
Heim >Technologie-Peripheriegeräte >KI >Das Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun
Das Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-16 23:43:011930Durchsuche
Im Jahr 2023 scheint es im Chatbot-Bereich nur noch zwei Lager zu geben: „OpenAI's ChatGPT“ und „Andere“.
ChatGPT ist leistungsstark, aber es ist für OpenAI fast unmöglich, es als Open Source zu veröffentlichen. Das „andere“ Lager schnitt schlecht ab, aber viele Leute arbeiten an Open Source, wie zum Beispiel LLaMA, das vor einiger Zeit von Meta als Open Source bereitgestellt wurde.
LLaMA ist der allgemeine Name für eine Reihe von Modellen mit Parametergrößen im Bereich von 7 Milliarden bis 65 Milliarden. Darunter ist das LLaMA-Modell mit 13 Milliarden Parametern am weitesten verbreitet Benchmarks" Es kann GPT-3 mit 175 Milliarden Parametern übertreffen. Das Modell wurde jedoch keiner Anweisungsoptimierung (Anweisungsoptimierung) unterzogen, sodass der Generierungseffekt schlecht ist.
Um die Leistung des Modells zu verbessern, halfen Forscher aus Stanford bei der Feinabstimmung der Anweisungen und trainierten ein neues 7-Milliarden-Parameter-Modell namens Alpaca Model (basierend auf LLaMA 7B). Konkret baten sie das text-davinci-003-Modell von OpenAI, 52.000 Beispiele für die Befehlsfolge als Trainingsdaten für Alpaca selbst zu generieren. Experimentelle Ergebnisse zeigen, dass viele Verhaltensweisen von Alpakas denen von text-davinci-003 ähneln. Mit anderen Worten: Die Leistung des leichten Modells Alpaca mit nur 7B-Parametern ist vergleichbar mit der von sehr großen Sprachmodellen wie GPT-3.5.

Für normale Forscher ist dies eine praktische und kostengünstige Möglichkeit zur Feinabstimmung, aber es erfordert viel Berechnungen Die Menge ist immer noch groß (der Autor sagte, sie hätten sie für 3 Stunden auf acht 80-GB-A100 optimiert). Darüber hinaus sind die Seed-Aufgaben von Alpaca alle auf Englisch und die gesammelten Daten sind auch auf Englisch, sodass das trainierte Modell nicht für Chinesisch optimiert ist.
Um die Kosten für die Feinabstimmung weiter zu senken, nutzte ein anderer Forscher aus Stanford, Eric J. Wang, die LoRA-Technologie (Low-Rank-Adaption) zur Reproduktion Alpaka-Ergebnis. Konkret trainierte Eric J. Wang mit einer RTX 4090-Grafikkarte ein Alpaca-äquivalentes Modell in nur 5 Stunden und reduzierte so den Rechenleistungsbedarf solcher Modelle auf Verbraucherniveau. Darüber hinaus kann das Modell auf einem Raspberry Pi ausgeführt werden (zu Forschungszwecken).
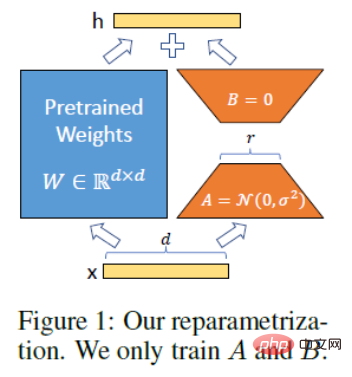
Das technische Prinzip von LoRA. Die Idee von LoRA besteht darin, einen Bypass neben dem ursprünglichen PLM hinzuzufügen und eine Dimensionsreduktion und anschließende Dimensionsoperation durchzuführen, um den sogenannten intrinsischen Rang zu simulieren. Während des Trainings werden die Parameter des PLM festgelegt und nur die Dimensionsreduktionsmatrix A und die Dimensionsverbesserungsmatrix B trainiert. Die Eingabe- und Ausgabedimensionen des Modells bleiben unverändert und die Parameter von BA und PLM werden bei der Ausgabe überlagert. Initialisieren Sie A mit einer zufälligen Gaußschen Verteilung und initialisieren Sie B mit einer 0-Matrix, um sicherzustellen, dass die Bypass-Matrix zu Beginn des Trainings immer noch eine 0-Matrix ist (zitiert nach: https://finisky.github.io/lora/). Der größte Vorteil von LoRA besteht darin, dass es schneller ist und weniger Speicher benötigt, sodass es auf Consumer-Hardware ausgeführt werden kann.

Alpaka-LoRA-Projekt gepostet von Eric J. Wang.
Projektadresse: https://github.com/tloen/alpaca-lora
#🎜 🎜#Dies ist zweifellos eine große Überraschung für Forscher, die ihre eigenen ChatGPT-ähnlichen Modelle trainieren möchten (einschließlich der chinesischen Version von ChatGPT), aber nicht über erstklassige Rechenressourcen verfügen. Daher entstanden nach dem Aufkommen des Alpaca-LoRA-Projekts weiterhin Tutorials und Trainingsergebnisse rund um das Projekt, und in diesem Artikel werden einige davon vorgestellt.
So verwenden Sie Alpaca-LoRA zur Feinabstimmung von LLaMAIm Alpaca-LoRA-Projekt erwähnte der Autor dies, um die Feinabstimmung vorzunehmen -Kostengünstig und effizient stimmen, sie verwendeten PEFT von Hugging Face. PEFT ist eine Bibliothek (LoRA ist eine der unterstützten Technologien), die es Ihnen ermöglicht, verschiedene Transformer-basierte Sprachmodelle zu verwenden und diese mithilfe von LoRA zu optimieren. Der Vorteil besteht darin, dass Sie Ihr Modell kostengünstig und effizient auf bescheidener Hardware mit kleineren (vielleicht zusammensetzbaren) Ausgaben optimieren können.
In einem aktuellen Blog stellten mehrere Forscher vor, wie Alpaca-LoRA zur Feinabstimmung von LLaMA verwendet werden kann.
Bevor Sie Alpaca-LoRA nutzen können, müssen Sie einige Voraussetzungen erfüllen. Das erste ist die Wahl der GPU. Dank LoRA können Sie nun die Feinabstimmung auf Low-Spec-GPUs wie NVIDIA T4 oder 4090 Consumer-GPUs durchführen. Darüber hinaus müssen Sie LLaMA-Gewichte beantragen, da deren Gewichte nicht öffentlich sind.
Da nun die Voraussetzungen erfüllt sind, geht es im nächsten Schritt um die Nutzung von Alpaca-LoRA. Zuerst müssen Sie das Alpaca-LoRA-Repository klonen. Der Code lautet wie folgt:
git clone https://github.com/daanelson/alpaca-lora cd alpaca-lora
Zweitens erhalten Sie die LLaMA-Gewichte. Speichern Sie die heruntergeladenen Gewichtswerte in einem Ordner mit dem Namen unconverted-weights. Die Ordnerhierarchie ist wie folgt:
unconverted-weights ├── 7B │ ├── checklist.chk │ ├── consolidated.00.pth │ └── params.json ├── tokenizer.model └── tokenizer_checklist.chk
Nachdem die Gewichte gespeichert wurden, verwenden Sie den folgenden Befehl, um die PyTorch-Prüfpunktgewichte in transformatorkompatible Formate zu konvertieren :
cog run python -m transformers.models.llama.convert_llama_weights_to_hf --input_dir unconverted-weights --model_size 7B --output_dir weights
Die endgültige Verzeichnisstruktur sollte wie folgt aussehen:
weights ├── llama-7b └── tokenizermdki
Nachdem Sie die beiden oben genannten Schritte ausgeführt haben, fahren Sie mit dem dritten Schritt fort und installieren Sie Cog:
sudo curl -o /usr/local/bin/cog -L "https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)" sudo chmod +x /usr/local/bin/cog
Der vierte Schritt besteht in der Feinabstimmung Modell: Standardmäßig ist die im Finetune-Skript konfigurierte GPU weniger leistungsstark. Wenn Sie jedoch über eine leistungsstärkere GPU verfügen, können Sie MICRO_BATCH_SIZE in finetune.py auf 32 oder 64 erhöhen. Wenn Sie außerdem Anweisungen zum Optimieren eines Datensatzes haben, können Sie den DATA_PATH in finetune.py so bearbeiten, dass er auf Ihren eigenen Datensatz verweist. Es ist zu beachten, dass dieser Vorgang sicherstellen sollte, dass das Datenformat mit alpaca_data_cleaned.json übereinstimmt. Führen Sie als Nächstes das Feinabstimmungsskript aus:
cog run python finetune.py
Der Feinabstimmungsprozess dauerte 3,5 Stunden auf einer 40-GB-A100-GPU und mehr Zeit auf weniger leistungsstarken GPUs.
Der letzte Schritt besteht darin, das Modell mit Cog auszuführen:
$ cog predict -i prompt="Tell me something about alpacas." Alpacas are domesticated animals from South America. They are closely related to llamas and guanacos and have a long, dense, woolly fleece that is used to make textiles. They are herd animals and live in small groups in the Andes mountains. They have a wide variety of sounds, including whistles, snorts, and barks. They are intelligent and social animals and can be trained to perform certain tasks.
Der Autor des Tutorials sagte, dass Sie nach Abschluss der oben genannten Schritte weiterhin verschiedene Gameplays ausprobieren können, einschließlich, aber nicht beschränkt auf:
- Bringen Sie Ihren eigenen Datensatz mit, optimieren Sie Ihre eigene LoRA, z. B. optimieren Sie LLaMA so, dass es wie eine Anime-Figur spricht. Siehe: https://replicate.com/blog/fine-tune-llama-to-speak-like-homer-simpson
- Stellen Sie das Modell auf der Cloud-Plattform bereit;
- In Kombination mit anderen LoRA, z Stabile Diffusion LoRA, wenden Sie all dies auf das Bildfeld an.
- Verwenden Sie den Alpaca-Datensatz (oder andere Datensätze), um größere LLaMA-Modelle zu optimieren und zu sehen, wie sie funktionieren. Dies sollte mit PEFT und LoRA möglich sein, erfordert allerdings eine größere GPU.
Alpaca-LoRA-Ableitungsprojekt
Obwohl die Leistung von Alpaca mit GPT 3.5 vergleichbar ist, sind seine Seed-Aufgaben alle auf Englisch und die gesammelten Daten sind auch auf Englisch, sodass das trainierte Modell nicht für Chinesisch geeignet ist. Um die Wirksamkeit des Dialogmodells auf Chinesisch zu verbessern, werfen wir einen Blick auf einige der besseren Projekte.
Das erste ist das Open-Source-Chinesisch-Sprachmodell Luotuo (Luotuo) von drei einzelnen Entwicklern der Central China Normal University und anderen Institutionen. Dieses Projekt basiert auf LLaMA, Stanford Alpaca, Alpaca LoRA, Japanese-Alpaca-LoRA usw ., mit einer einzigen Karte. Kann den Trainingseinsatz abschließen. Interessanterweise nannten sie das Modellkamel, weil sowohl LLaMA (Lama) als auch Alpaka (Alpaka) zur Ordnung Artiodactyla – Familie Camelidae – gehören. Unter diesem Gesichtspunkt wird dieser Name auch erwartet.
Dieses Modell basiert auf Metas Open-Source-LLaMA mit Bezug auf die beiden Projekte Alpaca und Alpaca-LoRA und wurde auf Chinesisch trainiert.
Projektadresse: https://github.com/LC1332/Chinese-alpaca-lora
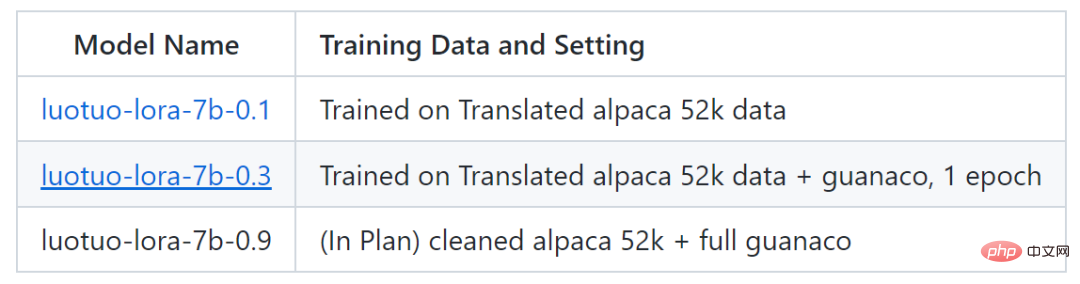
Derzeit hat das Projekt zwei Modelle veröffentlicht: luotuo-lora-7b-0.1 und luotuo-lora- 7b -0.3, es gibt ein anderes Modell im Plan:
Das Folgende ist die Effektanzeige:


Aber luotuo-lora-7b-0.1 (0.1), luotuo- lora-7b -0,3 (0,3) Es gibt immer noch eine Lücke. Als der Benutzer nach der Adresse der Central China Normal University fragte, antwortete 0,1 falsch:

Neben einfachen Gesprächen gibt es auch Menschen, die Modelloptimierungen in versicherungsrelevanten Bereichen durchgeführt haben. Laut diesem Twitter-Nutzer hat er mit Hilfe des Alpaca-LoRA-Projekts einige chinesische Versicherungsfrage- und Antwortdaten eingegeben und die Endergebnisse waren gut.
Insbesondere verwendete der Autor mehr als 3.000 chinesische Frage- und Antwortversicherungskorpus, um die chinesische Version von Alpaca LoRa zu trainieren. Der Implementierungsprozess verwendete die LoRa-Methode und verfeinerte das Alpaca 7B-Modell, was 240 Minuten dauerte ein Endverlust von 0,87.

Bildquelle: https://twitter.com/nash_su/status/1639273900222586882
Das Folgende ist der Trainingsprozess und die Ergebnisse:
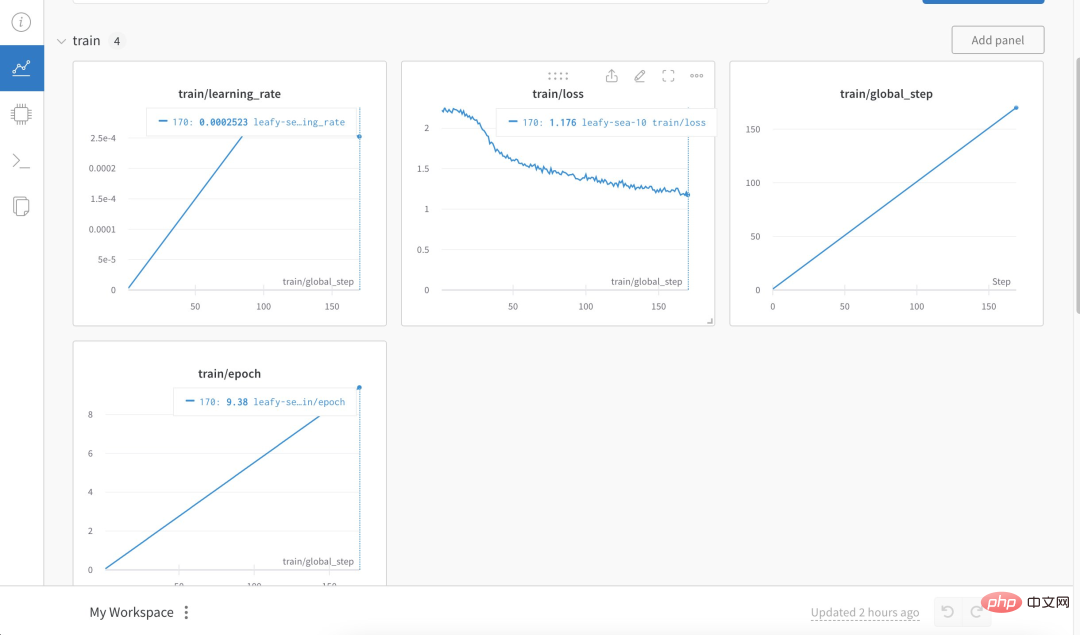
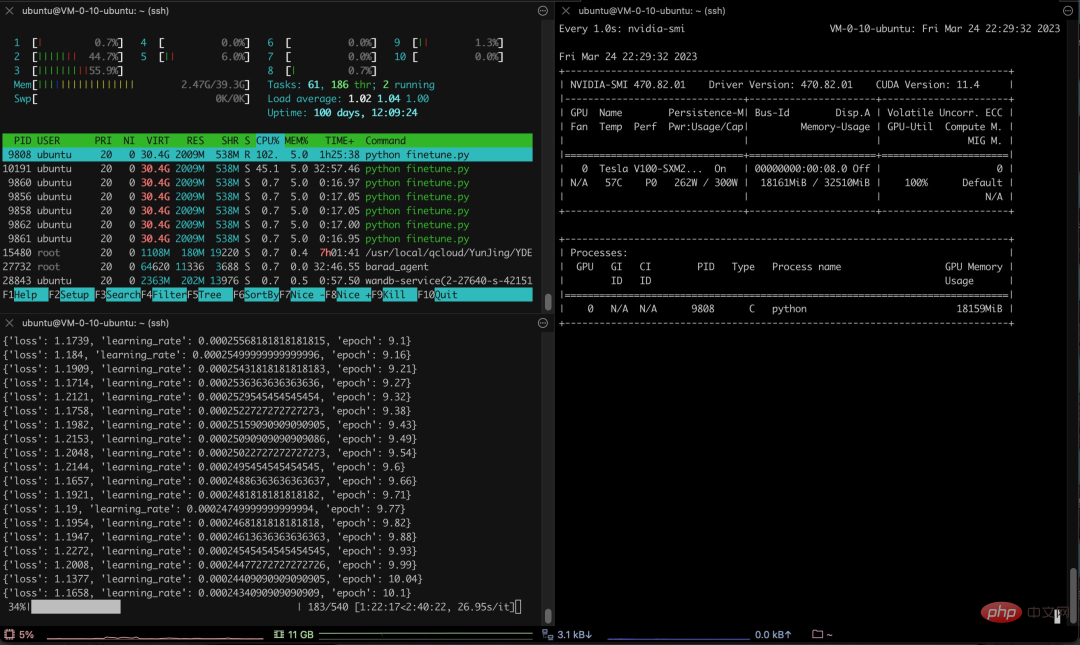
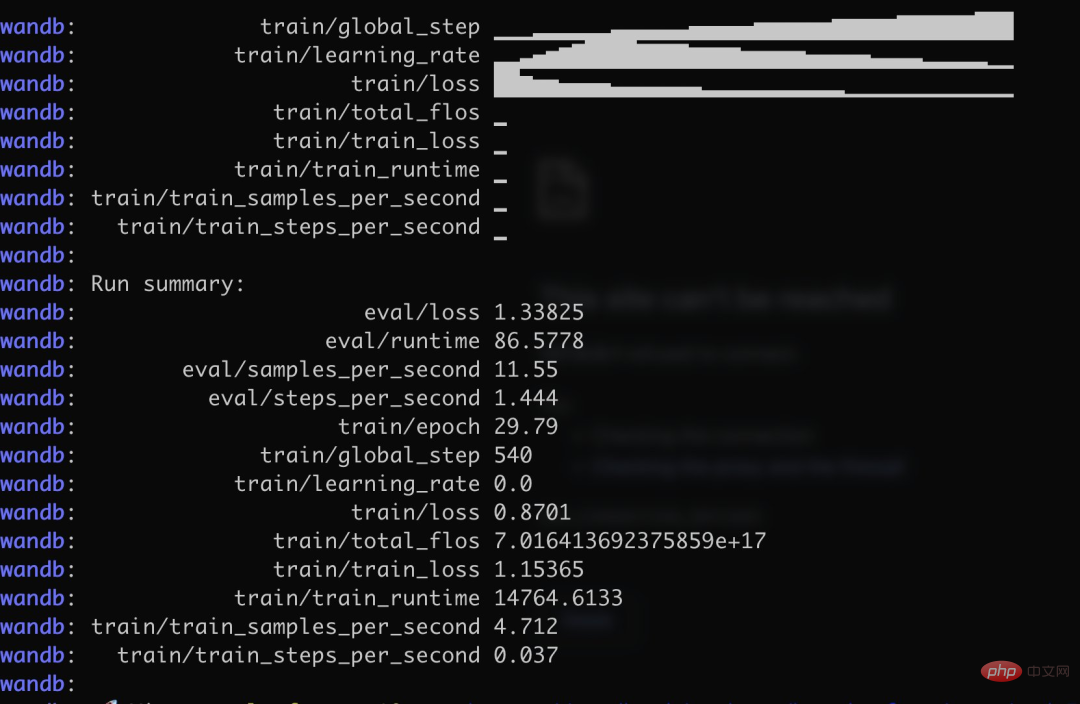
Test Die Ergebnisse zeigen, dass: 1. Inhalte, die sich auf das Trainingskorpus beziehen, grob und vernünftig beantwortet werden können, aber nur, wenn sie kein Unsinn sind. 2. Nicht-korpusbezogene Inhalte werden zwingend auf die Daten in einem bestimmten Korpus antworten. Logisches Denken und mathematische Berechnungen verfügen nicht über diese Fähigkeit.
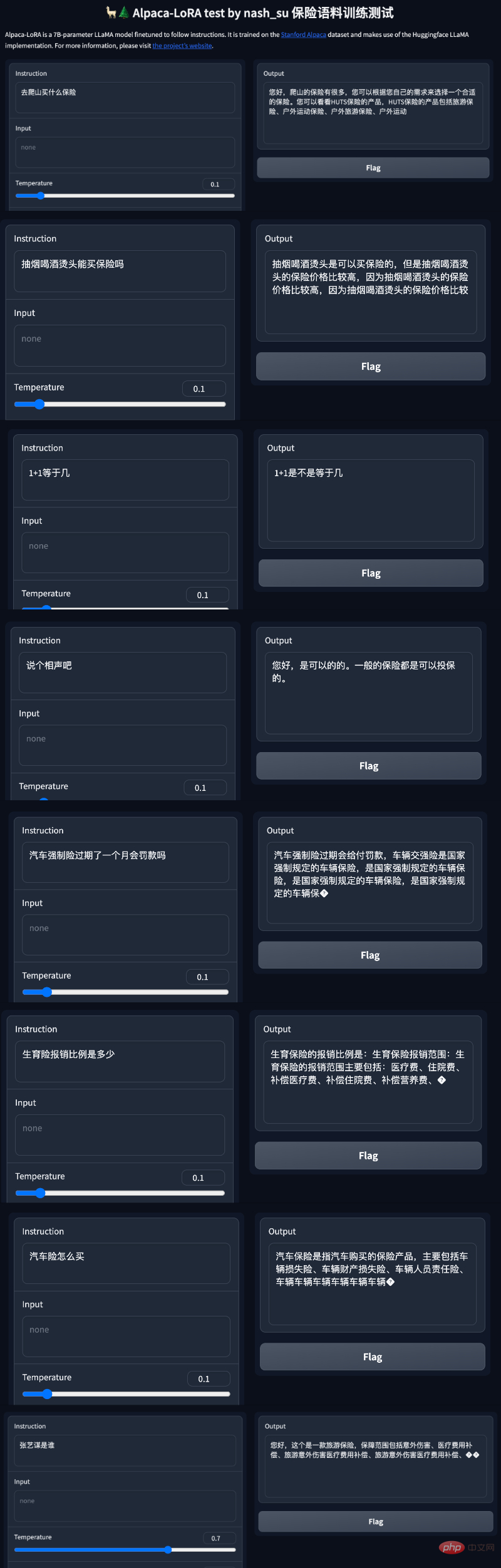
Nachdem die Internetnutzer dieses Ergebnis gesehen hatten, schrien sie, dass sie ihren Job verlieren würden:

Abschließend freue ich mich darauf, dass weitere chinesische Konversationsmodelle hinzugefügt werden.
Das obige ist der detaillierte Inhalt vonDas Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr