
Heim >Technologie-Peripheriegeräte >KI >Die Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit
Die Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-23 15:19:071417Durchsuche
Wie leistungsstark ist eine Codezeile? Die Kernl-Bibliothek, die wir heute vorstellen werden, ermöglicht es Benutzern, das Pytorch-Transformator-Modell mit nur einer Codezeile um ein Vielfaches schneller auf der GPU auszuführen, wodurch die Inferenzgeschwindigkeit des Modells erheblich beschleunigt wird.
Insbesondere ist Berts Inferenzgeschwindigkeit mit dem Segen von Kernl 12-mal schneller als die Basislinie von Hugging Face. Dieser Erfolg ist hauptsächlich darauf zurückzuführen, dass Kernl benutzerdefinierte GPU-Kernel in den neuen OpenAI-Programmiersprachen Triton und TorchDynamo schreibt. Der Projektautor stammt aus Lefebvre Sarrut.
GitHub-Adresse: https://github.com/ELS-RD/kernl/
Das Folgende ist ein Vergleich zwischen Kernl und anderen Inferenz-Engines. Die Zahlen in Klammern Die Abszisse gibt jeweils die Stapelgröße und die Sequenzlänge an, und die Ordinate ist die Inferenzbeschleunigung.
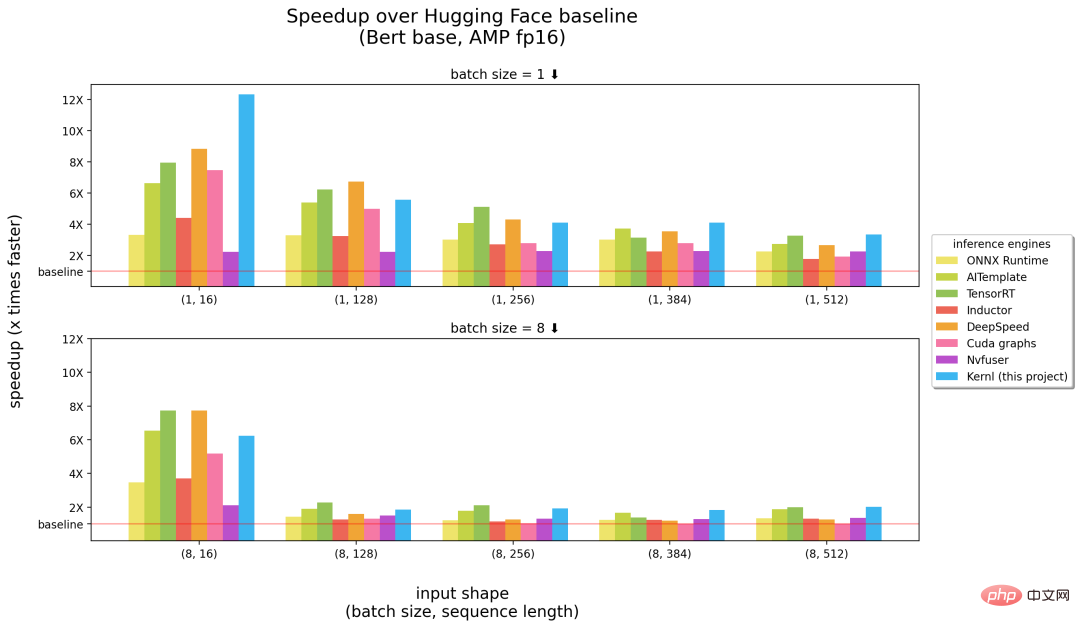
Benchmarks laufen auf einer 3090 RTX-GPU und einer 12-Core-Intel-CPU.
Aus den obigen Ergebnissen ist ersichtlich, dass Kernl bei der Eingabe langer Sequenzen als die schnellste Inferenz-Engine (rechte Hälfte des Bildes oben) gilt und nahe an NVIDIAs TensorRT liegt kurze Eingabesequenzen ( (linke Bildhälfte oben). Ansonsten ist der Kernl-Kernelcode sehr kurz und leicht zu verstehen und zu ändern. Das Projekt fügt sogar einen Triton-Debugger und Tools (basierend auf Fx) hinzu, um den Kernel-Austausch zu vereinfachen, sodass keine Änderungen am Quellcode des PyTorch-Modells erforderlich sind.
Projektautor Michaël Benesty hat diese Forschung zusammengefasst. Sie haben Kernl veröffentlicht, eine Bibliothek zur Beschleunigung der Transformatorinferenz. Sie ist sehr schnell, erreicht manchmal die SOTA-Leistung und kann so geknackt werden, dass sie mit den meisten Transformatorarchitekturen übereinstimmt.
Sie haben es auch auf T5 getestet und es war sechsmal schneller. Benesty sagte, das sei erst der Anfang.
Warum wurde Kernl erstellt?
Bei Lefebvre Sarrut betreibt der Projektautor mehrere Transformer-Modelle in der Produktion, von denen einige latenzempfindlich sind, hauptsächlich Suche und Recsys. Sie verwenden auch OnnxRuntime und TensorRT und haben sogar die Transformer-Deploy-OSS-Bibliothek erstellt, um ihr Wissen mit der Community zu teilen.
Kürzlich hat der Autor generative Sprachen getestet und hart daran gearbeitet, sie zu beschleunigen. Allerdings hat es sich als sehr schwierig erwiesen, dies mit herkömmlichen Werkzeugen zu bewerkstelligen. Ihrer Ansicht nach ist Onnx ein weiteres interessantes Format, das für maschinelles Lernen entwickelt wurde und zum Speichern trainierter Modelle verwendet wird.
Allerdings weist das Onnx-Ökosystem (hauptsächlich die Inferenz-Engine) die folgenden Einschränkungen auf, wenn es mit der neuen LLM-Architektur umgeht:
- Der Export von Modellen ohne Kontrollfluss nach Onnx ist einfach, denn darauf können Sie sich verlassen Verfolgung. Aber dynamisches Verhalten ist schwieriger zu erreichen;
- Im Gegensatz zu PyTorch bietet ONNX Runtime/TensorRT noch keine native Unterstützung für Multi-GPU-Aufgaben, die Tensor-Parallelität implementieren;
- TensorRT kann nicht zwei Dynamiken für Transformatormodelle mit derselben verwalten Konfigurationsdatei axis. Da Sie jedoch normalerweise Eingaben unterschiedlicher Länge bereitstellen möchten, müssen Sie 1 Modell pro Stapelgröße erstellen.
- Sehr große Modelle sind üblich, aber Onnx (als Protobuff-Datei) weist einige Einschränkungen hinsichtlich der Datei auf Größe und Gewichte müssen außerhalb des Modells gespeichert werden, um das Problem zu lösen.
Eine sehr ärgerliche Tatsache ist, dass neue Modelle niemals beschleunigt werden. Sie müssen warten, bis jemand anderes einen benutzerdefinierten CUDA-Kernel dafür schreibt. Es ist nicht so, dass die vorhandenen Lösungen schlecht wären. Eines der großartigen Dinge an OnnxRuntime ist die Multi-Hardware-Unterstützung, und TensorRT ist dafür bekannt, sehr schnell zu sein.
Also wollten die Projektautoren einen Optimierer haben, der so schnell ist wie TensorRT auf Python/PyTorch, weshalb sie Kernl erstellt haben.
Wie geht das?
Speicherbandbreite ist normalerweise der Engpass beim Deep Learning. Um die Schlussfolgerung zu beschleunigen, ist die Reduzierung des Speicherzugriffs oft eine gute Strategie. Bei kurzen Eingabesequenzen hängt der Engpass normalerweise mit dem CPU-Overhead zusammen, der beseitigt werden muss. Die Projektautoren nutzen hauptsächlich die folgenden drei Technologien:
Die erste ist OpenAI Triton, eine Sprache zum Schreiben von GPU-Kerneln wie CUDA. Verwechseln Sie sie nicht mit dem Nvidia Triton-Inferenzserver, der effizienter ist . Verbesserungen wurden durch die Fusion mehrerer Operationen erzielt, sodass Berechnungen verkettet werden, ohne Zwischenergebnisse im GPU-Speicher zu behalten. Der Autor verwendet es, um Aufmerksamkeit (ersetzt durch Flash Attention), lineare Ebenen und Aktivierungen sowie Layernorm/Rmsnorm neu zu schreiben.
Das zweite ist das CUDA-Diagramm. Während des Aufwärmschritts speichert es jeden gestarteten Kern und seine Parameter. Anschließend rekonstruierten die Projektautoren den gesamten Argumentationsprozess.
Schließlich gibt es noch TorchDynamo, einen von Meta vorgeschlagenen Prototyp, der Projektautoren beim Umgang mit dynamischem Verhalten helfen soll. Während des Aufwärmschritts verfolgt es das Modell und stellt ein Fx-Diagramm (statisches Berechnungsdiagramm) bereit. Sie ersetzten einige Operationen des Fx-Graphen durch ihren eigenen Kernel, der in Python neu kompiliert wurde.
Zukünftig wird die Projekt-Roadmap schnelleres Aufwärmen, unregelmäßige Inferenz (keine Verlustberechnung beim Padding), Trainingsunterstützung (Unterstützung langer Sequenzen), Multi-GPU-Unterstützung (mehrere Parallelisierungsmodi) und Quantisierung (PTQ) umfassen. , Cutlass-Kernel-Tests neuer Chargen und verbesserte Hardware-Unterstützung usw.
Weitere Einzelheiten finden Sie im Originalprojekt.
Das obige ist der detaillierte Inhalt vonDie Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr