
Heim >Technologie-Peripheriegeräte >KI >Gemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |
Gemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |

- 王林nach vorne
- 2023-04-16 19:25:011493Durchsuche
Aufgabenuniversalität ist eines der Kernziele der grundlegenden Modellforschung und auch die einzige Möglichkeit für die Deep-Learning-Forschung, zu fortgeschrittener Intelligenz zu führen. Dank der universellen Schlüsselmodellierungsfähigkeiten des Aufmerksamkeitsmechanismus hat Transformer in den letzten Jahren in vielen Bereichen gute Leistungen erbracht und nach und nach einen Trend zur universellen Architektur gezeigt. Mit zunehmender Länge der Sequenz weist die Berechnung des Standardaufmerksamkeitsmechanismus jedoch eine quadratische Komplexität auf, was seine Anwendung bei der Modellierung langer Sequenzen und großen Modellen erheblich behindert.
Zu diesem Zweck hat ein Team der School of Software der Tsinghua-Universität dieses Schlüsselproblem eingehend untersucht und einen aufgabenuniversellen linearen Komplexitäts-Backbone-Netzwerk-Flowformer vorgeschlagen, der seine Komplexität auf den Standard-Transformer reduziert und gleichzeitig seine Vielseitigkeit beibehält. Das Papier wurde vom ICML 2022 angenommen.

Autorenliste: Wu Haixu, Wu Jialong,
Code: https://github.com/thuml/FlowformerIm Vergleich zum Standardtransformer weist das in diesem Artikel vorgeschlagene Flowformer-Modell die folgenden Eigenschaften auf:
Lineare Komplexität
und kann Behandeln Sie Eingaben mit Tausenden von Sequenzlängen.
- führt keine neuen Induktionspräferenzen ein und behält die universelle Modellierungsfähigkeit des ursprünglichen Aufmerksamkeitsmechanismus bei Sprache, Zeitreihen, Reinforcement Learning
- erzielt hervorragende Ergebnisse bei fünf Hauptaufgaben. 1. Problemanalyse
- Die Standardeingabe des Aufmerksamkeitsmechanismus enthält drei Teile: Abfragen (), Schlüssel () und Werte (). Die Berechnungsmethode lautet wie folgt: Wo ist die Aufmerksamkeitsgewichtsmatrix und das Finale? Das Berechnungsergebnis wird aus der gewichteten Fusion erhalten, und die Rechenkomplexität des obigen Prozesses beträgt. Es wird darauf hingewiesen, dass es viele Studien zum Problem der kontinuierlichen Multiplikation multinomialer Matrizen in klassischen Algorithmen gibt. Insbesondere für den Aufmerksamkeitsmechanismus können wir das assoziative Gesetz der Matrixmultiplikation verwenden, um eine Optimierung zu erreichen. Beispielsweise kann die ursprüngliche quadratische Komplexität auf linear reduziert werden. Die Funktion im Aufmerksamkeitsmechanismus macht es jedoch unmöglich, das Assoziativgesetz direkt anzuwenden. Daher ist das Entfernen von Funktionen im Aufmerksamkeitsmechanismus der Schlüssel zum Erreichen linearer Komplexität. Viele neuere Arbeiten haben jedoch gezeigt, dass Funktionen eine Schlüsselrolle bei der Vermeidung trivialer Aufmerksamkeitslernen spielen. Zusammenfassend freuen wir uns auf eine Modelldesignlösung, die die folgenden Ziele erreicht: (1) Funktionen entfernen; (2) triviale Aufmerksamkeit vermeiden; (3) die Vielseitigkeit des Modells beibehalten; 2. Motivation
- Um Ziel (1) zu erreichen, wurde in früheren Arbeiten häufig die Kernelmethode verwendet, um die Funktion zu ersetzen, d wird triviale Aufmerksamkeit erregen. Zu diesem Zweck mussten in früheren Arbeiten für Ziel (2) einige induktive Präferenzen eingeführt werden, die die Vielseitigkeit des Modells einschränkten und daher Ziel (3) nicht erfüllten, wie beispielsweise die Lokalitätsannahme in cosFormer. Wettbewerbsmechanismus in Softmax
Um die oben genannten Ziele zu erreichen, gehen wir von den grundlegenden Eigenschaften der Analyse aus. Wir weisen darauf hin, dass ursprünglich vorgeschlagen wurde, die maximale Operation „Winner-take-all“ in eine differenzierbare Form zu erweitern. Daher
Dank seines inhärenten „Konkurrenz“-Mechanismus kann es die Aufmerksamkeitsgewichte zwischen Token unterscheiden und so gewöhnliche Aufmerksamkeitsprobleme vermeiden.Basierend auf den obigen Überlegungen versuchen wir, den Wettbewerbsmechanismus in das Design des Aufmerksamkeitsmechanismus einzuführen, um triviale Aufmerksamkeitsprobleme zu vermeiden, die durch die Zerlegung der Kernelmethode verursacht werden.
Wettbewerbsmechanismus im NetzwerkflussWir achten auf das klassische Netzwerkflussmodell (Flow Network) in der Graphentheorie. „Erhaltung“(Erhaltung) ist ein wichtiges Phänomen, das heißt, der Zufluss jedes Knotens ist gleich zum Abfluss. Inspiriert von „Bei festen Ressourcen wird es zwangsläufig zu Konkurrenz kommen“ versuchen wir in diesem Artikel, den Informationsfluss im klassischen Aufmerksamkeitsmechanismus aus der Perspektive des Netzwerkflusses erneut zu analysieren und Wettbewerb in den Aufmerksamkeitsmechanismus einzuführen durch ErhaltungseigenschaftenDesign, um alltägliche Aufmerksamkeitsprobleme zu vermeiden.
3. Flowformer (Flusskapazität, entsprechend dem Aufmerksamkeitsgewicht) konvergiert zu
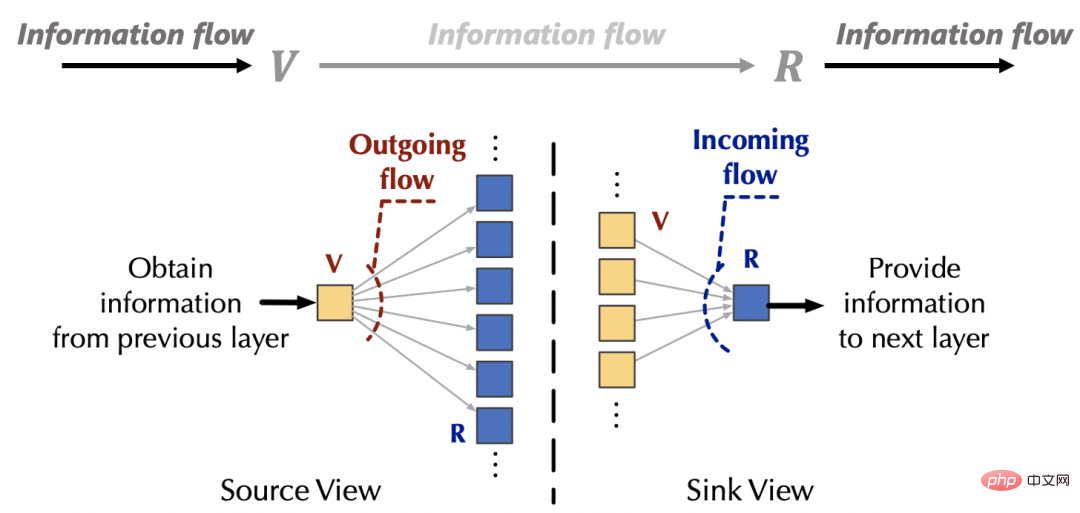
Sink (Senke, entsprechend). Außerhalb des Aufmerksamkeitsmechanismus stammen die Informationen der Quelle (v) von der oberen Schicht des Netzwerks, und die Informationen der Senke (R) werden auch der darunter liegenden Feed-Forward-Schicht bereitgestellt. Basierend auf den obigen Beobachtungen können wir „feste Ressourcen“ realisieren, indem wir die Interaktion zwischen dem Aufmerksamkeitsmechanismus und dem externen Netzwerk aus zwei Perspektiven steuern: Zufluss und Abfluss verursacht Konkurrenz innerhalb von Quellen bzw. Senken, um triviale Aufmerksamkeit zu vermeiden. Ohne Beschränkung der Allgemeinheit setzen wir die Menge an Interaktionsinformationen zwischen dem Aufmerksamkeitsmechanismus und dem externen Netzwerk auf den Standardwert 1 ist nicht schwer zu bekommen, vor der Konservierung beträgt die Menge an einfließenden Informationen für die Senke: . Um die Informationsmenge, die in jede Senke fließt, auf Einheit 1 festzulegen, führen wir als Normalisierung in die Berechnung des Informationsflusses (Aufmerksamkeitsgewicht) ein. Nach der Normalisierung beträgt die Menge der Zuflussinformationen der Senke: . Um die aus jeder Quelle fließende Informationsmenge auf Einheit 1 festzulegen, führen wir die Berechnung des Informationsflusses (Aufmerksamkeitsgewicht) als Normalisierung ein. Nach der Normalisierung beträgt die Menge der Abflussinformationen aus der j-ten Quelle: (3) Gesamtdesign In diesem Artikel wurden umfangreiche Experimente mit Standarddatensätzen durchgeführt: Deckt Eingabesituationen verschiedener Sequenzlängen (20-4000) ab.
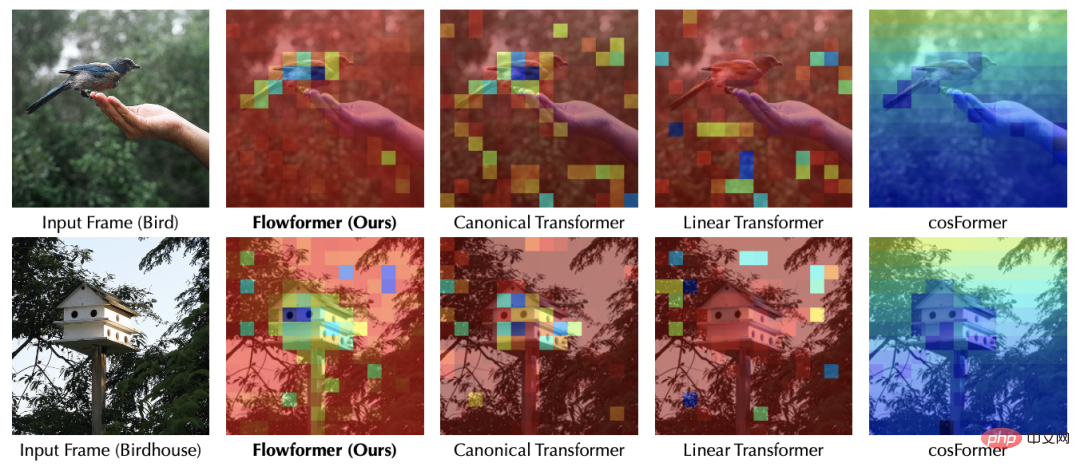
Vergleicht verschiedene Basismethoden wie klassische Modelle in verschiedenen Bereichen, Mainstream-Deep-Modelle, Transformer und seine Varianten. Um das Funktionsprinzip von Flowformer weiter zu erklären, haben wir ein visuelles Experiment zur Aufmerksamkeit in der ImageNet-Klassifizierungsaufgabe (entsprechend Flow-Attention) durchgeführt, aus dem wir Folgendes finden können: Die obige Visualisierung zeigt, dass die Einführung von Wettbewerb in die Gestaltung des Aufmerksamkeitsmechanismus durch Flow-Attention triviale Aufmerksamkeit effektiv vermeiden kann. Weitere Visualisierungsexperimente finden Sie im Artikel. Der in diesem Artikel vorgeschlagene Flowformer führt das Erhaltungsprinzip im Netzwerkfluss in das Design ein und führt auf natürliche Weise den Wettbewerbsmechanismus in die Aufmerksamkeitsberechnung ein, wodurch das triviale Aufmerksamkeitsproblem effektiv vermieden und lineare Komplexität erreicht wird Gleichzeitig bleibt die Vielseitigkeit des Standard-Transformers erhalten. Flowformer hat bei fünf Hauptaufgaben hervorragende Ergebnisse erzielt: lange Sequenzen, Vision, natürliche Sprache, Zeitreihen und verstärkendes Lernen. Darüber hinaus inspiriert das Designkonzept „keine besondere Induktionspräferenz“ im Flowformer auch zur Erforschung allgemeiner Infrastruktur. In zukünftigen Arbeiten werden wir das Potenzial von Flowformer für groß angelegte Vorschulungen weiter untersuchen. 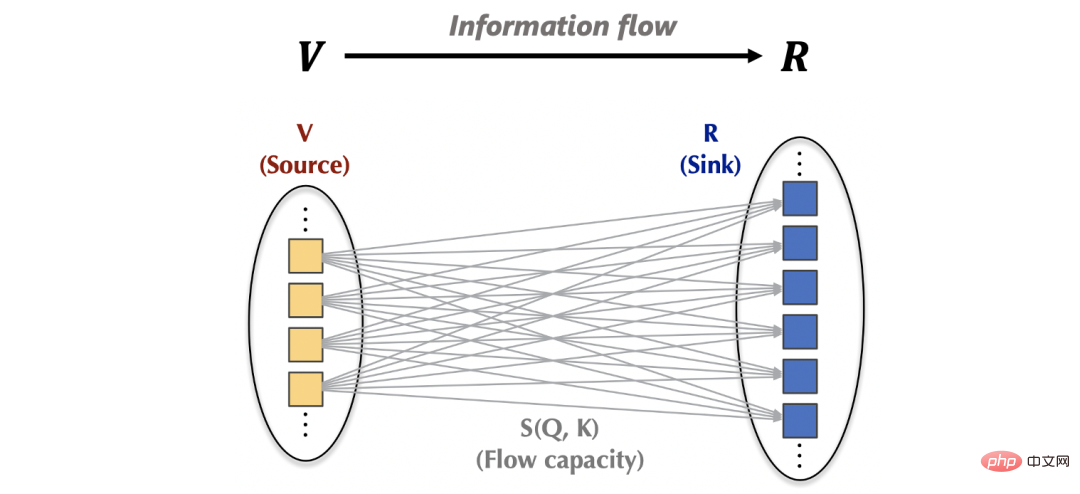
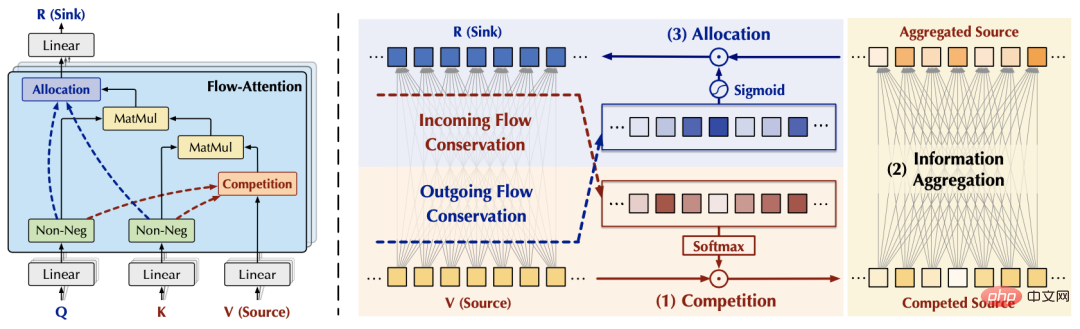
3.2 Fluss-Aufmerksamkeit
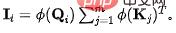
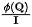 (2) Erhaltung des Ausflusses aus der Quelle (V): Ähnlich wie beim oben genannten Prozess beträgt vor der Erhaltung für die Quelle die Menge der ausfließenden Informationen:
(2) Erhaltung des Ausflusses aus der Quelle (V): Ähnlich wie beim oben genannten Prozess beträgt vor der Erhaltung für die Quelle die Menge der ausfließenden Informationen: 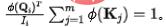
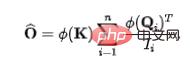
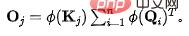 Basierend auf den obigen Ergebnissen entwerfen wir den folgenden Flow-Attention-Mechanismus, der insbesondere drei Teile umfasst: Wettbewerb, Aggregation und Zuteilung: Der Wettbewerb konkurriert Wenn der Mechanismus vorhanden ist Wichtige Informationen werden hervorgehoben. Die Aggregation basiert auf dem Matrix-Assoziationsgesetz, um eine lineare Komplexität zu erreichen. Durch die Einführung eines Wettbewerbsmechanismus wird die Menge der an die nächste Ebene weitergegebenen Informationen gesteuert. Alle Operationen im obigen Prozess weisen eine lineare Komplexität auf. Gleichzeitig basiert das Design von Flow-Attention nur auf dem Erhaltungsprinzip im Netzwerkfluss und integriert den Informationsfluss wieder. Daher werden keine neuen induktiven Präferenzen eingeführt, wodurch die Vielseitigkeit des Modells gewährleistet wird. Flowformer wird erhalten, indem die quadratische Komplexität Attention im Standardtransformator durch Flow-Attention ersetzt wird.
Basierend auf den obigen Ergebnissen entwerfen wir den folgenden Flow-Attention-Mechanismus, der insbesondere drei Teile umfasst: Wettbewerb, Aggregation und Zuteilung: Der Wettbewerb konkurriert Wenn der Mechanismus vorhanden ist Wichtige Informationen werden hervorgehoben. Die Aggregation basiert auf dem Matrix-Assoziationsgesetz, um eine lineare Komplexität zu erreichen. Durch die Einführung eines Wettbewerbsmechanismus wird die Menge der an die nächste Ebene weitergegebenen Informationen gesteuert. Alle Operationen im obigen Prozess weisen eine lineare Komplexität auf. Gleichzeitig basiert das Design von Flow-Attention nur auf dem Erhaltungsprinzip im Netzwerkfluss und integriert den Informationsfluss wieder. Daher werden keine neuen induktiven Präferenzen eingeführt, wodurch die Vielseitigkeit des Modells gewährleistet wird. Flowformer wird erhalten, indem die quadratische Komplexität Attention im Standardtransformator durch Flow-Attention ersetzt wird. 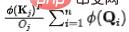 4. Experimente
4. Experimente
5. Analyse
6. Zusammenfassung
Das obige ist der detaillierte Inhalt vonGemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr