
Heim >Technologie-Peripheriegeräte >KI >Nur 10 % der Parameter werden benötigt, um SOTA zu übertreffen! Die Zhejiang University, Byte und Hong Kong Chinese schlugen gemeinsam einen neuen Rahmen für die Aufgabe „Posenschätzung auf Kategorieebene' vor
Nur 10 % der Parameter werden benötigt, um SOTA zu übertreffen! Die Zhejiang University, Byte und Hong Kong Chinese schlugen gemeinsam einen neuen Rahmen für die Aufgabe „Posenschätzung auf Kategorieebene' vor

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-17 21:40:01996Durchsuche
Robotern ein dreidimensionales Verständnis von Alltagsgegenständen zu vermitteln, ist eine große Herausforderung bei Robotikanwendungen.
Bei der Erkundung einer unbekannten Umgebung sind die vorhandenen Methoden zur Schätzung der Objektposition aufgrund der Vielfalt der Objektformen immer noch unbefriedigend.

Kürzlich haben Forscher der Zhejiang-Universität, des ByteDance Artificial Intelligence Laboratory und der Chinese University of Hong Kong gemeinsam ein neues Framework für die Objektform- und Posenschätzung auf Kategorieebene aus einem einzelnen RGB-D-Bild vorgeschlagen.

Papieradresse: https://arxiv.org/abs/2210.01112
Projektlink: https://zju3dv.github.io/gCasp
An Um die Formvariation von Objekten innerhalb einer Kategorie zu bewältigen, übernehmen Forscher semantische Grunddarstellungen, um verschiedene Formen in einem einheitlichen latenten Raum zu kodieren. Diese Darstellung wird zuverlässig zwischen beobachteten Punktwolken und geschätzten Formen hergestellt. Der Schlüssel zur Korrespondenz.
Dann wird durch das Entwerfen eines Formdeskriptors, der gegenüber starren Körperähnlichkeitstransformationen invariant ist, die Form- und Posenschätzung des Objekts entkoppelt, wodurch die implizite Formoptimierung des Zielobjekts in jeder Pose unterstützt wird. Experimente zeigen, dass die vorgeschlagene Methode in öffentlichen Datensätzen eine „führende Posenschätzungsleistung“ erzielt. Forschungshintergrund
Im Bereich der Roboterwahrnehmung und -bedienung ist die Schätzung der Form und Stellung von Alltagsgegenständen eine grundlegende Funktion und hat eine Vielzahl von Anwendungen, darunter 3D-Szenenverständnis, Roboterbedienung und autonome Lagerhaltung.
Die meisten frühen Arbeiten zu dieser Aufgabe konzentrierten sich auf die Posenschätzung auf Instanzebene, bei der die Objektposition hauptsächlich durch Ausrichten des beobachteten Objekts an einem bestimmten CAD-Modell ermittelt wird.
Allerdings ist ein solcher Aufbau in realen Szenarien nur begrenzt möglich, da es schwierig ist, im Voraus ein genaues Modell eines bestimmten Objekts zu erhalten.
Um auf unsichtbare, aber semantisch vertraute Objekte zu verallgemeinern, zieht die Schätzung der Objekthaltung auf Kategorieebene immer mehr Aufmerksamkeit in der Forschung auf sich, da sie möglicherweise verschiedene Instanzen derselben Kategorie in realen Szenen verarbeiten kann.
 Bestehende Posenschätzungsmethoden auf Kategorieebene versuchen normalerweise, die normalisierten Koordinaten von Instanzen in einer Klasse auf Pixelebene vorherzusagen, oder verwenden nach der Verformung ein Referenz-Vormodell, um die Objektpose abzuschätzen.
Bestehende Posenschätzungsmethoden auf Kategorieebene versuchen normalerweise, die normalisierten Koordinaten von Instanzen in einer Klasse auf Pixelebene vorherzusagen, oder verwenden nach der Verformung ein Referenz-Vormodell, um die Objektpose abzuschätzen.
Obwohl diese Arbeiten große Fortschritte gemacht haben, stoßen diese One-Shot-Vorhersagemethoden immer noch auf Schwierigkeiten, wenn es in derselben Kategorie große Formunterschiede gibt.
Um die Vielfalt von Objekten innerhalb derselben Kategorie zu bewältigen, nutzen einige Arbeiten eine neuronale implizite Darstellung, um sich an die Form des Zielobjekts anzupassen, indem sie die Pose und Form im impliziten Raum iterativ optimieren und eine bessere Leistung erzielen.
Bei der Posenschätzung von Objekten auf Kategorieebene gibt es zwei Hauptherausforderungen. Zum einen besteht der große Formunterschied innerhalb der Klasse, zum anderen besteht die Kopplung bestehender Methoden aus Form und Pose zur Optimierung, was leicht zu Optimierungsproblemen führen kann. Komplexer.
In diesem Artikel entkoppeln Forscher die Form- und Posenschätzung von Objekten, indem sie einen Formdeskriptor entwerfen, der gegenüber starren Körperähnlichkeitstransformationen invariant ist und so die implizite Formoptimierung von Zielobjekten in beliebigen Posen unterstützt. Schließlich werden Maßstab und Lage des Objekts auf der Grundlage der semantischen Assoziation zwischen der geschätzten Form und der Beobachtung ermittelt.
Einführung in den Algorithmus
Der Algorithmus besteht aus drei Modulen:
Semantische Primitivextraktion, Generative Formschätzung und Objektpositionsschätzung.
Die Eingabe des Algorithmus ist ein einzelnes RGB-D-Bild. Der Algorithmus verwendet vorab trainiertes Mask R-CNN, um die semantischen Segmentierungsergebnisse des RGB-Bildes zu erhalten, und projiziert dann die Punktwolke zurück jedes Objekts basierend auf den internen Parametern der Kamera. Diese Methode verarbeitet hauptsächlich Punktwolken und ermittelt schließlich den Maßstab und die 6DoF-Pose jedes Objekts.
Semantische Primitivextraktion
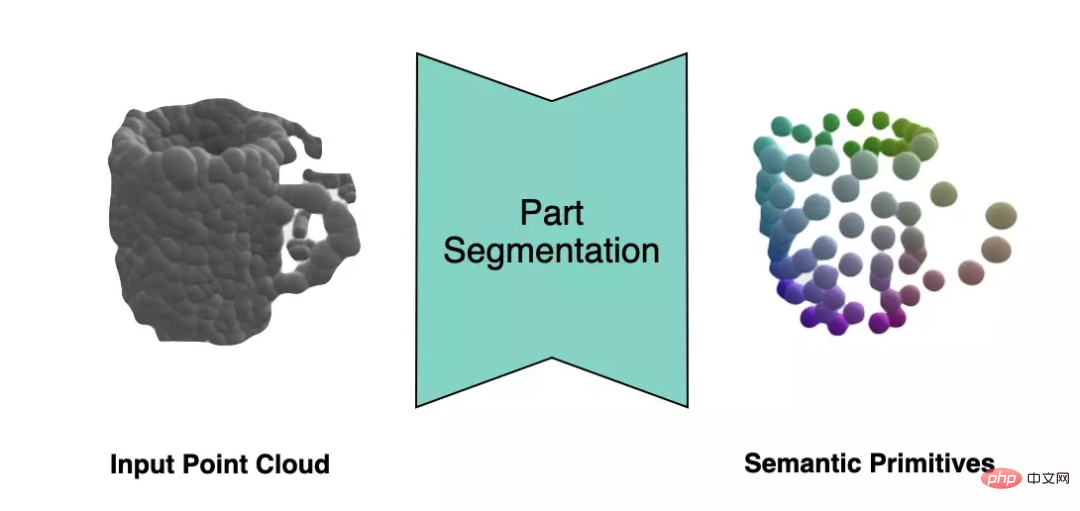
DualSDF [1] schlug eine semantische Darstellungsmethode für Primitive für ähnliche Objekte vor. Wie auf der linken Seite der Abbildung unten gezeigt, ist jede Instanz im gleichen Objekttyp in eine bestimmte Anzahl semantischer Grundelemente unterteilt, und die Bezeichnung jedes Grundelements entspricht einem bestimmten Teil eines bestimmten Objekttyps.
Um die semantischen Grundelemente von Objekten aus der Beobachtungspunktwolke zu extrahieren, verwendet der Autor ein Punktwolken-Segmentierungsnetzwerk, um die Beobachtungspunktwolke in Semantik mit Bezeichnungen als Grundelemente zu segmentieren .
Generative Formschätzung
# 🎜 🎜 #Die meisten generativen 3D-Modelle (wie DeepSDF) arbeiten in einem normalisierten Koordinatensystem.
Allerdings wird es eine ähnliche Posentransformation (Rotation, Translation und Skalierung) zwischen dem Objekt in der realen Beobachtung und dem normalisierten Koordinatensystem geben.
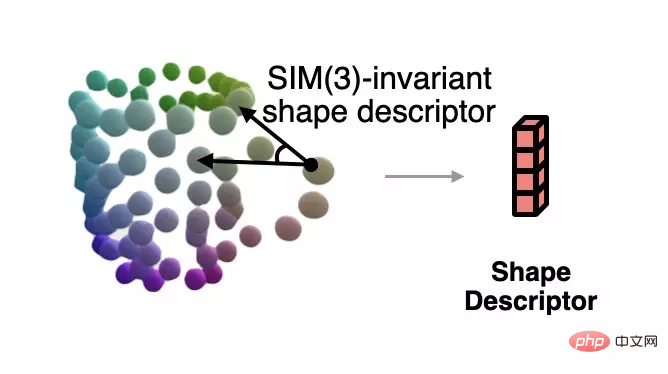
Um die normalisierte Form zu lösen, die der aktuellen Beobachtung entspricht, wenn die Pose unbekannt ist, schlägt der Autor eine Methode vor, die gegenüber der Ähnlichkeitstransformation auf der Grundlage semantischer primitiver Darstellung invariant ist . Formdeskriptor.
Dieser Deskriptor ist in der folgenden Abbildung dargestellt, die den Winkel zwischen Vektoren beschreibt, die aus verschiedenen Grundelementen bestehen: #🎜 🎜##🎜 🎜#
 Der Autor verwendet diesen Deskriptor, um den Fehler zwischen der aktuellen Beobachtung und der geschätzten Form zu messen, und verwendet den Gradientenabstieg, um die geschätzte Form konsistenter mit der Beobachtung zu machen in der folgenden Abbildung dargestellt. Der Autor zeigt auch weitere Beispiele zur Formoptimierung. #? Die semantische primitive Entsprechung zwischen der beobachteten Punktwolke und der gelösten Form verwendet der Autor den Umeyama-Algorithmus, um die Pose der beobachteten Form zu lösen.
Der Autor verwendet diesen Deskriptor, um den Fehler zwischen der aktuellen Beobachtung und der geschätzten Form zu messen, und verwendet den Gradientenabstieg, um die geschätzte Form konsistenter mit der Beobachtung zu machen in der folgenden Abbildung dargestellt. Der Autor zeigt auch weitere Beispiele zur Formoptimierung. #? Die semantische primitive Entsprechung zwischen der beobachteten Punktwolke und der gelösten Form verwendet der Autor den Umeyama-Algorithmus, um die Pose der beobachteten Form zu lösen.
Experimentelle Ergebnisse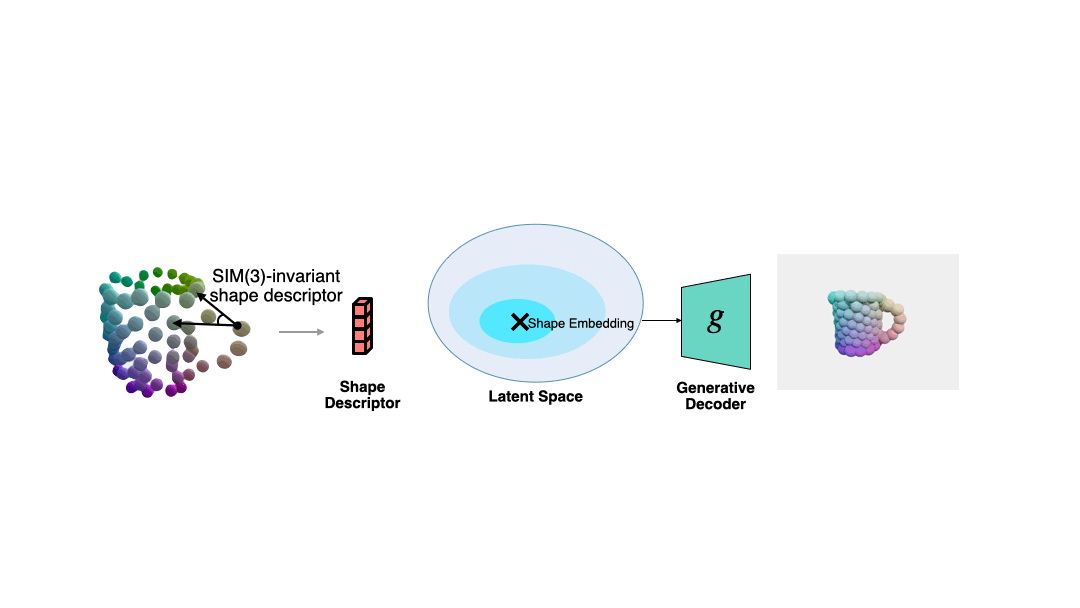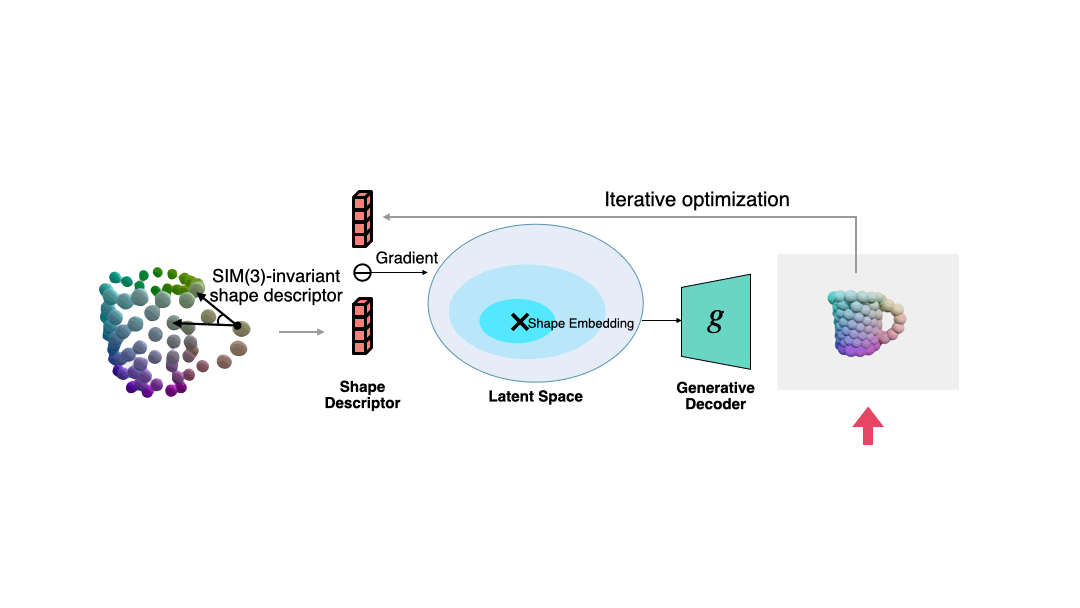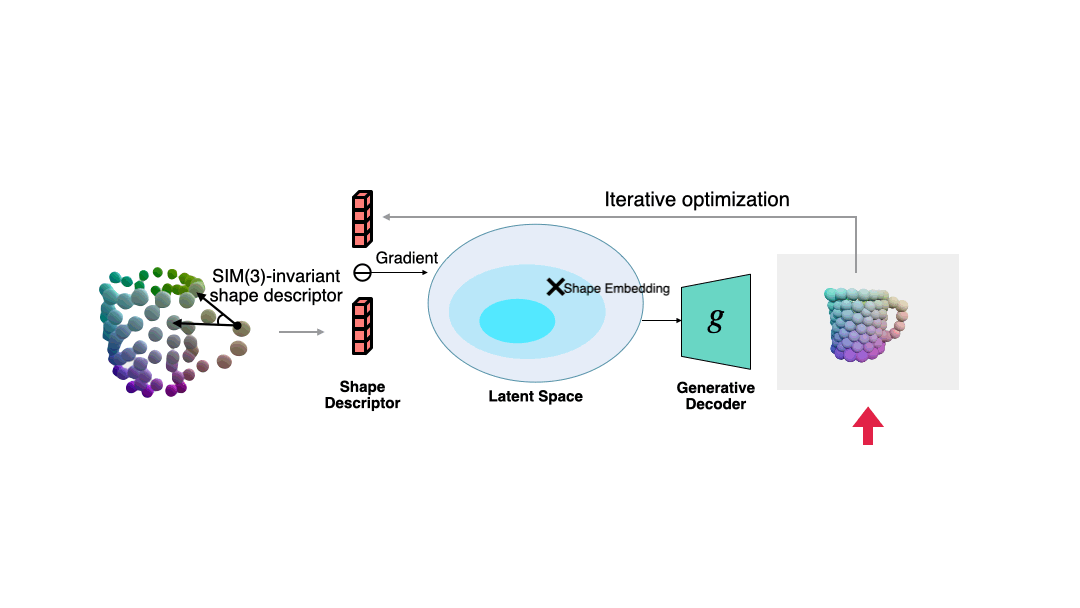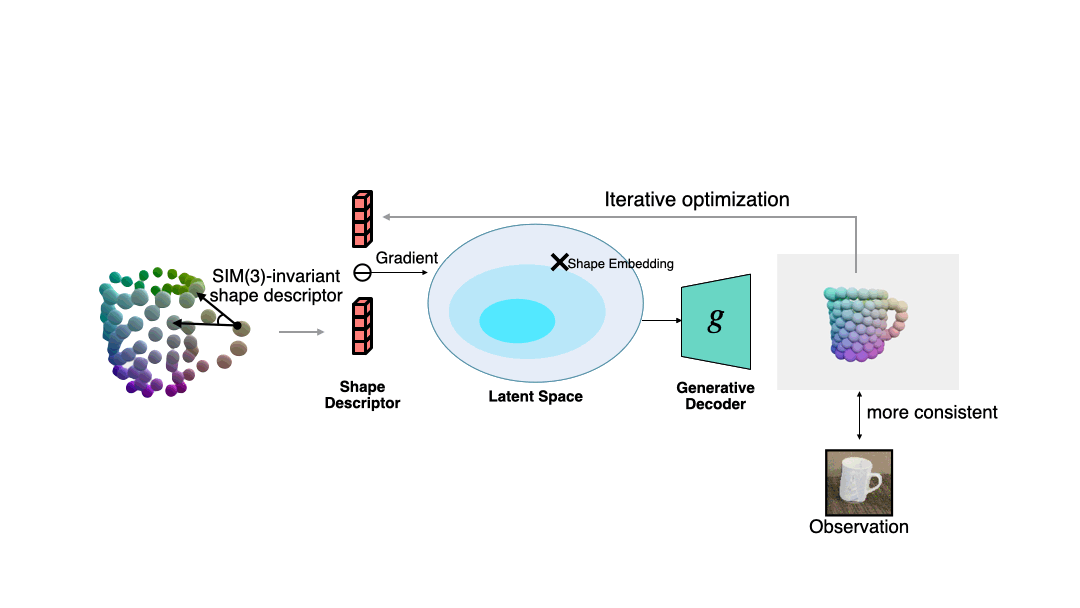
Der Autor hat REAL275 (realer Datensatz) in NOCS bereitgestellt und Es wurden Vergleichsexperimente mit dem Datensatz CAMERA25 (synthetischer Datensatz) durchgeführt und die Genauigkeit der Posenschätzung mit anderen Methoden verglichen. Die vorgeschlagene Methode übertraf andere Methoden bei mehreren Indikatoren bei weitem.
Gleichzeitig verglich der Autor auch die Menge der Parameter, die auf dem von NOCS bereitgestellten Trainingssatz trainiert werden müssen. Der Autor benötigt mindestens 2,3 Millionen Parameter, um das State-of-the-Art-Niveau zu erreichen. 
Das obige ist der detaillierte Inhalt vonNur 10 % der Parameter werden benötigt, um SOTA zu übertreffen! Die Zhejiang University, Byte und Hong Kong Chinese schlugen gemeinsam einen neuen Rahmen für die Aufgabe „Posenschätzung auf Kategorieebene' vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr