
Heim >Technologie-Peripheriegeräte >KI >Probleme mit der Interpretierbarkeit neuronaler Netze: Wiederholung der Kritik an NNs von vor dreißig Jahren
Probleme mit der Interpretierbarkeit neuronaler Netze: Wiederholung der Kritik an NNs von vor dreißig Jahren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-21 14:19:091428Durchsuche
1 Parkplatz) ist es entscheidend, diese Entscheidungen zu erklären und nicht nur eine vorhergesagte Punktzahl zu erstellen.
Die Forschung im Bereich erklärbarer künstlicher Intelligenz (XAI) hat sich in letzter Zeit auf das Konzept kontrafaktischer Beispiele konzentriert. Die Idee ist einfach: Erstellen Sie zunächst einige kontrafaktische Beispiele mit erwarteten Ausgaben und speisen Sie sie in das ursprüngliche Netzwerk ein. Lesen Sie dann die Einheiten der verborgenen Schicht, um zu erklären, warum das Netzwerk andere Ausgaben erzeugt hat. Formeller:
„Der Bruch p wird zurückgegeben, weil der Variablen V ein Wert (v1, v2, ...) zugeordnet ist. Wenn V einen Wert (v′1, v′2, ...) hat. ), Wenn alle anderen Variablen konstant gehalten werden, wird der Score p' zurückgegeben 45.000 £ beträgt, erhalten Sie einen Kredit.“ Eine Arbeit von Browne und Swift [1] (im Folgenden als B&W bezeichnet) zeigte jedoch kürzlich, dass das kontrafaktische Beispiel nur geringfügig aussagekräftiger ist. Beispiele werden durch die Durchführung kleiner und nicht beobachtbarer Störungen generiert auf der Eingabe, was dazu führt, dass das Netzwerk sie mit hoher Sicherheit falsch klassifiziert.
Darüber hinaus „erklären“ kontrafaktische Beispiele, was einige Funktionen sein sollten, um korrekte Vorhersagen zu erhalten, aber „öffnen Sie nicht die Blackbox“; das heißt, sie erklären nicht, wie der Algorithmus funktioniert. Der Artikel argumentiert weiter, dass kontrafaktische Beispiele keine Lösung für die Interpretierbarkeit bieten und dass es „ohne Semantik keine Erklärung“ gibt.
Tatsächlich macht der Artikel sogar einen noch stärkeren Vorschlag:
1) Wir finden entweder einen Weg, die Semantik zu extrahieren, von der angenommen wird, dass sie in den verborgenen Schichten des Netzwerks existiert, oder
2) Geben Sie das zu wir scheitern.
Und Walid S. Saba selbst ist pessimistisch in Bezug auf (1). Mit anderen Worten: Er gibt unser Versagen mit Bedauern zu. Im Folgenden sind seine Gründe aufgeführt.
2 Der Autor glaubt, dass der Grund, warum die Hoffnung auf eine zufriedenstellende Erklärung nicht verwirklicht werden kann, genau die Gründe sind, die Fodor und Pylyshyn [2] vor mehr als dreißig Jahren dargelegt haben.Walid S. Saba argumentierte dann: Bevor wir erklären, wo das Problem liegt, müssen wir beachten, dass rein extensionale Modelle (wie neuronale Netze) Systemizität und Kompositionalität nicht modellieren können, da sie symbolische Strukturen mit ableitbarer Syntax nicht erkennen entsprechende Semantik.
Darstellungen in neuronalen Netzen sind also nicht wirklich „Symbole“, die irgendetwas Interpretierbarem entsprechen – sondern vielmehr verteilte, korrelierte und kontinuierliche Werte, die selbst nichts implizieren, was konzeptionell den oben erläuterten Dingen entsprechen kann.
Einfacher ausgedrückt beziehen sich subsymbolische Darstellungen in neuronalen Netzen selbst nicht auf etwas, das Menschen konzeptionell verstehen können (verborgene Einheiten selbst können keine Objekte von metaphysischer Bedeutung darstellen). Es handelt sich vielmehr um eine Reihe versteckter Einheiten, die zusammen typischerweise ein hervorstechendes Merkmal darstellen (z. B. die Schnurrhaare einer Katze).
Aber genau aus diesem Grund können neuronale Netze keine Interpretierbarkeit erreichen, nämlich weil die Kombination mehrerer versteckter Merkmale nicht bestimmbar ist – sobald die Kombination abgeschlossen ist (durch irgendeine lineare Kombinationsfunktion), gehen die einzelnen Einheiten verloren (wir werden unten gezeigt). ).
3 Modul[2].
In symbolischen Systemen gibt es wohldefinierte kombinatorische semantische Funktionen, die die Bedeutung zusammengesetzter Wörter basierend auf der Bedeutung ihrer Bestandteile berechnen. Aber diese Kombination ist umkehrbar –
das heißt, man hat immer Zugriff auf die (Eingabe-)Komponenten, die diese Ausgabe erzeugt haben, und zwar genau deshalb, weil man in einem symbolischen System Zugriff auf eine „syntaktische Struktur“ hat. Diese Struktur enthält eine Karte wie die Komponenten zusammengebaut werden. Nichts davon trifft auf NN zu. Sobald Vektoren (Tensoren) in einem NN kombiniert werden, kann ihre Zerlegung nicht mehr bestimmt werden (die Möglichkeiten, wie Vektoren (einschließlich Skalare) zerlegt werden können, sind unendlich!)
Um zu veranschaulichen, warum dies der Kern des Problems ist, betrachten wir Folgendes B&W-Vorschlag zum Extrahieren der Semantik in DNNs, um Interpretierbarkeit zu erreichen. Der Vorschlag von B&W besteht darin, diese Richtlinien zu befolgen:
Das Eingabebild trägt die Bezeichnung „Architektur“, da das versteckte Neuron 41435, das normalerweise die Radkappe aktiviert, einen Aktivierungswert von 0,32 hat. Wenn der Aktivierungswert des versteckten Neurons 41435 0,87 beträgt, wird das Eingabebild mit „Auto“ gekennzeichnet.
Um zu verstehen, warum dies nicht zu einer Interpretierbarkeit führt, beachten Sie bitte, dass es nicht ausreicht, eine Aktivierung von Neuron 41435 von 0,87 zu verlangen. Nehmen Sie der Einfachheit halber an, dass Neuron 41435 nur zwei Eingänge hat, x1 und x2. Was wir jetzt haben, ist in Abbildung 1 unten dargestellt:
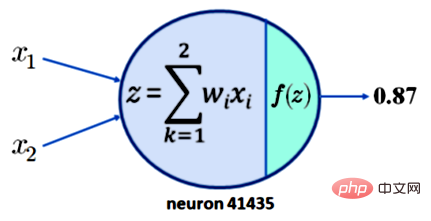
Legende: Die Ausgabe eines einzelnen Neurons mit zwei Eingängen beträgt 0,87
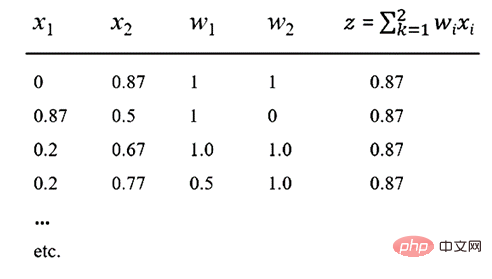
Nehmen wir nun an, dass unsere Aktivierungsfunktion f die beliebte ReLU-Funktion ist. dann kann eine Ausgabe von z = 0,87 erzeugt werden. Dies bedeutet, dass für die in der folgenden Tabelle aufgeführten Werte von x1, x2, w1 und w2 eine Ausgabe von 0,87 erhalten wird. Hinweis zur Tabelle: Verschiedene Eingabemethoden können einen Wert von 0,87 ergeben , und sie erzeugen eine Ausgabe von 0,87. Der wichtige Punkt hierbei ist, dass die Zusammensetzung in NNs irreversibel ist, sodass aus keinem Neuron oder keiner Ansammlung von Neuronen eine sinnvolle Semantik erfasst werden kann.
 Gemäß dem Slogan von B&W „Keine Semantik, keine Erklärung“ erklären wir, dass von NN niemals eine Erklärung erhalten werden kann. Kurz gesagt, es gibt keine Semantik ohne Kompositionalität, es gibt keine Erklärung ohne Semantik und DNN kann Kompositionalität nicht modellieren. Dies kann wie folgt formalisiert werden:
Gemäß dem Slogan von B&W „Keine Semantik, keine Erklärung“ erklären wir, dass von NN niemals eine Erklärung erhalten werden kann. Kurz gesagt, es gibt keine Semantik ohne Kompositionalität, es gibt keine Erklärung ohne Semantik und DNN kann Kompositionalität nicht modellieren. Dies kann wie folgt formalisiert werden:
1 Es gibt keine Erklärung ohne Semantik[1] 2. Es gibt keine Semantik ohne reversible Kompositionalität[2]
3. Kompositionalität in DNN ist irreversibel[2]
=> DNN unerklärlich (ohne XAI)
Ende.
Übrigens hat die Tatsache, dass die Zusammensetzung in DNNs irreversibel ist, neben der Unfähigkeit, interpretierbare Vorhersagen zu erstellen, auch Konsequenzen, insbesondere in Bereichen, die eine Argumentation auf höherer Ebene erfordern, wie z. B. Natural Language Understanding (NLU).
Insbesondere kann ein solches System wirklich nicht erklären, wie ein Kind lernen kann, eine unendliche Anzahl von Sätzen nur anhand von Vorlagen wie (
) zu interpretieren, weil „John“, „Neighbor Girl“, „Always Dressed The boy“. mit dem T-Shirt hier“ usw. sind alles mögliche Ausprägungen von, und „Classic Rock“, „Ruhm“, „Marys Oma“, „Laufen am Strand“ usw. sind alles mögliche Ausprägungen von .
Da solche Systeme kein „Gedächtnis“ haben und ihre Zusammensetzung nicht rückgängig gemacht werden kann, benötigen sie theoretisch unzählige Beispiele, um diese einfache Struktur zu erlernen. [Anmerkung des Herausgebers: Dieser Punkt war genau Chomskys Infragestellung der strukturellen Linguistik und leitete damit die transformative generative Grammatik ein, die die Linguistik seit mehr als einem halben Jahrhundert beeinflusst. 】
Abschließend betont der Autor, dass Fodor und Pylyshyn [2] vor mehr als dreißig Jahren Kritik an NN als kognitiver Architektur geäußert haben – sie zeigten, warum NN Systematik, Produktivität und Kompositionalität nicht modellieren kann, die alle notwendig sind, um darüber zu sprechen „Semantik“ – und diese zwingende Kritik wurde nie perfekt beantwortet.
Da die Notwendigkeit, das Problem der KI-Erklärbarkeit zu lösen, immer wichtiger wird, müssen wir diesen klassischen Aufsatz noch einmal aufgreifen, denn er zeigt die Grenzen der Gleichsetzung statistischer Mustererkennung mit Fortschritt in der KI auf.
Das obige ist der detaillierte Inhalt vonProbleme mit der Interpretierbarkeit neuronaler Netze: Wiederholung der Kritik an NNs von vor dreißig Jahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr