
Heim >Technologie-Peripheriegeräte >KI >Google hat die Parameter des visuellen Übertragungsmodells auf 22 Milliarden erweitert, und seit ChatGPT populär wurde, haben Forscher gemeinsame Maßnahmen ergriffen
Google hat die Parameter des visuellen Übertragungsmodells auf 22 Milliarden erweitert, und seit ChatGPT populär wurde, haben Forscher gemeinsame Maßnahmen ergriffen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-27 11:31:071303Durchsuche
Ähnlich wie bei der Verarbeitung natürlicher Sprache verbessert die Übertragung vorab trainierter visueller Rückgrate die Modellleistung bei verschiedenen visuellen Aufgaben. Größere Datensätze, skalierbare Architekturen und neue Trainingsmethoden haben alle zu Verbesserungen der Modellleistung geführt.
Allerdings bleiben visuelle Modelle immer noch weit hinter Sprachmodellen zurück. Insbesondere verfügt ViT, das bislang größte Vision-Modell, nur über 4B-Parameter, während Sprachmodelle der Einstiegsklasse häufig über 10B-Parameter verfügen, ganz zu schweigen von großen Sprachmodellen mit 540B-Parametern.
Um die Leistungsgrenzen von KI-Modellen zu erkunden, hat Google Research kürzlich eine Studie im CV-Bereich durchgeführt und dabei die Führung bei der Erweiterung der Vision Transformer-Parametergröße auf 22B übernommen , und vorgeschlagenes ViT-22B im Vergleich zum vorherigen ähnlichen Modellparameterwert von 4B, kann man sagen, dass dies das bisher größte dichte ViT-Modell ist.

Papieradresse: https://arxiv.org /pdf/2302.05442.pdf
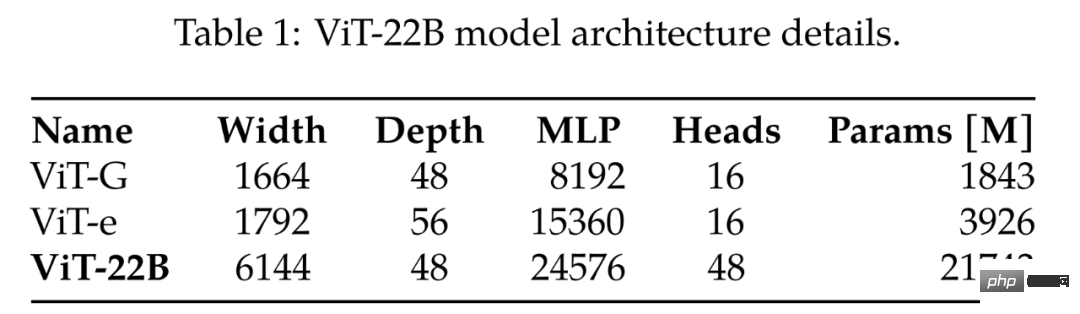
Beim Vergleich der bisher größten ViT-G und ViT-e enthält Tabelle 1 die Vergleichsergebnisse, wie aus ersichtlich ist Die folgende Tabelle: Ja, ViT-22B erweitert hauptsächlich die Breite des Modells, wodurch die Anzahl der Parameter größer und die Tiefe gleich wie bei ViT-G wird. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#aktuelles Vit Big Model#🎜🎜 ## 🎜🎜 ## 🎜 🎜#
Wie dieser Zhihu-Internetnutzer sagte: Liegt es daran, dass Google eine Runde bei ChatGPT verloren hat und zwangsläufig im Lebenslaufbereich mithalten muss? Wie geht das? Es stellte sich heraus, dass sie in den frühen Stadien der Forschung entdeckten, dass es während der Erweiterung von ViT zu Trainingsinstabilitäten kam, die zu architektonischen Änderungen führen könnten. Anschließend entwarfen die Forscher das Modell sorgfältig und trainierten es parallel mit beispielloser Effizienz. Die Qualität von ViT-22B wurde anhand einer umfassenden Reihe von Aufgaben bewertet, von der Klassifizierung (mit wenigen Schüssen) bis hin zu Aufgaben mit dichter Ausgabe, bei denen es die aktuellen SOTA-Werte erreichte oder übertraf. Beispielsweise erreichte ViT-22B auf ImageNet eine Genauigkeit von 89,5 %, selbst wenn es als Extraktor für eingefrorene visuelle Merkmale verwendet wurde. Indem ein Textturm so trainiert wird, dass er diesen visuellen Merkmalen entspricht, wird auf ImageNet eine Nullschussgenauigkeit von 85,9 % erreicht. Darüber hinaus kann das Modell als Lehrer betrachtet und als Destillationsziel verwendet werden. Die Forscher trainierten ein ViT-B-Studentenmodell und erreichten auf ImageNet eine Genauigkeit von 88,6 %, was dem SOTA-Niveau für ein Modell dieser Größenordnung entspricht.
ViT-22B ist ein Transformer-basiertes Encodermodell, ähnlich der ursprünglichen Vision Transformer-Architektur, enthält jedoch die folgenden drei Es wurden zwei wesentliche Änderungen vorgenommen, um die Effizienz und Stabilität beim groß angelegten Training zu verbessern: parallele Schichten, Abfrage-/Schlüssel-Normalisierung (QK) und ausgelassene Verzerrungen.
Parallele Schicht. Wie in der Studie von Wang und Komatsuzaki beschrieben, entwarf diese Studie eine Aufmerksamkeits- und MLP-Parallelstruktur: #Dies kann durch die Kombination von MLP und linearer Projektion von Aufmerksamkeitsblöcken erreicht werden, um eine zusätzliche Parallelisierung zu erreichen. Insbesondere werden die Matrixmultiplikation für die Abfrage-/Schlüssel-/Wertprojektion und die erste lineare Schicht von MLP in einer einzigen Operation verschmolzen, wie dies bei der Projektion außerhalb der Aufmerksamkeit und der zweiten linearen Schicht von MLP der Fall ist.
QK-Normalisierung. Eine Schwierigkeit beim Training großer Modelle ist die Stabilität des Modells. Bei der Erweiterung von ViT stellten Forscher fest, dass der Trainingsverlust nach Tausenden von Schrittrunden abweicht. Dieses Phänomen ist im 8B-Parametermodell besonders ausgeprägt. Um das Modelltraining zu stabilisieren, verwendeten die Forscher die Methode von Gilmer et al., um LayerNorm-Normalisierungsoperationen auf Abfragen und Schlüssel anzuwenden, bevor Punktprodukt-Aufmerksamkeitsberechnungen durchgeführt werden, um die Trainingsstabilität zu verbessern. Konkret wird das Aufmerksamkeitsgewicht wie folgt berechnet:

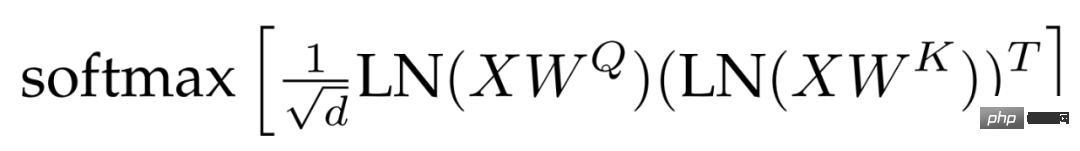
ausgelassene Vorurteile. Nach PaLM wird der Bias-Term aus der QKV-Projektion entfernt und alle Schichtnormen werden ohne Bias angewendet, was zu einer verbesserten Beschleunigerauslastung (3 %) ohne Qualitätsverlust führt. Allerdings verwendeten die Forscher im Gegensatz zu PaLM einen Bias-Term für die dichte MLP-Schicht, und trotzdem ging dieser Ansatz bei gleichzeitiger Berücksichtigung der Qualität nicht zu Lasten der Geschwindigkeit.
Abbildung 2 zeigt einen ViT-22B-Encoderblock. Die Einbettungsschicht führt Operationen wie Patch-Extraktion, lineare Projektion und Einbettung hinzugefügter Positionen basierend auf dem ursprünglichen ViT aus. Die Forscher verwendeten Multi-Head-Aufmerksamkeitspooling, um jede Token-Repräsentation in den Köpfen zu aggregieren.

ViT-22B verwendet einen 14 × 14-Patch und die Bildauflösung ist 224 × 224. ViT-22B verwendet eine erlernte eindimensionale Positionseinbettung. Während der Feinabstimmung an hochauflösenden Bildern führten die Forscher eine zweidimensionale Interpolation basierend darauf durch, wo sich die vorab trainierten Positionseinbettungen im Originalbild befanden.
Trainingsinfrastruktur und -effizienz
ViT-22B verwendet die FLAX-Bibliothek, die als JAX implementiert und in Scenic integriert ist. Es nutzt sowohl Modell- als auch Datenparallelität. Insbesondere verwendeten die Forscher die jax.xmap-API, die eine explizite Kontrolle über das Sharding aller Zwischenprodukte (wie Gewichte und Aktivierungen) sowie die Kommunikation zwischen Chips bietet. Die Forscher organisierten die Chips in einem logischen 2D-Gitter der Größe t × k, wobei t die Größe der parallelen Datenachse und k die Größe der Modellachse ist. Dann erfassen k Geräte für jede der t Gruppen den gleichen Bildstapel, wobei jedes Gerät nur 1/k Aktivierungen behält und für die Berechnung von 1/k aller linearen Layer-Ausgaben verantwortlich ist (Details unten).
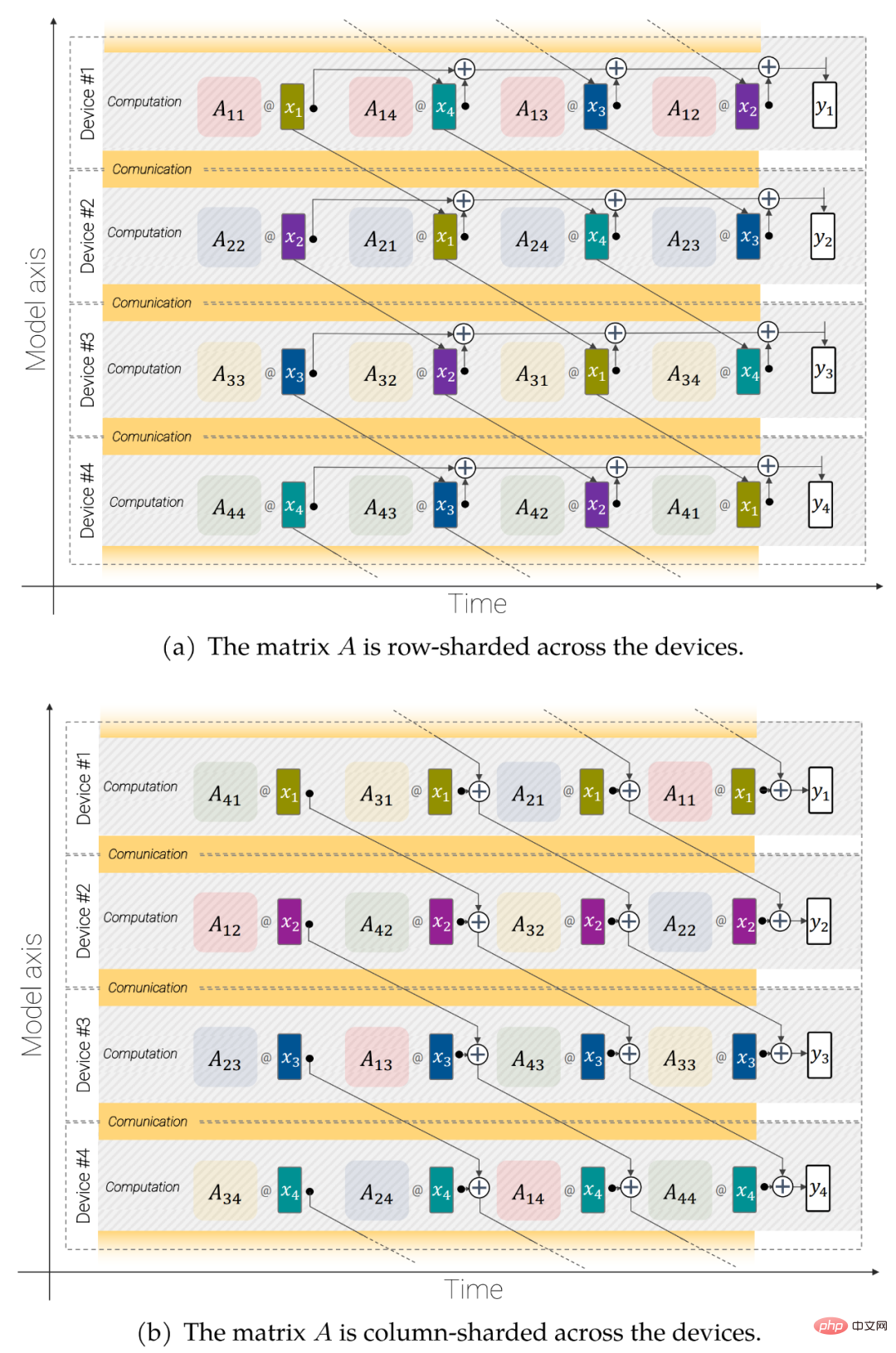
Abbildung 3: Asynchrone parallele lineare Operationen (y = Ax): Modellparallele Matrixmultiplikation für überlappende Kommunikation und Berechnung über Geräte hinweg.
Asynchrone parallele lineare Operationen. Um den Durchsatz zu maximieren, müssen Berechnung und Kommunikation berücksichtigt werden. Das heißt, wenn Sie möchten, dass diese Operationen analytisch äquivalent zum ungeteilten Fall sind, müssen Sie so wenig wie möglich kommunizieren und sie idealerweise überlappen lassen, damit Sie die Matrixmultiplikationseinheit (in der sich der größte Teil der Kapazität des FLOP befindet) erhalten können immer beschäftigt.
Parameter-Sharding. Das Modell ist auf der ersten Achse datenparallel. Jeder Parameter kann vollständig auf dieser Achse repliziert werden, oder jedes Gerät kann mit einem Teil davon gespeichert werden. Die Forscher entschieden sich dafür, einige große Tensoren von den Modellparametern abzutrennen, um größere Modelle und Chargengrößen anpassen zu können.
Mit diesen Techniken verarbeitet ViT-22B während des Trainings auf TPUv4 1,15.000 Token pro Sekunde und Kern. Die Modell-Flop-Auslastung (MFU) von ViT-22B beträgt 54,9 %, was auf eine sehr effiziente Nutzung der Hardware hinweist. Beachten Sie, dass PaLM eine MFU von 46,2 % meldet, während die Forscher für ViT-e (nur Datenparallelität) auf derselben Hardware eine MFU von 44,0 % gemessen haben.
Experimentelle Ergebnisse
Das Experiment untersuchte die Bewertungsergebnisse von ViT-22B für die Bildklassifizierung.
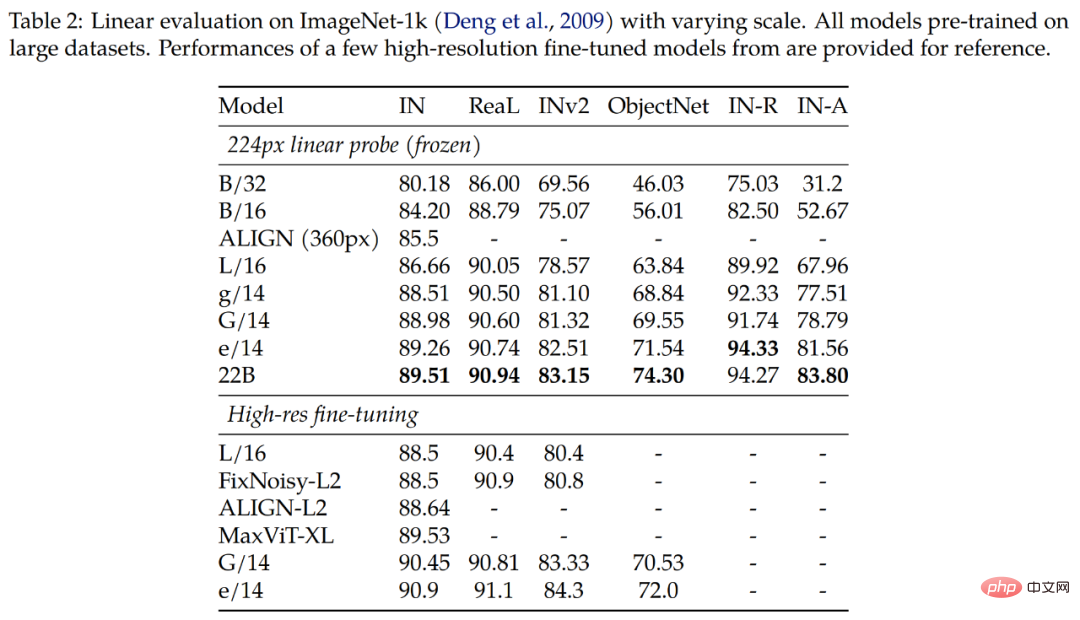
Die Ergebnisse von Tabelle 2 zeigen, dass ViT-22B bei verschiedenen Indikatoren immer noch deutliche Verbesserungen aufweist. Darüber hinaus haben Studien gezeigt, dass die lineare Sondierung großer Modelle wie dem ViT-22B die volle Feinabstimmungsleistung kleinerer Modelle mit hoher Auflösung erreichen oder sogar übertreffen kann, was oft kostengünstiger und einfacher durchzuführen ist.
Die Studie testet außerdem die lineare Machbarkeit des feinkörnigen Klassifizierungsdatensatzes iNaturalist 2017 Trennbarkeit, Vergleich von ViT-22B mit anderen ViT-Varianten. In der Studie wurden Eingabeauflösungen von 224 Pixel und 384 Pixel getestet. Die Ergebnisse sind in Abbildung 4 dargestellt. Die Studie ergab, dass ViT-22B andere ViT-Varianten deutlich übertrifft, insbesondere bei der standardmäßigen Eingabeauflösung von 224 Pixel. Dies zeigt, dass die große Anzahl an Parametern in ViT-22B nützlich ist, um detaillierte Informationen aus Bildern zu extrahieren.
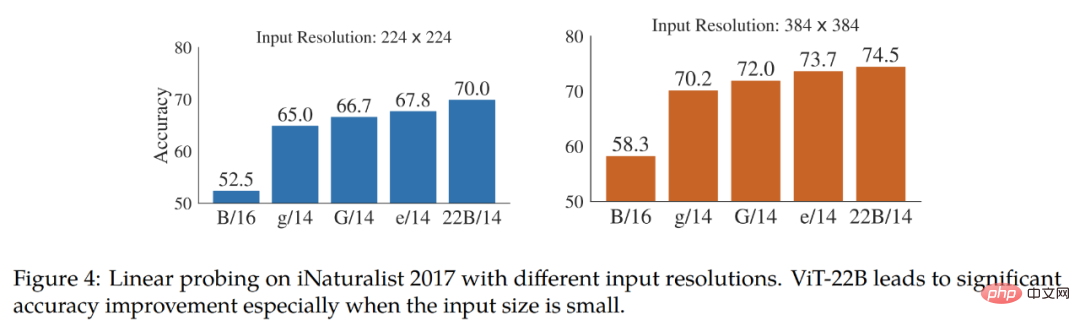
Tabelle 3 zeigt die Nullproben-Migrationsergebnisse von ViT-22B für CLIP-, ALIGN-, BASIC-, CoCa- und LiT-Modelle. Unten in Tabelle 3 werden die Leistungen der drei ViT-Modelle verglichen.
ViT-22B erzielt in allen ImageNet-Testsätzen vergleichbare oder bessere Ergebnisse. Bemerkenswert ist, dass die Zero-Shot-Ergebnisse des ObjectNet-Testsatzes stark mit der ViT-Modellgröße korrelieren. Der größte, ViT-22B, setzt einen neuen Stand der Technik im anspruchsvollen ObjectNet-Testset.

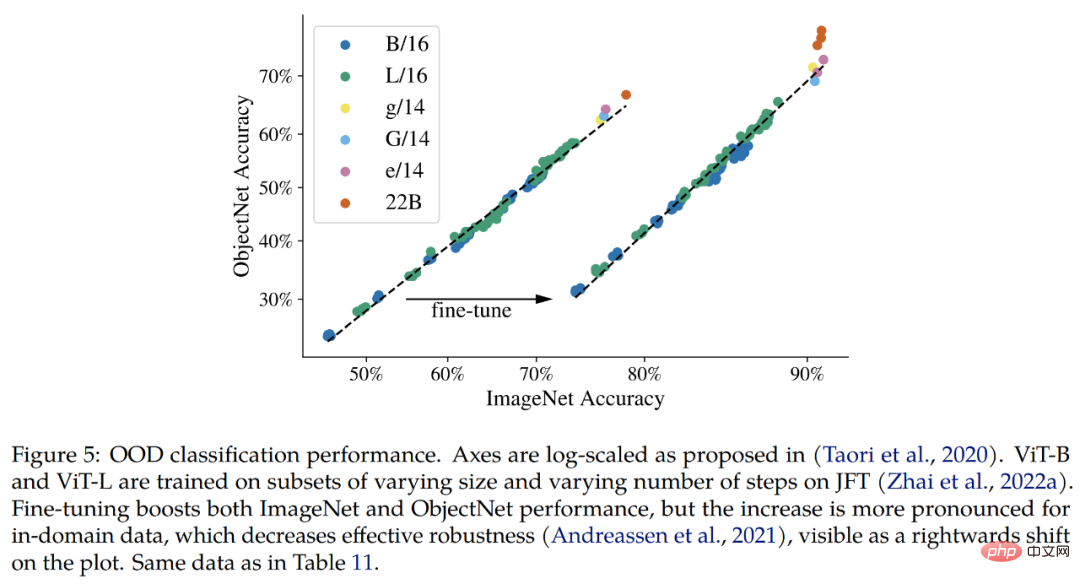
Out-of-distribution (OOD). Die Studie erstellt eine Etikettenzuordnung von JFT zu ImageNet und von ImageNet zu verschiedenen Datensätzen außerhalb der Verteilung, nämlich ObjectNet, ImageNet-v2, ImageNet-R und ImageNet-A.
Die Ergebnisse, die bisher bestätigt werden können, sind, dass das erweiterte Modell im Einklang mit den Verbesserungen bei ImageNet die Out-of-Distribution-Leistung steigert. Dies funktioniert für Modelle, die nur JFT-Bilder gesehen haben, sowie für Modelle, die auf ImageNet feinabgestimmt wurden. In beiden Fällen setzt ViT-22B den Trend einer besseren OOD-Leistung bei größeren Modellen fort (Abb. 5, Tabelle 11).
Darüber hinaus untersuchten die Forscher die Qualität der vom ViT-22B-Modell erfassten geometrischen und räumlichen Informationen bei semantischen Segmentierungs- und monokularen Tiefenschätzungsaufgaben.
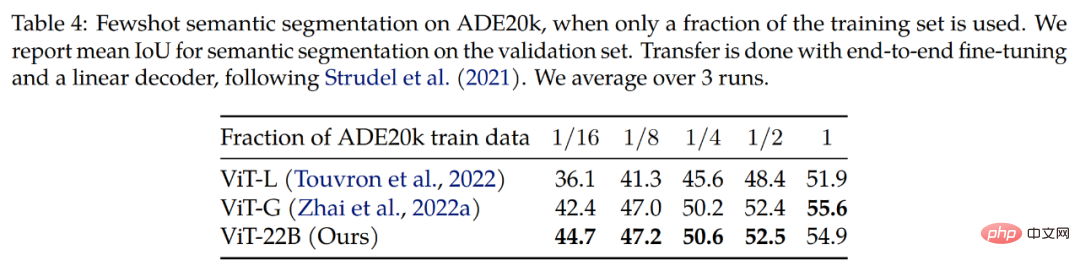
Semantische Segmentierung. Die Forscher bewerteten ViT-22B als Rückgrat der semantischen Segmentierung anhand von drei Benchmarks: ADE20K, Pascal Context und Pascal VOC. Wie aus Tabelle 4 ersichtlich ist, funktioniert die ViT-22B-Backbone-Migration besser, wenn nur wenige Segmentierungsmasken sichtbar sind.
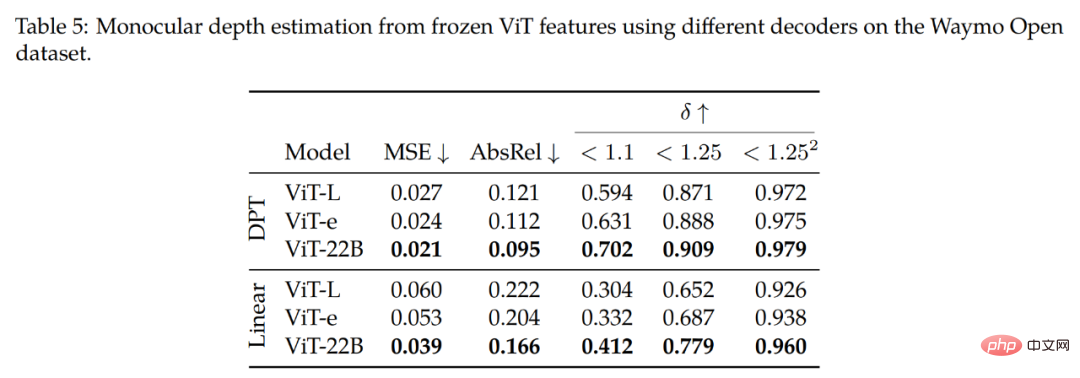
Monokulare Tiefenschätzung. Tabelle 5 fasst die wichtigsten Ergebnisse der Studie zusammen. Wie aus der oberen Reihe (DPT-Decoder) hervorgeht, erzielt die Verwendung von ViT-22B-Funktionen die beste Leistung (bei allen Metriken) im Vergleich zu anderen Backbones. Beim Vergleich des ViT-22B-Backbones mit ViT-e, einem kleineren Modell, das jedoch auf denselben Daten wie ViT-22B trainiert wurde, stellten wir fest, dass eine Erweiterung der Architektur die Leistung verbessert.
Darüber hinaus wurde beim Vergleich des ViT-e-Backbones mit ViT-L (einer ähnlichen Architektur wie ViT-e, aber mit weniger Daten trainiert) festgestellt, dass diese Verbesserungen auch auf die Erweiterung der Vortrainingsdaten zurückzuführen sind. Diese Ergebnisse legen nahe, dass sowohl größere Modelle als auch größere Datensätze zur Leistungsverbesserung beitragen.
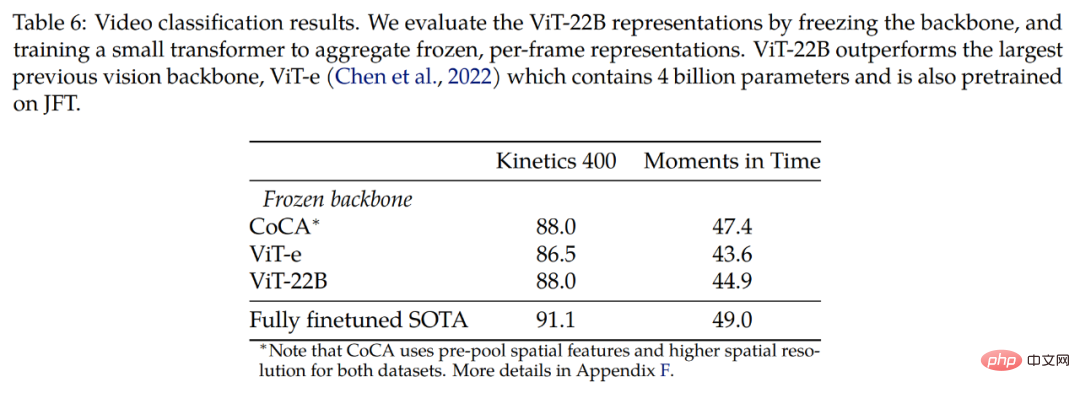
Die Studie wurde auch anhand eines Videodatensatzes untersucht. Tabelle 6 zeigt Videoklassifizierungsergebnisse für die Kinetics 400- und Moments in Time-Datensätze und zeigt, dass mit eingefrorenen Backbones wettbewerbsfähige Ergebnisse erzielt werden können. Die Studie vergleicht zunächst mit ViT-e, das über das größte bisherige visuelle Backbone-Modell verfügt, bestehend aus 4 Milliarden Parametern, und auch auf dem JFT-Datensatz trainiert wird. Wir beobachteten eine Verbesserung um 1,5 Punkte bei Kinetics 400 und 1,3 Punkte bei Moments in Time für das größere ViT-22B-Modell.
Abschließende Untersuchungen ergaben, dass es Raum für weitere Verbesserungen mit einer vollständigen End-to-End-Feinabstimmung gibt.
Weitere technische Details finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonGoogle hat die Parameter des visuellen Übertragungsmodells auf 22 Milliarden erweitert, und seit ChatGPT populär wurde, haben Forscher gemeinsame Maßnahmen ergriffen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr