
Heim >Backend-Entwicklung >Python-Tutorial >Wie erstellt man einen Dokumentenscanner in Python?
Wie erstellt man einen Dokumentenscanner in Python?

- 王林nach vorne
- 2023-04-26 13:10:111818Durchsuche
Übersetzer |. Bugatti
Rezensent |. Vielleicht möchten Sie Dokumente digitalisieren, um physischen Platz zu sparen oder Backups zu erstellen. Auf jeden Fall ist das Schreiben eines Programms zum Konvertieren von Fotos von Papierdokumenten in ein Quasiformat genau das, worin Python gut ist.
Durch die Kombination mehrerer geeigneter Bibliotheken können Sie eine kleine Anwendung zum Digitalisieren von Dokumenten erstellen. Ihr Programm nimmt ein Bild eines physischen Dokuments als Eingabe, wendet verschiedene Bildverarbeitungstechniken darauf an und gibt eine gescannte Version der Eingabe aus.
1. Bereiten Sie die Umgebung vor
Zunächst sollten Sie mit den Grundlagen von Python vertraut sein und auch wissen, wie man die NumPy-Python-Bibliothek verwendet.
Öffnen Sie eine beliebige Python-IDE und erstellen Sie zwei Python-Dateien. Benennen Sie eine main.py und die andere transform.py. Führen Sie dann den folgenden Befehl auf dem Terminal aus, um die erforderlichen Bibliotheken zu installieren.
pip install OpenCV-Python imutils scikit-image NumPy
Sie werden OpenCV-Python verwenden, um eine Bildeingabe zu übernehmen und etwas Bildverarbeitung durchzuführen, Imutils verwenden, um die Größe der Eingabe- und Ausgabebilder zu ändern, und scikit-image verwenden, um die Bilder mit einem Schwellenwert zu versehen. NumPy hilft Ihnen bei Arrays.
 Warten Sie, bis die Installation abgeschlossen ist und die IDE das Projekt-Backbone aktualisiert. Sobald der Backbone-Inhalt aktualisiert ist, können Sie mit der Programmierung beginnen. Der vollständige Quellcode ist im GitHub-Repository zu finden.
Warten Sie, bis die Installation abgeschlossen ist und die IDE das Projekt-Backbone aktualisiert. Sobald der Backbone-Inhalt aktualisiert ist, können Sie mit der Programmierung beginnen. Der vollständige Quellcode ist im GitHub-Repository zu finden.
2. Importieren Sie die installierte Bibliothek.
Öffnen Sie die Datei main.py und importieren Sie die installierte Bibliothek. Dadurch können Sie deren Funktionen bei Bedarf aufrufen und nutzen.
import cv2 import imutils from skimage.filters import threshold_local from transform import perspective_transform
Fehler ignorieren, die von perspective_transform ausgelöst werden. Sobald Sie die Verarbeitung der transform.py-Datei abgeschlossen haben, verschwindet der Fehler.
3. Rufen Sie die Eingabe ab und ändern Sie ihre Größe.
Machen Sie ein klares Bild des Dokuments, das Sie scannen möchten. Stellen Sie sicher, dass alle vier Ecken des Dokuments und seines Inhalts sichtbar sind. Kopieren Sie das Bild in denselben Ordner, in dem die Programmdateien gespeichert sind.
 Übergeben Sie den Eingabebildpfad an OpenCV. Erstellen Sie eine Kopie des Originalbildes, da Sie diese während der Perspektivtransformation benötigen. Teilen Sie die Höhe des Originalbilds durch die Höhe, auf die Sie die Größe ändern möchten. Dadurch bleibt das Seitenverhältnis erhalten. Abschließend wird das angepasste Bild ausgegeben.
Übergeben Sie den Eingabebildpfad an OpenCV. Erstellen Sie eine Kopie des Originalbildes, da Sie diese während der Perspektivtransformation benötigen. Teilen Sie die Höhe des Originalbilds durch die Höhe, auf die Sie die Größe ändern möchten. Dadurch bleibt das Seitenverhältnis erhalten. Abschließend wird das angepasste Bild ausgegeben.
# Passing the image path
original_img = cv2.imread('sample.jpg')
copy = original_img.copy()
# The resized height in hundreds
ratio = original_img.shape[0] / 500.0
img_resize = imutils.resize(original_img, height=500)
# Displaying output
cv2.imshow('Resized image', img_resize)
# Waiting for the user to press any key
cv2.waitKey(0)
Die Ausgabe des obigen Codes ist wie folgt:
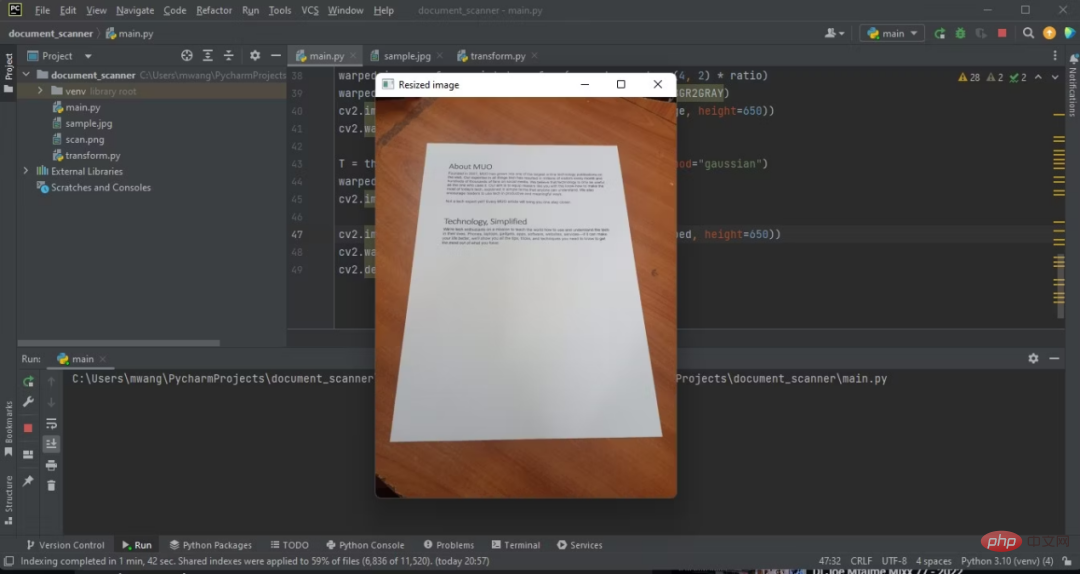 Jetzt haben Sie die Höhe des Originalbilds auf 500 Pixel angepasst.
Jetzt haben Sie die Höhe des Originalbilds auf 500 Pixel angepasst.
4. Konvertieren Sie das angepasste Bild in ein Graustufenbild.
Konvertieren Sie das angepasste RGB-Bild in ein Graustufenbild. Die meisten Bildverarbeitungsbibliotheken verarbeiten nur Graustufenbilder, da diese einfacher zu verarbeiten sind.
gray_image = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayed Image', gray_image)
cv2.waitKey(0)
Beachten Sie den Unterschied zwischen dem Originalbild und dem Graustufenbild.
Programmausgabe mit grauem Bild auf der IDE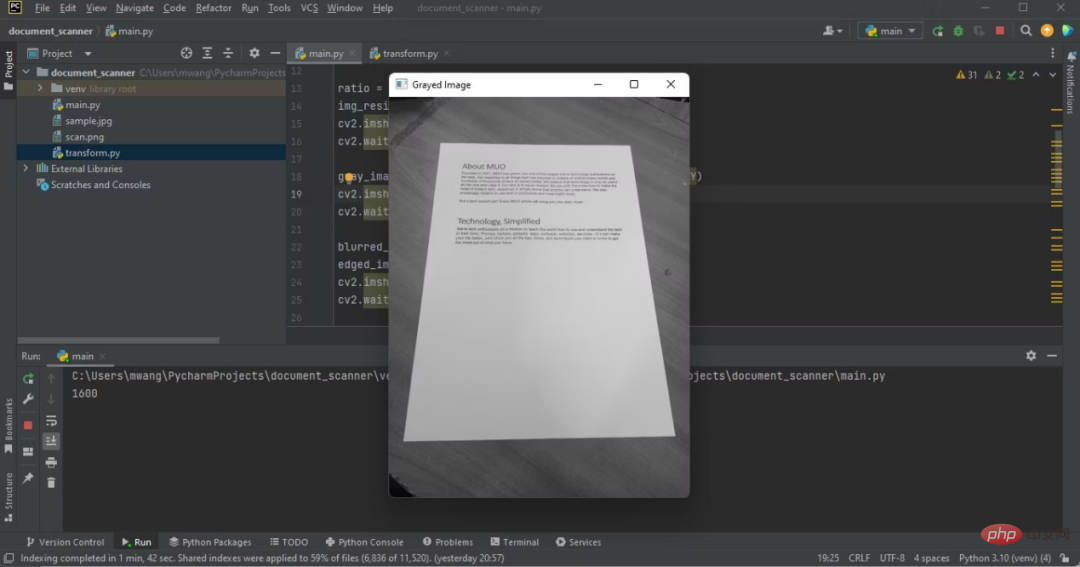
Farbtabelle in Schwarzweißtabelle umgewandelt.
5. Verwenden Sie den Kantendetektor
Wenden Sie den Gaußschen Unschärfefilter auf das Graustufenbild an, um Rauschen zu entfernen. Anschließend wird die OpenCV-Canny-Funktion aufgerufen, um die im Bild vorhandenen Kanten zu erkennen.
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
edged_img = cv2.Canny(blurred_image, 75, 200)
cv2.imshow('Image edges', edged_img)
cv2.waitKey(0)
Kanten sind auf der Ausgabe sichtbar.
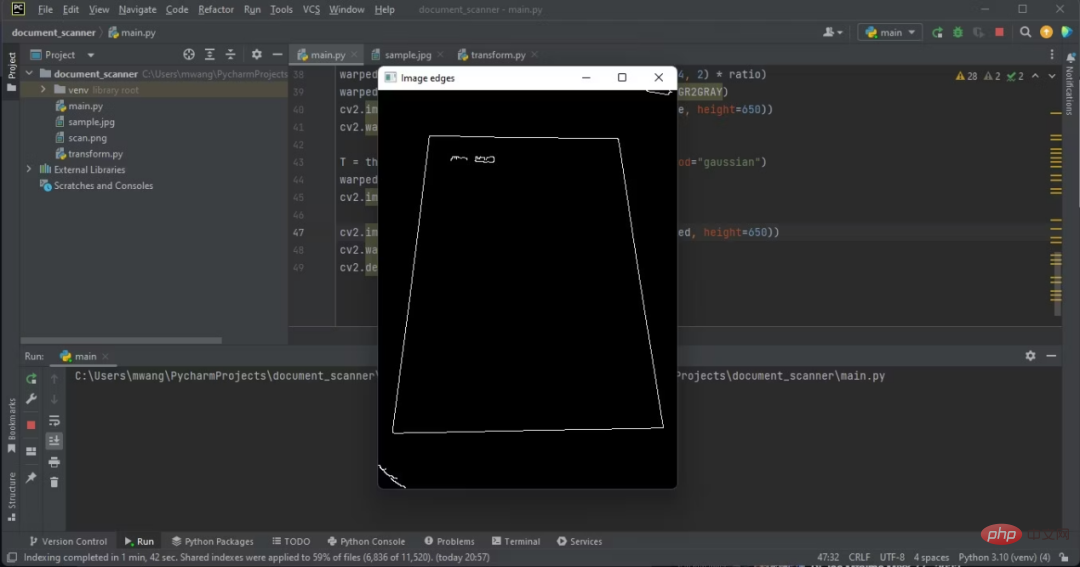 Die Kanten, an denen Sie arbeiten, sind die Kanten des Dokuments.
Die Kanten, an denen Sie arbeiten, sind die Kanten des Dokuments.
6. Finden Sie die größte Kontur
Konturen in Kantenbildern erkennen. Sortieren Sie in absteigender Reihenfolge und behalten Sie nur die fünf größten Konturen bei. Durch zyklisches Sortieren der Konturen wird näherungsweise die größte vierseitige Kontur erhalten.
cnts, _ = cv2.findContours(edged_img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5] for c in cnts: peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.02 * peri, True) if len(approx) == 4: doc = approx break
Eine Silhouette mit vier Seiten enthält wahrscheinlich ein Dokument.
7. Kreisen Sie die vier Ecken des Dokumentumrisses ein.
Kreisen Sie mehrere Ecken des erkannten Dokumentumrisses ein. Dadurch können Sie feststellen, ob Ihr Programm das Dokument im Bild erkennen kann.
p = []
for d in doc:
tuple_point = tuple(d[0])
cv2.circle(img_resize, tuple_point, 3, (0, 0, 255), 4)
p.append(tuple_point)
cv2.imshow('Circled corner points', img_resize)
cv2.waitKey(0)
Kreisen Sie ein paar Ecken des angepassten RGB-Bildes ein.
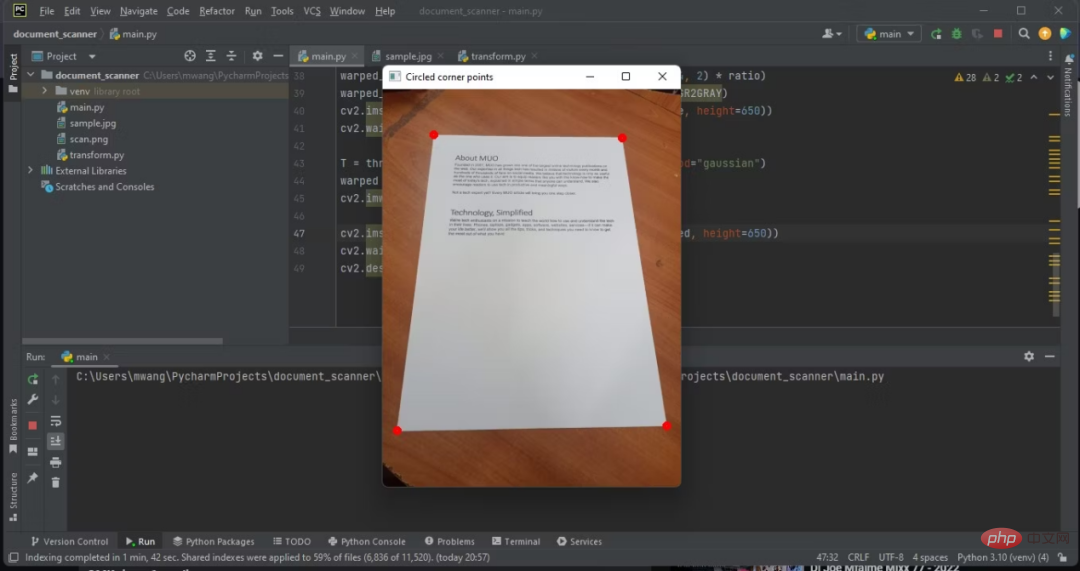 Nachdem Sie das Dokument erkannt haben, müssen Sie es nun aus dem Bild extrahieren.
Nachdem Sie das Dokument erkannt haben, müssen Sie es nun aus dem Bild extrahieren.
8. Verwenden Sie eine verzerrte Perspektive, um das gewünschte Bild zu erhalten.
Die Warp-Perspektive ist eine Computer-Vision-Technik, mit der Bilder transformiert werden, um Verzerrungen zu korrigieren. Dadurch wird das Bild in verschiedene Ebenen umgewandelt, sodass Sie das Bild aus verschiedenen Blickwinkeln betrachten können.
warped_image = perspective_transform(copy, doc.reshape(4, 2) * ratio)
warped_image = cv2.cvtColor(warped_image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Warped Image", imutils.resize(warped_image, height=650))
cv2.waitKey(0)
Um das verzerrte Bild zu erhalten, müssen Sie ein einfaches Modul erstellen, um die Perspektivtransformation durchzuführen.
9. Konvertierungsmodul
该模块将对文档角的点进行排序。它还会将文档图像转换成不同的平面,并将相机角度更改为俯拍。
打开之前创建的那个transform.py文件,导入OpenCV库和NumPy库。
import numpy as np import cv2
这个模块将含有两个函数。创建一个对文档角点的坐标进行排序的函数。第一个坐标将是左上角的坐标,第二个将是右上角的坐标,第三个将是右下角的坐标,第四个将是左下角的坐标。
def order_points(pts): # initializing the list of coordinates to be ordered rect = np.zeros((4, 2), dtype = "float32") s = pts.sum(axis = 1) # top-left point will have the smallest sum rect[0] = pts[np.argmin(s)] # bottom-right point will have the largest sum rect[2] = pts[np.argmax(s)] '''computing the difference between the points, the top-right point will have the smallest difference, whereas the bottom-left will have the largest difference''' diff = np.diff(pts, axis = 1) rect[1] = pts[np.argmin(diff)] rect[3] = pts[np.argmax(diff)] # returns ordered coordinates return rect
创建将计算新图像的角坐标,并获得俯拍的第二个函数。然后,它将计算透视变换矩阵,并返回扭曲的图像。
def perspective_transform(image, pts): # unpack the ordered coordinates individually rect = order_points(pts) (tl, tr, br, bl) = rect '''compute the width of the new image, which will be the maximum distance between bottom-right and bottom-left x-coordinates or the top-right and top-left x-coordinates''' widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) maxWidth = max(int(widthA), int(widthB)) '''compute the height of the new image, which will be the maximum distance between the top-left and bottom-left y-coordinates''' heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) maxHeight = max(int(heightA), int(heightB)) '''construct the set of destination points to obtain an overhead shot''' dst = np.array([ [0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype = "float32") # compute the perspective transform matrix transform_matrix = cv2.getPerspectiveTransform(rect, dst) # Apply the transform matrix warped = cv2.warpPerspective(image, transform_matrix, (maxWidth, maxHeight)) # return the warped image return warped
现在您已创建了转换模块。perspective_transform导入方面的错误现在将消失。
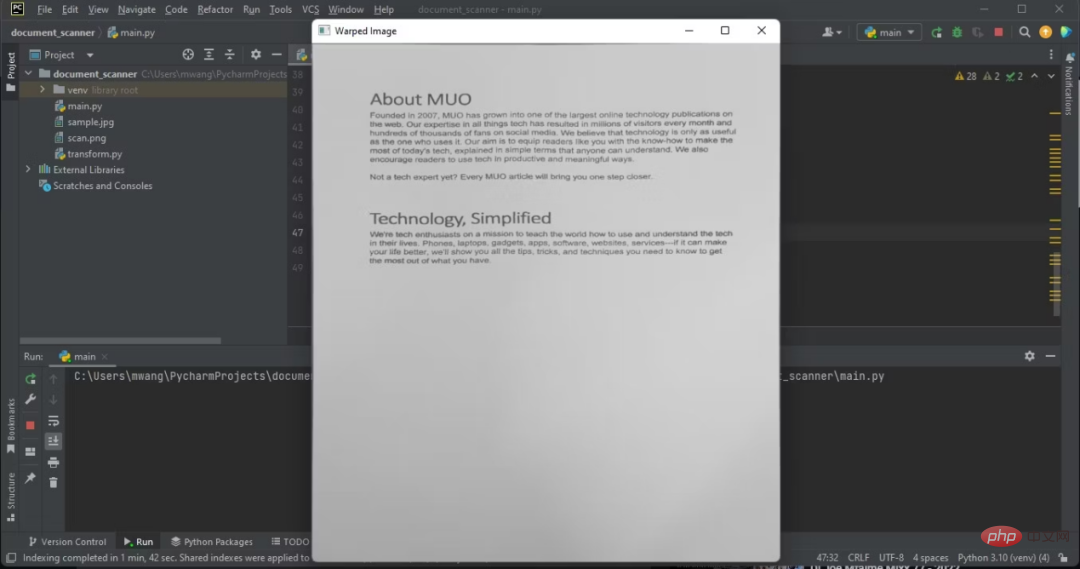
注意,显示的图像有俯拍。
10、运用自适应阈值,保存扫描输出
在main.py文件中,对扭曲的图像运用高斯阈值。这将给扭曲的图像一个扫描后的外观。将扫描后的图像输出保存到含有程序文件的文件夹中。
T = threshold_local(warped_image, 11, offset=10, method="gaussian")
warped = (warped_image > T).astype("uint8") * 255
cv2.imwrite('./'+'scan'+'.png',warped)
以PNG格式保存扫描件可以保持文档质量。
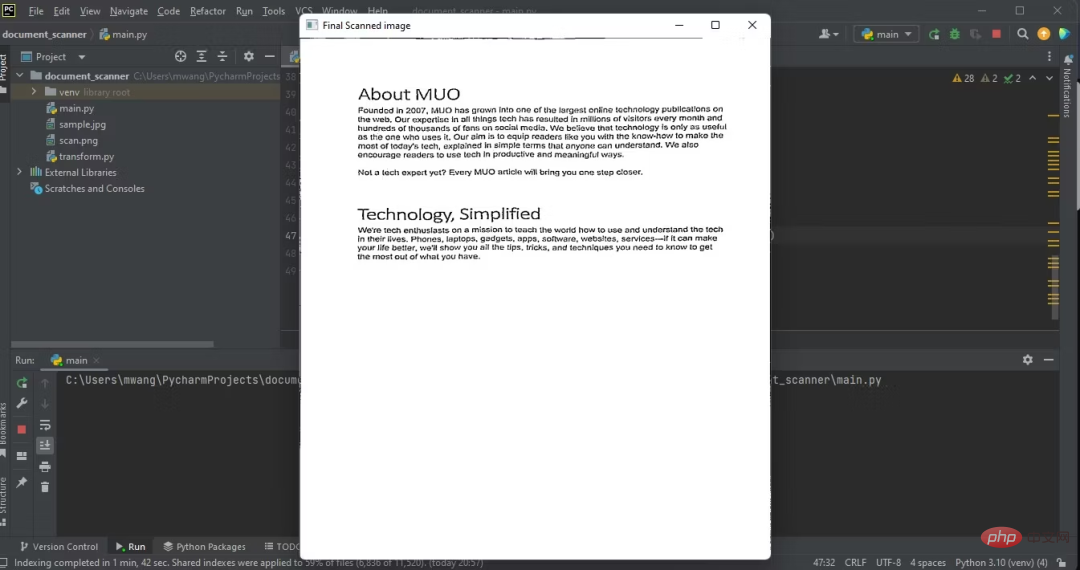
11、显示输出
输出扫描后文档的图像:
cv2.imshow("Final Scanned image", imutils.resize(warped, height=650))
cv2.waitKey(0)
cv2.destroyAllWindows()
下图显示了程序的输出,即扫描后文档的俯拍。
12、计算机视觉在如何进步?
创建文档扫描器涉及计算机视觉的一些核心领域,计算机视觉是一个广泛而复杂的领域。为了在计算机视觉方面取得进步,您应该从事有趣味又有挑战性的项目。
您还应该阅读如何将计算机视觉与当前前技术结合使用方面的更多信息。这让您能了解情况,并为所处理的项目提供新的想法。
原文链接:https://www.makeuseof.com/python-create-document-scanner/
Das obige ist der detaillierte Inhalt vonWie erstellt man einen Dokumentenscanner in Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!