
Heim >Backend-Entwicklung >Python-Tutorial >Teilen Sie gute Beispiele zum Erlernen der Python-Datenvisualisierung!
Teilen Sie gute Beispiele zum Erlernen der Python-Datenvisualisierung!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-25 23:04:051078Durchsuche

Hallo zusammen, ich bin Bruder J. (Buch am Ende des Artikels)
Verwenden Sie Visualisierung, um Diagramme zu erkunden
1. Datenvisualisierung und Erkundungsdiagramme
Unter Datenvisualisierung versteht man die Verwendung von Grafiken oder Tabellen zur Darstellung von Daten. Diagramme können die Art von Daten und die Beziehungen zwischen Daten oder Attributen klar darstellen und so die Interpretation des Diagramms für Benutzer erleichtern. Mithilfe des Exploratory Graph können Benutzer die Eigenschaften der Daten verstehen, Trends in den Daten finden und die Schwelle für das Verständnis der Daten senken.
2. Häufige Diagrammbeispiele
In diesem Kapitel wird hauptsächlich Pandas zum Zeichnen von Grafiken verwendet, anstatt das Matplotlib-Modul zu verwenden. Tatsächlich hat Pandas die Zeichenmethoden von Matplotlib in DataFrame integriert, sodass Benutzer in praktischen Anwendungen Zeichenarbeiten abschließen können, ohne direkt auf Matplotlib zu verweisen.
1. Liniendiagramm
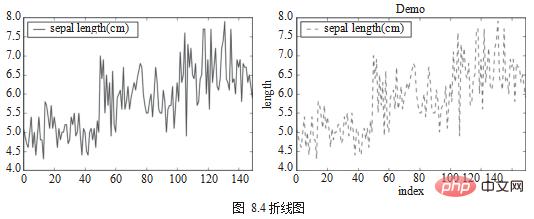
Liniendiagramm ist das einfachste Diagramm, mit dem die Beziehung zwischen kontinuierlichen Daten in verschiedenen Feldern dargestellt werden kann. Die Methode plot.line() wird zum Zeichnen eines Liniendiagramms verwendet und es können Parameter wie Farbe und Form festgelegt werden. In Bezug auf die Verwendung erbt die Methode zum Zeichnen des geteilten Liniendiagramms vollständig die Verwendung von Matplotlib, sodass das Programm am Ende auch plt.show() aufrufen muss, um das Diagramm zu generieren, wie in Abbildung 8.4 dargestellt.
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()
2. Streudiagramm
Streudiagramm wird verwendet, um die Beziehung zwischen diskreten Daten in verschiedenen Feldern anzuzeigen. Streudiagramme werden mit df.plot.scatter() gezeichnet, wie in Abbildung 8.5 dargestellt.
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')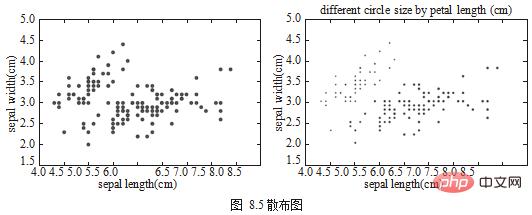
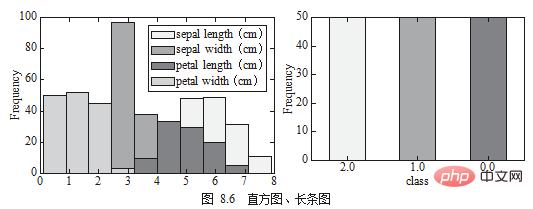
3. Histogrammdiagramm wird normalerweise in derselben Spalte verwendet, um die Verteilung kontinuierlicher Daten anzuzeigen. Ein anderes Diagramm, das dem Histogramm ähnelt, wird zur Anzeige desselben Felds verwendet , wie in Abbildung 8.6 dargestellt.
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()
 4. Kreisdiagramm, Kastendiagramm
4. Kreisdiagramm, Kastendiagramm
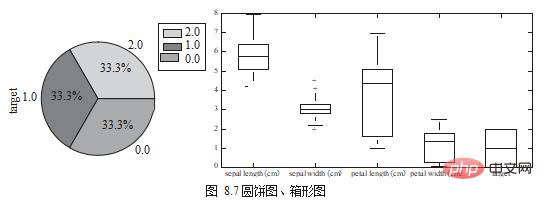
Kreisdiagramm kann verwendet werden, um den Anteil jeder Kategorie in derselben Spalte anzuzeigen, während Kastendiagramm verwendet werden kann, um die Verteilungsunterschiede von Daten im selben Feld zu vergleichen oder in verschiedenen Bereichen, wie in Abbildung 8.7 dargestellt.
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],figsize=(10,5))
 Teilen praktischer Datenexploration
Teilen praktischer Datenexploration
In diesem Abschnitt werden zwei reale Datensätze verwendet, um tatsächlich verschiedene Methoden der Datenexploration zu demonstrieren.
1. American Community Survey 2013
Im Rahmen der American Community Survey werden jedes Jahr etwa 3,5 Millionen Haushalte ausführlich befragt, wer sie sind und wie sie leben. Die Umfrage deckt eine Reihe von Themen ab, darunter Abstammung, Bildung, Arbeit, Transport, Internetnutzung und Wohnort.
Datenquelle: https://www.kaggle.com/census/2013-american-community-survey.
Datenname: American Community Survey 2013.
Beobachten Sie zunächst das Aussehen und die Eigenschaften der Daten sowie die Bedeutung, Art und den Umfang der einzelnen Felder.
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()Verbinden Sie zunächst die beiden ss13pusa.csv. Diese Daten enthalten insgesamt 300.000 Daten mit 3 Feldern: SCHL (Schulniveau), PINCP (Einkommen) und ESR (Arbeitsstatus, Arbeitsstatus).
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)Gruppieren Sie die Daten nach akademischen Qualifikationen, beobachten Sie den Anteil der Zahlen mit unterschiedlichen akademischen Qualifikationen und berechnen Sie dann deren Durchschnittseinkommen.
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())2. Boston House-Datensatz
Der Boston House-Preisdatensatz enthält Informationen über Wohnraum in der Region Boston, einschließlich 506 Datenbeispielen und 13 Merkmalsdimensionen.
Datenquelle: https://archive.ics.uci.edu/ml/machine-learning-databases/housing/.
Datenname: Boston House Price Dataset.
Beobachten Sie zunächst das Aussehen und die Eigenschaften der Daten sowie die Bedeutung, Art und den Umfang der einzelnen Felder.
Die Verteilung der Immobilienpreise (MEDV) kann in Form eines Histogramms dargestellt werden, wie in Abbildung 8.8 dargestellt.
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()
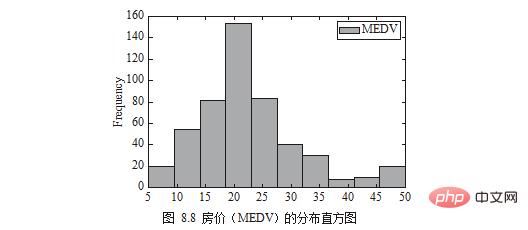 Hinweis: Das Englisch im Bild entspricht den vom Autor im Code oder in den Daten angegebenen Namen. In der Praxis können Leser sie durch die benötigten Wörter ersetzen.
Hinweis: Das Englisch im Bild entspricht den vom Autor im Code oder in den Daten angegebenen Namen. In der Praxis können Leser sie durch die benötigten Wörter ersetzen.
Als nächstes müssen Sie wissen, welche Dimensionen offensichtlich mit „Hauspreisen“ zusammenhängen. Beobachten Sie es zunächst mithilfe eines Streudiagramms, wie in Abbildung 8.9 dargestellt.
# draw scatter chart df.plot.scatter(x='MEDV', y='RM') . plt.show()
最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation corr = df.corr() # drawheatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()
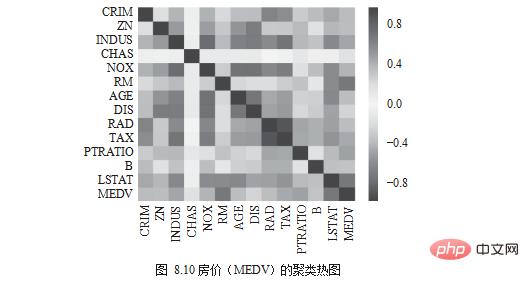
颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
声明:本文选自清华大学出版社的《深入浅出python数据分析》一书,略有修改,经出版社授权刊登于此。
Das obige ist der detaillierte Inhalt vonTeilen Sie gute Beispiele zum Erlernen der Python-Datenvisualisierung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!