
Heim >Technologie-Peripheriegeräte >KI >Universeller Fear-Shot-Lerner: eine Lösung für eine Vielzahl dichter Vorhersageaufgaben
Universeller Fear-Shot-Lerner: eine Lösung für eine Vielzahl dichter Vorhersageaufgaben

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-26 22:46:091718Durchsuche
ICLR (International Conference on Learning Representations) gilt als eine der einflussreichsten internationalen akademischen Konferenzen zum Thema maschinelles Lernen.
Auf der diesjährigen ICLR 2023-Konferenz veröffentlichte Microsoft Research Asia die neuesten Forschungsergebnisse in den Bereichen Robustheit des maschinellen Lernens, verantwortungsvolle künstliche Intelligenz und anderen Bereichen.
Unter anderem wurden die Ergebnisse der wissenschaftlichen Forschungskooperation zwischen Microsoft Research Asia und dem Korea Advanced Institute of Science and Technology (KAIST) im Rahmen der akademischen Zusammenarbeit beider Parteien für ihre herausragende Klarheit, Einsicht, Kreativität und Auszeichnung mit dem ICLR 2023 Outstanding ausgezeichnet potenziell nachhaltige Wirkung.

Papieradresse: https://arxiv.org/abs/2303.14969
VTM: Der erste Lernende mit wenigen Stichproben, der an alle dichten Vorhersageaufgaben angepasst ist Wichtige Aufgabenklasse in diesem Bereich, wie semantische Segmentierung, Tiefenschätzung, Kantenerkennung und Schlüsselpunkterkennung usw. Für solche Aufgaben ist die manuelle Annotation von Beschriftungen auf Pixelebene mit unerschwinglich hohen Kosten verbunden. Daher ist die Frage, wie man aus einer kleinen Menge gekennzeichneter Daten lernt und genaue Vorhersagen trifft, d. h. das Lernen kleiner Stichproben, ein Thema von großer Bedeutung in diesem Bereich. In den letzten Jahren hat die Forschung zum Lernen kleiner Stichproben weiterhin Durchbrüche erzielt, insbesondere einige Methoden, die auf Meta-Lernen und kontradiktorischem Lernen basieren und in der akademischen Gemeinschaft große Aufmerksamkeit und Zustimmung gefunden haben.
Bestehende Computer Vision-Lernmethoden für kleine Stichproben zielen jedoch im Allgemeinen auf eine bestimmte Art von Aufgaben ab, z. B. Klassifizierungsaufgaben oder semantische Segmentierungsaufgaben. Beim Entwurf der Modellarchitektur und des Trainingsprozesses nutzen sie häufig Vorkenntnisse und spezifische Annahmen für diese Aufgaben und eignen sich daher nicht für die Verallgemeinerung auf Vorhersageaufgaben mit beliebiger Dichte. Forscher von Microsoft Research Asia wollten einer Kernfrage nachgehen: Gibt es einen allgemeinen Few-Shot-Lerner, der dichte Vorhersageaufgaben für beliebige Segmente unsichtbarer Bilder aus einer kleinen Anzahl beschrifteter Bilder lernen kann?
Das Ziel einer dichten Vorhersageaufgabe besteht darin, eine Zuordnung von Eingabebildern zu in Pixeln annotierten Beschriftungen zu lernen, die wie folgt definiert werden kann:
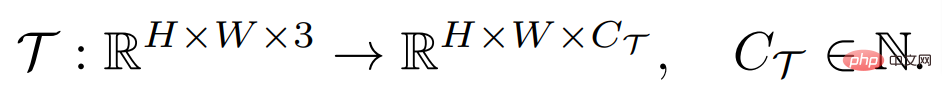 wobei H und B die Höhe und Breite des Bildes sind Das Eingabebild enthält im Allgemeinen drei RGB-Kanäle, und C_Τ stellt die Anzahl der Ausgabekanäle dar. Unterschiedliche dichte Vorhersageaufgaben können unterschiedliche Ausgabekanalnummern und Kanalattribute beinhalten. Beispielsweise ist die Ausgabe einer semantischen Segmentierungsaufgabe ein mehrkanaliger binärer Wert, während die Ausgabe einer Tiefenschätzungsaufgabe ein einkanaliger kontinuierlicher Wert ist. Ein allgemeiner Lernender mit wenigen Stichproben F kann für jede dieser Aufgaben Τ bei gegebener kleiner Anzahl beschrifteter Stichprobenunterstützungssätze S_Τ (einschließlich N Gruppen von Stichproben X^i und Beschriftungen Y^i) lernen, die Bildarchitektur ungesehen abzufragen. Diese Struktur ist in der Lage, beliebig dichte Vorhersageaufgaben zu bewältigen und teilt die Parameter, die für die meisten Aufgaben erforderlich sind, um verallgemeinerbares Wissen zu erhalten, wodurch das Lernen jeder unbekannten Aufgabe mit einer kleinen Anzahl von Stichproben ermöglicht wird.
wobei H und B die Höhe und Breite des Bildes sind Das Eingabebild enthält im Allgemeinen drei RGB-Kanäle, und C_Τ stellt die Anzahl der Ausgabekanäle dar. Unterschiedliche dichte Vorhersageaufgaben können unterschiedliche Ausgabekanalnummern und Kanalattribute beinhalten. Beispielsweise ist die Ausgabe einer semantischen Segmentierungsaufgabe ein mehrkanaliger binärer Wert, während die Ausgabe einer Tiefenschätzungsaufgabe ein einkanaliger kontinuierlicher Wert ist. Ein allgemeiner Lernender mit wenigen Stichproben F kann für jede dieser Aufgaben Τ bei gegebener kleiner Anzahl beschrifteter Stichprobenunterstützungssätze S_Τ (einschließlich N Gruppen von Stichproben X^i und Beschriftungen Y^i) lernen, die Bildarchitektur ungesehen abzufragen. Diese Struktur ist in der Lage, beliebig dichte Vorhersageaufgaben zu bewältigen und teilt die Parameter, die für die meisten Aufgaben erforderlich sind, um verallgemeinerbares Wissen zu erhalten, wodurch das Lernen jeder unbekannten Aufgabe mit einer kleinen Anzahl von Stichproben ermöglicht wird.
Zweitens sollte der Lernende seinen Vorhersagemechanismus flexibel anpassen, um unbekannte Aufgaben mit unterschiedlicher Semantik zu lösen und gleichzeitig effizient genug zu sein, um eine Überanpassung zu verhindern.
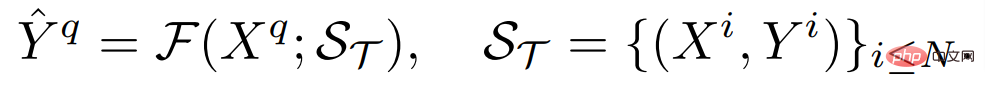
Daher haben Forscher von Microsoft Research Asia das visuelle Token-Matching für Lernende in kleinen Stichproben VTM (Visual Token Matching) entworfen und implementiert, das für jede dichte Vorhersageaufgabe verwendet werden kann. Dies ist der erste Lernende für kleine Stichproben, der an alle intensiven Vorhersageaufgaben angepasst ist. VTM eröffnet eine neue Denkweise für die Verarbeitung intensiver Vorhersageaufgaben und Lernmethoden für kleine Stichproben in der Computer Vision. Diese Arbeit wurde mit dem
ICLR 2023 Outstanding Paper Award- ausgezeichnet.
Das Design von VTM ist von der Analogie zum menschlichen Denkprozess inspiriert: Bei einer kleinen Anzahl von Beispielen einer neuen Aufgabe können Menschen basierend auf der Ähnlichkeit zwischen den Beispielen schnell ähnliche Ausgaben ähnlichen Eingaben zuordnen und auch ähnliche Ausgaben zuweisen auf ähnliche Eingaben basierend auf der Ähnlichkeit zwischen den Beispielen. Der Kontext hängt davon ab, auf welchen Ebenen die Eingabe und die Ausgabe ähnlich sind. Die Forscher implementierten einen Analogieprozess für eine dichte Vorhersage mithilfe eines nichtparametrischen Matchings basierend auf Patch-Levels. Durch Training wird das Modell dazu inspiriert, Ähnlichkeiten in Bildfeldern zu erfassen.
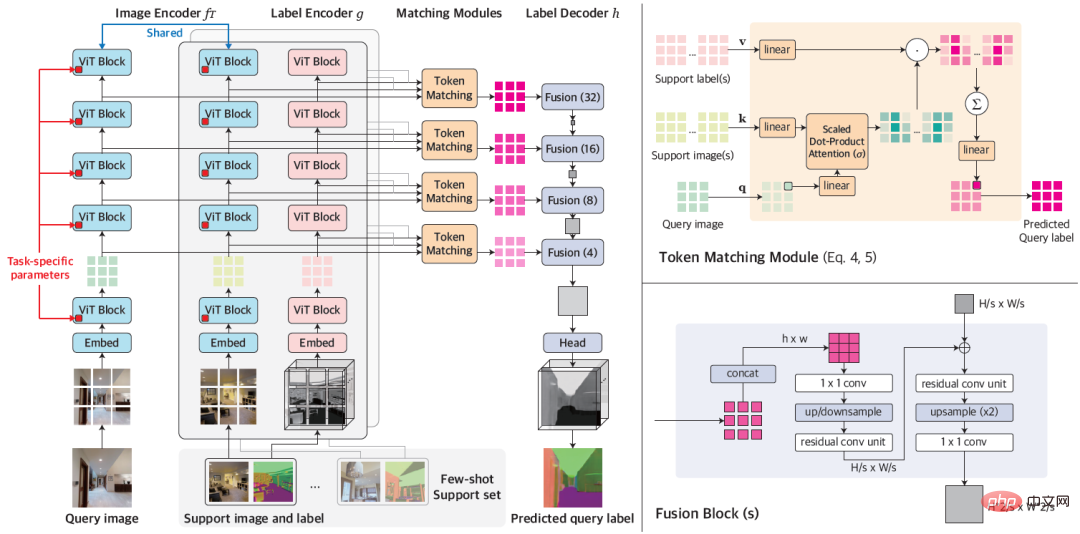
Angesichts einer kleinen Anzahl beschrifteter Beispiele für eine neue Aufgabe passt VTM zunächst sein Verständnis der Ähnlichkeit basierend auf dem gegebenen Beispiel und der Beschriftung des Beispiels an und sperrt Bildfelder von den Beispielbildfeldern, die dem Bild ähnlich sind vorherzusagender Patch: Sagen Sie die Beschriftungen unsichtbarer Bildfelder vorher, indem Sie deren Beschriftungen kombinieren. Abbildung 1: Gesamtarchitektur von VTM Es besteht hauptsächlich aus vier Modulen, nämlich dem Bildkodierer f_Τ, dem Etikettenkodierer g, dem passenden Modul und dem Etikettendekodierer h. Bei einem Abfragebild und einem Supportsatz extrahiert der Bildencoder zunächst Bild-Patch-Level-Darstellungen für jede Abfrage und jedes Supportbild unabhängig voneinander. Der Tag-Encoder extrahiert auf ähnliche Weise jedes Tag, das Tags unterstützt. Angesichts der Beschriftungen auf jeder Ebene führt das Matching-Modul einen nichtparametrischen Abgleich durch und der Label-Decoder leitet schließlich die Beschriftung des Abfragebilds ab.
 Die Essenz von VTM ist eine Meta-Lernmethode. Das Training besteht aus mehreren Episoden, wobei jede Episode ein kleines Beispiel-Lernproblem simuliert. Das VTM-Training verwendet den Meta-Trainingsdatensatz D_train, der eine Vielzahl beschrifteter Beispiele für dichte Vorhersageaufgaben enthält. In jeder Trainingsepisode wird ein Lernszenario mit wenigen Schüssen für eine bestimmte Aufgabe T_train im Datensatz simuliert, mit dem Ziel, angesichts des Unterstützungssatzes die richtige Bezeichnung für das Abfragebild zu erstellen. Durch die Erfahrung des Lernens aus mehreren kleinen Stichproben kann das Modell allgemeines Wissen erlernen, um sich schnell und flexibel an neue Aufgaben anzupassen. Zum Testzeitpunkt muss das Modell für jede Aufgabe T_test, die nicht im Trainingsdatensatz D_train enthalten ist, ein Wenig-Schuss-Lernen durchführen.
Die Essenz von VTM ist eine Meta-Lernmethode. Das Training besteht aus mehreren Episoden, wobei jede Episode ein kleines Beispiel-Lernproblem simuliert. Das VTM-Training verwendet den Meta-Trainingsdatensatz D_train, der eine Vielzahl beschrifteter Beispiele für dichte Vorhersageaufgaben enthält. In jeder Trainingsepisode wird ein Lernszenario mit wenigen Schüssen für eine bestimmte Aufgabe T_train im Datensatz simuliert, mit dem Ziel, angesichts des Unterstützungssatzes die richtige Bezeichnung für das Abfragebild zu erstellen. Durch die Erfahrung des Lernens aus mehreren kleinen Stichproben kann das Modell allgemeines Wissen erlernen, um sich schnell und flexibel an neue Aufgaben anzupassen. Zum Testzeitpunkt muss das Modell für jede Aufgabe T_test, die nicht im Trainingsdatensatz D_train enthalten ist, ein Wenig-Schuss-Lernen durchführen. Da bei der Bearbeitung beliebiger Aufgaben die Ausgabedimension C_Τ jeder Aufgabe beim Metatraining und Testen unterschiedlich ist, wird es zu einer großen Herausforderung, einheitliche allgemeine Modellparameter für alle Aufgaben zu entwerfen. Um eine einfache und allgemeine Lösung bereitzustellen, transformierten die Forscher die Aufgabe in C_Τ-Einzelkanal-Unteraufgaben, lernten jeden Kanal separat und modellierten jede Unteraufgabe unabhängig mithilfe eines gemeinsamen Modells F.
Um VTM zu testen, haben die Forscher außerdem speziell eine Variante des Taskonomy-Datensatzes erstellt, um das Lernen kleiner Stichproben von unsichtbaren dichten Vorhersageaufgaben zu simulieren. Taskonomy enthält eine Vielzahl annotierter Innenbilder, aus denen die Forscher zehn dichte Vorhersageaufgaben mit unterschiedlicher Semantik und Ausgabedimensionen ausgewählt und diese zur Kreuzvalidierung in fünf Teile unterteilt haben. In jeder Aufteilung werden zwei Aufgaben für die Small-Shot-Bewertung (T_test) und die restlichen acht Aufgaben für das Training (T_train) verwendet. Die Forscher haben die Partitionen sorgfältig so konstruiert, dass sich die Trainings- und Testaufgaben ausreichend voneinander unterscheiden, beispielsweise durch die Gruppierung von Randaufgaben (TE, OE) in Testaufgaben, um die Bewertung von Aufgaben mit neuer Semantik zu ermöglichen.
Tabelle 1: Quantitativer Vergleich des Taskonomy-Datensatzes (Few-Shot-Basislinie) Nach Trainingsaufgaben von anderen Partitionen wurde 10-Shot-Lernen für die zu testende Partitionsaufgabe durchgeführt, bei der vollständig überwachte Basislinien trainiert wurden und auf jeder Falte (DPT) oder allen Faltungen (InvPT) ausgewertet
Tabelle 1 und Abbildung 2 veranschaulichen quantitativ und qualitativ die Lernleistung von VTM bei kleinen Stichproben und den beiden Arten von Basismodellen bei jeweils zehn dichten Vorhersageaufgaben. Unter ihnen sind DPT und InvPT die beiden fortschrittlichsten überwachten Lernmethoden, die für jede einzelne Aufgabe unabhängig trainiert werden können, während InvPT alle Aufgaben gemeinsam trainieren kann. Da es vor VTM keine dedizierte Methode für kleine Stichproben gab, die für allgemeine dichte Vorhersageaufgaben entwickelt wurde, verglichen die Forscher VTM mit drei hochmodernen Segmentierungsmethoden für kleine Stichproben, nämlich DGPNet, HSNet und VAT, und erweiterten sie, um allgemeine Aufgaben zu bewältigen Beschriften Sie Räume für dichte Vorhersageaufgaben. VTM hatte während des Trainings keinen Zugriff auf die Testaufgabe T_test und verwendete zum Testzeitpunkt nur eine kleine Anzahl (10) beschrifteter Bilder, schnitt jedoch unter allen Small-Shot-Basismodellen am besten ab und schnitt bei vielen Aufgaben im Vergleich zu vollständig gut ab überwachte Basismodelle.
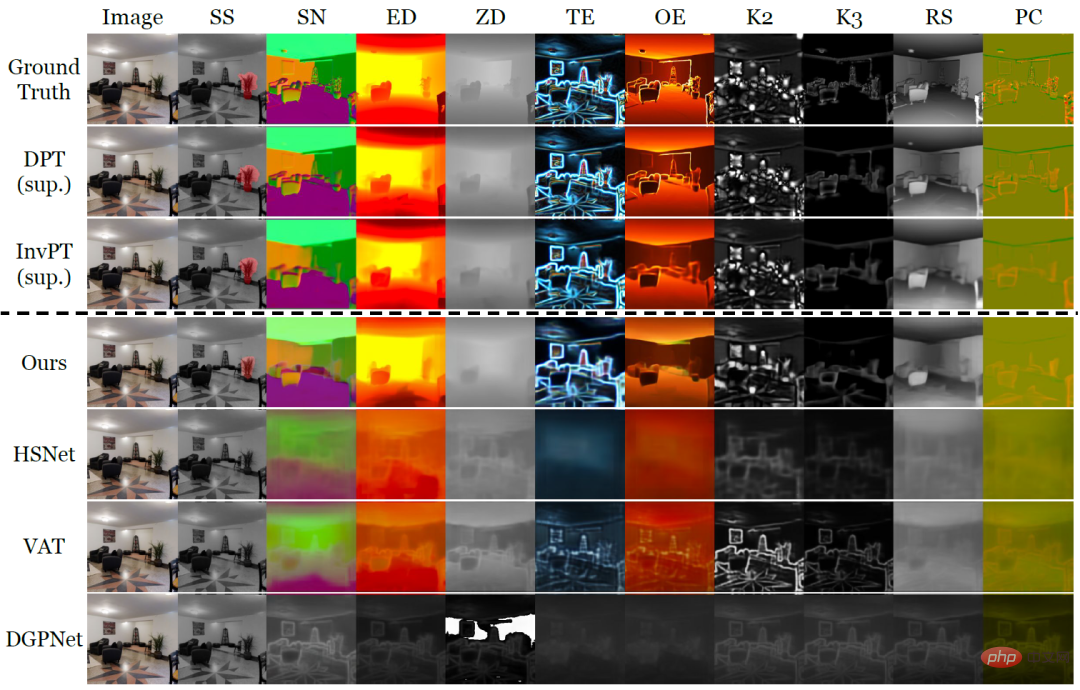
Abbildung 2: Qualitativer Vergleich von Wenig-Schuss-Lernmethoden für eine neue Aufgabe mit nur zehn beschrifteten Bildern für die zehn dichten Vorhersageaufgaben von Taskonomy. Wo andere Methoden scheiterten, erlernte VTM erfolgreich alle neuen Aufgaben mit unterschiedlicher Semantik und unterschiedlichen Beschriftungsdarstellungen.
In Abbildung 2 sind über der gepunkteten Linie die tatsächlichen Beschriftungen und die beiden überwachten Lernmethoden DPT bzw. InvPT dargestellt. Unterhalb der gestrichelten Linie befindet sich die kleine Beispiel-Lernmethode. Bemerkenswerterweise erlitten andere Basislinien mit kleinen Stichproben eine katastrophale Unteranpassung bei neuen Aufgaben, während VTM alle Aufgaben erfolgreich lernte. Experimente zeigen, dass VTM jetzt mit vollständig überwachten Basislinien bei einer sehr kleinen Anzahl gekennzeichneter Beispiele eine ähnlich wettbewerbsfähige Leistung erbringen kann (
Zusammenfassend lässt sich sagen, dass die zugrunde liegende Idee von VTM zwar sehr einfach ist, es aber eine einheitliche Architektur hat, die für beliebig dichte Vorhersageaufgaben verwendet werden kann, da der Matching-Algorithmus im Wesentlichen alle Aufgaben und Labelstrukturen umfasst (z. B. kontinuierlich oder diskret). Darüber hinaus führt VTM nur eine kleine Anzahl aufgabenspezifischer Parameter ein, wodurch es resistent gegen Überanpassung und flexibel ist. In Zukunft hoffen die Forscher, die Auswirkungen von Aufgabentyp, Datenvolumen und Datenverteilung auf die Modellgeneralisierungsleistung während des Pre-Training-Prozesses weiter zu untersuchen und uns so dabei zu helfen, einen wirklich universellen Lernenden für kleine Stichproben zu entwickeln.
Das obige ist der detaillierte Inhalt vonUniverseller Fear-Shot-Lerner: eine Lösung für eine Vielzahl dichter Vorhersageaufgaben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr