
Heim >Technologie-Peripheriegeräte >KI >„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'
„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-24 18:25:091744Durchsuche
Das Folgende ist der Inhalt der Rede von Professor Lu Zhiwu auf der ChatGPT- und Large Model Technology-Konferenz, die von Heart of the Machine abgehalten wurde, ohne die ursprüngliche Bedeutung zu ändern:

Hallo zusammen, ich bin Lu Zhiwu, Renmin University of China. Der Titel meines heutigen Berichts lautet „Wichtige Aufklärungen von ChatGPT zu multimodalen generativen Modellen“ und besteht aus vier Teilen.

Zunächst bringt uns ChatGPT einige Inspirationen zur Innovation von Forschungsparadigmen. Der erste Punkt besteht darin, „Big Model + Big Data“ zu verwenden, ein Forschungsparadigma, das wiederholt verifiziert wurde und auch das grundlegende Forschungsparadigma von ChatGPT darstellt. Es ist besonders wichtig zu betonen, dass ein großes Modell erst dann über neue Fähigkeiten verfügt, wie z. B. kontextbezogenes Lernen, CoT-Argumentation und andere Fähigkeiten. Diese Fähigkeiten sind sehr erstaunlich.
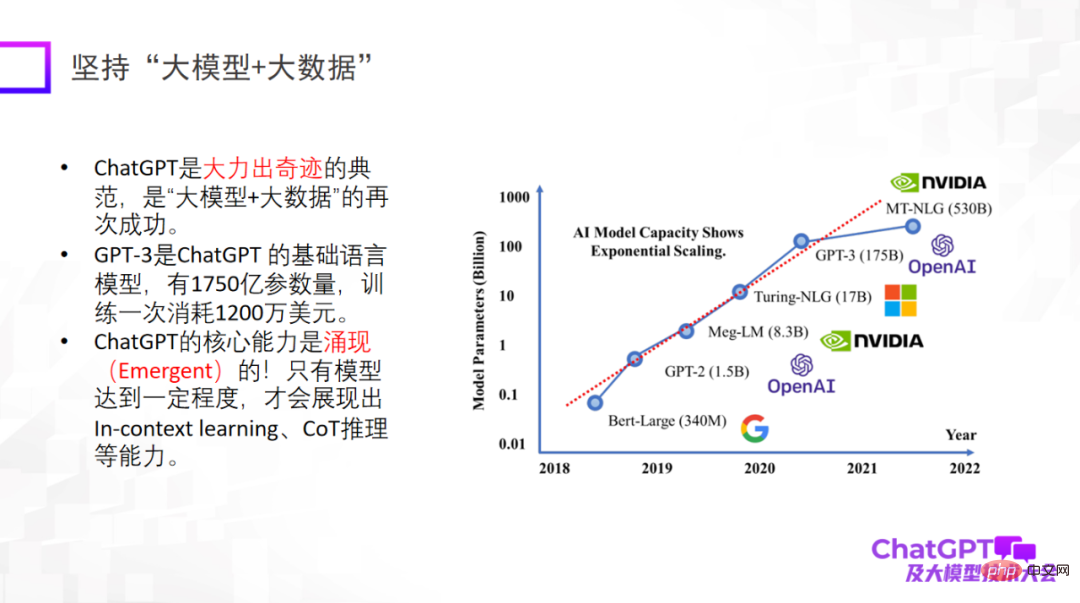
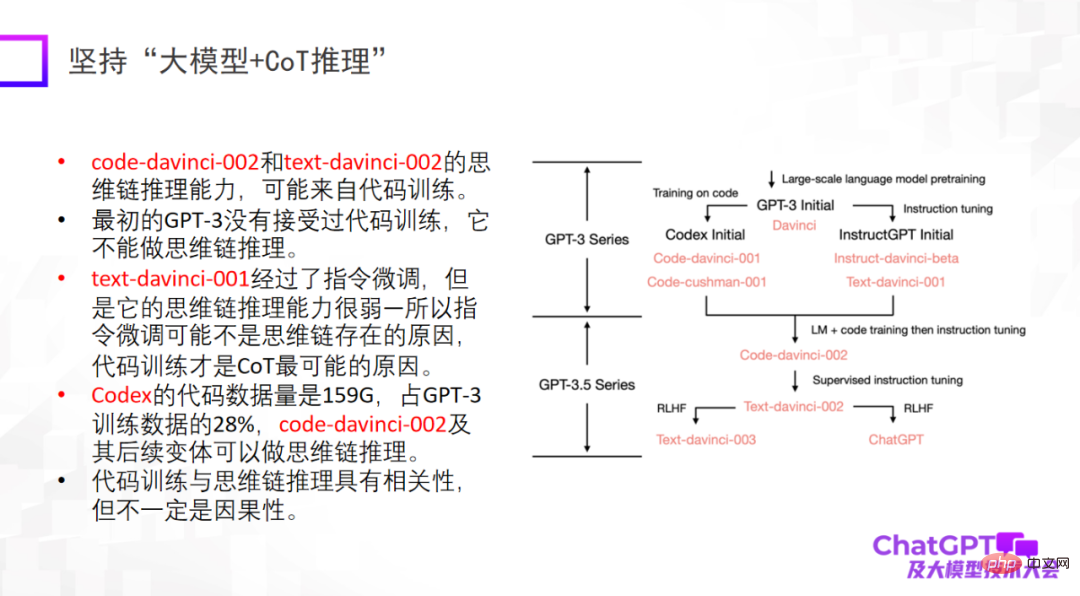
Der zweite Punkt ist, auf „großes Modell + Inferenz“ zu bestehen. Dies ist auch der Punkt, der mich an ChatGPT am meisten beeindruckt hat. Denn im Bereich des maschinellen Lernens oder der künstlichen Intelligenz gilt das Denken als das schwierigste, und auch ChatGPT hat in dieser Hinsicht Durchbrüche erzielt. Natürlich kann die Argumentationsfähigkeit von ChatGPT hauptsächlich aus dem Code-Training stammen, aber ob ein unvermeidlicher Zusammenhang besteht, ist noch nicht sicher. Im Hinblick auf das logische Denken sollten wir uns mehr Mühe geben, herauszufinden, woher es kommt und ob es andere Trainingsmethoden gibt, um das logische Denken weiter zu verbessern.
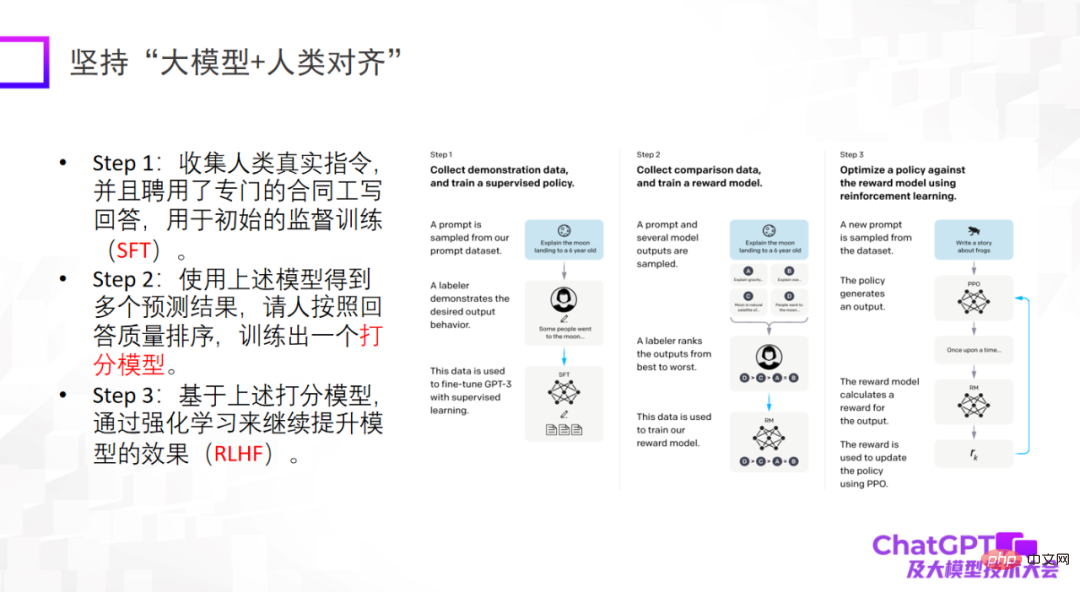
Der dritte Punkt ist, dass große Modelle auf Menschen ausgerichtet sein müssen. Dies ist eine wichtige Offenbarung, die uns ChatGPT aus technischer Sicht oder aus Sicht der Modelllandung gibt. Wenn das Modell nicht auf den Menschen abgestimmt ist, generiert es viele schädliche Informationen, wodurch das Modell unbrauchbar wird. Der dritte Punkt besteht nicht darin, die Obergrenze des Modells anzuheben, aber die Zuverlässigkeit und Sicherheit des Modells sind in der Tat sehr wichtig.
Die Einführung von ChatGPT hatte große Auswirkungen auf viele Bereiche, mich eingeschlossen. Da ich mich seit mehreren Jahren mit Multimodalität beschäftige, werde ich darüber nachdenken, warum wir kein so leistungsstarkes Modell entwickelt haben.
ChatGPT ist eine allgemeine Generierung in Sprache oder Text. Werfen wir einen Blick auf die neuesten Fortschritte im Bereich der multimodalen allgemeinen Generierung. Multimodale Pre-Training-Modelle haben begonnen, sich in multimodale allgemeine generative Modelle umzuwandeln, und es wurden einige vorläufige Untersuchungen durchgeführt. Schauen wir uns zunächst das von Google im Jahr 2019 vorgeschlagene Flamingo-Modell an. Die folgende Abbildung zeigt die Modellstruktur.
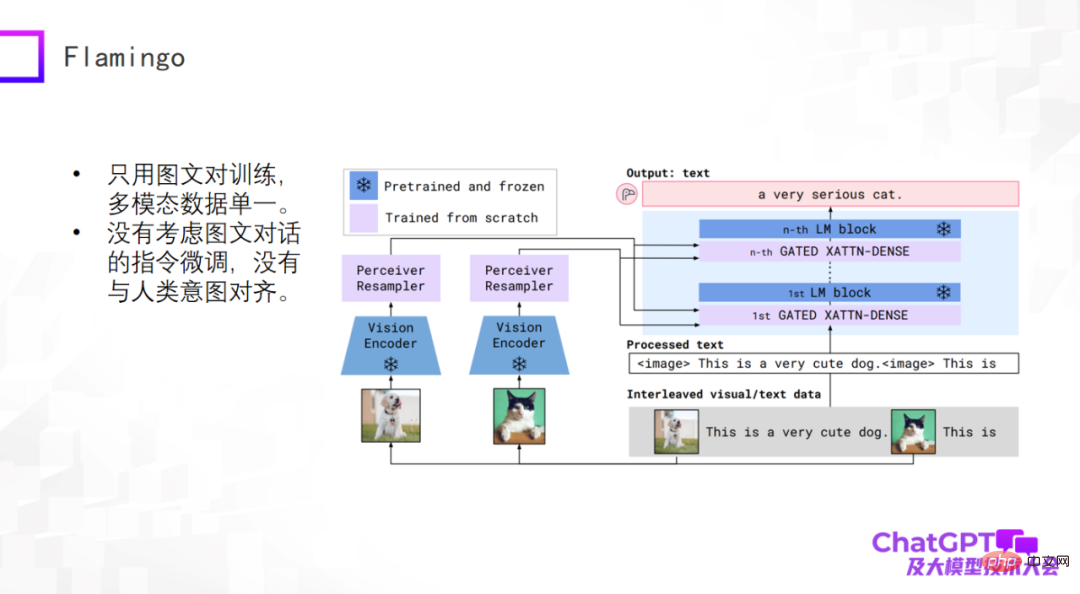
Der Hauptteil der Flamingo-Modellarchitektur ist der Decoder (Decoder) des großen Sprachmodells, bei dem es sich um das blaue Modul auf der rechten Seite des Bildes oben handelt. Zwischen jedem blauen Modul werden einige Adapterschichten hinzugefügt . Der visuelle Teil davon ist die Hinzufügung eines Vision Encoders und eines Perceiver Resamplers. Der Entwurf des gesamten Modells besteht darin, visuelle Dinge zu kodieren und zu konvertieren, den Adapter zu durchlaufen und sie an der Sprache auszurichten, sodass das Modell automatisch Textbeschreibungen für Bilder generieren kann.
Was sind die Vorteile eines architektonischen Entwurfs wie Flamingo? Erstens ist das blaue Modul im obigen Bild fest (eingefroren), einschließlich des Sprachmodell-Decoders, während die Parametermenge des rosa Moduls selbst steuerbar ist, sodass die Anzahl der tatsächlich vom Flamingo-Modell trainierten Parameter sehr gering ist. Denken Sie also nicht, dass multimodale universelle generative Modelle schwierig zu erstellen sind. Tatsächlich ist das nicht so pessimistisch. Das trainierte Flamingo-Modell kann viele allgemeine Aufgaben basierend auf der Textgenerierung erledigen. Natürlich ist die Eingabe multimodal, wie z. B. Videobeschreibung, visuelle Frage und Antwort, multimodaler Dialog usw. Aus dieser Perspektive kann Flamingo als allgemeines generatives Modell betrachtet werden.
Das zweite Beispiel ist das vor einiger Zeit neu veröffentlichte BLIP-2-Modell. Es basiert auf einer verbesserten Modellarchitektur und ist der von Flamingo sehr ähnlich Modell, diese beiden Teile werden fixiert, und dann wird in der Mitte ein Q-Former mit einer Konverterfunktion hinzugefügt – von der visuellen zur Sprachkonvertierung. Der Teil von BLIP-2, der wirklich trainiert werden muss, ist der Q-Former.
Wie in der Abbildung unten gezeigt, geben Sie zunächst ein Bild (das Bild rechts) in den Image Encoder ein. Der Text in der Mitte ist die vom Benutzer gestellte Frage oder Anweisung Eingabe in das große Sprachmodell. Schließlich wird die Antwort generiert, wahrscheinlich durch einen solchen Generierungsprozess.
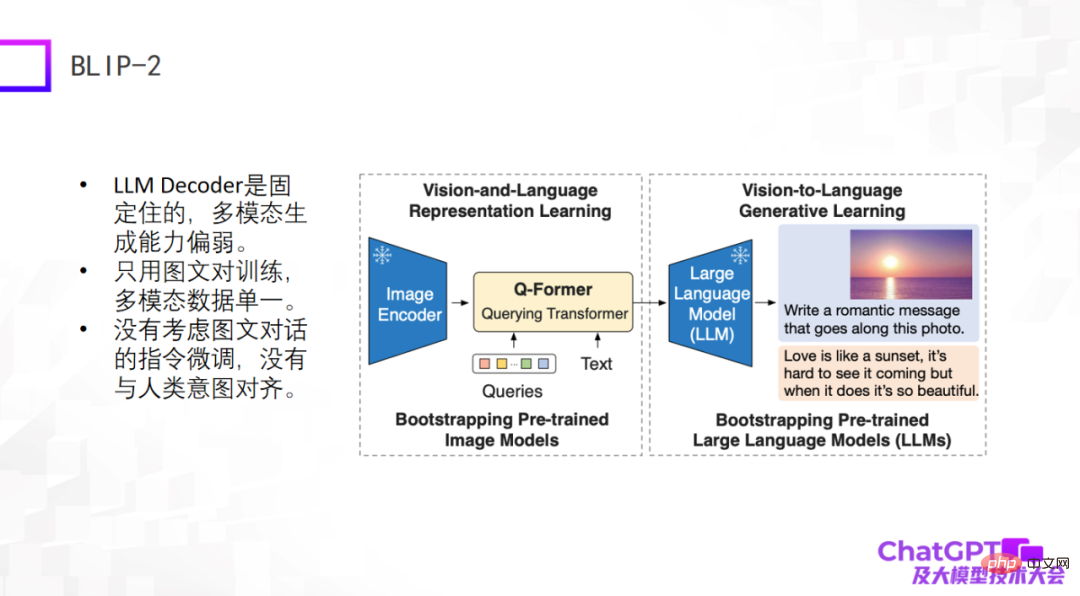
Die Mängel dieser beiden Modelle liegen auf der Hand, da sie relativ früh oder gerade erst erschienen sind und die von ChatGPT verwendeten technischen Methoden nicht berücksichtigt wurden. Zumindest gibt es keine Anweisungen für grafische Dialoge oder Multimodalität Die Feinabstimmung des Dialogs ist daher insgesamt nicht zufriedenstellend.
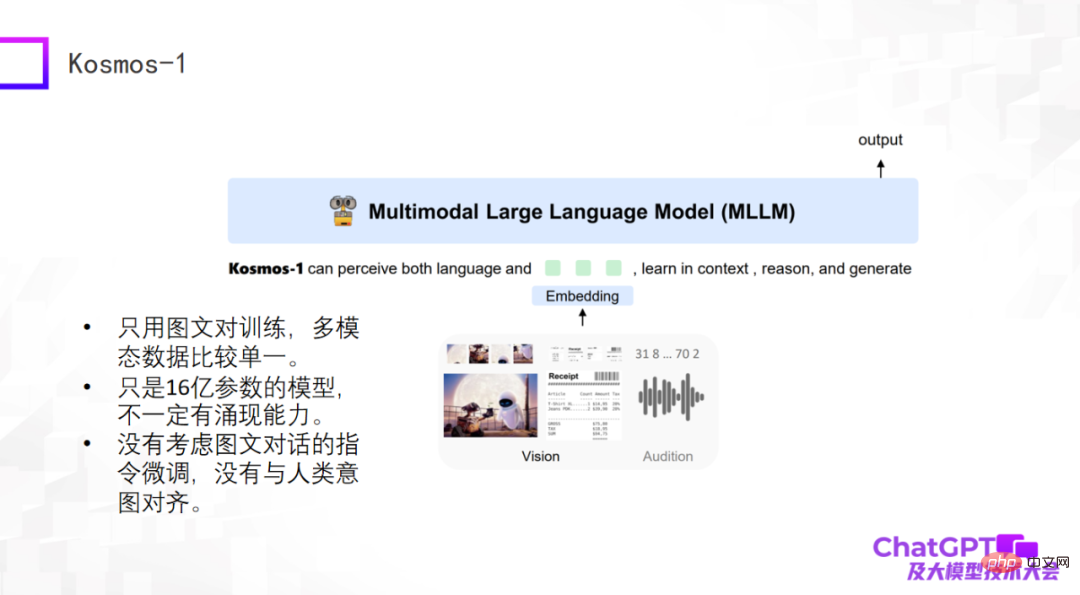
Der dritte ist Kosmos-1, der kürzlich von Microsoft veröffentlicht wurde. Er hat eine sehr einfache Struktur und verwendet nur Bild- und Textpaare für das Training. Die multimodalen Daten sind relativ einfach. Der größte Unterschied zwischen Kosmos-1 und den beiden oben genannten Modellen besteht darin, dass das große Sprachmodell selbst in den beiden oben genannten Modellen festgelegt ist, während das große Sprachmodell selbst in Kosmos-1 trainiert werden muss, also das Kosmos-1-Modell Die Nummer Die Anzahl der Parameter beträgt nur 1,6 Milliarden, und ein Modell mit 1,6 Milliarden Parametern kann möglicherweise nicht entstehen. Natürlich hat Kosmos-1 die Feinabstimmung der Befehle im grafischen Dialog nicht berücksichtigt, was dazu führte, dass manchmal Unsinn gesprochen wurde.
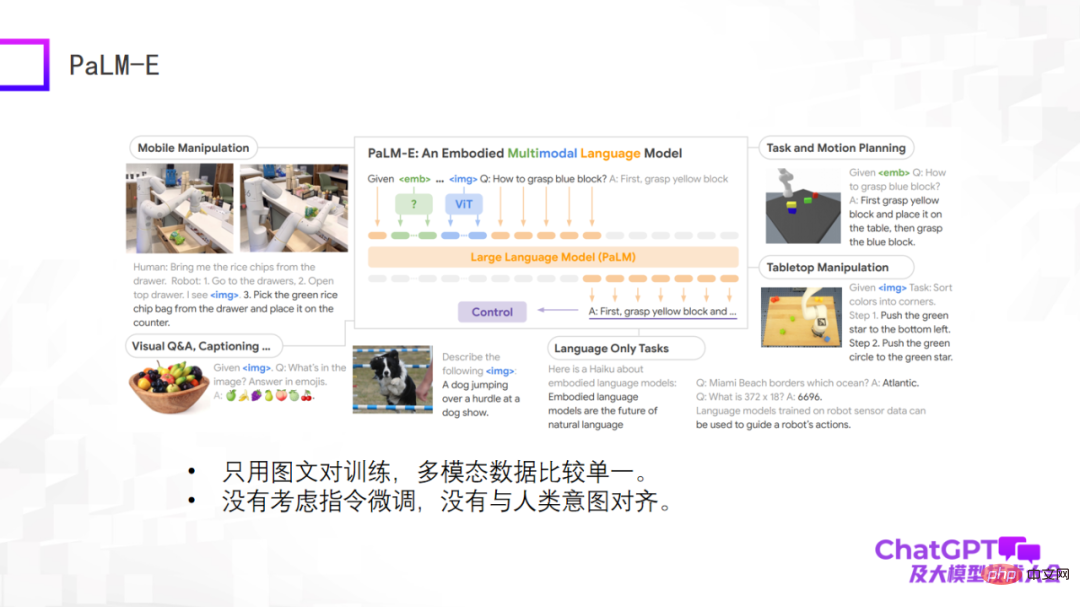
Das nächste Beispiel ist Googles multimodales verkörpertes visuelles Sprachmodell PaLM-E. Das PaLM-E-Modell ähnelt den ersten drei Beispielen und verwendet auch das große Sprachmodell ViT +. Der größte Durchbruch von PaLM-E besteht darin, dass es endlich die Möglichkeit untersucht, multimodale große Sprachmodelle im Bereich der Robotik zu implementieren. PaLM-E versucht den ersten Schritt der Erforschung, aber die Arten von Roboteraufgaben, die es berücksichtigt, sind sehr begrenzt und können nicht wirklich universell sein.
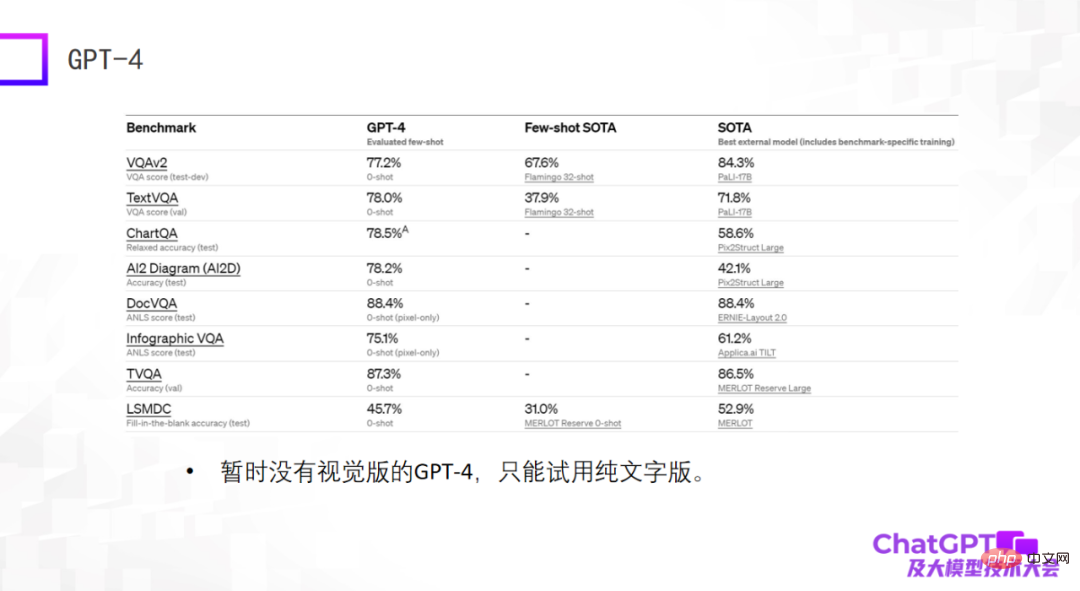
Das letzte Beispiel ist GPT-4 – das besonders erstaunliche Ergebnisse bei Standarddatensätzen liefert, oft sogar besser als die fein abgestimmten SOTA-Modelle, die derzeit auf dem Datensatz trainiert werden. Das mag ein Schock sein, hat aber eigentlich keine Bedeutung. Als wir vor zwei Jahren multimodale große Modelle erstellten, stellten wir fest, dass die Fähigkeiten großer Modelle nicht anhand von Standarddatensätzen bewertet werden können. Es gibt viele Unterschiede zwischen ihnen zwei. Große Lücke. Aus diesem Grund bin ich vom aktuellen GPT-4 etwas enttäuscht, da es nur Ergebnisse für Standarddatensätze liefert. Darüber hinaus handelt es sich bei dem derzeit verfügbaren GPT-4 nicht um eine visuelle Version, sondern um eine reine Textversion.
Im Allgemeinen werden die oben genannten Modelle für die allgemeine Sprachgenerierung verwendet, und die Eingabe ist eine multimodale Eingabe. Die folgenden beiden Modelle unterscheiden sich – nicht nur für die allgemeine Sprachgenerierung, sondern auch für die Generierung von Visionen sowohl Sprache als auch Bilder generieren.
Das erste ist Microsofts Visual ChatGPT, lassen Sie mich es kurz bewerten. Die Idee dieses Modells ist sehr einfach und es handelt sich eher um eine Überlegung beim Produktdesign. Es gibt viele Arten der visuellen Generierung sowie einige visuelle Erkennungsmodelle. Die Eingaben und Anweisungen für diese verschiedenen Aufgaben sind sehr unterschiedlich. Das Problem besteht darin, wie ein Modell alle diese Aufgaben umfassen kann. Daher hat Microsoft den Prompt-Manager entwickelt. Das im Kernteil von OpenAI verwendete ChatGPT entspricht der Übersetzung von Anweisungen für verschiedene visuelle Generierungsaufgaben durch ChatGPT. Bei den Fragen des Benutzers handelt es sich um in natürlicher Sprache beschriebene Anweisungen, die über ChatGPT in Anweisungen übersetzt werden, die die Maschine verstehen kann.
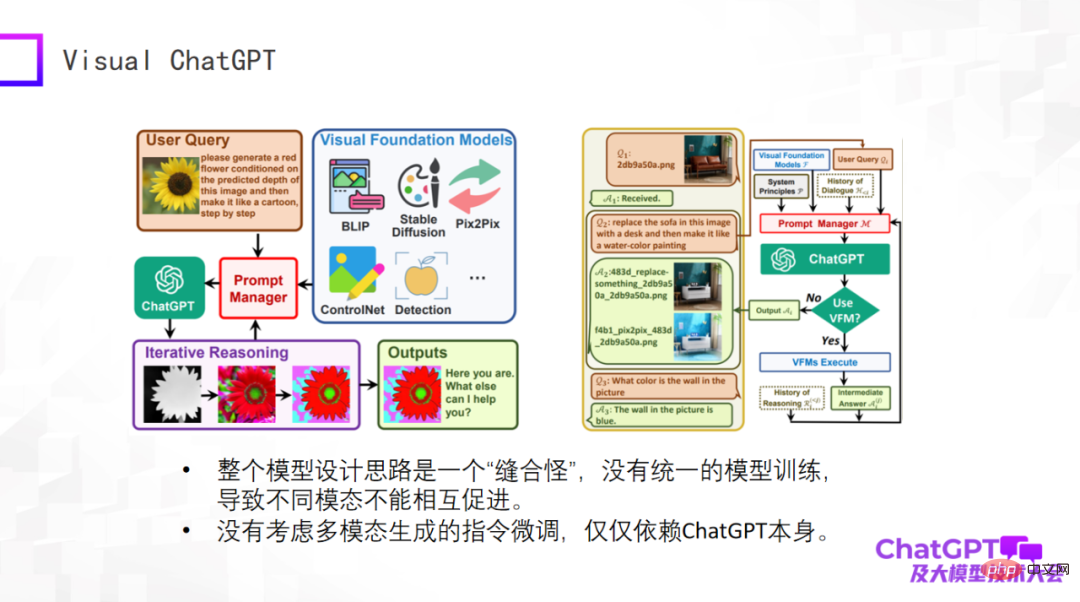
Visual ChatGPT macht genau so etwas. Aus Produktsicht ist es also wirklich gut, aus Sicht des Modelldesigns jedoch nichts Neues. Daher ist das Gesamtmodell aus Sicht des Modells ein „Stichmonster“. Es gibt kein einheitliches Modelltraining, was zu keiner gegenseitigen Förderung zwischen verschiedenen Modi führt. Wir betreiben Multimodalität, weil wir glauben, dass Daten aus verschiedenen Modalitäten einander helfen müssen. Und Visual ChatGPT berücksichtigt nicht die Feinabstimmung der Anweisungen zur multimodalen Generierung. Die Feinabstimmung der Anweisungen basiert nur auf ChatGPT selbst.
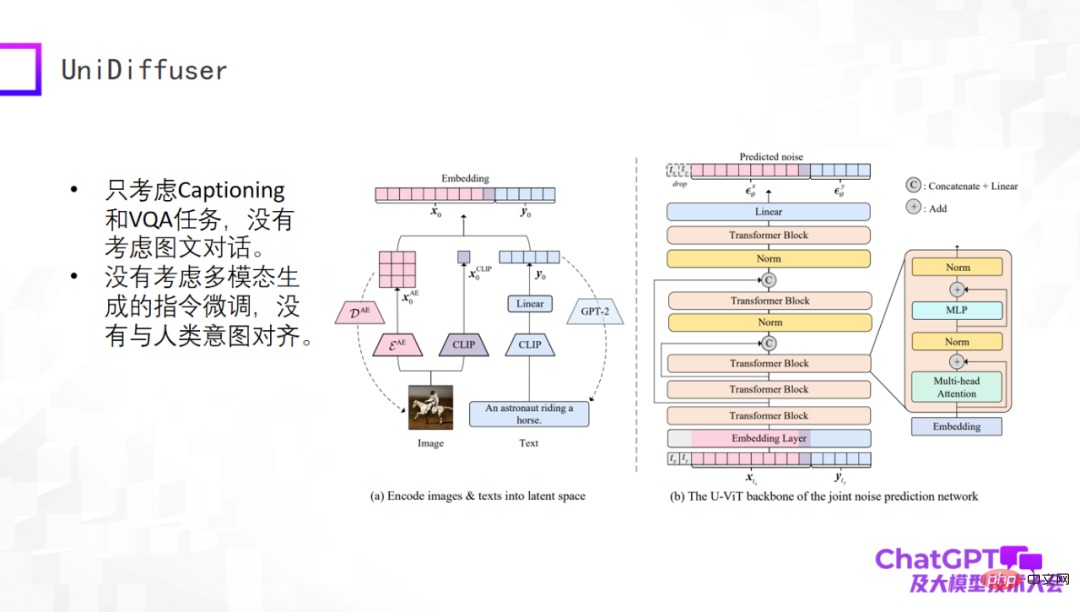
Das nächste Beispiel ist das UniDiffuser-Modell, das vom Team von Professor Zhu Jun von der Tsinghua-Universität veröffentlicht wurde. Aus akademischer Sicht kann dieses Modell tatsächlich Text und visuelle Inhalte aus multimodalen Eingaben generieren. Dies ist auf die transformatorbasierte Netzwerkarchitektur U-ViT zurückzuführen, die U-Net, der Kernkomponente von Stable Diffusion, ähnelt Dann werden Bilder und Textgenerierung in einem Framework vereint. Diese Arbeit selbst ist sehr aussagekräftig, aber sie ist noch relativ früh. Sie berücksichtigt beispielsweise nur Untertitel- und VQA-Aufgaben, berücksichtigt nicht mehrere Dialogrunden und optimiert die Anweisungen für die multimodale Generierung nicht.
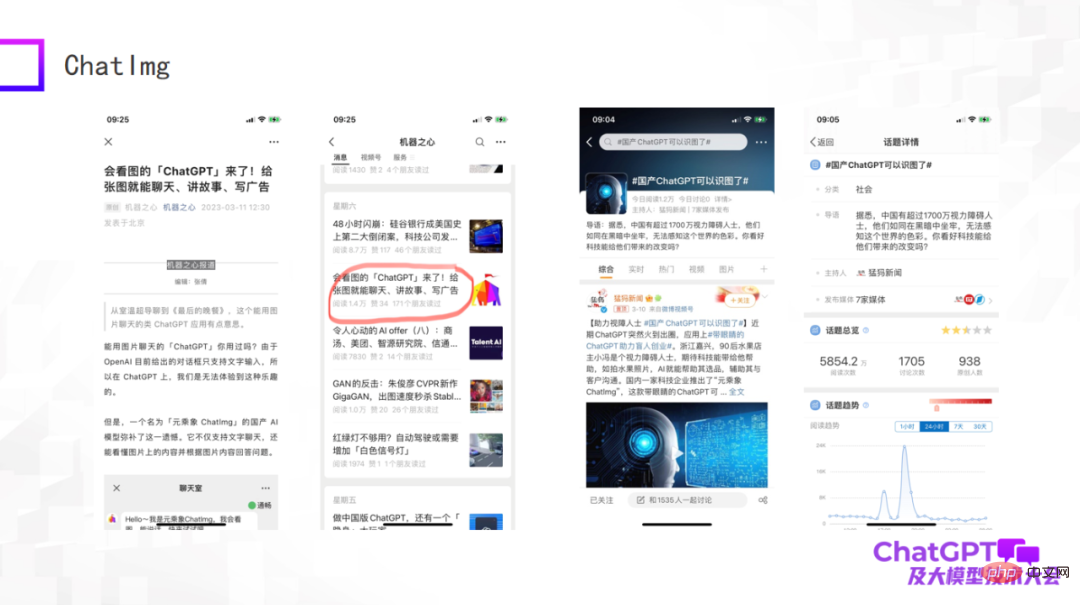
Es gab schon so viele Rezensionen, dass wir auch ein Produkt namens ChatImg entwickelt haben, wie im Bild unten gezeigt. Im Allgemeinen enthält ChatImg einen Bild-Encoder, einen multimodalen Bild- und Text-Encoder und einen Text-Decoder. Es ähnelt Flamingo und BLIP-2, wir berücksichtigen jedoch mehr und es gibt detaillierte Unterschiede in der spezifischen Implementierung.
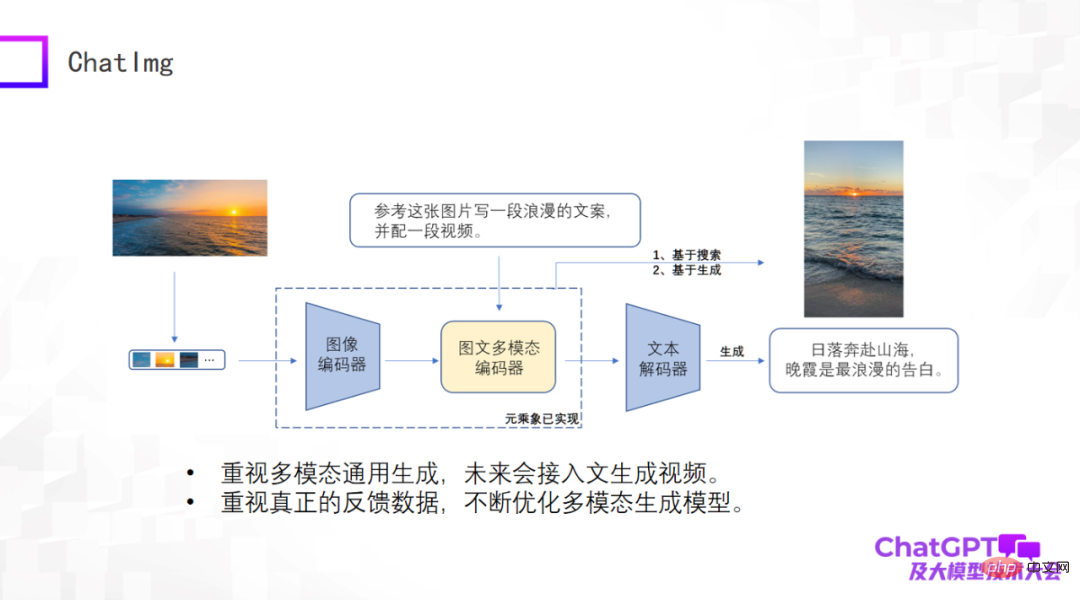
Einer der größten Vorteile von ChatImg ist, dass es Videoeingaben akzeptieren kann. Besonderes Augenmerk legen wir auf die multimodale allgemeine Generierung, einschließlich Textgenerierung, Bildgenerierung und Videogenerierung. Wir hoffen, in diesem Rahmen verschiedene Generierungsaufgaben implementieren zu können und letztendlich auf Text zugreifen zu können, um Videos zu generieren.
Zweitens legen wir besonderen Wert auf echte Benutzerdaten. Wir hoffen, das Generierungsmodell selbst kontinuierlich zu optimieren und seine Fähigkeiten nach Erhalt echter Benutzerdaten zu verbessern, deshalb haben wir die ChatImg-Anwendung veröffentlicht.
Die folgenden Bilder sind einige Beispiele, die wir als frühes Modell getestet haben. Obwohl es immer noch einige Dinge gibt, die nicht gut gemacht sind, kann ChatImg die Bilder im Allgemeinen immer noch verstehen. ChatImg kann beispielsweise Beschreibungen von Gemälden in Gesprächen generieren und auch kontextbezogenes Lernen durchführen.
Das erste Beispiel im Bild oben beschreibt das Gemälde „Sternennacht“. In der Beschreibung nennt ChatImg es einen amerikanischen Maler Beispiel: ChatImg hat physikalische Rückschlüsse auf die Objekte im Bild gezogen; das dritte Beispiel ist ein Foto, das ich selbst aufgenommen habe und das zwei Regenbögen enthielt, und es wurde genau erkannt.
Uns ist aufgefallen, dass es beim dritten und vierten Beispiel im obigen Bild um emotionale Probleme geht. Dies hängt tatsächlich mit der Arbeit zusammen, die wir als Nächstes erledigen werden. Wir möchten ChatImg mit dem Roboter verbinden. Heutige Roboter sind meist passiv und alle Anweisungen sind voreingestellt, was sie sehr starr erscheinen lässt. Wir hoffen, dass mit ChatImg verbundene Roboter aktiv mit Menschen kommunizieren können. Wie geht das? Zuallererst muss der Roboter in der Lage sein, Menschen zu fühlen, um den Zustand der Welt und die Emotionen der Menschen objektiv zu sehen, oder um ein Spiegelbild zu erhalten. Anhand dieser beiden Beispiele glaube ich, dass dieses Ziel erreichbar ist.
Lassen Sie mich abschließend den heutigen Bericht zusammenfassen. Erstens haben ChatGPT und GPT-4 Innovationen in das Forschungsparadigma gebracht. Wir können uns nicht darüber beschweren, dass wir keine Ressourcen haben, es gibt immer Möglichkeiten Schwierigkeiten zu überwinden. Für die multimodale Forschung sind nicht einmal Maschinen mit Hunderten von Karten erforderlich. Solange entsprechende Strategien angewendet werden, kann eine kleine Anzahl von Maschinen gute Arbeit leisten. Zweitens haben alle bestehenden multimodalen generativen Modelle ihre eigenen Probleme. GPT-4 verfügt noch nicht über eine offene visuelle Version, und es gibt immer noch eine Chance für uns alle. Darüber hinaus denke ich, dass GPT-4 immer noch ein Problem hat, wie das multimodale generative Modell letztendlich aussehen sollte. Es gibt keine perfekte Antwort (tatsächlich enthüllt es keine Details von GPT-4). Das ist eigentlich eine gute Sache. Menschen auf der ganzen Welt sind sehr schlau und jeder hat seine eigenen Ideen. Dadurch kann eine neue Forschungssituation entstehen, in der hundert Blumen blühen. Das war’s für meine Rede, vielen Dank an alle.

Das obige ist der detaillierte Inhalt von„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr