
Heim >Technologie-Peripheriegeräte >KI >Das chinesische NUS-Team veröffentlicht das neueste Modell: 3D-Rekonstruktion in Einzelansicht, schnell und genau!
Das chinesische NUS-Team veröffentlicht das neueste Modell: 3D-Rekonstruktion in Einzelansicht, schnell und genau!

- 王林nach vorne
- 2023-04-26 17:37:081063Durchsuche
Die 3D-Rekonstruktion von 2D-Bildern war schon immer ein Highlight im Lebenslaufbereich.
Um dieses Problem zu lösen, wurden verschiedene Modelle entwickelt.
Heute veröffentlichten Wissenschaftler der National University of Singapore gemeinsam einen Artikel und entwickelten ein neues Framework, Anything-3D, um dieses seit langem bestehende Problem zu lösen.

Papieradresse: https://arxiv.org/pdf/2304.10261.pdf
Mit Hilfe des Meta-Modells „Alles teilen“ lässt Anything-3D jedes geteilte Objekt direkt entstehen lebendig .

Darüber hinaus können Sie mit dem Zero-1-to-3-Modell Corgis aus verschiedenen Blickwinkeln betrachten.
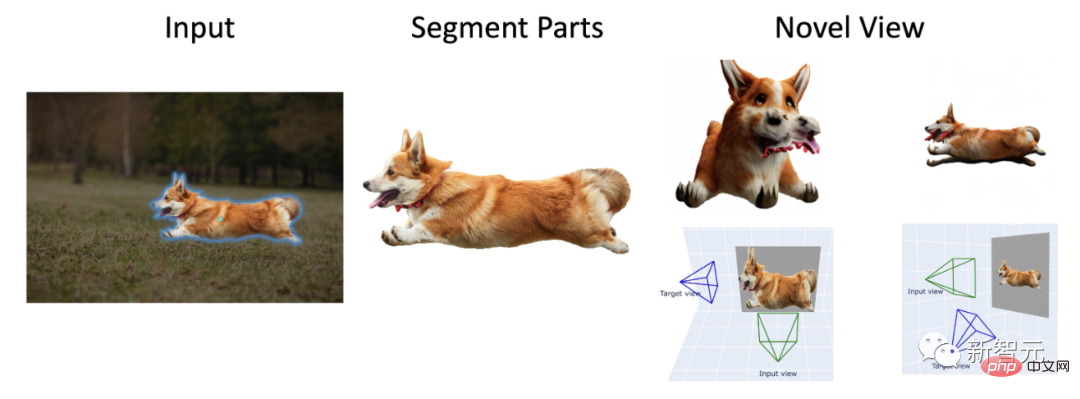
Sie können sogar eine 3D-Rekonstruktion von Charakteren durchführen.

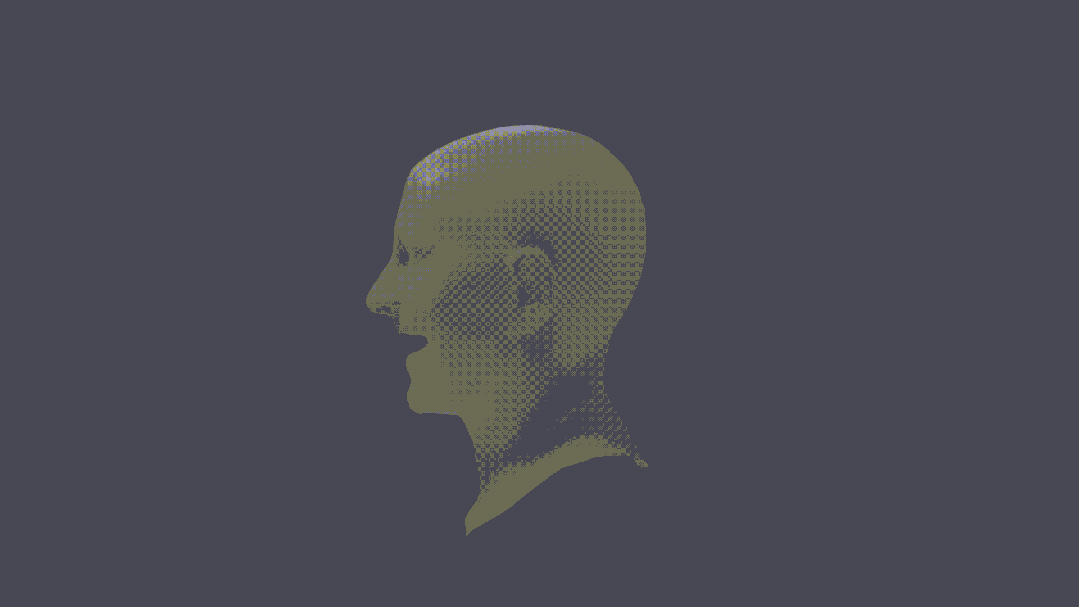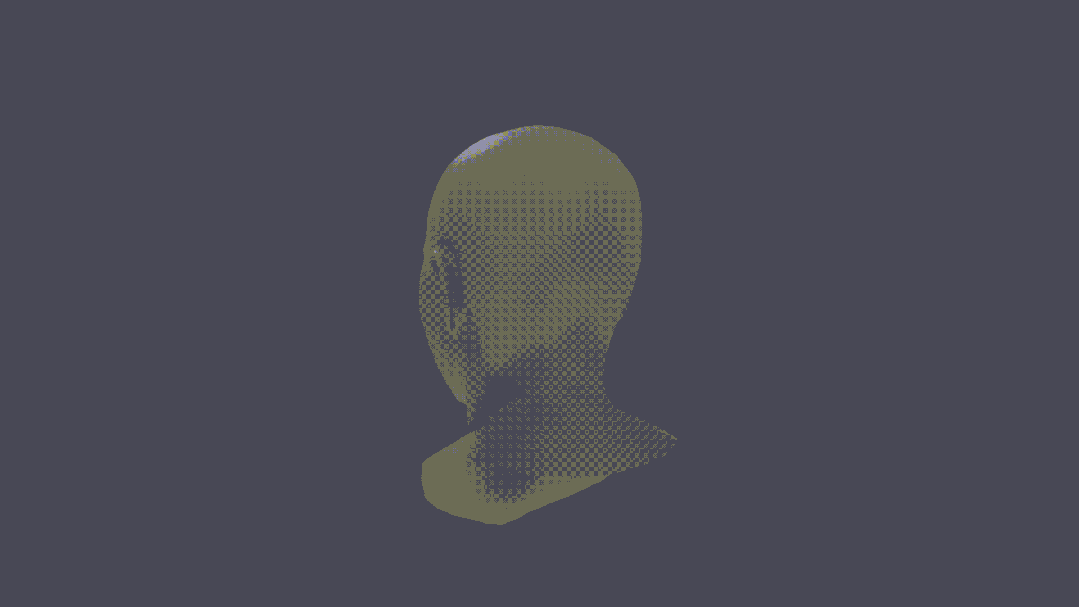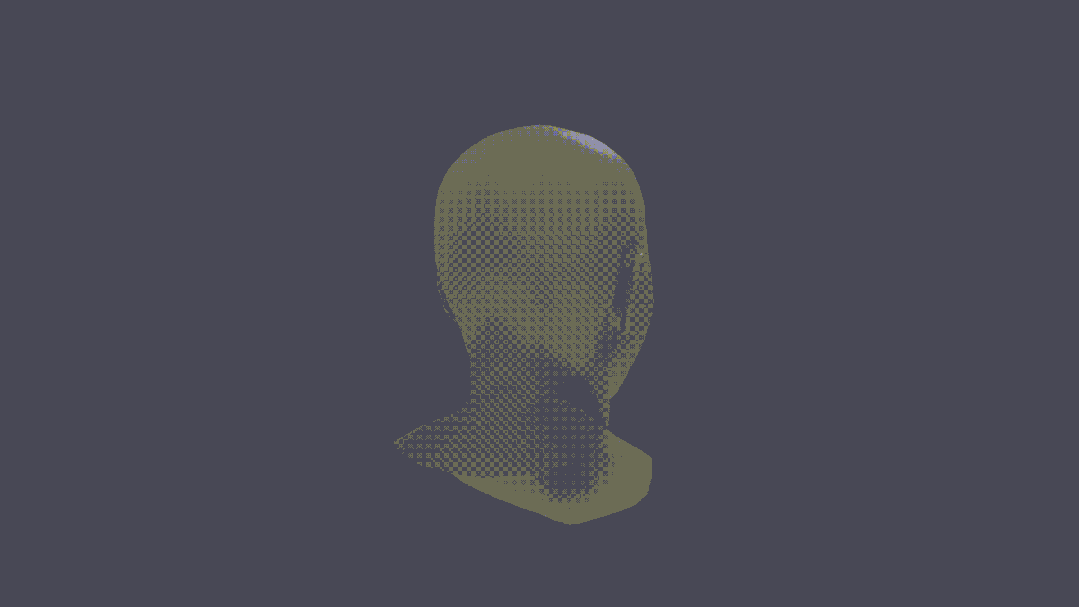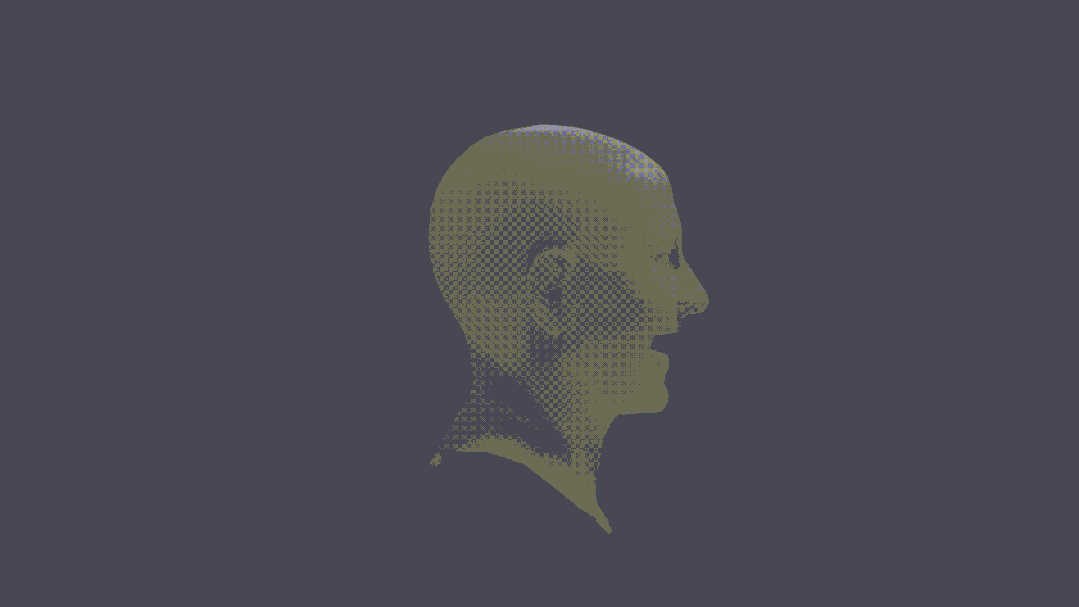
Man kann sagen, dass dies ein echter Durchbruch ist.
Alles – 3D!
In der realen Welt sind verschiedene Objekte und Umgebungen vielfältig und komplex. Daher ist die 3D-Rekonstruktion aus einem einzelnen RGB-Bild ohne Einschränkungen mit vielen Schwierigkeiten verbunden.
Hier kombinierten Forscher der National University of Singapore eine Reihe visueller Sprachmodelle und SAM-Objektsegmentierungsmodelle (Segment-Anything), um ein multifunktionales und zuverlässiges System zu generieren – Anything-3D.
Der Zweck besteht darin, die Aufgabe der 3D-Rekonstruktion aus einer einzigen Perspektive abzuschließen.
Sie verwenden das BLIP-Modell, um Texturbeschreibungen zu generieren, verwenden das SAM-Modell, um Objekte im Bild zu extrahieren, und verwenden dann das Text → Bilddiffusionsmodell Stable Diffusion, um die Objekte in Nerf (neuronales Strahlungsfeld) zu platzieren.
In nachfolgenden Experimenten demonstrierte Anything-3D seine leistungsstarken dreidimensionalen Rekonstruktionsfähigkeiten. Es ist nicht nur genau, sondern auch auf ein breites Anwendungsspektrum anwendbar.
Anything-3D hat offensichtliche Auswirkungen auf die Lösung der Einschränkungen bestehender Methoden. Die Vorteile dieses neuen Rahmenwerks demonstrierten die Forscher durch Tests und Auswertungen verschiedener Datensätze.

Auf dem Bild oben sehen wir den „Corgi, der mit ausgestreckter Zunge Tausende von Kilometern rennt“, „die silberflügelige Göttinnenstatue, die sich einem Luxusauto hingibt“ und die „braune Kuh auf dem Feld“. trägt ein blaues Seil auf dem Kopf.
Dies ist eine vorläufige Demonstration, dass das Anything-3D-Framework in jeder Umgebung aufgenommene Einzelansichtsbilder geschickt in 3D-Formen wiederherstellen und Texturen erzeugen kann.
Dieses neue Framework liefert trotz großer Änderungen in der Kameraperspektive und den Objekteigenschaften immer hochpräzise Ergebnisse.
Sie müssen wissen, dass die Rekonstruktion von 3D-Objekten aus 2D-Bildern das Kernthema im Bereich Computer Vision ist und einen großen Einfluss auf Bereiche wie Robotik, autonomes Fahren, Augmented Reality, Virtual Reality und 3D-Druck hat.
Obwohl in den letzten Jahren einige gute Fortschritte erzielt wurden, ist die Aufgabe der Einzelbild-Objektrekonstruktion in einer unstrukturierten Umgebung immer noch ein sehr attraktives und dringend zu lösendes Problem.
Derzeit haben Forscher die Aufgabe, aus einem einzigen zweidimensionalen Bild eine dreidimensionale Darstellung eines oder mehrerer Objekte zu generieren. Die Darstellungsmethoden umfassen Punktwolken, Gitter oder Volumendarstellungen.
Dieses Problem ist jedoch grundsätzlich nicht wahr.
Aufgrund der inhärenten Mehrdeutigkeit, die durch die zweidimensionale Projektion entsteht, ist es unmöglich, die dreidimensionale Struktur eines Objekts eindeutig zu bestimmen.
Gepaart mit den enormen Unterschieden in Form, Größe, Textur und Aussehen ist die Rekonstruktion von Objekten in ihrer natürlichen Umgebung sehr komplex. Darüber hinaus sind Objekte in realen Bildern häufig verdeckt, was eine genaue Rekonstruktion verdeckter Teile erschwert.
Gleichzeitig können auch Variablen wie Beleuchtung und Schatten das Erscheinungsbild von Objekten stark beeinflussen, und auch Unterschiede in Winkeln und Abständen können zu erheblichen Veränderungen in 2D-Projektionen führen.
Genug der Schwierigkeiten, es ist Zeit für Anything-3D.
In der Arbeit stellten die Forscher dieses bahnbrechende System-Framework ausführlich vor, das das visuelle Sprachmodell und das Objektsegmentierungsmodell integriert, um 2D-Objekte einfach in 3D umzuwandeln.
Auf diese Weise steht ein System mit leistungsstarken Funktionen und starker Anpassungsfähigkeit zur Verfügung. Einzelansichtsrekonstruktion? Einfach.
Die Forscher sagen, dass es durch die Kombination der beiden Modelle möglich ist, die dreidimensionale Textur und Geometrie eines bestimmten Bildes abzurufen und zu bestimmen.
Anything-3D verwendet das BLIP-Modell (Bootstrapping Language-Image Model), um die Textbeschreibung des Bildes vorab zu trainieren, und verwendet dann das SAM-Modell, um den Verbreitungsbereich des Objekts zu identifizieren.
Als nächstes verwenden Sie die segmentierten Objekte und Textbeschreibungen, um die 3D-Rekonstruktionsaufgabe durchzuführen.
Mit anderen Worten: In diesem Artikel wird ein vorab trainiertes 2D-Text-→Bilddiffusionsmodell verwendet, um eine 3D-Synthese von Bildern durchzuführen. Darüber hinaus nutzten die Forscher die fraktionierte Destillation, um einen Nerf speziell für Bilder zu trainieren.
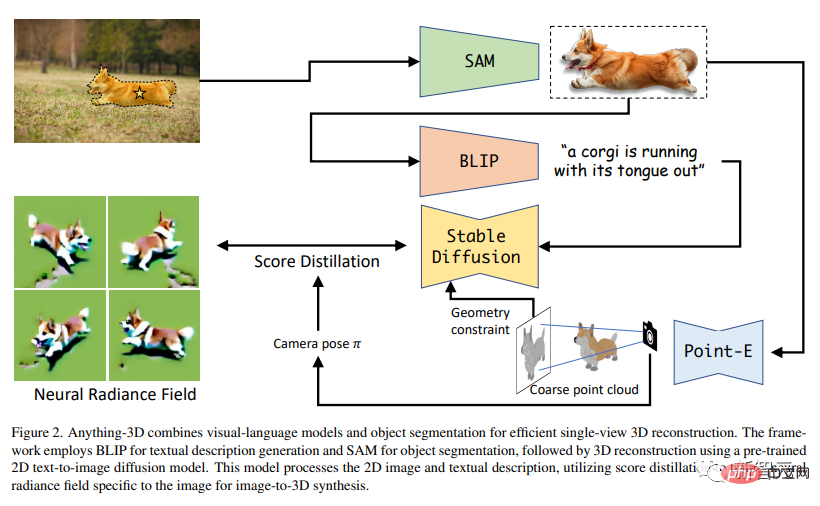
Das obige Bild zeigt den gesamten Prozess der Generierung von 3D-Bildern. Die obere linke Ecke ist das 2D-Originalbild. Es durchläuft zunächst SAM, um den Corgi zu segmentieren, durchläuft dann BLIP, um eine Textbeschreibung zu generieren, und verwendet dann eine fraktionierte Destillation, um einen Nerf zu erstellen.
Durch strenge Experimente mit verschiedenen Datensätzen demonstrierten die Forscher die Wirksamkeit und Anpassungsfähigkeit dieses Ansatzes und übertrafen gleichzeitig bestehende Methoden in Bezug auf Genauigkeit, Robustheit und Generalisierungsfähigkeiten.
Die Forscher führten außerdem eine umfassende und eingehende Analyse bestehender Herausforderungen bei der 3D-Objektrekonstruktion in natürlichen Umgebungen durch und untersuchten, wie das neue Framework solche Probleme lösen kann.
Letztendlich kann das neue Framework durch die Integration der Null-Distanz-Sicht- und Sprachverständnisfunktionen in das Basismodell Objekte aus verschiedenen realen Bildern rekonstruieren und genaue, komplexe und weithin anwendbare 3D-Darstellungen generieren.
Man kann sagen, dass Anything-3D ein großer Durchbruch auf dem Gebiet der 3D-Objektrekonstruktion ist.实 Nachfolgend finden Sie weitere Beispiele:
 cooles schwarzes Interieur von Xiaobai Porsche, leuchtend orangefarbener Baggerkran, grüner Hut, kleine gelbe Gummiente
cooles schwarzes Interieur von Xiaobai Porsche, leuchtend orangefarbener Baggerkran, grüner Hut, kleine gelbe Gummiente
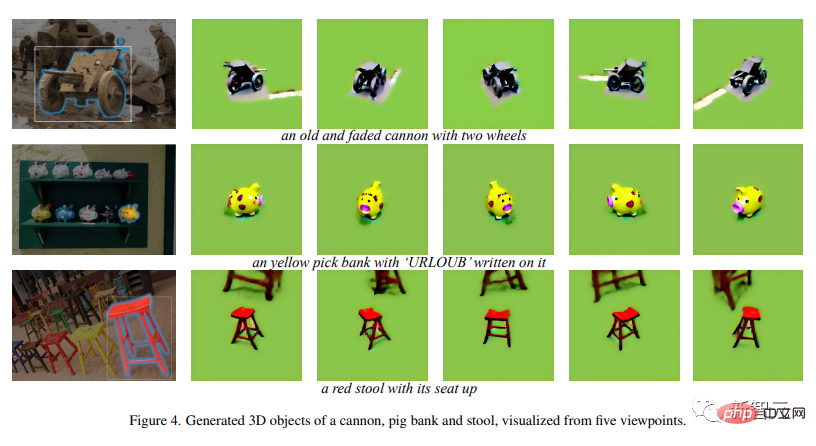 Ära Tränen verblasste Kanone, Schweinchen süßes Mini-Sparschwein , zinnoberroter vierbeiniger Hochhocker
Ära Tränen verblasste Kanone, Schweinchen süßes Mini-Sparschwein , zinnoberroter vierbeiniger Hochhocker
Dieses neue Framework kann interaktiv Regionen in Einzelansichtsbildern identifizieren und 2D-Objekte mit optimierten Texteinbettungen darstellen. Letztendlich wird ein 3D-fähiges fraktioniertes Destillationsmodell verwendet, um effizient hochwertige 3D-Objekte zu generieren.
Zusammenfassend zeigt Anything-3D das Potenzial der Rekonstruktion natürlicher 3D-Objekte aus Einzelansichtsbildern.
Forscher sagen, dass die Qualität der 3D-Rekonstruktion des neuen Frameworks noch perfekter sein kann, und Forscher arbeiten ständig hart daran, die Qualität der Generierung zu verbessern.
Darüber hinaus gaben die Forscher an, dass quantitative Auswertungen von 3D-Datensätzen wie die Synthese neuer Ansichten und die Fehlerrekonstruktion derzeit nicht bereitgestellt werden, diese jedoch in zukünftige Arbeitsiterationen einbezogen werden.
Gleichzeitig besteht das ultimative Ziel der Forscher darin, dieses Framework zu erweitern, um es an praktischere Situationen anzupassen, einschließlich der Objektwiederherstellung unter spärlichen Ansichten.
Über den Autor
Wang ist derzeit Tenure-Track-Assistenzprofessor am ECE-Department der National University of Singapore (NUS).
Bevor er an die National University of Singapore kam, war er Assistenzprofessor in der CS-Abteilung des Stevens Institute of Technology. Bevor ich zu Stevens kam, war ich Postdoc in der Bilderzeugungsgruppe von Professor Thomas Huang am Beckman Institute der University of Illinois in Urbana-Champaign.
Wang promovierte am Computer Vision Laboratory der Ecole Polytechnique Fédérale de Lausanne (EPFL) unter der Leitung von Professor Pascal Fua und erhielt einen erstklassigen Bachelor-Abschluss mit Auszeichnung vom Department of Computer Science des Hong Kong Polytechnic Universität im Jahr 2010.

Das obige ist der detaillierte Inhalt vonDas chinesische NUS-Team veröffentlicht das neueste Modell: 3D-Rekonstruktion in Einzelansicht, schnell und genau!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr