
Heim >Technologie-Peripheriegeräte >KI >Warum ChatGPT und Bing Chat so gut darin sind, Geschichten zu erzählen
Warum ChatGPT und Bing Chat so gut darin sind, Geschichten zu erzählen

- PHPznach vorne
- 2023-04-17 08:37:021408Durchsuche

Warum erfinden KI-Chatbots zufällige Dinge und können wir ihrer Ausgabe voll und ganz vertrauen? Zu diesem Zweck haben wir einige Experten gefragt Um das herauszufinden, haben wir uns eingehend mit der Funktionsweise dieser KI-Modelle befasst.
„Illusion“ – ein voreingenommener Begriff in der künstlichen Intelligenz
KI-Chatbots wie ChatGPT von OpenAI basieren auf der künstlichen Intelligenz eines sogenannten „großen Sprachmodells“ (LLM). generieren ihre Antworten. LLM ist ein Computerprogramm, das auf Millionen von Textquellen trainiert wurde, um Textsprache in „natürlicher Sprache“ zu lesen und zu erzeugen, so wie Menschen auf natürliche Weise schreiben oder sprechen. Leider machen sie auch Fehler.
In der akademischen Literatur nennen KI-Forscher diese Fehler oft „Halluzinationen“. Mit zunehmender Verbreitung des Themas wird die Bezeichnung immer kontroverser, da einige glauben, dass sie KI-Modelle anthropomorphisiert (was darauf hindeutet, dass sie menschenähnliche Eigenschaften haben) oder sie KI-Modellen zuordnet, wenn dies nicht impliziert werden sollte (was impliziert). dass sie ihre eigenen Entscheidungen treffen können). Darüber hinaus nutzen die Entwickler kommerzieller LLMs möglicherweise auch Illusionen als Vorwand, um dem KI-Modell die Schuld für fehlerhafte Ergebnisse zu geben, anstatt die Verantwortung für die Ergebnisse selbst zu übernehmen.
Dennoch ist generative KI ein sehr neues Feld, und wir müssen Metaphern aus bestehenden Ideen übernehmen, um diese hochtechnischen Konzepte der breiten Öffentlichkeit zu erklären. In diesem Fall sind wir der Meinung, dass das Wort „Konfabulation“, obwohl es ebenso unvollkommen ist, eine bessere Metapher ist als die Metapher „Halluzination“. In der menschlichen Psychologie bezieht sich „Fiktion“ auf eine Lücke im Gedächtnis einer Person, und das Gehirn füllt die vergessene Erfahrung mit einer überzeugenden fiktiven Tatsache aus, ohne andere absichtlich zu täuschen. ChatGPT funktioniert nicht wie das menschliche Gehirn, aber der Begriff „Fiktion“ ist wohl eine bessere Metapher, da es auf dem Prinzip basiert, Lücken kreativ zu schließen (anstatt absichtlich zu täuschen), was wir weiter unten untersuchen werden.
fictionquestion
Es ist ein großes Problem, wenn KI-Bots falsche Informationen produzieren, die irreführend oder diffamierend wirken können. Kürzlich berichtete die Washington Post über einen Juraprofessor, der herausfand, dass ChatGPT ihn auf eine Liste von Rechtswissenschaftlern gesetzt hatte, die andere sexuell belästigt hatten. Aber diese Angelegenheit ist falsch und vollständig von ChatGPT erfunden. Am selben Tag berichtete Ars auch, dass ein australischer Bürgermeister herausgefunden habe, dass die Behauptung von ChatGPT, er sei wegen Bestechung verurteilt und inhaftiert worden, ebenfalls völlig erfunden sei.
ChatGPT Kurz nach dem Start begann man, das Ende von Suchmaschinen zu befürworten. Gleichzeitig begannen jedoch viele fiktive Fälle von ChatGPT in den sozialen Medien weit verbreitet zu kursieren. KI-Bots erfanden nicht existierende Bücher und Studien, Veröffentlichungen, die nicht von Professoren verfasst wurden, gefälschte wissenschaftliche Arbeiten, gefälschte juristische Zitate, nicht existierende Linux-Systemfunktionen, unwirkliche Einzelhandelsmaskottchen und bedeutungslose technische Details.
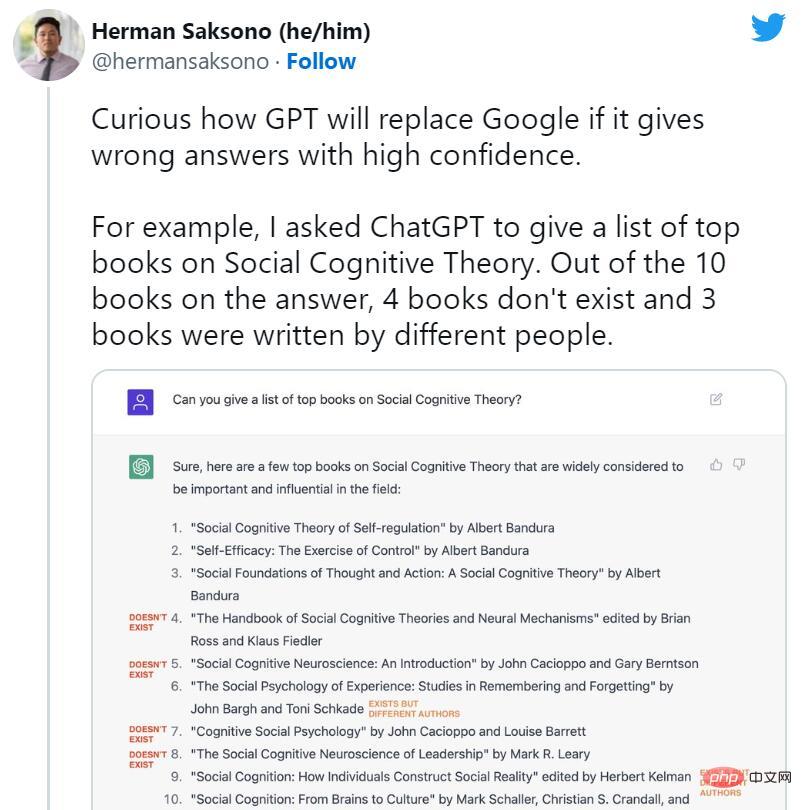
Trotz der Neigung von ChatGPT zu gelegentlichen Lügen ist die Unterdrückung von Fiktion genau das, worüber wir heute sprechen seine Gründe. Einige Experten weisen darauf hin, dass ChatGPT technisch gesehen eine Verbesserung gegenüber dem regulären GPT-3 (sein Vorgängermodell) darstellt, da es die Beantwortung einiger Fragen verweigern oder Sie informieren kann, wenn die Antworten möglicherweise ungenau sind.
Riley Goodside, Experte für große Sprachmodelle und Prompt-Ingenieur bei Scale AI, sagte: „Ein wesentlicher Faktor für den Erfolg von ChatGPT ist, dass es Fiktion erfolgreich unterdrückt und viele häufig gestellte Fragen unaufdringlich macht. Hinweis: ChatGPT ist erheblich.“ Wenn es als Brainstorming-Tool verwendet wird, können die logischen Sprünge und Fantasien von ChatGPT zu kreativen Durchbrüchen führen. Aber wenn ChatGPT als sachliche Referenz verwendet wird, kann es echten Schaden anrichten, und OpenAI weiß das.
Kurz nach der Veröffentlichung des Modells schrieb OpenAI-CEO Sam Altman auf Twitter: „ChatGPT ist in der Funktionalität sehr eingeschränkt, aber in einigen Aspekten gut genug, um einen tollen irreführenden Eindruck zu erwecken. Es wäre ein Fehler.“ dass wir uns jetzt bei allem Wichtigen darauf verlassen können; wir haben noch viel Arbeit vor uns, was Robustheit und Authentizität angeht.“ In einem späteren Tweet schrieb er: „Es weiß zwar viel, aber die Gefahr besteht darin, dass es blind ist.“ und in den meisten Fällen falsch GPT-Modelle wie ChatGPT oder Bing Chat führen „Fiktion“ aus. Wir müssen wissen, wie GPT-Modelle funktionieren. Während OpenAI noch keine technischen Details zu ChatGPT, Bing Chat oder sogar GPT-4 veröffentlicht hat, erwarten wir, dass im Jahr 2020 Forschungsarbeiten zur Einführung von GPT-3 (ihrem Vorgänger) erscheinen werden.
Forscher erstellen (trainieren) große Sprachmodelle wie GPT-3 und GPT-4 mithilfe eines Prozesses namens „unüberwachtes Lernen“, was bedeutet, dass die Daten, die sie zum Trainieren des Modells verwenden, nicht speziell annotiert oder gekennzeichnet sind. In diesem Prozess wird das Modell mit einer großen Textmenge (Millionen Bücher, Websites, Artikel, Gedichte, Manuskripte und andere Quellen) gefüttert und versucht wiederholt, das nächste Wort in jeder Wortfolge vorherzusagen. Wenn die Vorhersage des Modells nahe am tatsächlichen nächsten Wort liegt, aktualisiert das neuronale Netzwerk seine Parameter, um das Muster zu verstärken, das zu dieser Vorhersage geführt hat.
Wenn umgekehrt die Vorhersage falsch ist, passt das Modell die Parameter an, um die Leistung zu verbessern, und versucht es erneut. Obwohl es sich bei diesem Prozess des Versuchs und Irrtums um eine sogenannte Backpropagation-Technik handelt, kann das Modell aus seinen Fehlern lernen und seine Vorhersagen während des Trainings schrittweise verbessern.
Daher lernt GPT den statistischen Zusammenhang zwischen Wörtern und verwandten Konzepten im Datensatz. Einige, wie der Chefwissenschaftler von OpenAI, Ilya Sutskever, glauben, dass das GPT-Modell darüber hinausgeht und ein internes Modell der Realität aufbaut, damit sie den nächstbesten Token genauer vorhersagen können, aber diese Idee ist umstritten. Die genauen Details, wie das GPT-Modell den nächsten Token in seinem neuronalen Netzwerk vorschlägt, bleiben ungewiss.

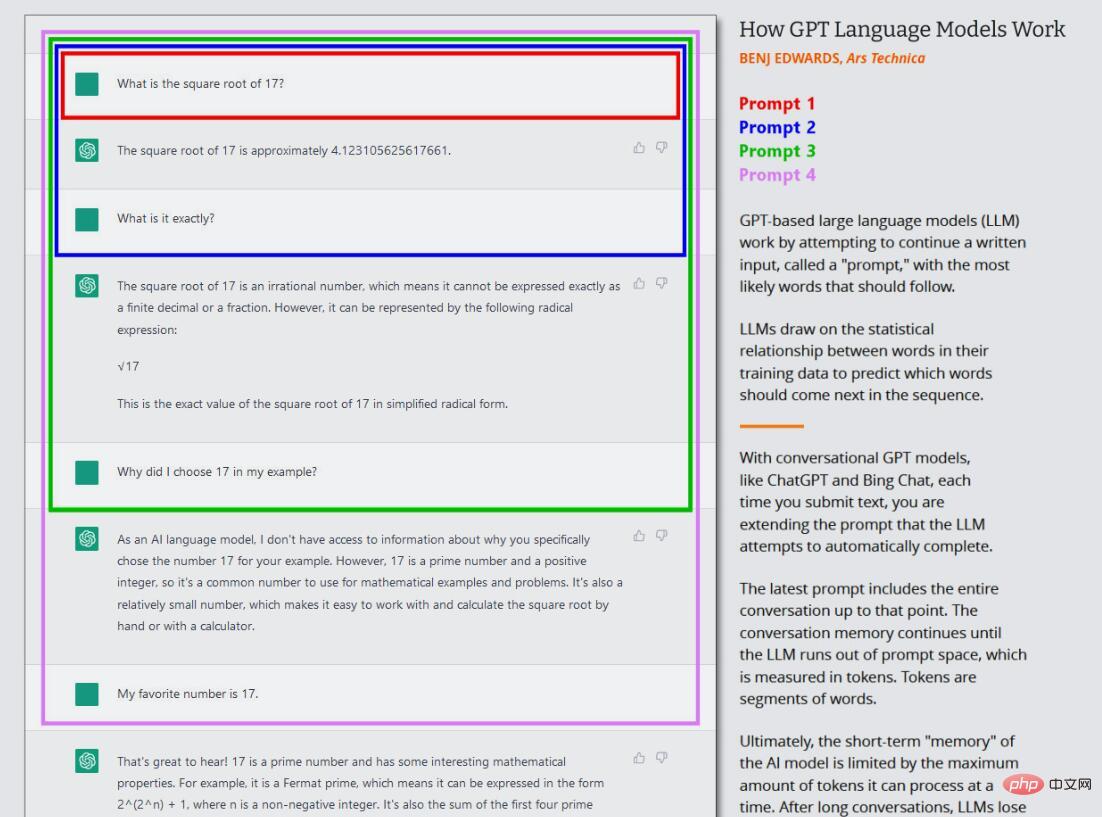
In der aktuellen Welle der GPT-Modelle findet dieses Kerntraining (heute oft „Vortraining“ genannt) nur einmal statt. Danach kann man das trainierte neuronale Netzwerk im „Inferenzmodus“ verwenden, der es dem Benutzer ermöglicht, Eingaben in das trainierte Netzwerk einzuspeisen und die Ergebnisse zu erhalten. Während der Inferenz wird die Eingabesequenz für das GPT-Modell immer von einem Menschen bereitgestellt, was als „Eingabeaufforderung“ bezeichnet wird. Die Eingabeaufforderung bestimmt die Ausgabe des Modells, und eine geringfügige Änderung der Eingabeaufforderung kann die vom Modell erzeugten Ergebnisse drastisch verändern.
Wenn Sie beispielsweise GPT-3 „Mary had a... (Mary had a)“ auffordern, wird der Satz normalerweise mit „little lamb“ vervollständigt. Dies liegt daran, dass es im Trainingsdatensatz von GPT-3 wahrscheinlich Zehntausende Beispiele für „Mary hatte ein kleines Lamm“ gibt, was es zu einer vernünftigen Ausgabe macht. Wenn Sie der Eingabeaufforderung jedoch mehr Kontext hinzufügen, z. B. „Mary hatte im Krankenhaus ein Kind“, ändern sich die Ergebnisse und geben etwa das Wort „Baby“ oder „Testreihe“ zurück.
Das ist das Interessante an ChatGPT, denn es ist als Konversation mit einem Agenten konzipiert und nicht nur als direkte Textgenerierungsaufgabe. Im Fall von ChatGPT ist die Eingabeaufforderung die gesamte Konversation, die Sie mit ChatGPT führen, beginnend mit Ihrer ersten Frage oder Aussage, einschließlich aller spezifischen Anweisungen, die ChatGPT vor Beginn der simulierten Konversation bereitgestellt werden. Während dieses Vorgangs speichert ChatGPT ein Kurzzeitgedächtnis (ein sogenanntes „Kontextfenster“) über das ChatGPT und alles, was Sie geschrieben haben, und während es mit Ihnen „spricht“, versucht es, die Textgenerierungsaufgabe der Konversation abzuschließen.
Darüber hinaus unterscheidet sich ChatGPT von gewöhnlichem GPT-3 dadurch, dass es auch auf von Menschen geschriebene Konversationstexte trainiert wird. OpenAI schreibt auf seiner ersten ChatGPT-Veröffentlichungsseite: „Wir haben ein erstes Modell mithilfe einer überwachten Feinabstimmung trainiert: Menschliche KI-Trainer führen Gespräche durch, in denen sie als beide Parteien fungieren – als Benutzer und als KI-Assistent.“ Helfen Sie ihnen, ihre eigenen Antworten zu verfassen.“
ChatGPT verwendet für eine bessere Abstimmung auch eine Technik namens Reinforcement Learning with Human Feedback (RLHF). Bei dieser Technik ordnen menschliche Bewerter ChatGPT-Antworten basierend auf Präferenzen und geben diese Informationen dann in das Modell ein. Durch RLHF ist OpenAI in der Lage, dem Modell das Ziel zu vermitteln, „die Beantwortung von Fragen zu vermeiden, die nicht genau beantwortet werden können“. Dadurch kann ChatGPT konsistente Antworten mit weniger Fiktion als das Basismodell erzeugen. Dennoch können ungenaue Informationen durchschlüpfen.
Warum ChatGPT Fiktion produziert
Im Wesentlichen gibt es im Originaldatensatz des GPT-Modells nichts, was Fakten von Fiktion trennen könnte.
Das Verhalten von LLMs bleibt ein aktives Forschungsgebiet. Sogar die Forscher, die diese GPT-Modelle erstellt haben, entdecken immer noch überraschende Eigenschaften der Technologie, die bei ihrer ersten Entwicklung niemand vorhergesehen hatte. Die Fähigkeit von GPT, viele der interessanten Dinge zu tun, die wir heute sehen, wie etwa Sprachübersetzung, Programmierung und Schachspielen, überraschte die Forscher einst.
Wenn wir also fragen, warum ChatGPT Artefakte generiert, ist es schwierig, eine genaue technische Antwort zu finden. Da neuronale Netzwerkgewichte über ein „Black-Box“-Element verfügen, ist es schwierig (oder sogar unmöglich), ihre genaue Ausgabe bei einer komplexen Eingabeaufforderung vorherzusagen. Dennoch kennen wir einige grundlegende Gründe, warum es Fiktion gibt.
Der Schlüssel zum Verständnis der fiktiven Fähigkeiten von ChatGPT liegt darin, seine Rolle als Vorhersagemaschine zu verstehen. Beim Nachholen sucht ChatGPT nach Informationen oder Analysen, die nicht im Datensatz vorhanden sind, und füllt die Lücken mit plausibel klingenden Wörtern. ChatGPT ist aufgrund der schieren Datenmenge, die es verarbeiten muss, und seiner Fähigkeit, den Wortkontext so gut zu erfassen, besonders gut darin, Dinge zu erfinden, wodurch Fehlermeldungen nahtlos in den umgebenden Text eingefügt werden können.
Der Softwareentwickler Simon Willison sagte: „Ich denke, der beste Weg, über Fiktion nachzudenken, besteht darin, über die Natur großer Sprachmodelle nachzudenken: Das Einzige, was sie tun können, ist, das nächste basierend darauf auszuwählen.“ Der Trainingssatz basiert auf statistischer Wahrscheinlichkeit. Bestes Wort. Der erste Grund liegt in ungenauem Quellmaterial im Trainingsdatensatz, wie z. B. häufigen Missverständnissen (z. B. „Truthahn essen macht schläfrig“). Die zweite Möglichkeit besteht darin, Rückschlüsse auf bestimmte Situationen zu ziehen, die im Trainingsdatensatz nicht vorhanden sind. Dies fällt unter die zuvor erwähnte Bezeichnung „Halluzination“.
Ob ein GPT-Modell wilde Vermutungen anstellt, hängt davon ab, was KI-Forscher als „Temperatur“-Attribut bezeichnen, das oft als „Kreativitäts“-Einstellung beschrieben wird. Wenn die Kreativität hoch eingestellt ist, wird das Modell wilde Vermutungen anstellen; wenn sie niedrig eingestellt ist, wird es Daten basierend auf seinem Datensatz deterministisch ausspucken.
Kürzlich sprach Microsoft-Mitarbeiter Mikhail Parakhin auf Twitter über die Neigung von Bing Chat zu Halluzinationen und was Halluzinationen verursacht. Er schrieb: „Das ist es, was ich vorher zu erklären versucht habe: Illusion = Kreativität. Es wird versucht, mit allen Daten, die es verarbeitet, eine Fortsetzung der Zeichenfolge mit der höchsten Wahrscheinlichkeit zu erzeugen. Normalerweise ist es richtig. Manchmal haben Leute noch nie eine solche Fortsetzung gemacht.“# 🎜🎜#
Parakhin fügte hinzu, dass es diese verrückten kreativen Sprünge sind, die den Spaß am LLM ausmachen. Sie können die Halluzinationen unterdrücken, aber Sie werden es super langweilig finden. Weil es immer mit „Ich weiß nicht“ antwortet oder nur das zurückgibt, was in den Suchergebnissen steht (was manchmal auch falsch ist). Was jetzt fehlt, ist der Ton: Er sollte in diesen Situationen nicht so souverän wirken. ” Wenn es um die Feinabstimmung eines Sprachmodells wie ChatGPT geht, ist die Balance zwischen Kreativität und Genauigkeit eine Herausforderung. Einerseits macht die Fähigkeit, kreative Antworten zu finden, ChatGPT zu einem leistungsstarken Tool für die Generierung neuer Ideen oder die Beseitigung von Schreibengpässen. Dadurch klingt das Modell auch menschlicher. Andererseits ist die Genauigkeit des Quellmaterials von entscheidender Bedeutung für die Erstellung zuverlässiger Informationen und die Vermeidung von Fiktion , ist aber entscheidend für die Entwicklung eines Tools, das sowohl nützlich als auch vertrauenswürdig ist. Beim Training mit GPT-3 wurde auch das Problem der Komprimierung berücksichtigt, aber das resultierende neuronale Netzwerk war nur ein Bruchteil davon In einem vielgelesenen Artikel im New Yorker nannte der Autor Ted Chiang es ein „unscharfes JPEG des Webs“. Das bedeutet, dass die meisten tatsächlichen Trainingsdaten verloren gehen, aber GPT-3 gleicht dies aus, indem es Beziehungen zwischen Konzepten lernt, was es kann Später kann man diese Tatsachen neu formulieren, genau wie eine Person mit einem mangelhaften Gedächtnis. Manchmal geht sie aber auch schief, wenn sie die Antwort nicht kennt. Wir dürfen die Rolle von Aufforderungen in der Fiktion nicht vergessen, ChatGPT ist ein Spiegel: Was du ihm gibst, gibt es dir. Wenn du es mit Lügen fütterst, wird es dir tendenziell zustimmen. Denken Sie in diese Richtung. Deshalb ist es wichtig, bei einem Themenwechsel oder wenn Sie auf eine unerwünschte Antwort stoßen, mit einer neuen Eingabeaufforderung von vorne zu beginnen. ChatGPT ist probabilistisch, was bedeutet, dass die Ausgabe teilweise zufälliger Natur ist, selbst bei derselben Eingabeaufforderung . Änderungen zwischen den Sitzungen. All dies führt zu einer Schlussfolgerung, der OpenAI zustimmt: ChatGPT ist in seiner derzeitigen Form keine zuverlässige Quelle für sachliche Informationen und kann von Dr . Margaret Mitchell, Forscherin und leitende Ethikwissenschaftlerin bei Hugging Face, glaubt, dass „ChatGPT für bestimmte Dinge sehr nützlich sein kann, etwa um Schreibblockaden zu überwinden oder kreative Ideen zu entwickeln.“ Es wurde nicht für die Wahrheit gebaut und kann daher keine Wahrheit sein. So einfach ist das. ” Kann Lügen korrigiert werden? Es ist ein Fehler, KI-Chatbots blind zu vertrauen, aber das kann sich ändern, wenn sich die zugrunde liegende Technologie verbessert. Seit seiner Veröffentlichung im November wurde mehrmals aktualisiert, einige davon umfassen Verbesserungen bei der Genauigkeit und die Möglichkeit, die Beantwortung von Fragen zu verweigern, auf die die Antwort nicht bekannt ist. Wie will OpenAI ChatGPT genauer machen? Wir haben OpenAI in der Vergangenheit mehrmals kontaktiert Einige Monate lang haben wir uns mit diesem Problem befasst und keine Antwort erhalten, aber wir können den von OpenAI veröffentlichten Dokumenten und den Nachrichtenberichten entnehmen, dass das Unternehmen versucht, ChatGPT dazu zu bringen, sich an menschliche Mitarbeiter anzupassen.
Wie bereits erwähnt, liegt einer der Gründe, warum ChatGPT so erfolgreich ist, in der umfangreichen Schulung mit RLHF. OpenAI erklärt: „Um unsere Modelle sicherer, hilfreicher und konsistenter zu machen, nutzen wir eine bestehende Technologie namens ‚Reinforcement Learning with Human Feedback (RLHF).‘ Gemäß den von Kunden an die API übermittelten Tipps bietet unser Tagger eine Demonstration davon.“ „Das gewünschte Modellverhalten und die Sortierung mehrerer Ausgaben aus dem Modell. Wir verwenden diese Daten dann zur Feinabstimmung von GPT-3“, sagt Sutskever von OpenAI, der das Halluzinationsproblem lösen kann. Sutskever sagte zu Forbes Anfang des Monats: „Ich hoffe sehr, dass ich durch die einfache Verbesserung dieses Nachfolge-RLHF lernen werde, nicht zu halluzinieren.“ Er fuhr fort: „Was wir heute getan haben, ist der Weg dazu.“ Das heißt, wir stellen Leute ein, die unserem neuronalen Netzwerk beibringen, wie es reagieren soll. Sie interagieren einfach damit und es wird an Ihrer Reaktion erkennen, dass es nicht das ist, was Sie wollen Mit der Ausgabe ist die Ausgabe also nicht sehr gut. Ich denke, das ist eine große Änderung und dieser Ansatz wird das Halluzinationsproblem vollständig lösen. Yann LeCun, Chefwissenschaftler für künstliche Intelligenz bei Meta, glaubt, dass das aktuelle LLM, das die GPT-Architektur verwendet, das Halluzinationsproblem nicht lösen kann. Es gibt jedoch eine neue Methode, die LLM unter der aktuellen Architektur möglicherweise eine höhere Genauigkeit verleiht. Er erklärt: „Einer der am intensivsten erforschten Ansätze zur Erhöhung des Realismus im LLM ist die Retrieval-Augmentation – die Bereitstellung externer Dokumente als Quellen und unterstützender Kontext für das Modell. Mit dieser Technik hoffen die Forscher, dem Modell beizubringen, externe Dokumente wie die Google-Suche zu verwenden.“ Suchmaschinen zitieren wie menschliche Forscher in ihren Antworten zuverlässige Quellen und verlassen sich weniger auf unzuverlässiges Faktenwissen, das sie während des Modelltrainings gelernt haben. „
Bing Chat und Google Bard erreichen dies bereits mit der Websuche. Bald wird dies auch eine browserfähige Version von ChatGPT tun umgesetzt werden. Darüber hinaus soll das ChatGPT-Plugin die Trainingsdaten von GPT-4 ergänzen, indem es Informationen aus externen Quellen wie dem Internet und speziell erstellten Datenbanken abruft. Diese Verbesserung ist vergleichbar damit, dass Personen mit einer Enzyklopädie Fakten genauer beschreiben als Personen ohne Enzyklopädie.
Außerdem ist es möglich, ein Modell wie GPT-4 zu trainieren, um zu erkennen, wann es Dinge erfindet, und sich entsprechend anzupassen. Mitchell glaubt, dass „die Leute einige tiefgreifendere Dinge tun könnten, um ChatGPT und ähnliches von Anfang an realistischer zu machen, einschließlich einer ausgefeilteren Datenverwaltung und der Verwendung eines PageRank-ähnlichen Ansatzes, um Trainingsdaten mit ‚Vertrauen‘ in Einklang zu bringen. Die Ergebnisse sind verknüpft.“ ... und das Modell kann auch feinabgestimmt werden, um das Risiko abzusichern, wenn es weniger zuversichtlich ist, was die Antworten angeht.“
 Während ChatGPT derzeit mit seinen fiktiven Problemen zu kämpfen hat, gibt es möglicherweise einen Ausweg, wie die More and Immer mehr Menschen verlassen sich auf diese Tools als grundlegende Assistenten, und ich glaube, dass es bald zu Verbesserungen bei der Zuverlässigkeit kommen sollte.
Während ChatGPT derzeit mit seinen fiktiven Problemen zu kämpfen hat, gibt es möglicherweise einen Ausweg, wie die More and Immer mehr Menschen verlassen sich auf diese Tools als grundlegende Assistenten, und ich glaube, dass es bald zu Verbesserungen bei der Zuverlässigkeit kommen sollte.
Das obige ist der detaillierte Inhalt vonWarum ChatGPT und Bing Chat so gut darin sind, Geschichten zu erzählen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr