
Heim >Technologie-Peripheriegeräte >KI >Richard Sutton erklärte unverblümt, dass die Faltungs-Backpropagation ins Hintertreffen geraten sei und KI-Durchbrüche neue Ideen erfordern: kontinuierliche Backpropagation
Richard Sutton erklärte unverblümt, dass die Faltungs-Backpropagation ins Hintertreffen geraten sei und KI-Durchbrüche neue Ideen erfordern: kontinuierliche Backpropagation

- 王林nach vorne
- 2023-04-19 15:37:591307Durchsuche
„Verlust der Plastizität“ ist einer der am häufigsten kritisierten Mängel tiefer neuronaler Netze, was auch einer der Gründe dafür ist, dass KI-Systeme, die auf Deep Learning basieren, als unfähig gelten, weiter zu lernen.
Für das menschliche Gehirn bezieht sich „Plastizität“ auf die Fähigkeit, neue Neuronen und neue Verbindungen zwischen Neuronen zu erzeugen, was eine wichtige Grundlage für kontinuierliches Lernen darstellt. Mit zunehmendem Alter nimmt die Plastizität des Gehirns allmählich ab, auf Kosten der Festigung des Gelernten. Neuronale Netze sind ähnlich.
Ein anschauliches Beispiel ist, dass sich das Warmstart-Training im Jahr 2020 bewährt hat: Nur durch das Verwerfen des zunächst Gelernten und das Training auf dem gesamten Datensatz in einer einmaligen Lernweise können Vergleiche erzielt werden. Guter Lerneffekt.
Beim Deep Reinforcement Learning (DRL) muss das KI-System häufig alle zuvor vom neuronalen Netzwerk gelernten Inhalte „vergessen“, nur einen Teil der Inhalte im Wiedergabepuffer speichern und dann von vorne beginnen kontinuierliches Lernen erreichen. Diese Art des Zurücksetzens des Netzwerks gilt auch als Beweis dafür, dass Deep Learning nicht weiter lernen kann.
Wie können wir also Lernsysteme formbar halten?
Kürzlich hielt Richard Sutton, der Vater des Reinforcement Learning, auf der CoLLAs-Konferenz 2022 eine Rede mit dem Titel „Maintaining Plasticity in Deep Continual Learning“ und schlug eine Antwort vor, von der er glaubte, dass sie dieses Problem lösen könnte: Kontinuierlicher Backpropagation-Algorithmus ( Kontinuierlicher Backprop).
Richard Sutton bewies zunächst die Existenz eines Plastizitätsverlusts aus der Perspektive des Datensatzes, analysierte dann die Ursachen des Plastizitätsverlusts innerhalb des neuronalen Netzwerks und schlug schließlich den kontinuierlichen Backpropagation-Algorithmus als Lösung für den Plastizitätsverlust vor : Reinitialisierung einer kleinen Anzahl von Neuronen mit geringem Nutzen, Diese kontinuierliche Injektion von Diversität kann die Plastizität tiefer Netzwerke auf unbestimmte Zeit aufrechterhalten.
Das Folgende ist der vollständige Text der Rede, der von AI Technology Review zusammengestellt wurde, ohne die ursprüngliche Bedeutung zu ändern.
1 Die wahre Existenz von Plastizitätsverlust
Kann Deep Learning das Problem des kontinuierlichen Lernens wirklich lösen?
Die Antwort lautet „Nein“, hauptsächlich für die folgenden drei Punkte:
- „Unlösbar“ bedeutet, dass die Lerngeschwindigkeit wie bei einem nicht tiefen linearen Netzwerk letztendlich sehr langsam sein wird;
- in der Tiefe verwendet Lernen Professionelle Standardisierungsmethoden sind nur beim einmaligen Lernen wirksam und stehen im Gegensatz zum kontinuierlichen Lernen.
- Replay-Caching selbst ist eine extreme Methode, um zuzugeben, dass tiefes Lernen nicht möglich ist.
Daher Wir müssen bessere Algorithmen finden, die für dieses neue Lernmodell geeignet sind, und die Einschränkungen des einmaligen Lernens beseitigen.
Zunächst verwenden wir ImageNet- und MNIST-Datensätze für Klassifizierungsaufgaben, um eine Regressionsvorhersage zu erreichen, den kontinuierlichen Lerneffekt direkt zu testen und die Existenz eines Plastizitätsverlusts beim überwachten Lernen nachzuweisen.
ImageNet-Datensatztest
ImageNet ist ein Datensatz, der Millionen von Bildern enthält, die mit Substantiven getaggt sind. Es verfügt über 1000 Kategorien mit 700 oder mehr Bildern pro Kategorie und wird häufig zum Lernen von Kategorien und zur Vorhersage von Kategorien verwendet.
Unten sehen Sie ein Foto eines Hais, heruntergerechnet auf die Größe 32*32. Der Zweck dieses Experiments besteht darin, minimale Änderungen gegenüber Deep-Learning-Praktiken zu finden. Wir haben die 700 Bilder jeder Kategorie in 600 Trainingsmuster und 100 Testmuster unterteilt und dann die 1000 Kategorien in zwei Gruppen unterteilt, um eine binäre Klassifizierungsaufgabensequenz mit einer Länge von 500 zu generieren. Alle Datensätze wurden zufällig in der Reihenfolge gemischt. Nach dem Training für jede Aufgabe bewerten wir die Genauigkeit des Modells anhand der Testprobe, führen es 30 Mal unabhängig aus und ermitteln den Durchschnitt, bevor wir mit der nächsten binären Klassifizierungsaufgabe beginnen.

500 Klassifizierungsaufgaben teilen sich dasselbe Netzwerk. Um die Auswirkungen der Komplexität zu beseitigen, wird das Hauptnetzwerk nach dem Aufgabenwechsel zurückgesetzt. Wir verwenden ein Standardnetzwerk, das heißt 3 Faltungsschichten + 3 vollständig verbundene Schichten, aber die Ausgabeschicht kann für den ImageNet-Datensatz relativ klein sein, da in einer Aufgabe nur zwei Kategorien verwendet werden. Für jede Aufgabe werden alle 100 Beispiele als Stapel verwendet, mit insgesamt 12 Stapeln und 250 Trainingsepochen. Vor Beginn der ersten Aufgabe wird nur eine Initialisierung durchgeführt, wobei die Kaiming-Verteilung zum Initialisieren der Gewichte verwendet wird. Für den Kreuzentropieverlust wird eine impulsbasierte stochastische Gradientenabstiegsmethode und eine ReLU-Aktivierungsfunktion verwendet.
Daaus ergeben sich zwei Fragen:
1. Wie wird sich die Leistung in der Aufgabensequenz entwickeln?
2. Bei welcher Aufgabe wird die Leistung besser sein? Ist die erste Mission besser? Oder profitieren nachfolgende Aufgaben von den Erfahrungen früherer Aufgaben?
Die Antwort ist in der folgenden Abbildung dargestellt: Die Leistung des kontinuierlichen Lernens wird umfassend durch die Trainingsschrittgröße und die Backpropagation bestimmt.
Da es sich um ein binäres Klassifizierungsproblem handelt, beträgt die Zufallswahrscheinlichkeit 50 %. Der schattierte Bereich stellt die Standardabweichung dar, und dieser Unterschied ist nicht signifikant. Der lineare Benchmark verwendet eine lineare Ebene, um Pixelwerte direkt zu verarbeiten, was nicht so effektiv ist wie die Deep-Learning-Methode. Dieser Unterschied ist erheblich.
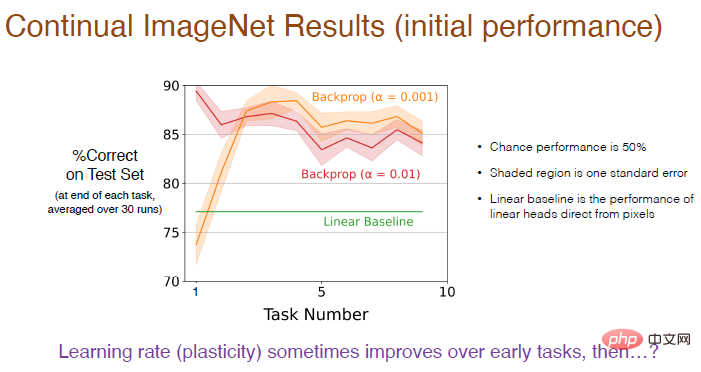
Abbildung: Die Verwendung einer kleineren Lernrate (α=0,001) führt zu einer höheren Genauigkeit und die Leistung wird sich in den ersten 5 Aufgaben allmählich verbessern, auf lange Sicht zeigt sich jedoch ein Abwärtstrend.
Wir haben dann die Anzahl der Aufgaben auf 2000 erhöht und den Einfluss der Lernrate auf den kontinuierlichen Lerneffekt weiter analysiert. Im Durchschnitt wurde die Genauigkeit alle 50 Aufgaben berechnet. Das Ergebnis ist unten dargestellt.
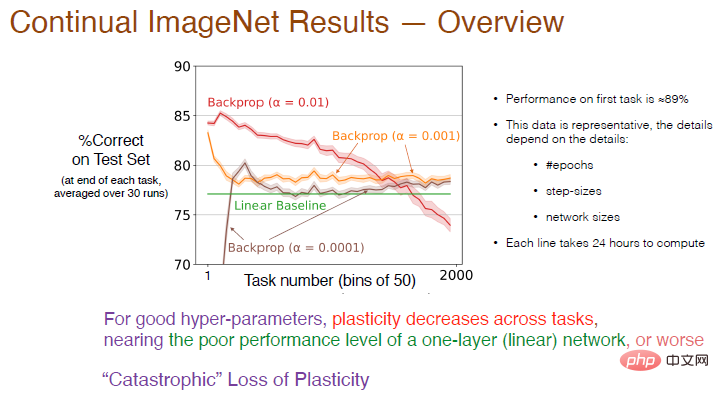
Legende: Die Genauigkeit der roten Kurve mit α=0,01 bei der ersten Aufgabe beträgt etwa 89 %. Sobald die Anzahl der Aufgaben 50 überschreitet, nimmt die Genauigkeit ab Nach und nach fehlt die endgültige Genauigkeit unter der linearen Grundlinie. Bei α = 0,001 verlangsamt sich die Lerngeschwindigkeit, die Plastizität nimmt ebenfalls stark ab und die Genauigkeit ist nur geringfügig höher als beim linearen Netzwerk.
Daher nimmt bei guten Hyperparametern die Plastizität zwischen Aufgaben ab und die Genauigkeit wird geringer sein als bei der Verwendung nur einer Schicht neuronaler Netze. Die rote Kurve zeigt einen nahezu „katastrophalen Verlust an Plastizität“.
Die Trainingsergebnisse hängen auch von Parametern wie der Anzahl der Iterationen, der Anzahl der Schritte und der Netzwerkgröße ab. Die Trainingszeit für jede Kurve in der Abbildung beträgt 24 Stunden auf mehreren Prozessoren, was möglicherweise nicht praktikabel ist Als nächstes wählen wir den MNIST-Datensatz zum Testen aus.
MNIST-Datensatztest
Der MNIST-Datensatz enthält insgesamt 60.000 handgeschriebene Ziffernbilder mit 10 Kategorien von 0 bis 9 und sind 28*28 Graustufenbilder.
Goodfellow et al. haben einmal eine neue Testaufgabe durch Mischen der Reihenfolge oder zufälliges Anordnen von Pixeln erstellt. Das Bild in der unteren rechten Ecke ist ein Beispiel für das generierte angeordnete Bild. In jeder Aufgabe werden 6000 Bilder nach dem Zufallsprinzip präsentiert. Hier wird kein Aufgabeninhalt hinzugefügt und die Netzwerkgewichte werden nur einmal vor der ersten Aufgabe initialisiert. Wir können den Online-Kreuzentropieverlust für das Training verwenden und weiterhin den Genauigkeitsindex verwenden, um den Effekt des kontinuierlichen Lernens zu messen.

Die neuronale Netzwerkstruktur besteht aus 4 vollständig verbundenen Schichten, die Anzahl der Neuronen in den ersten 3 Schichten beträgt 2000 und die Anzahl der Neuronen in der letzten Schicht beträgt 10. Da die Bilder des MNIST-Datensatzes zentriert und skaliert sind, werden keine Faltungsoperationen durchgeführt. Alle Klassifizierungsaufgaben verwenden dasselbe Netzwerk und verwenden einen stochastischen Gradientenabstieg ohne Impuls. Die anderen Einstellungen sind dieselben wie die, die am ImageNet-Datensatz getestet wurden.
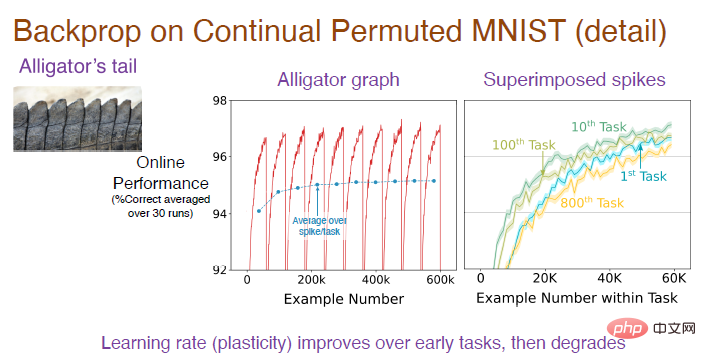
Hinweis: Das mittlere Bild ist das durchschnittliche Ergebnis nach 30 unabhängigen Durchläufen in der Aufgabensequenz. Da es sich um eine Klassifizierungsaufgabe handelt, beträgt die Genauigkeit des zufälligen Erratens zu Beginn Durch die Regeln zum Anordnen von Bildern wird die Vorhersagegenauigkeit allmählich erhöht, aber nach dem Wechseln der Aufgaben sinkt die Genauigkeit auf 10 %, sodass der Gesamttrend ständig schwankt. Das Bild rechts zeigt den Lerneffekt des Modells bei jeder Aufgabe. Die anfängliche Genauigkeit beträgt 0. Mit der Zeit wird der Effekt allmählich besser. Die Genauigkeit bei der 10. Aufgabe ist besser als bei der 1. Aufgabe, aber die Genauigkeit sinkt bei der 100. Aufgabe und die Genauigkeit bei der 800. Aufgabe ist sogar geringer als bei der ersten.
Um den gesamten Prozess zu verstehen, müssen wir uns auf die Analyse der Genauigkeit des konvexen Teils konzentrieren und ihn dann mitteln, um die blaue Kurve des Zwischenbilds zu erhalten. Es ist deutlich zu erkennen, dass die Genauigkeit zu Beginn allmählich ansteigt und sich dann bis zur 100. Aufgabe einpendelt. Warum sinkt die Genauigkeit bei der 800. Aufgabe stark?
Als nächstes haben wir verschiedene Schrittwerte bei weiteren Aufgabensequenzen ausprobiert, um deren Lerneffekte weiter zu beobachten. Die Ergebnisse sind wie folgt:
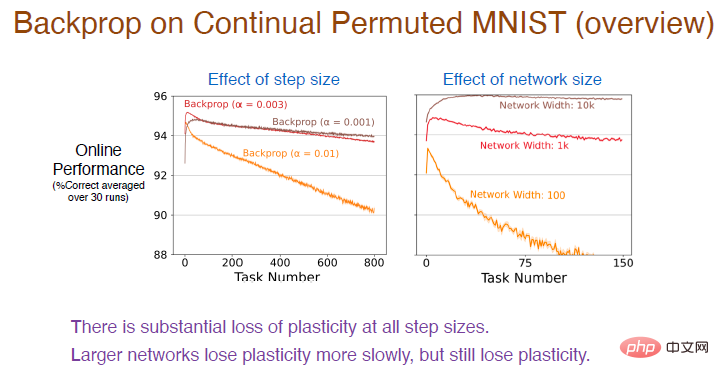
Legende: Die rote Kurve verwendet denselben Schrittwert wie im vorherigen Experiment. Die Genauigkeit nimmt tatsächlich stetig ab und der Plastizitätsverlust ist relativ groß.
Gleichzeitig nimmt die Plastizität umso schneller ab, je höher die Lernrate ist. Bei allen Schrittweitenwerten kommt es zu einem enormen Plastizitätsverlust. Darüber hinaus wirkt sich auch die Anzahl der Neuronen in der verborgenen Schicht auf die Genauigkeit aus. Aufgrund der verbesserten Anpassungsfähigkeit des neuronalen Netzwerks nimmt die Genauigkeit zu diesem Zeitpunkt sehr langsam ab Es wird immer noch ein Verlust an Plastizität auftreten, aber je größer das Netzwerk, desto stärker nimmt die Genauigkeit ab. Je kleiner die Größe, desto schneller nimmt die Plastizität ab.
Warum kommt es innerhalb des neuronalen Netzwerks zu einem Verlust der Plastizität?
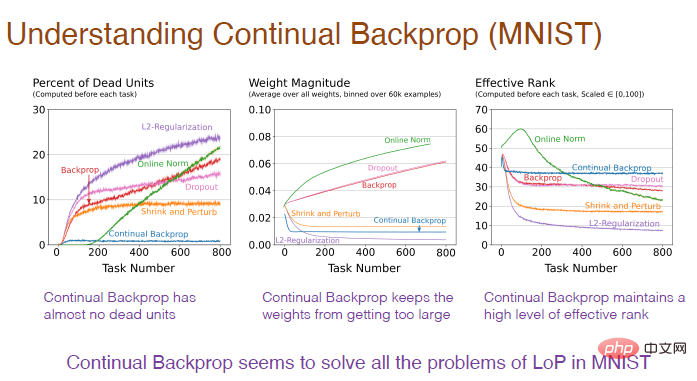
Das Bild unten erklärt warum. Es lässt sich feststellen, dass ein übermäßig hoher Anteil „toter“ Neuronen, ein übermäßiges Gewicht der Neuronen und ein Verlust der neuronalen Diversität Ursachen für den Verlust der Plastizität sind.
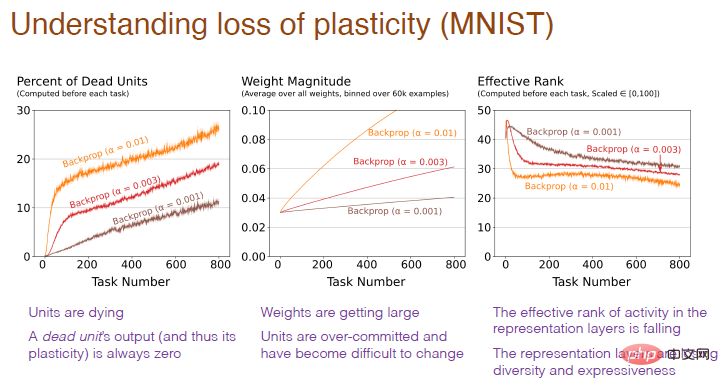
Diagrammhinweis: Die horizontale Achse stellt weiterhin die Aufgabennummer dar. Die vertikale Achse des ersten Bildes stellt den Prozentsatz der „toten“ Neuronen dar, deren Ausgabe und Gradient immer gleich sind 0 Neuronen können keine Netzwerkplastizität mehr vorhersagen. Die vertikale Achse des zweiten Diagramms stellt das Gewicht dar. Die vertikale Achse des dritten Diagramms stellt die effektive Anzahl der verbleibenden verborgenen Neuronen dar.
2 Einschränkungen bestehender Methoden
Wir analysieren, ob bestehende Deep-Learning-Methoden außer Backpropagation zur Aufrechterhaltung der Plastizität beitragen.
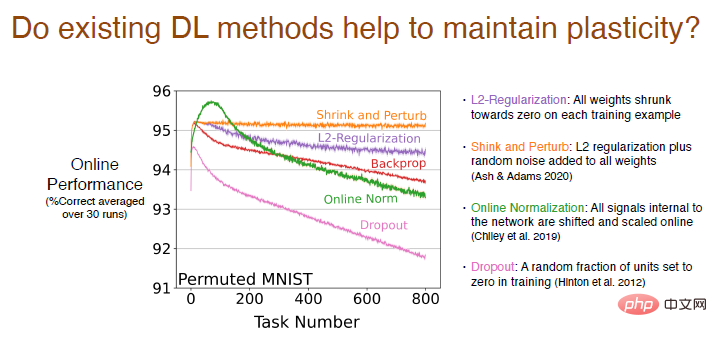
Die Ergebnisse zeigen, dass die L2-Regularisierungsmethode den Plastizitätsverlust reduziert und dabei die Gewichte auf 0 schrumpft, sodass sie dynamisch angepasst werden und die Plastizität aufrechterhalten kann.
Die Schrumpfungs- und Störungsmethoden ähneln der L2-Regularisierung. Gleichzeitig wird allen Gewichten zufälliges Rauschen hinzugefügt, um die Diversität zu erhöhen, und es gibt grundsätzlich keinen Verlust an Plastizität.
Wir haben auch andere Online-Standardisierungsmethoden ausprobiert, die anfangs relativ gut funktionierten, aber mit fortschreitendem Lernen war der Plastizitätsverlust gravierend. Die Leistung der Dropout-Methode ist noch schlechter. Wir haben einen Teil der Neuronen für das Neutraining zufällig auf 0 gesetzt und festgestellt, dass der Plastizitätsverlust stark zugenommen hat.
Verschiedene Methoden werden auch Auswirkungen auf die interne Struktur des neuronalen Netzwerks haben. Die Verwendung einer Regularisierungsmethode erhöht den Prozentsatz „toter“ Neuronen, da beim Schrumpfen der Gewichte auf 0, wenn diese bei 0 bleiben, die Ausgabe 0 ist und die Neuronen „sterben“. Und Schrumpfung und Störung fügen den Gewichten zufälliges Rauschen hinzu, sodass es nicht zu viele „tote“ Neuronen gibt. Die Normalisierungsmethode hat auch viele „tote“ Neuronen und scheint in die falsche Richtung zu gehen, und Dropout ist ähnlich.
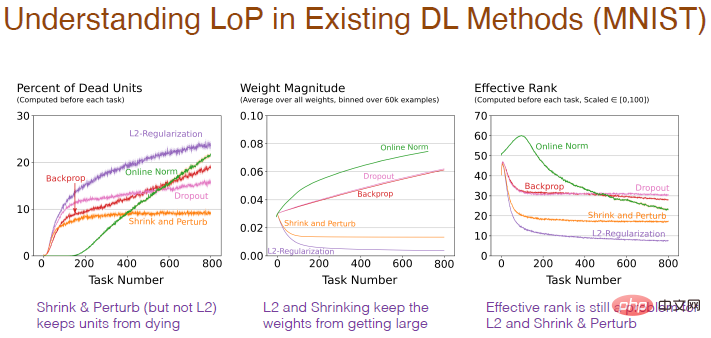
Das Ergebnis der Gewichtsänderung mit der Anzahl der Aufgaben ist vernünftiger. Durch die Reduzierung des Gewichts wird ein sehr geringes Gewicht erzielt, während durch die Standardisierung das Rauschen verringert wird Gewicht wird größer. Bei der L2-Regularisierung, -Kontraktion und -Störung ist die effektive Anzahl verborgener Neuronen jedoch relativ gering, was darauf hindeutet, dass ihre Leistung bei der Aufrechterhaltung der Diversität schlecht ist, was ebenfalls ein Problem darstellt.
Slowly Changing Regression Problem (SCR)
Alle unsere Ideen und Algorithmen basieren auf Slowly Changing Regression ProblemExperimenten, einem neuen idealisierten Problem, das sich auf kontinuierliches Lernen konzentriert.
In diesem Experiment besteht unser Ziel darin, die Zielfunktion zu erreichen, die durch ein einschichtiges neuronales Netzwerk mit zufälligen Gewichten gebildet wird, und die Neuronen der verborgenen Schicht sind 100 Neuronen mit linearer Schwelle.
Wir führen keine Klassifizierung durch, wir generieren nur eine Zahl, es handelt sich also um ein Regressionsproblem. Alle 10.000 Trainingsschritte wählen wir 1 Bit aus den letzten 15 Bits der Eingabe zum Umdrehen aus, es handelt sich also um eine sich langsam ändernde Zielfunktion.
Unsere Lösung besteht darin, die gleiche Netzwerkstruktur mit nur einer verborgenen Neuronenschicht zu verwenden und gleichzeitig sicherzustellen, dass die Aktivierungsfunktion differenzierbar ist, aber wir werden 5 versteckte Neuronen haben. Dies ähnelt RL. Der Erkundungsbereich des Agenten ist viel kleiner als der der interaktiven Umgebung, sodass er nur eine ungefähre Verarbeitung durchführen kann. Versuchen Sie, den ungefähren Wert zu ändern, was die Durchführung erleichtert einige systematische Experimente.
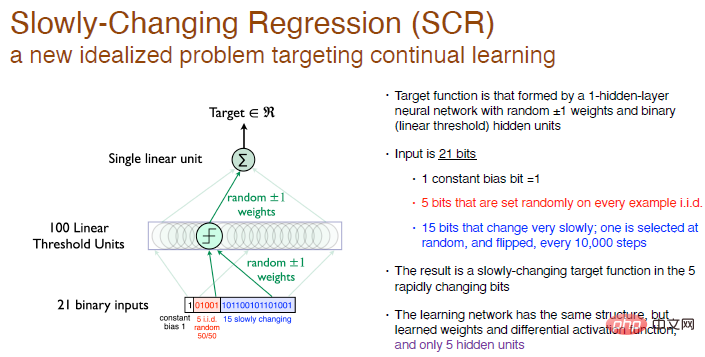
Legende: Die Eingabe ist eine 21-Bit-Zufallsbinärzahl, das erste Bit ist die Eingabekonstantenabweichung mit einem Wert von 1, die mittleren 5 Bits sind unabhängige und identisch verteilte Zufallszahlen und das andere 15 Bits ändern sich langsam. Konstante, die Ausgabe ist eine reelle Zahl. Die Gewichtungen werden auf 0 randomisiert und können zufällig auf +1 oder -1 gewählt werden.
Wir haben den Einfluss sich ändernder Schrittwerte und Aktivierungsfunktionen auf den Lerneffekt weiter untersucht. Hier werden beispielsweise Tanh-, Sigmoid- und Relu-Aktivierungsfunktionen verwendet:
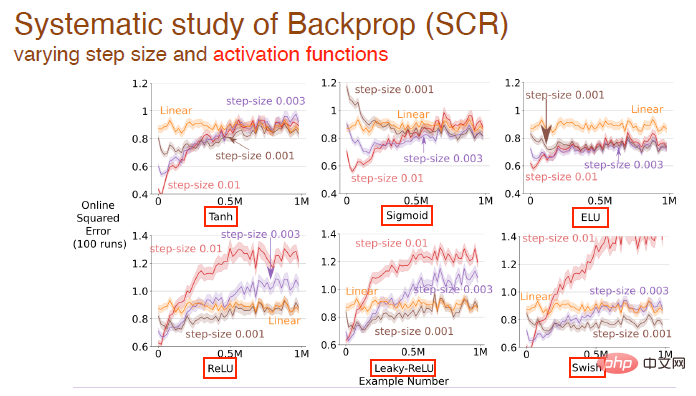
und die Aktivierungsfunktionsform ist für alle Algorithmen geeignet Einfluss des Lerneffekts:
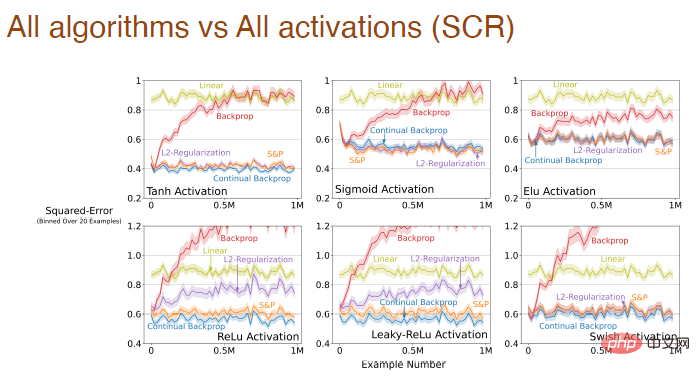
Wenn sich Schrittgröße und Aktivierungsfunktion gleichzeitig ändern, haben wir auch eine systematische Analyse des Einflusses der Adam-Rückausbreitung durchgeführt:
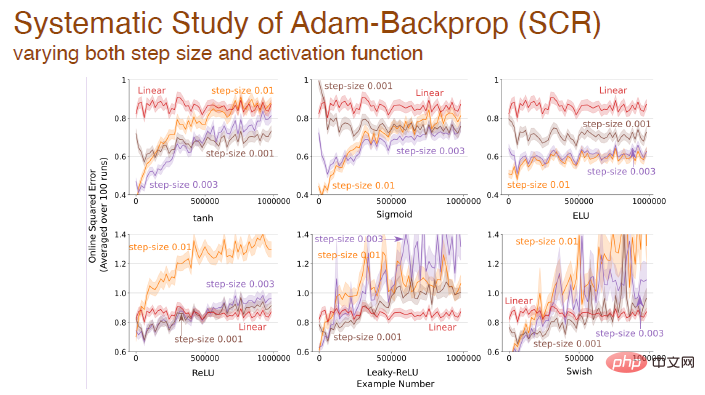
Schließlich wird nach der Aktivierung der Funktion der Fehler zwischen verschiedenen Algorithmen geändert, die auf dem Adam-Mechanismus basieren:
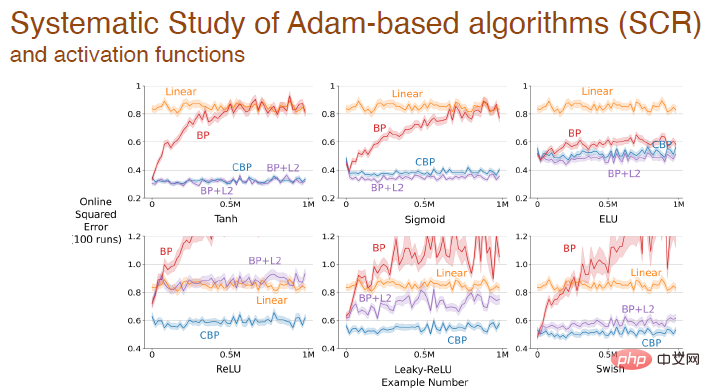
Die obigen experimentellen Ergebnisse zeigen, dass Deep-Learning-Methoden nicht mehr für kontinuierliches Lernen geeignet sind Bei Begegnung Neue Probleme, Lernen Der Prozess wird sehr langsam und der Vorteil der Tiefe wird nicht reflektiert. Standardisierte Methoden im Deep Learning sind nur für einmaliges Lernen geeignet. Wir müssen Deep-Learning-Methoden verbessern, um sie für kontinuierliches Lernen nutzen zu können.
3 Kontinuierliche Backpropagation
Wird der Faltungs-Backpropagation-Algorithmus selbst ein guter kontinuierlicher Lernalgorithmus sein?
Wir denken nicht.
Der Faltungs-Backpropagation-Algorithmus enthält hauptsächlich zwei Aspekte: Initialisierung mit kleinen Zufallsgewichten und Gradientenabstieg bei jedem Zeitschritt. Obwohl es zu Beginn kleine Zufallszahlen generiert, um die Gewichte zu initialisieren, wird es nicht noch einmal wiederholt. Im Idealfall benötigen wir möglicherweise einen Lernalgorithmus, der jederzeit ähnliche Berechnungen durchführen kann.
Wie sorgen wir also dafür, dass der Faltungs-Backpropagation-Algorithmus kontinuierlich lernt?
Der einfachste Weg besteht darin, punktuell neu zu initialisieren, zum Beispiel nach der Ausführung mehrerer Aufgaben. Gleichzeitig ist die Neuinitialisierung des gesamten Netzwerks beim kontinuierlichen Lernen jedoch möglicherweise nicht sinnvoll, da dies bedeutet, dass das neuronale Netzwerk alles vergisst, was es gelernt hat. Deshalb sollten wir besser einen Teil des neuronalen Netzwerks selektiv initialisieren z. B. einige „tote“ Neuronen neu initialisieren oder das neuronale Netzwerk nach Nutzen sortieren und Neuronen mit geringerem Nutzen neu initialisieren.
Die Idee der zufällig ausgewählten Initialisierung hängt mit der von Mahmood und Sutton im Jahr 2012 vorgeschlagenen Generierungs- und Testmethode zusammen. Es müssen lediglich einige Neuronen generiert und ihre Praktikabilität getestet werden. Der kontinuierliche Backpropagation-Algorithmus stellt die Verbindung zwischen diesen beiden her Konzepte. Die Generierungs- und Testmethode weist einige Einschränkungen auf: Da wir nur eine verborgene Schicht und nur ein Ausgabeneuron verwenden, erweitern wir sie auf ein mehrschichtiges Netzwerk, das mit einigen Deep-Learning-Methoden optimiert werden kann.
Wir überlegen uns zunächst, das Netzwerk in mehrere Schichten statt in einen einzigen Ausgang einzubauen. In früheren Arbeiten wurde das Konzept des Nutzens erwähnt, daher handelt es sich bei diesem Nutzen nur um ein Konzept auf Gewichtsebene. Die einfachste Verallgemeinerung besteht darin, den Nutzen auf der Ebene der Gewichtssummierung zu berücksichtigen.
Eine andere Idee besteht darin, die Aktivität der Features statt nur der Ausgabegewichte zu berücksichtigen, damit wir die Summe der Gewichte mit der durchschnittlichen Feature-Aktivierungsfunktion multiplizieren und so unterschiedliche Proportionen zuweisen können. Wir hoffen, Algorithmen zu entwerfen, die weiterhin lernen und schnell laufen können. Bei der Berechnung des Nutzens berücksichtigen wir auch die Plastizität von Funktionen. Schließlich wird der durchschnittliche Beitrag der Features auf die Ausgabeverzerrung übertragen, wodurch die Auswirkungen der Feature-Löschung verringert werden.
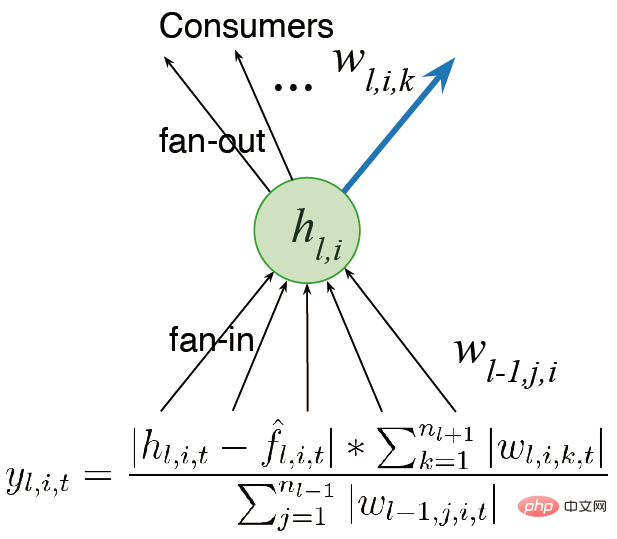
Es gibt zwei Hauptrichtungen für zukünftige Verbesserungen: (1) Wir müssen eine globale Messung des Nutzens vornehmen, den Einfluss von Neuronen auf die gesamte dargestellte Funktion messen, nicht nur auf Eingabegewichte und Ausgabe beschränkt lokale Maße wie Gewichte und Aktivierungsfunktionen; (2) Wir müssen den Generator zur Initialisierung weiter verbessern, und wir müssen auch Initialisierungsmethoden untersuchen, die die Leistung verbessern können.
Wie gut trägt die kontinuierliche Rückausbreitung zur Aufrechterhaltung der Plastizität bei?Experimentelle Ergebnisse zeigen, dass die kontinuierliche Backpropagation, trainiert mit dem online ausgerichteten MNIST-Datensatz,
die Plastizität vollständig aufrechterhält. Die blaue Kurve in der Abbildung unten zeigt dieses Ergebnis.
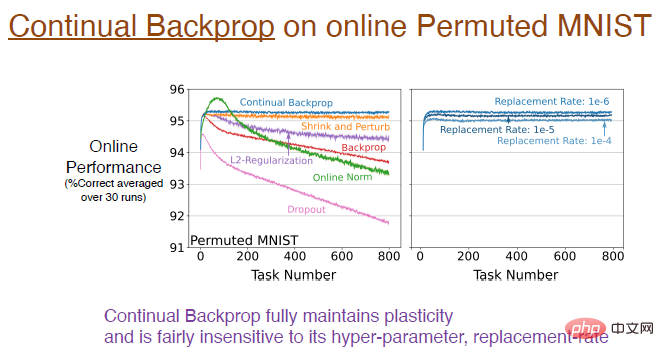
Diagrammhinweis: Das Bild rechts zeigt die Auswirkung unterschiedlicher Ersetzungsraten auf das kontinuierliche Lernen. Beispielsweise bedeutet eine Ersetzungsrate von 1e-6, dass bei jedem Zeitschritt 1/1000000 Darstellungen ersetzt werden. Das heißt, unter der Annahme, dass 2000 Merkmale vorhanden sind, wird alle 500 Schritte ein Neuron in jeder Schicht ersetzt. Diese Aktualisierungsgeschwindigkeit ist sehr langsam, sodass die Ersetzungsrate nicht sehr empfindlich auf Hyperparameter reagiert und den Lerneffekt nicht wesentlich beeinflusst.
Als nächstes müssen wir die Auswirkungen der kontinuierlichen Backpropagation auf die interne Struktur des neuronalen Netzwerks untersuchen.Bei der kontinuierlichen Backpropagation gibt es fast keine „toten“ Neuronen. Da das Dienstprogramm die durchschnittliche Funktionsaktivierung berücksichtigt, wird ein Neuron, wenn es „stirbt“, sofort ersetzt. Und weil wir ständig Neuronen ersetzen, erhalten wir neue Neuronen mit geringerem Gewicht. Da Neuronen zufällig initialisiert werden, behalten sie entsprechend eine reichhaltigere Darstellung und Diversität bei.
Kann die kontinuierliche Backpropagation also auf tiefere Faltungs-Neuronale Netze ausgeweitet werden?
Die Antwort ist ja! Im ImageNet-Datensatz blieb die Plastizität durch die kontinuierliche Rückausbreitung vollständig erhalten, und die endgültige Genauigkeit des Modells lag bei etwa 89 %. Tatsächlich ist die Leistung dieser Algorithmen in der anfänglichen Trainingsphase gleich. Wie bereits erwähnt, ändert sich die Ersetzungsrate sehr langsam und die Annäherung ist nur dann besser, wenn die Anzahl der Aufgaben groß genug ist.
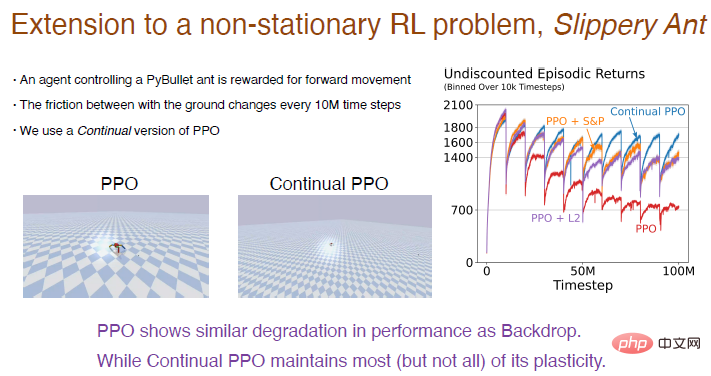
Hier nehmen wir das „Slippery Ant“-Problem als Beispiel, um die experimentellen Ergebnisse des Reinforcement Learning zu zeigen. Das „Slippery Ant“-Problem ist eine Erweiterung des instationären Verstärkungsproblems und ähnelt grundsätzlich der PyBullet-Umgebung, außer dass sich die Reibung zwischen Boden und Agent alle 10 Millionen Schritte ändert. Wir haben eine kontinuierlich lernende Version des PPO-Algorithmus implementiert, die auf kontinuierlicher Backpropagation basiert und selektiv initialisiert werden kann. Die Vergleichsergebnisse zwischen dem PPO-Algorithmus und dem kontinuierlichen PPO-Algorithmus sind wie folgt. Abbildung: Der PPO-Algorithmus funktioniert zu Beginn gut, aber mit fortschreitendem Training nimmt die Leistung immer weiter ab, was nach der Einführung des L2-Algorithmus und des Schrumpfungs- und Störungsalgorithmus gemildert wird. Der kontinuierliche PPO-Algorithmus schnitt relativ gut ab und behielt den größten Teil der Plastizität bei. Interessanterweise kann der vom PPO-Algorithmus trainierte Agent nur schwer laufen, aber der vom PPO-Algorithmus trainierte Agent kann kontinuierlich sehr weit laufen. Deep-Learning-Netzwerke sind in erster Linie für einmaliges Lernen optimiert, in dem Sinne, dass sie bei kontinuierlichem Lernen völlig versagen können. Deep-Learning-Methoden wie Normalisierung und DropOut sind möglicherweise nicht hilfreich für kontinuierliches Lernen, aber einige kleine Verbesserungen auf dieser Basis, wie z. B. kontinuierliche Backpropagation, können sehr effektiv sein. Kontinuierliche Backpropagation sortiert Netzwerkmerkmale nach dem Nutzen von Neuronen. Insbesondere für wiederkehrende neuronale Netze kann es zu weiteren Verbesserungen bei der Sortiermethode kommen. Der Reinforcement-Learning-Algorithmus nutzt die Idee der Policy-Iteration. Obwohl kontinuierliche Lernprobleme bestehen, eröffnet die Aufrechterhaltung der Plastizität von Deep-Learning-Netzwerken enorme neue Möglichkeiten für RL und modellbasiertes RL. 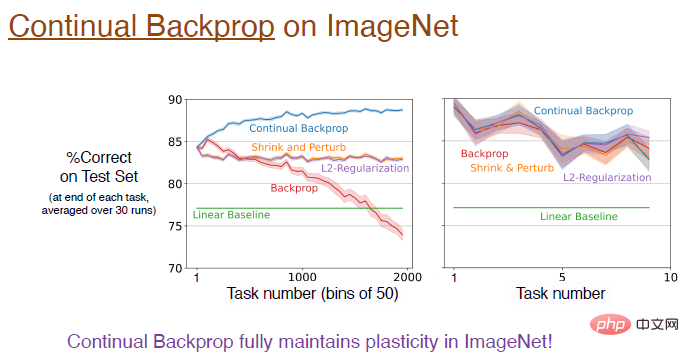
4 Fazit
Das obige ist der detaillierte Inhalt vonRichard Sutton erklärte unverblümt, dass die Faltungs-Backpropagation ins Hintertreffen geraten sei und KI-Durchbrüche neue Ideen erfordern: kontinuierliche Backpropagation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr