
Heim >Technologie-Peripheriegeräte >KI >DeepMind sagte: KI-Modelle müssen abnehmen, und Autoregression wird zum Haupttrend
DeepMind sagte: KI-Modelle müssen abnehmen, und Autoregression wird zum Haupttrend

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-27 16:49:081020Durchsuche
Autoregressive Aufmerksamkeitsprogramme mit Transformer als Kern waren schon immer schwierig, die Skalierungsschwierigkeiten zu überwinden. Zu diesem Zweck haben DeepMind/Google kürzlich ein neues Projekt ins Leben gerufen, um einen guten Weg vorzuschlagen, wie solche Programme effektiv abgespeckt werden können.
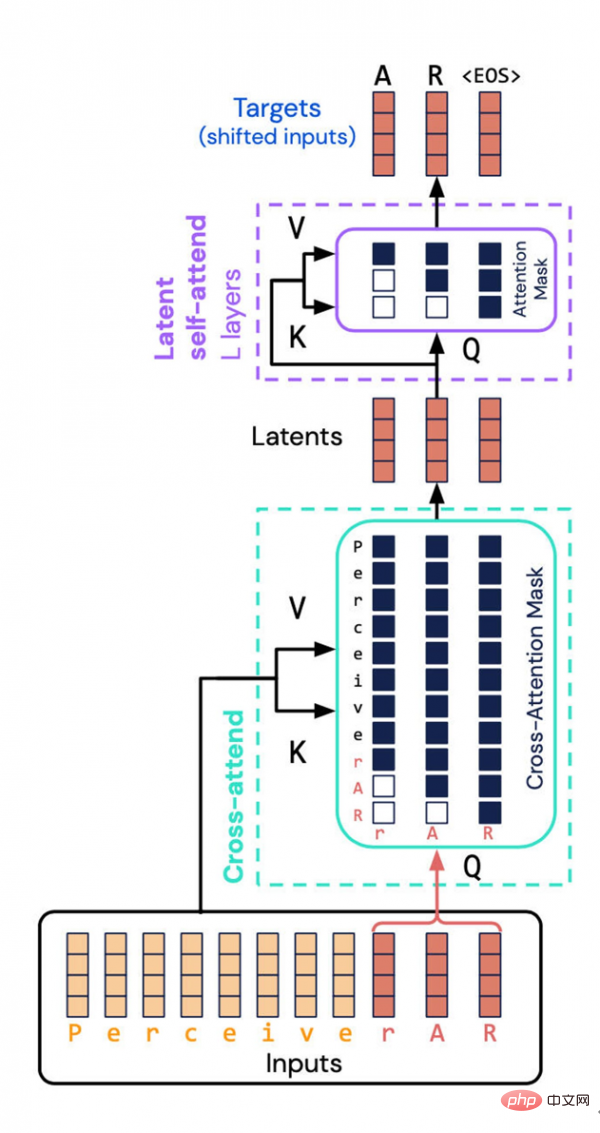
Die von DeepMind und Google Brain entwickelte Perceiver AR-Architektur vermeidet eine ressourcenintensive Aufgabe – die Berechnung der kombinierten Eigenschaften von Eingabe und Ausgabe im latenten Raum. Stattdessen führten sie eine „kausale Maskierung“ in den latenten Raum ein und erreichten so die autoregressive Ordnung eines typischen Transformers.
Einer der beeindruckendsten Entwicklungstrends im Bereich Künstliche Intelligenz/Deep Learning ist, dass die Größe der Modelle immer größer wird. Experten auf diesem Gebiet sagen, dass diese Welle der Volumenexpansion wahrscheinlich anhalten wird, da die Größe oft direkt mit der Leistung zusammenhängt.
Da jedoch der Projektumfang immer größer wird, werden natürlich immer mehr Ressourcen verbraucht, was dazu führt, dass Deep Learning neue soziale und ethische Fragen aufwirft. Dieses Dilemma hat die Aufmerksamkeit etablierter wissenschaftlicher Fachzeitschriften wie „Nature“ auf sich gezogen.
Aus diesem Grund müssen wir möglicherweise zum alten Wort „Effizienz“ zurückkehren – KI-Programme. Gibt es Raum für weitere Effizienzverbesserungen?
Wissenschaftler der DeepMind- und Google Brain-Abteilungen haben kürzlich das im letzten Jahr eingeführte neuronale Netzwerk Perceiver modifiziert, in der Hoffnung, seine Effizienz bei der Nutzung von Rechenressourcen zu verbessern.
Das neue Programm heißt Perceiver AR. Das AR stammt hier von „autoregressiv“, was heute auch eine weitere Entwicklungsrichtung immer mehr Deep-Learning-Programme ist. Autoregression ist eine Technik, die es der Maschine ermöglicht, die Ausgabe als neue Eingabe für das Programm zu verwenden. Es handelt sich um eine rekursive Operation, wodurch eine Aufmerksamkeitskarte erstellt wird, in der mehrere Elemente miteinander in Beziehung stehen.
Das beliebte neuronale Netzwerk Transformer, das 2017 von Google eingeführt wurde, verfügt ebenfalls über diese autoregressive Eigenschaft. Tatsächlich setzten das spätere GPT-3 und die erste Version von Perceiver den autoregressiven technischen Weg fort.
Bevor Perceiver AR im März dieses Jahres auf den Markt kam, war Perceiver IO die zweite Version von Perceiver. Noch weiter zurückgehend: Es war die erste Version von Perceiver, die letztes Jahr um diese Zeit veröffentlicht wurde.
Die ursprüngliche Innovation von Perceiver besteht darin, Transformer zu verwenden und Anpassungen vorzunehmen, sodass es verschiedene Eingaben, einschließlich Text, Ton und Bilder, flexibel absorbieren kann und so die Abhängigkeit von bestimmten Eingabearten beseitigt. Dies ermöglicht es Forschern, neuronale Netze mit mehreren Eingabetypen zu entwickeln.
Als Teil des Trends der Zeit hat Perceiver, wie auch andere Modellprojekte, damit begonnen, den autoregressiven Aufmerksamkeitsmechanismus zu nutzen, um verschiedene Eingabemodi und verschiedene Aufgabenbereiche zu mischen. Zu diesen Anwendungsfällen gehören auch Pathways von Google, Gato von DeepMind und data2vec von Meta.
Im März dieses Jahres veröffentlichten Andrew Jaegle, der Schöpfer der ersten Version von Perceiver, und sein Kollegenteam die „IO“-Version. Die neue Version erweitert die von Perceiver unterstützten Ausgabetypen und ermöglicht eine große Anzahl von Ausgaben mit einer Vielzahl von Strukturen, darunter Textsprache, optische Flussfelder, audiovisuelle Sequenzen und sogar ungeordnete Symbolsätze usw. Perceiver IO kann sogar Bedienungsanleitungen im Spiel „StarCraft 2“ generieren.
In diesem neuesten Artikel konnte Perceiver AR eine allgemeine autoregressive Modellierung für lange Kontexte implementieren. Doch während der Forschung stießen Jaegle und sein Team auch auf neue Herausforderungen: Wie lässt sich das Modell skalieren, wenn es mit verschiedenen multimodalen Eingabe- und Ausgabeaufgaben umgeht?
Das Problem besteht darin, dass die autoregressive Qualität des Transformers und jedes Programms, das auch Eingabe-zu-Ausgabe-Aufmerksamkeitskarten erstellt, riesige Verteilungsgrößen von bis zu Hunderttausenden Elementen erfordert.
Das ist die fatale Schwäche des Aufmerksamkeitsmechanismus. Genauer gesagt muss alles beachtet werden, um eine Wahrscheinlichkeitsverteilung der Aufmerksamkeitskarte zu erstellen.
Wie Jaegle und sein Team in dem Artikel erwähnten, wird der Verbrauch von Rechenressourcen durch das Modell zunehmend übertrieben, wenn die Anzahl der Dinge, die in der Eingabe miteinander verglichen werden müssen, zunimmt:
Diese lange Kontextstruktur und die Berechnung Die Eigenschaften von Transformer stehen im Widerspruch zueinander. Transformatoren führen wiederholt Selbstaufmerksamkeitsoperationen an der Eingabe durch, was dazu führt, dass der Rechenbedarf sowohl quadratisch mit der Eingabelänge als auch linear mit der Modelltiefe wächst. Je mehr Eingabedaten vorhanden sind, desto mehr Eingabetags entsprechen dem beobachteten Dateninhalt, die Muster in den Eingabedaten werden subtiler und komplexer und es müssen tiefere Schichten verwendet werden, um die generierten Muster zu modellieren. Aufgrund der begrenzten Rechenleistung sind Transformer-Benutzer gezwungen, entweder die Modelleingabe zu kürzen (wodurch die Beobachtung weiter entfernter Muster verhindert wird) oder die Tiefe des Modells zu begrenzen (wodurch ihm die Ausdrucksfähigkeit zur Modellierung komplexer Muster entzogen wird).
Tatsächlich versuchte die erste Version von Perceiver auch, die Effizienz von Transformers zu verbessern: nicht direkt Aufmerksamkeit auszuüben, sondern Aufmerksamkeit auf die potenzielle Darstellung des Inputs zu lenken. Auf diese Weise können die Rechenleistungsanforderungen für die Verarbeitung großer Eingabearrays „von den Rechenleistungsanforderungen für große tiefe Netzwerke (entkoppelt) werden“.
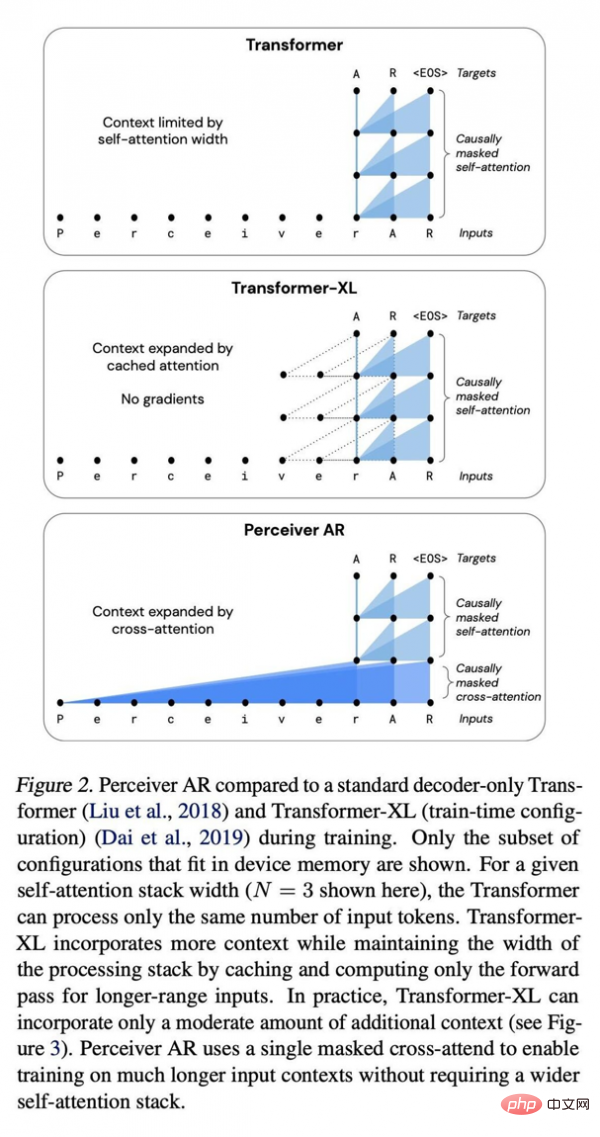
Vergleich zwischen Perceiver AR, Standard-Transformer-Deep-Network und erweitertem Transformer XL.
Im latenten Teil wird die Eingabedarstellung komprimiert, was sie zu einer effizienteren Aufmerksamkeitsmaschine macht. Auf diese Weise „erfolgen bei tiefen Netzwerken die meisten Berechnungen tatsächlich auf dem Selbstaufmerksamkeitsstapel“, anstatt unzählige Eingaben verarbeiten zu müssen.
Aber die Herausforderung besteht immer noch, da die zugrunde liegende Darstellung nicht über das Konzept der Ordnung verfügt und Perceiver daher keine Ausgabe wie Transformer generieren kann. Und die Reihenfolge ist bei der Autoregression von entscheidender Bedeutung. Jede Ausgabe sollte das Produkt der Eingabe davor sein, nicht das Produkt danach.
Die Forscher schreiben: „Da aber jedes latente Modell auf alle Eingaben unabhängig von ihrem Standort achtet, kann Perceiver nicht direkt anwendbar sein.“
Was Perceiver AR betrifft, ging das Forschungsteam noch einen Schritt weiter und fügte die Sequenz ein in Perceiver übertragen, um eine automatische Regression zu ermöglichen.
Der Schlüssel liegt hier darin, eine sogenannte „kausale Maskierung“ der Eingabe und der latenten Darstellung durchzuführen. Auf der Eingabeseite führt die kausale Maskierung zu einer „Kreuzaufmerksamkeit“, während sie auf der zugrunde liegenden Darstellungsseite das Programm dazu zwingt, nur auf das zu achten, was vor einem bestimmten Symbol steht. Diese Methode stellt die Richtwirkung des Transformators wieder her und kann den Gesamtberechnungsaufwand dennoch erheblich reduzieren.
Das Ergebnis ist, dass Perceiver AR basierend auf mehr Eingaben mit Transformer vergleichbare Modellierungsergebnisse erzielen kann, die Leistung jedoch erheblich verbessert wird.
Sie schreiben: „Perceiver AR kann lange Kontextmuster, die bei synthetischen Kopieraufgaben mindestens 100.000 Token voneinander entfernt sind, perfekt identifizieren und lernen.“ Im Vergleich dazu hat Transformer ein festes Limit von 2048 Token, und je mehr Token der Kontext, desto länger desto komplexer wird die Programmausgabe sein.
Im Vergleich zu den Transformer- und Transformer-XL-Architekturen, die häufig reine Decoder verwenden, ist Perceiver AR effizienter und kann die tatsächlich während des Tests verwendeten Rechenressourcen flexibel entsprechend dem Zielbudget ändern.
Das Papier schreibt, dass unter den gleichen Aufmerksamkeitsbedingungen die Berechnungszeit des Perceiver AR deutlich kürzer ist und bei gleichem Rechenleistungsbudget mehr Kontext (d. h. mehr Eingabesymbole) absorbiert werden kann:
Kontextlänge von Transformer The Die Grenze liegt bei 2048 Markern, was der Unterstützung von nur 6 Ebenen entspricht – da größere Modelle und längere Kontexte sehr viel Speicher erfordern. Mit der gleichen 6-Schichten-Konfiguration können wir die Gesamtkontextlänge des Transformer-XL-Speichers auf 8192 Token erweitern. Perceiver AR kann die Kontextlänge auf 65.000 Marker erweitern, und bei weiterer Optimierung wird erwartet, dass sie sogar 100.000 überschreitet.
All dies macht das Rechnen flexibler: „Wir können die Menge an Berechnungen, die ein bestimmtes Modell während des Tests generiert, besser kontrollieren und so ein stabiles Gleichgewicht zwischen Geschwindigkeit und Leistung finden
Auch Jaegle und Kollegen schreiben, dass dieser Ansatz funktioniert.“ mit jedem Eingabetyp und ist nicht auf Wortsymbole beschränkt. Beispielsweise können Pixel in Bildern unterstützt werden:
Der gleiche Prozess funktioniert für jede Eingabe, die sortiert werden kann, sofern kausale Maskierungstechniken angewendet werden. Beispielsweise können die RGB-Kanäle eines Bildes in Raster-Scan-Reihenfolge sortiert werden, indem die R-, G- und B-Farbkanäle jedes Pixels in der Reihenfolge in der Reihenfolge oder außerhalb der Reihenfolge dekodiert werden.
Die Autoren fanden großes Potenzial in Perceiver und schrieben in der Arbeit: „Perceiver AR ist ein idealer Kandidat für allgemeine autoregressive Modelle mit langem Kontext.“
Aber um eine höhere Recheneffizienz anzustreben, ist es notwendig, sich mit einem anderen zu befassen zusätzliche Quelle der Instabilität. Die Autoren weisen darauf hin, dass die Forschungsgemeinschaft kürzlich auch versucht hat, die Rechenanforderungen der autoregressiven Aufmerksamkeit durch „Sparsity“ (d. h. den Prozess der Begrenzung der Bedeutung, die einigen Eingabeelementen zugewiesen wird) zu reduzieren.
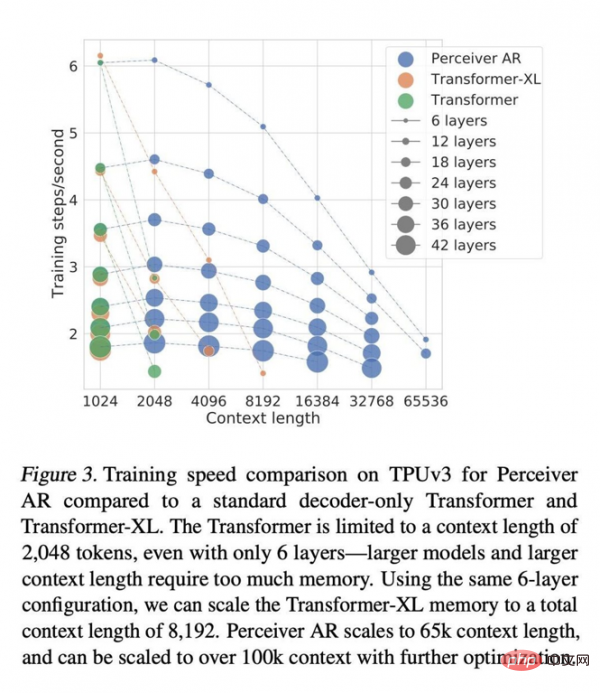
Im gleichen Zeittakt ist Perceiver AR in der Lage, mehr Symbole aus der Eingabe mit der gleichen Anzahl an Ebenen auszuführen oder die Berechnungszeit mit der gleichen Anzahl an Eingabesymbolen deutlich zu verkürzen. Die Autoren glauben, dass diese hervorragende Flexibilität zu einer allgemeinen Methode zur Effizienzverbesserung für große Netzwerke führen kann.
Aber die Sparsamkeit hat auch ihre eigenen Mängel, der wichtigste ist, dass sie zu starr ist. In dem Artikel heißt es: „Der Nachteil der Verwendung von Sparsity-Methoden besteht darin, dass diese Sparsity durch manuelle Anpassung oder heuristische Methoden erstellt werden muss. Diese Heuristiken sind oft nur auf bestimmte Felder anwendbar und oft schwierig anzupassen.“ Das 2017 veröffentlichte Projekt ist ein spärliches Projekt.
Sie erklären: „Im Gegensatz dazu erfordert unsere Arbeit keine manuelle Erstellung spärlicher Muster auf der Aufmerksamkeitsebene, sondern ermöglicht dem Netzwerk stattdessen, autonom zu lernen, welche Eingaben mit langem Kontext mehr Aufmerksamkeit erfordern und über das Netzwerk verbreitet werden müssen.“
Das Papier fügt außerdem hinzu, dass „die anfängliche Kreuzaufmerksamkeitsoperation die Anzahl der Positionen in der Sequenz verringert und als eine Form des Sparse-Lernens angesehen werden kann“
Die auf diese Weise erlernte Sparsity kann selbst in einer anderen verwendet werden Wir werden in den nächsten Jahren ein leistungsstarkes Werkzeug im Deep-Learning-Modell-Toolkit entwickeln.
Das obige ist der detaillierte Inhalt vonDeepMind sagte: KI-Modelle müssen abnehmen, und Autoregression wird zum Haupttrend. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr