
Heim >Technologie-Peripheriegeräte >KI >Der fein abgestimmte Open-Source-Befehlssatz von Microsoft hilft bei der Entwicklung einer Heimversion von GPT-4, die die zweisprachige Generierung in Chinesisch und Englisch unterstützt.
Der fein abgestimmte Open-Source-Befehlssatz von Microsoft hilft bei der Entwicklung einer Heimversion von GPT-4, die die zweisprachige Generierung in Chinesisch und Englisch unterstützt.

- 王林nach vorne
- 2023-04-26 14:58:091328Durchsuche
„Unterweisung“ ist ein Schlüsselfaktor für den bahnbrechenden Fortschritt des ChatGPT-Modells, der die Ausgabe des Sprachmodells besser an „menschliche Vorlieben“ anpassen kann.
Aber die Annotation von Anweisungen erfordert viel Arbeitskraft. Selbst mit Open-Source-Sprachmodellen ist es für akademische Institutionen und kleine Unternehmen mit unzureichenden Mitteln schwierig, ihr eigenes ChatGPT zu trainieren Die vorgeschlagene Self-Instruct-Technologie
ist der ersteVersuch, das GPT-4-Modell zu verwenden, um automatisch die für das Sprachmodell erforderlichen Feinabstimmungs-Anweisungsdaten zu generieren.
 Papierlink: https://arxiv.org/pdf/2304.03277.pdf
Papierlink: https://arxiv.org/pdf/2304.03277.pdf
Codelink: https://github.com/Instruction-Tuning-with-GPT -4/GPT-4-LLM
Experimentelle Ergebnisse des LLaMA-Modells basierend auf Meta Open Source zeigen, dass die 52.000 von GPT-4 generierten englischen und chinesischen Anweisungen zur Befolgung von Anweisungen in der neuen Aufgabe Zusätzlich zur Anweisung eine bessere Leistung erbrachten Neben Daten, die von früheren hochmodernen Modellen generiert wurden, sammelten die Forscher auch Rückmeldungen und Vergleichsdaten von GPT-4 für eine umfassende Bewertung und Schulung des Belohnungsmodells.
TrainingsdatenDatenerfassung
Die Forscher haben 52.000 Anweisungen des von der Stanford University veröffentlichten Alpaca-Modells wiederverwendet, wobei jede Anweisung die Aufgabe beschreibt, die das Modell ausführen soll, und derselben Aufforderungsstrategie folgt Alpaca betrachtet sowohl Eingabe- als auch Nicht-Eingabesituationen als optionalen Kontext oder Eingabe für die Aufgabe und verwendet ein großes Sprachmodell, um Antworten auf Anweisungen auszugeben.
Im Alpaca-Datensatz wurde die Ausgabe mit GPT-3.5 (text-davinci-003) generiert, in diesem Artikel entschieden sich die Forscher jedoch für die Verwendung von GPT-4 zur Generierung der Daten, insbesondere einschließlich Die folgenden vier Datensätze: 
1. Englische Anweisungsfolgedaten: Für die 52.000 in Alpaca gesammelten Anweisungen wird für jede Anweisung eine englische GPT-4-Antwort bereitgestellt.
Zukünftige Arbeit besteht darin, einem iterativen Prozess zu folgen und mithilfe von GPT-4 einen neuen Datensatz zu erstellen und sich selbst anzuleiten. 
2. Daten zur Befolgung chinesischer Anweisungen: Verwenden Sie ChatGPT, um 52.000 Anweisungen ins Chinesische zu übersetzen, und bitten Sie GPT-4, diese Anweisungen auf Chinesisch zu beantworten, und etablieren Sie so ein auf LLaMA basierendes Modell zur Befolgung chinesischer Anweisungen die sprachübergreifende Generalisierungsfähigkeit der Instruktionsoptimierung.
3. Vergleichsdaten: GPT-4 muss eine Punktzahl von 1 bis 10 für seine eigene Antwort und für die Antworten der drei zu trainierenden Modelle GPT-4, GPT-3.5 und OPT-IML angeben ein Belohnungsmodell.
 4. Antwort auf unnatürliche Anweisungen:
4. Antwort auf unnatürliche Anweisungen:
Statistik
Die Forscher verglichen die englischen Ausgabeantwortsätze von GPT-4 und GPT-3.5: Für jede Ausgabe wurden das Wurzelverb und das Substantiv mit direktem Objekt extrahiert, und für jeden Ausgabesatz wurde die Häufigkeit eindeutiger Verb-Nomen-Paare berechnet. 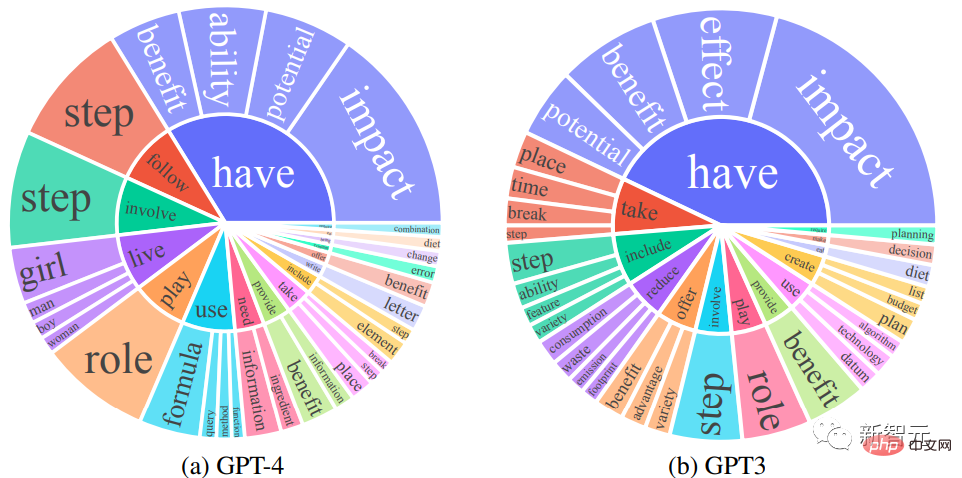
Verb-Nomen-Paare mit einer Häufigkeit von mehr als 10
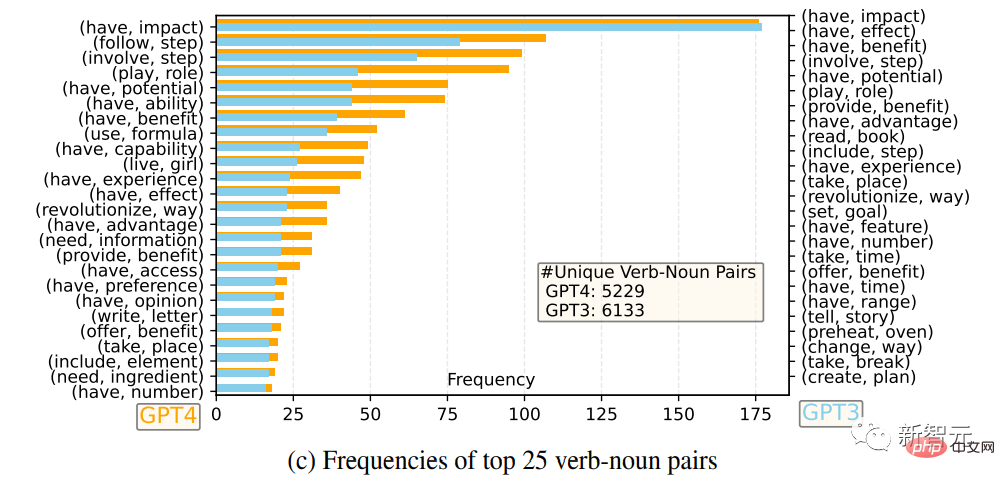
Die 25 häufigsten Verb-Nomen-Paare
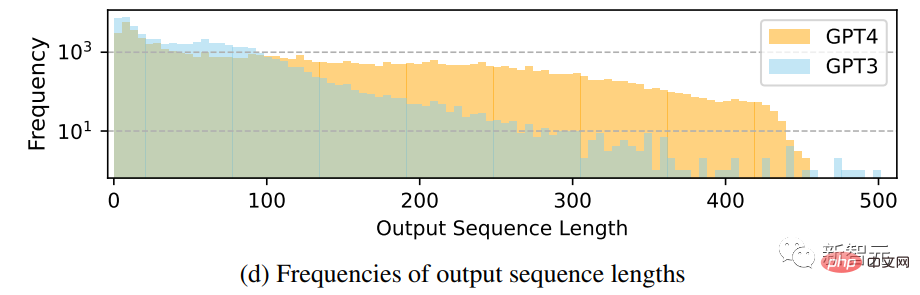
Ausgabe Vergleich der Häufigkeitsverteilung der Sequenzlänge
Es ist ersichtlich, dass GPT-4 tendenziell längere Sequenzen erzeugt als GPT-3.5. Das Long-Tail-Phänomen der GPT-3.5-Daten ist bei Alpaca offensichtlicher als die Ausgabeverteilung von GPT-4. Es kann sein, dass der Alpaca-Datensatz einen iterativen Datenerfassungsprozess beinhaltet, der ähnliche Befehlsinstanzen in jeder Iteration entfernt, was in der aktuellen einmaligen Datengenerierung nicht verfügbar ist.
Obwohl der Prozess einfach ist, weisen die von GPT-4 generierten Befehlsfolgedaten eine leistungsfähigere Ausrichtungsleistung auf.
Instruction Tuning Language Model
Self-Instruct Tuning
Die Forscher erhielten zwei Modelle basierend auf der überwachten Feinabstimmung des LLaMA 7B-Checkpoints: LLaMA-GPT4 wurde in GPT-4 5.2 generiert. Es wurde auf 10.000 trainiert Englische Befehlsfolgedaten; LLaMA-GPT4-CN wurde anhand von 52.000 chinesischen Befehlsfolgedaten von GPT-4 trainiert.
Zwei Modelle wurden verwendet, um die Datenqualität von GPT-4 und die sprachübergreifenden Generalisierungseigenschaften von anweisungsabgestimmten LLMs in einer Sprache zu untersuchen.
Belohnungsmodell
Reinforcement Learning from Human Feedback (RLHF) zielt darauf ab, das LLM-Verhalten mit menschlichen Vorlieben in Einklang zu bringen, sodass die Ausgabe des Sprachmodells für Menschen nützlicher ist.
Eine Schlüsselkomponente von RLHF ist die Belohnungsmodellierung. Das Problem kann als Regressionsaufgabe formuliert werden, um die Belohnungsbewertung anhand einer Eingabeaufforderung und einer Antwort vorherzusagen Vergleichen Sie die Antworten der beiden Modelle.
Bestehende Open-Source-Modelle wie Alpaca, Vicuna und Dolly verwenden RLHF aufgrund der hohen Kosten für die Annotation von Vergleichsdaten nicht, und neuere Untersuchungen zeigen, dass GPT-4 in der Lage ist, seine eigenen Fehler zu identifizieren und zu reparieren Beurteilen Sie die Qualität der Antworten genau.
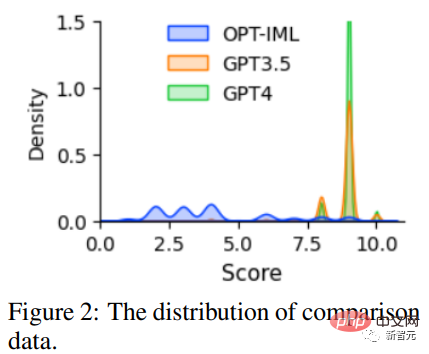
Um die Forschung zu RLHF zu fördern, erstellten Forscher Vergleichsdaten mit GPT-4; zur Bewertung der Datenqualität trainierten Forscher ein Belohnungsmodell basierend auf OPT 1.3B, um verschiedene Antworten zu bewerten. Bewertung: Für eine Eingabeaufforderung und K Antworten liefert GPT-4 für jede Antwort eine Punktzahl zwischen 1 und 10.
Experimentelle Ergebnisse
Die Bewertung der Leistung selbstinstruierender abgestimmter Modelle anhand von GPT-4-Daten für noch nie dagewesene Aufgaben bleibt eine schwierige Aufgabe.
Da das Hauptziel darin besteht, die Fähigkeit des Modells zu bewerten, verschiedene Aufgabenanweisungen zu verstehen und zu befolgen, verwendeten die Forscher zu diesem Zweck drei Arten von Bewertungen und bestätigten dies durch die Ergebnisse der Studie „Mit GPT-4“. zum Generieren von Daten“ im Vergleich zu Es ist eine effektive Methode zum Optimieren großer Sprachmodellanweisungen basierend auf Daten, die automatisch von anderen Maschinen generiert werden.
Menschliche Bewertung
Um die Qualität der Ausrichtung großer Sprachmodelle nach der Optimierung dieser Anweisung zu bewerten, haben die Forscher Befolgen Sie die zuvor vorgeschlagenen Ausrichtungskriterien: Wenn ein Assistent hilfreich, ehrlich und harmlos (HHH) ist, wird er an menschlichen Bewertungskriterien ausgerichtet, die auch häufig zur Bewertung künstlicher Intelligenzsysteme anhand menschlicher Werte verwendet werden.
Hilfsbereitschaft: Ob es Menschen helfen kann, ihre Ziele zu erreichen, ein Modell, das Fragen genau beantworten kann, ist hilfreich.
Ehrlichkeit: Ob wahrheitsgemäße Informationen bereitgestellt und ihre Unsicherheit bei Bedarf zum Ausdruck gebracht werden sollen, um irreführende menschliche Benutzer zu vermeiden. Ein Modell, das falsche Informationen liefert, ist unehrlich.
Harmlosigkeit: Ob es Menschen keinen Schaden zufügt, ein Modell, das Hassreden erzeugt oder Gewalt fördert, ist nicht harmlos. Schädlich.
Basierend auf den HHH-Ausrichtungskriterien nutzten die Forscher die Crowdsourcing-Plattform Amazon Mechanical Turk, um eine manuelle Auswertung der Ergebnisse der Modellgenerierung durchzuführen.
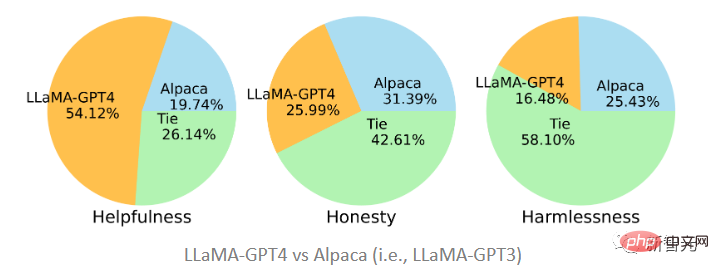
Die beiden im Artikel vorgeschlagenen Modelle sind jeweils in GPT-4 und GPT-3 wurde anhand der generierten Daten verfeinert. Es ist ersichtlich, dass LLaMA-GPT4 mit einem Anteil von 51,2 % deutlich besser ist als Alpaca (19,74 %), das auf GPT-3 verfeinert wurde In Bezug auf Ehrlichkeit und Unbedenklichkeit herrscht im Grunde ein Unentschieden unter dem Standard, und GPT-3 ist etwas besser.
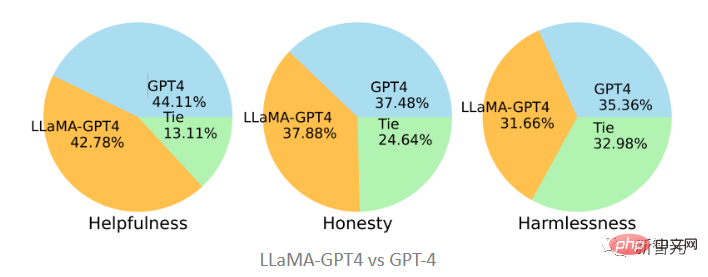
Im Vergleich zum ursprünglichen GPT-4 kann man feststellen, dass Die beiden sind Die drei Standards sind auch recht konsistent, das heißt, die LLaMA-Leistung nach der Optimierung der GPT-4-Anweisungen ähnelt der des ursprünglichen GPT-4.
GPT-4 automatische Auswertung
Inspiriert von Vicuna, The Die Forscher entschieden sich auch für die Verwendung von GPT-4, um die Qualität der von verschiedenen Chatbot-Modellen generierten Antworten auf 80 ungesehene Fragen zu bewerten, indem sie Antworten von LLaMA-GPT-4(7B)- und GPT-4-Modellen sowie von früheren Modellen sammelten. Wir erhielten Antworten von anderen Modellen Anschließend wurde GPT-4 gebeten, die Qualität der Antworten zwischen den beiden Modellen auf einer Skala von 1 bis 10 zu bewerten und die Ergebnisse mit anderen stark konkurrierenden Modellen (ChatGPT und GPT-4) zu vergleichen.
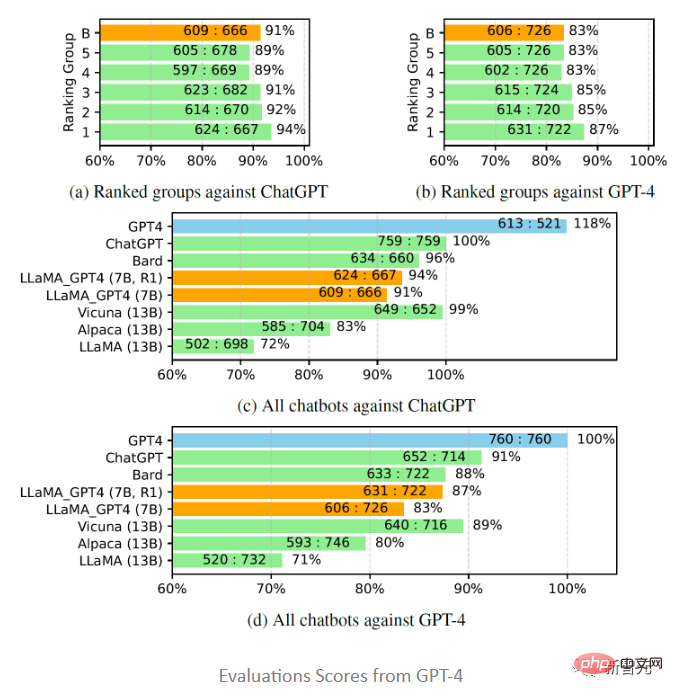
Die Auswertungsergebnisse zeigen, dass Feedbackdaten und Belohnungsmodelle die Leistung verbessern können von LLaMA Es ist effektiv; die Verwendung von GPT-4 zum Optimieren von LLaMA-Anweisungen hat oft eine höhere Leistung als text-davinci-003-Tuning (d. h. Alpaca) und kein Tuning (d. h. LLaMA); die Leistung von 7B LLaMA GPT4 übertrifft 13B Alpaca und LLaMA, aber Im Vergleich zu großen kommerziellen Chatbots wie GPT-4 besteht immer noch eine Lücke. Bei der weiteren Untersuchung der Leistung chinesischer Chatbots wurde zunächst GPT-4 verwendet. Außerdem wurden die Fragen des Chatbots vom Englischen ins Chinesische übersetzt und GPT-4 verwendet, um die Antworten zu erhalten. Dabei konnten zwei interessante Beobachtungen gemacht werden:
# 🎜🎜#1. Es lässt sich feststellen, dass #🎜 die relativen Bewertungsmetriken für 🎜#GPT-4-Bewertungen ziemlich konsistent
sind, sowohl über verschiedene Gegnermodelle (z. B. ChatGPT oder GPT-4) als auch über Sprachen hinweg (d. h. Englisch oder Chinesisch). 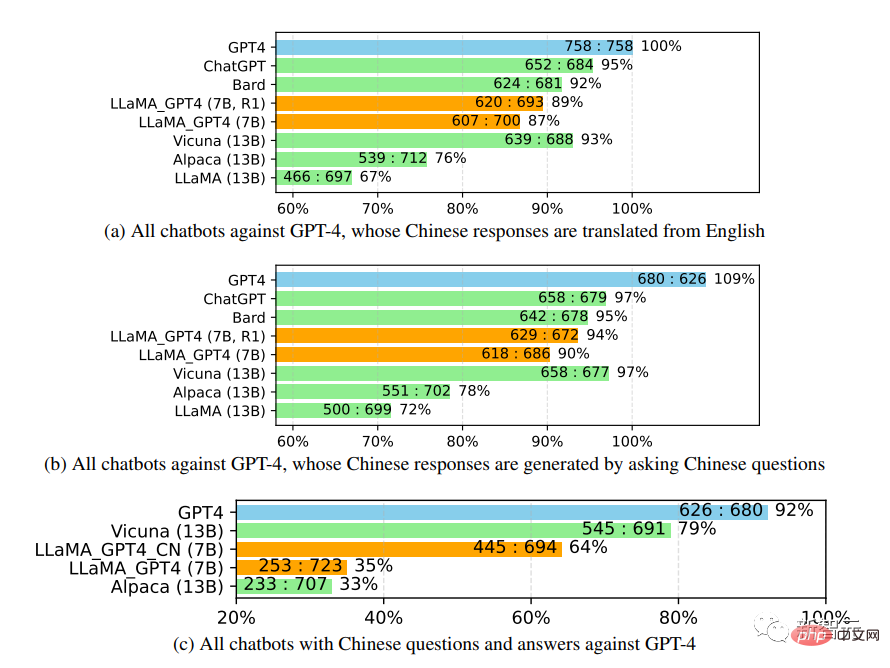
2. Nur im Hinblick auf die Ergebnisse von GPT-4 schnitten die übersetzten Antworten besser ab als die auf Chinesisch generierten Antworten, It Dies kann daran liegen, dass GPT-4 in einem umfangreicheren Englischkorpus als in Chinesisch trainiert wird und daher über bessere Fähigkeiten zur Befolgung von Englischanweisungen verfügt.
Unnatural Instruction Evaluation und GPT4 erzielen mit zunehmender Ground-Truth-Antwortlänge allmählich eine bessere Leistung und zeigen schließlich eine höhere Leistung, wenn die Länge 4 überschreitet, was bedeutet, dass Anweisungen besser befolgt werden können, wenn die Szene kreativer ist.
In verschiedenen Teilmengen ist das Verhalten von LLaMA-GPT4 und GPT-4 nahezu gleich. Wenn die Sequenzlänge kurz ist, können sowohl LLaMA-GPT4 als auch GPT-4 Antworten generieren, die einfache grundlegende Faktenantworten enthalten Zusätzliche Wörter, um Antworten chatähnlicher zu gestalten, können zu einem niedrigeren ROUGE-L-Score führen.
Das obige ist der detaillierte Inhalt vonDer fein abgestimmte Open-Source-Befehlssatz von Microsoft hilft bei der Entwicklung einer Heimversion von GPT-4, die die zweisprachige Generierung in Chinesisch und Englisch unterstützt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr