
Heim >Technologie-Peripheriegeräte >KI >Wie man KI-Malerei spielt, die dieses Jahr sehr beliebt ist
Wie man KI-Malerei spielt, die dieses Jahr sehr beliebt ist

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-17 11:25:021316Durchsuche
1. Vorwort
2022 kann man definitiv als das erste Jahr von AIGC bezeichnen. Den Google-Suchtrends nach zu urteilen, wird das Suchvolumen für KI-Malerei und KI-generierte Kunst im Jahr 2022 stark ansteigen.
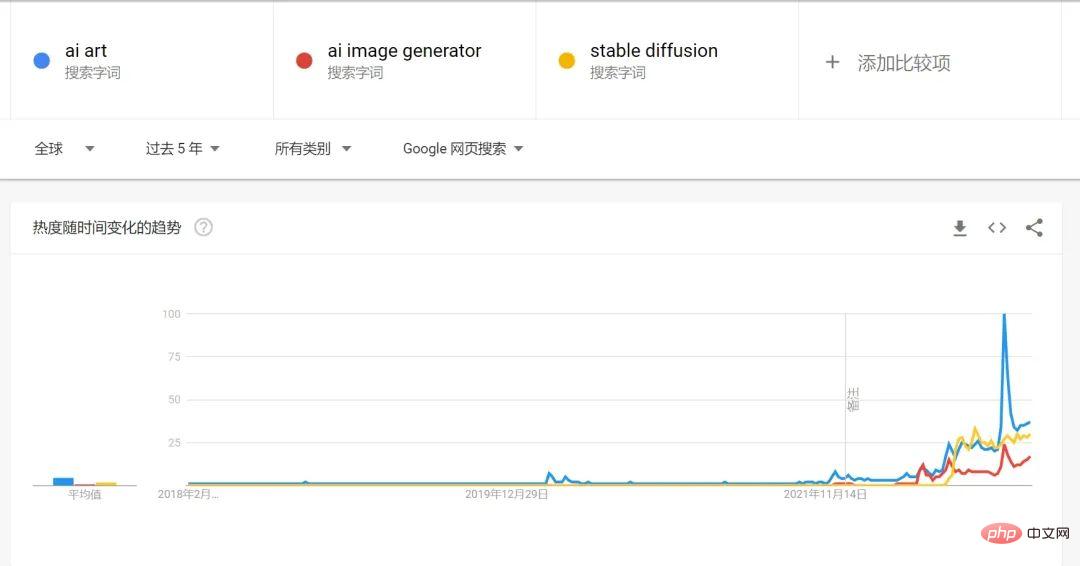
Ein sehr wichtiger Grund für die Explosion der KI-Malerei in diesem Jahr ist die Open Source von Stable Diffusion auch in der Nähe Neben der rasanten Entwicklung des Diffusionsmodells in den letzten Jahren ist in Kombination mit dem bereits entwickelten Textsprachenmodell GPT-3 von OPENAI der Generierungsprozess von Text zu Bildern einfacher geworden.
2. Der Engpass von GAN (Generative Adversarial Network)
Von seiner Geburt im Jahr 2014 bis zu StyleGAN im Jahr 2018 hat GAN große Fortschritte im Bereich der Bildgenerierung gemacht. So wie Raubtiere und Beute in der Natur miteinander konkurrieren und sich entwickeln, besteht das Prinzip von GAN einfach darin, zwei neuronale Netze zu verwenden: eines als Generator und eines als Diskriminator. Der Generator erzeugt unterschiedliche Bilder, damit der Diskriminator beurteilen kann, ob das Ergebnis qualifiziert ist oder nicht, die beiden treten gegeneinander an, um das Modell zu trainieren.
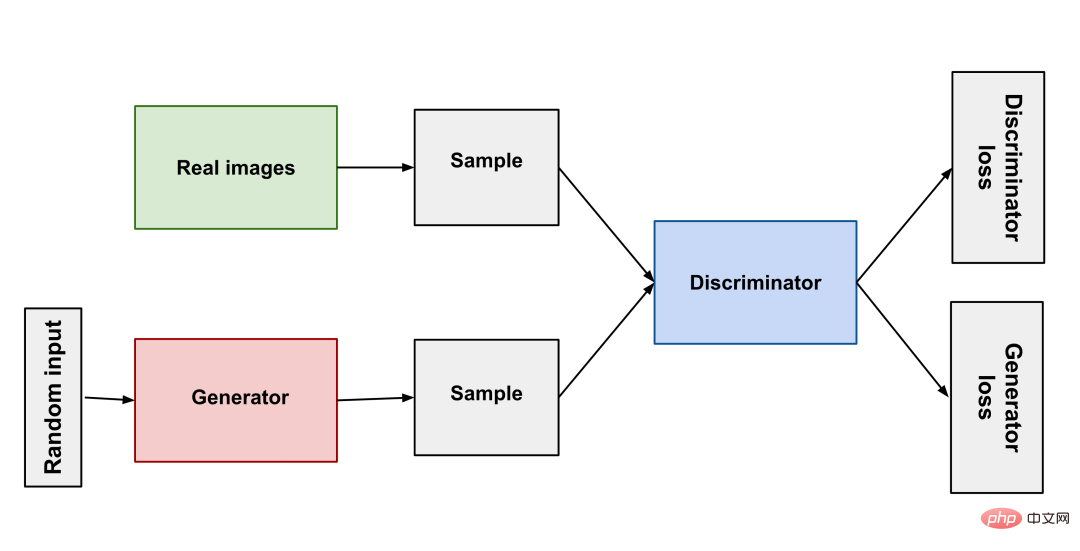
GAN (Generative Adversarial Network) hat durch kontinuierliche Weiterentwicklung gute Ergebnisse erzielt, aber einige Probleme sind immer schwer zu überwinden . Probleme: Mangelnde Vielfalt bei den generierten Ergebnissen, Moduszusammenbruch (der Generator macht keine Fortschritte, nachdem er den besten Modus gefunden hat) und hohe Trainingsschwierigkeiten. Diese Schwierigkeiten haben es der KI-generierten Kunst erschwert, praktische Produkte zu produzieren.
3. Durchbruch beim Diffusionsmodell
Nach Jahren der Engpässe im GAN haben Wissenschaftler die sehr erstaunliche Diffusionsmodell-Methode entwickelt: Verwenden Sie eine Markov-Kette, um kontinuierlich zu arbeiten Fügen Sie dem Originalbild Rauschpunkte hinzu, die schließlich zu einem zufälligen Rauschbild werden, und lassen Sie dann das trainierte neuronale Netzwerk diesen Vorgang umkehren und das zufällige Rauschbild schrittweise zum Originalbild wiederherstellen, sodass das neuronale Netzwerk Man kann sagen, dass es das hat Möglichkeit, Bilder von Grund auf zu erstellen. Um Bilder aus Text zu generieren, wird der Beschreibungstext verarbeitet und als Rauschen zum Originalbild hinzugefügt. Dadurch kann das neuronale Netzwerk Bilder aus Text generieren.

Diffusionsmodell (Diffusionsmodell) erleichtert das Training des Modells, es sind lediglich eine große Anzahl von Bildern erforderlich Auch die Qualität der erzeugten Bilder kann ein sehr hohes Niveau erreichen und die erzeugten Ergebnisse können sehr vielfältig sein. Aus diesem Grund kann die neue Generation der KI eine unglaubliche „Fantasie“ haben.
Natürlich hat die von Nvidia Ende Januar veröffentlichte aktualisierte Version von StyleGAN-T erstaunliche Fortschritte gemacht und erzeugt ein Bild mit der gleichen Rechenleistung Bilder dauern 3 Sekunden, StyleGAN-T dauert nur 0,1 Sekunden. Und StyleGAN-T ist bei Bildern mit niedriger Auflösung besser als das Diffusionsmodell, aber bei der Erzeugung von Bildern mit hoher Auflösung dominiert das Diffusionsmodell immer noch. Da StyleGAN-T nicht so weit verbreitet ist wie Stable Diffusion, konzentriert sich dieser Artikel auf die Einführung von Stable Diffusion.
4, Stable Diffusion
Anfang dieses Jahres erlebte der KI-Malkreis die Ära von Disco Diffusion, DALL-E2 und Midjouney, bis Stable Diffusion Open Source war , Der Staub hat sich gerade für eine gewisse Zeit gelegt. Als leistungsstärkstes KI-Malmodell hat Stable Diffusion einen Karneval in der KI-Community ausgelöst. Im Grunde werden jeden Tag neue Modelle und neue Open-Source-Bibliotheken geboren. Insbesondere nach der Einführung der WebUI-Version von Auto1111 ist die Verwendung von Stable Diffusion zu einer sehr einfachen Sache geworden, egal ob in der Cloud oder lokal bereitgestellt. Durch die kontinuierliche Weiterentwicklung der Community sind viele hervorragende Projekte wie Dreambooth und Deforum zu Stable geworden. Für die Diffusion WEBUI-Version wurde ein Plug-in hinzugefügt, mit dem Funktionen wie die Feinabstimmung von Modellen und die Erstellung von Animationen in einem Schritt ausgeführt werden können.
5. Einführung in das Gameplay und die Fähigkeiten der KI-Malerei
Das Folgende ist eine Einführung zur aktuellen Verwendung von Stable Welche Art von Gameplay und Fähigkeiten kann Diffusion haben? 🎜#
Einführung |
Eingabe |
Ausgabe#🎜 🎜 # |
|||
| text2img | Generieren Sie Bilder durch Textbeschreibung, und Sie können den Künstler angeben durch Textbeschreibung Stil, Art der Kunst. Hier ist ein Beispiel im Stil des Künstlers Greg Rutkowski. | ein wunderschönes Mädchen mit einem geblümten Hemd, das für ein Foto posiert, wobei das Kinn auf der rechten Hand ruht, von Greg Rutkowski#🎜🎜 # |
# 🎜🎜#
| img2img||
durch Bilder und Text Beschreibung Bild generieren |
ein wunderschönes Mädchen mit einem geblümten Hemd, das für ein Foto posiert, das Kinn auf der rechten Hand, von Greg Rutkowski |
|
ein wunderschönes Mädchen mit einem geblümten Hemd, das sanft lächelt und für ein Foto posiert, das Kinn auf der rechten Hand, von Greg Rutkowski |
||
|
|
. |
||||
verwenden DreamBooth ist ein fein abgestimmtes großes Modell, das auf dem SD-Modelltraining basiert. Nach dem Training kann das Modell die oben genannten Funktionen von text2img img2img und andere verwenden Derzeit wird NAI auf der Grundlage öffentlicher Bilder von der danbooru-Website als Datensatz trainiert. Aufgrund von Urheberrechtsproblemen auf danbooru selbst war NovelAI jedoch relativ umstritten und das Modell wurde von kommerziellen Diensten durchgesickert mit Vorsicht. | |||||
| NovelAI
|
|||||
|
AI Painting |
|
Subjektmodell basierend auf Benutzerfotos trainiert |
Trainieren Sie ein Modell für das Motiv basierend auf mehreren vom Benutzer bereitgestellten Fotos. Dieses Modell kann verwendet werden, um jedes Bild zu generieren, das das Motiv basierend auf der Beschreibung enthält. |
Dieser Bildersatz verwendet 20 Fotos von Kollegen, um ein 2000-Stepout-Modell basierend auf dem Stable Diffusion 1.5-Modell mit mehreren stilisierten Eingabeaufforderungsausgaben zu trainieren. Prompt-Beispiel (Abbildung 1): Porträt von Alicepoizon, sehr detailliertes VFX-Porträt, Unreal Engine, Greg Rutkowski, Loish, Rhads, Caspar David Friedrich, Makoto Shinkai und Lois Van Baarle, Ilya Kuvshinov, Rossdraws, Elegent, Tom Bagshaw , Alphonse Mucha, globale Beleuchtung, detaillierte und komplizierte Umgebung *Alicepoizon ist der Name, der dieser Figur beim Training dieses Modells gegeben wurde |
.
Dieser Bildersatz wird mit dem fein abgestimmten Stilmodell erstellt, das von der Dewu Digital Collection ME.X trainiert wurde. |
|
|
|||||
|
| |||||
|
|
|||||
Scarlett Johansson |
|
||||


 #🎜. 🎜# #? ## 🎜🎜#
#🎜. 🎜# #? ## 🎜🎜#









6. Einführung in die aktuellen Hauptanwendungen
| Einführung | Beispiel # 🎜 🎜# |
|||
| #🎜🎜 # Bereitstellung ein komfortableres KI-Malerlebnis und Sie können viele benutzerdefinierte große Modelle mit unterschiedlichen Stilen verwenden. |
|
|||
|
| bietet den vorherigen Dreambooth + Stable Diffusion-Service, etwa 18-25 Yuan pro Zeit, laden Sie 15-20 Benutzerfotos hoch und erstellen Sie etwa 20 benutzerdefinierte Kunstfotos. ||||
|
# 🎜 🎜#
|
https://www.php.cn/link/81d7118d88d5570189ace943bd14f142 Die aktuelle Mainstream-KI-Open-Source-Community hat, ähnlich wie Github, eine große Anzahl von Benutzern, die eine Feinabstimmung (Feinabstimmung) vorgenommen haben. Stabile Diffusionsmodelle, die heruntergeladen und auf Ihrem eigenen Server oder lokalen Computer bereitgestellt werden können. Zum Beispiel ist das pix2pix-Modell auf der rechten Seite ein stabiles Diffusionsmodell in Kombination mit GPT3, das die oben erwähnte Inpainting-Funktion durch Beschreibung in natürlicher Sprache vervollständigen kann. |
|

 #🎜. 🎜#
#🎜. 🎜# 

7. Erstellen Sie Ihren eigenen Stable Diffusion WEBUI-Dienst
7.1 Cloud Version
wird hier mit der von AutoDL bereitgestellten Cloud-Computing-Leistung erstellt. Sie können auch andere Plattformen wie Google Colab oder Baidu Fei Paddle verwenden.
- Registrieren Sie zunächst ein Konto bei AutoDL und mieten Sie einen Cloud-Host mit einer A5000/RTX3090-Grafikkarte. https://www.autodl.com/market/list
- Erstellen Sie ein Bild auf diesem Host. Für das Bild können Sie das gepackte Algorithmusbild auf www.codewithgpu.com auswählen. Hier nehmen wir das Bild https://www.codewithgpu.com/i/AUTOMATIC1111/stable-diffusion-webui/Stable-Diffusion-for-NovelAI. Wählen Sie es aus und erstellen Sie es.
- Nach der Erstellung schalten Sie JupterLab ein und starten es.

Führen Sie den folgenden Befehl aus, um den Dienst zu starten. Wenn Sie feststellen, dass nicht genügend Speicherplatz auf der Systemfestplatte vorhanden ist, können Sie auch den Ordner „stable-diffusion-webui/“ auf die Datenfestplatte verschieben und autodl-tmp neu starten. Wenn beim Start ein Fehler auftritt, können Sie die Beschleunigung akademischer Ressourcen entsprechend dem Standort Ihres Computers konfigurieren.
cd stable-diffusion-webui/ rm -rf outputs && ln -s /root/autodl-tmp outputs python launch.py --disable-safe-unpickle --port=6006 --deepdanbooru
6.2 本地版本
Wenn Sie einen Computer mit einer guten Grafikkarte haben, können Sie diese lokal bereitstellen. Hier ist eine Einführung zum Erstellen der Windows-Version:
- Zuerst müssen Sie Python 3.10.6 installieren und Umgebungsvariablen hinzufügen der Pfad
- Installation git
- Klonen Sie den Stable Diffusion WEBUI-Projektcode auf lokal
- Platzieren Sie die Modelldatei im Verzeichnis models/Stable-Diffusion. Verwandte Modelle können von https://www.php.cn/link/81d7118d88d5570189ace943bd14f142 heruntergeladen werden
- Führen Sie webui-user.bat aus und greifen Sie über die lokale Computer-IP und den Port 7860 auf den Dienst zu.
8. Zusammenfassung
In diesem Artikel werden einige relevante Informationen zum Thema KI-Malerei vorgestellt. Interessierte Freunde können den Dienst auch selbst einsetzen und versuchen, die Verwendung von DreamBooth oder der neuesten Version von Lora zur Feinabstimmung großer Modelle zu erlernen. Ich glaube, dass im Jahr 2023, da die Popularität von AIGC weiter zunimmt, unsere Arbeit und unser Leben durch KI stark verändert werden. Der Start von ChatGPT hat uns vor einiger Zeit sehr schockiert. Ebenso wie die Fähigkeit, nach Informationen zu suchen, als wir zum ersten Mal im Internet waren, wird auch das Erlernen der Nutzung von KI zur Unterstützung unserer Arbeit in Zukunft eine sehr wichtige Fähigkeit sein.
9. Referenzen
- Lassen Sie uns im ersten Jahr der generativen KI-Kunst über KI sprechen Ein vorläufiges Verständnis von GAN und Diffusion hinter der Malerei
https://blog.csdn.net/qq_45848817/article/details/127808815
- Wie Diffusionsmodelle funktionieren: die Mathematik von Grund auf
https://theaisummer. com/diffusion-models/
- GAN-Strukturübersicht using through ' s ' through ' s ' durch . https://www.entrogames.com/2022/08/absolute - beginners-guide-to-midjourney- magical-introduction-to-ai-art/
Die virale KI-Avatar-App Lensa hat mich ausgezogen – ohne meine Zustimmung
- https://www.technologyreview.com/2022/12/ 12/1064751/the-viral-ai-avatar-app-lensa-abgesundet-me-without-my-conent/
instruct-pix2pix
https://www.php.cn/link/81d7118d88d5570189ace943bd14f142tims/inStractwork943bd14f142timStactwork943bd14f142tums -pix2pixDas obige ist der detaillierte Inhalt vonWie man KI-Malerei spielt, die dieses Jahr sehr beliebt ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr