 4 oben dargestellt. Die am Ende der Sequenz gestellte Frage wird so beschrieben, dass zur korrekten Beantwortung der Frage willkürliche Fakten herangezogen werden müssen.

Experimentelle Ergebnisse
Die Forscher verwendeten 4 bis 8 NVIDIA 1080ti-GPUs, um das Modell zu trainieren und zu bewerten. Für längere Sequenzen verwendeten sie eine einzelne 40-GB-NVIDIA A100, um die Auswertung zu beschleunigen.
Kurslernen
Die Forscher stellten fest, dass die Verwendung des Trainingsplans die Genauigkeit und Stabilität der Lösung erheblich verbessern kann. RMT wird zunächst auf einer kürzeren Version der Aufgabe trainiert und erhöht die Aufgabenlänge durch Hinzufügen eines weiteren Segments, wenn das Training konvergiert. Der Kurslernprozess wird fortgesetzt, bis die erforderliche Eingabelänge erreicht ist.
Im Experiment begannen die Forscher zunächst mit einer Sequenz, die für ein einzelnes Segment geeignet war. Die tatsächliche Segmentgröße beträgt 499, aber aufgrund der 3 speziellen Token und 10 Speicherplatzhalter von BERT, die aus der Modelleingabe übernommen wurden, beträgt die Größe 512. Sie stellen fest, dass RMT nach dem Training einer kürzeren Aufgabe längere Versionen der Aufgabe leichter lösen kann, da weniger Trainingsschritte erforderlich sind, um zu einer perfekten Lösung zu gelangen.
Extrapolationsfähigkeit
Was ist die Generalisierungsfähigkeit von RMT auf verschiedene Sequenzlängen? Um diese Frage zu beantworten, bewerteten die Forscher Modelle, die auf einer unterschiedlichen Anzahl von Segmenten trainiert wurden, um längere Aufgaben zu lösen, wie in Abbildung 5 unten dargestellt.
Sie beobachteten, dass Modelle bei kürzeren Aufgaben tendenziell eine bessere Leistung erbringen, mit der einzigen Ausnahme bei der Einzelsegment-Inferenzaufgabe, die schwieriger zu lösen ist, sobald das Modell auf längeren Sequenzen trainiert wird. Eine mögliche Erklärung ist, dass das Modell, da die Aufgabengröße ein Segment überschreitet, keine Probleme im ersten Segment mehr „erwartet“, was zu einer Verschlechterung der Qualität führt.
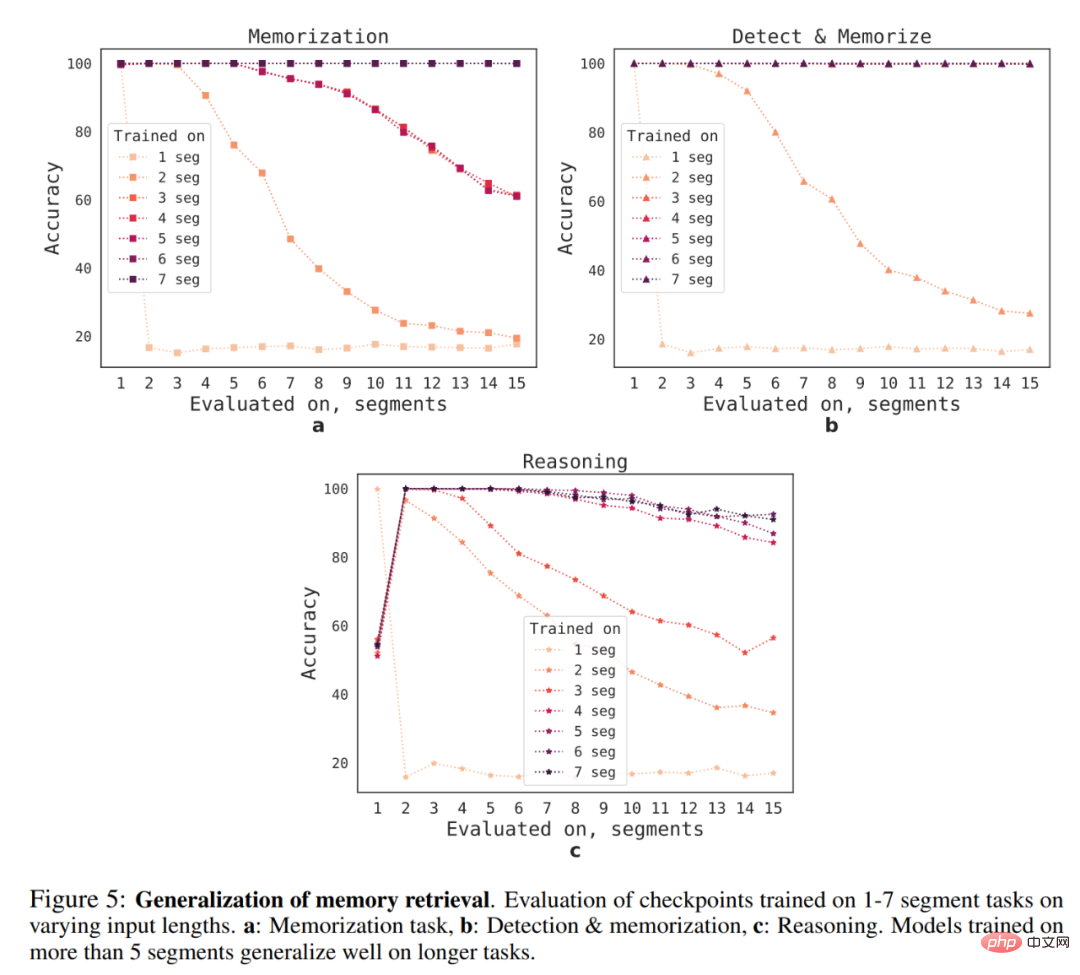
Interessanterweise zeigt sich auch die Fähigkeit von RMT, auf längere Sequenzen zu verallgemeinern, wenn die Anzahl der Trainingssegmente zunimmt. Nach dem Training in 5 oder mehr Segmenten kann RMT nahezu perfekt auf doppelt so lange Aufgaben verallgemeinern.
Um die Grenzen der Generalisierung zu testen, erhöhten die Forscher die Größe der Verifizierungsaufgabe auf 4096 Segmente oder 2.043.904 Token (wie in Abbildung 1 oben gezeigt), schnitt RMT bei einer so langen Sequenz überraschend gut ab. Erkennungs- und Speicheraufgaben sind die einfachsten und Inferenzaufgaben die komplexesten.
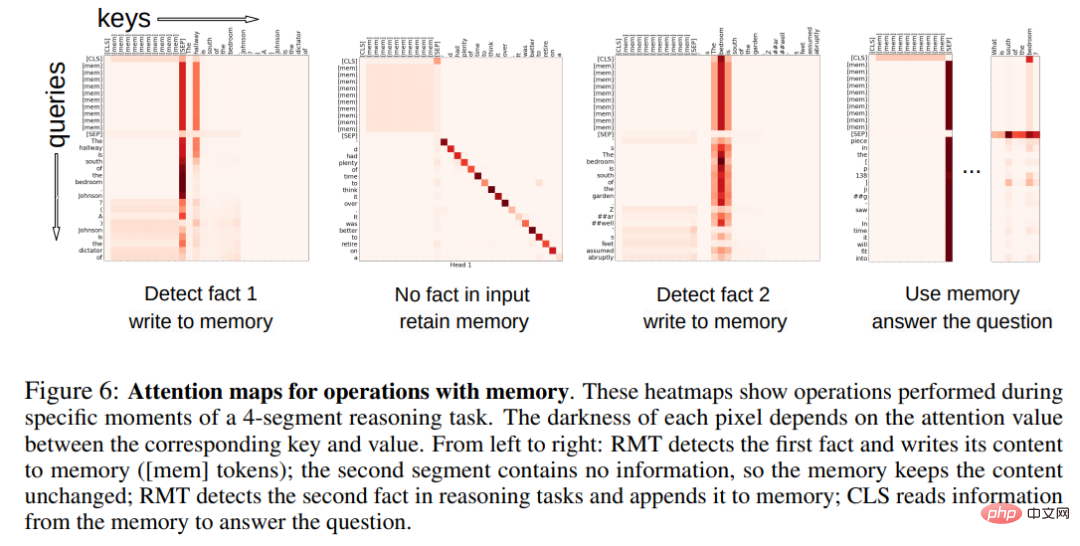
Aufmerksamkeitsmuster von Gedächtnisoperationen
In Abbildung 6 unten stellte der Forscher durch Untersuchung der RMT-Aufmerksamkeit auf bestimmte Segmente fest, dass Gedächtnisoperationen bestimmten Aufmerksamkeitsmustern entsprechen. Darüber hinaus zeigt die hohe Extrapolationsleistung bei extrem langen Sequenzen in Abschnitt 5.2 die Wirksamkeit der gelernten Speicheroperationen, selbst bei tausendfacher Verwendung.
Weitere technische und experimentelle Details finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonEchtes Quantengeschwindigkeitslesen: Neue Forschungen durchbrechen die Grenze von GPT-4, die nur 50 Textseiten gleichzeitig verstehen kann, und dehnen sich auf Millionen von Token aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr